
이제 실제 데이터를 가지고 테스트 해볼 것이다.
추천 과정
1. 사용자가 tag 3개를 선택하면 전체 데이터(train)에서 필터링된 데이터 보여줌(20개)
→ 50개 이상이면 최신순으로 20개 보여줌
- 필터링된 50개의 데이터(train) 중에 사용자가 작품을 선택하면 해당 작품과 유사도가 높은 현재 상영중인 작품(present) 추천
→ 즉, train데이터와 present데이터 줄거리 간의 유사도를 측정해서 추천
파일명 정리
train.csv : 과거 데이터 원본
cleaned_train : train.csv의 특수문자 및 HTML 엔터티 코드 제거한 파일
벡터화 : train_synopsis_vector.ipynb, present_synopsis_vector.ipynb
train_synopsis_vector.ipynb의 csv파일 : past_vector.csv (날짜 처리 및 시놉시스 벡터 컬럼 추가됨)
present_synopsis_vecto.ipynbr의 csv파일 : present_vector.csv
tag : train_tag, present_tag
추천 : content_musical.ipynb
train 데이터 백터화 + tag
-
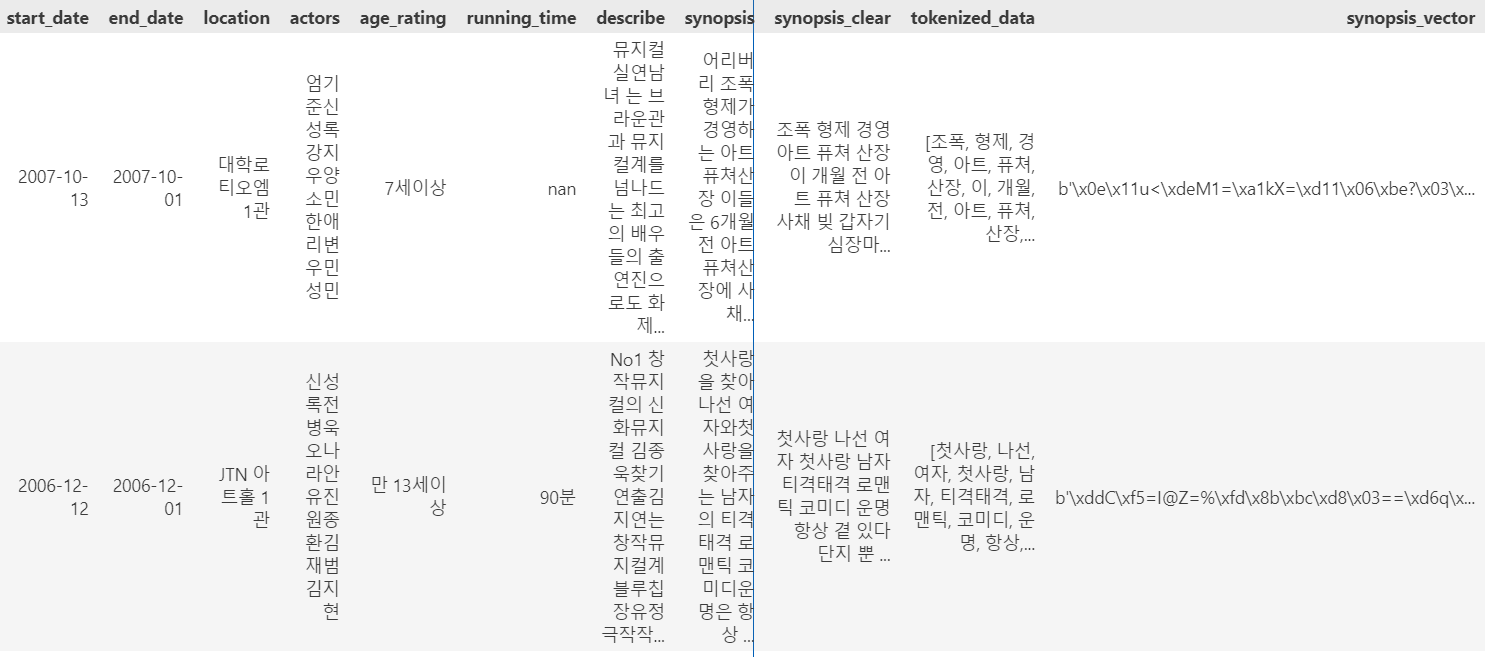
벡터화 : /data_preprocessing/train_synopsis_vector.ipynb
1. 모든 열에 대해 특수 문자와 HTML 엔터티 코드 모두 제거 : /data/cleaned_train.csv
2. 학습용 Word2Vec 모델 훈련(벡터화) : /data_preprocessing/vector_model.bin

3. 벡터를 문자열로 저장

4. date를 start_date와 end_date로 분리
5. 날짜 처리 및 시놉시스 벡터 컬럼 추가해서 csv저장 : /data/past_vector.csv
-
tag : /data_preprocessing/train_tag.ipynb
1. /data/past_vector.csv 파일 불러오기
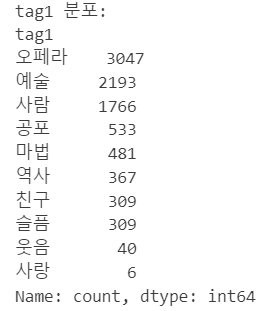
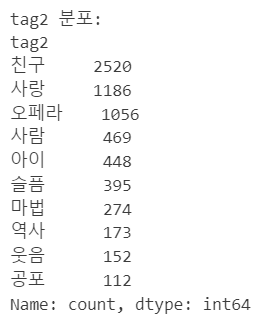
2. 단어를 조회하여 tag 11가지 선정 완료
'웃음'(코미디) : 890 '슬픔'(감정) : 315 '사랑'(로맨스): 4 '마법'(판타지): 469 '공포'(스릴러) : 829 '과거'(역사) : 249 '오페라': 964 '예술': 550
3. 유사도가 높은 1000개의 단어를 하나의 tag로 통합하기

4. tag 컬럼 추가해서 저장 : /data/train_tag.csv

5. 장르 분포 확인하기

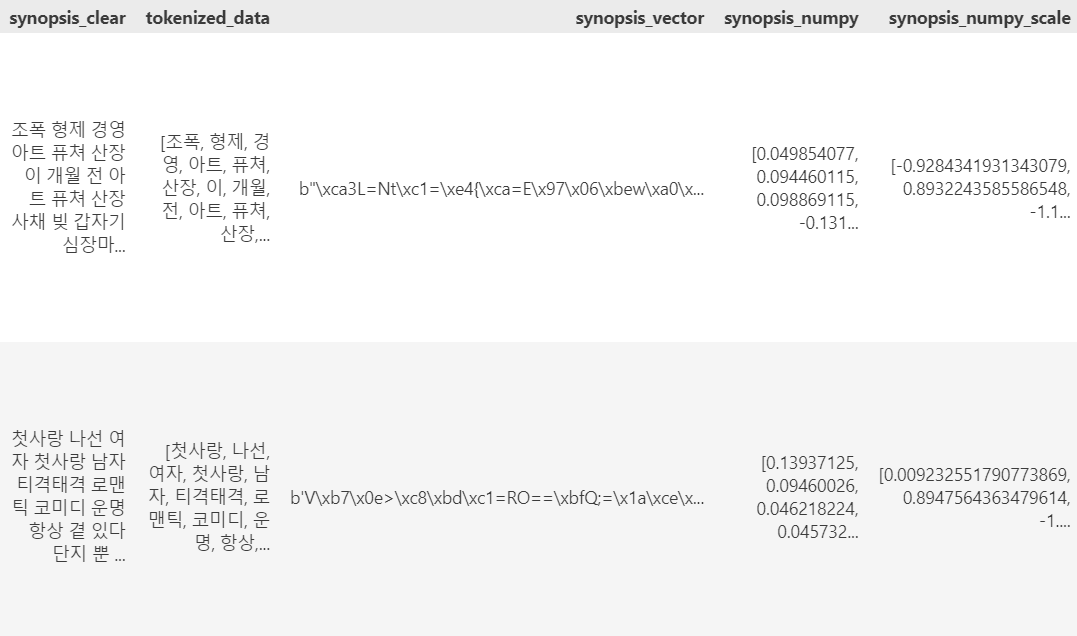
train데이터 synopsis_numpy_scale 컬럼 추가
- 문자열로 변환한 synopsis_vector 컬럼값 -> string_array에 저장
- 모든 행의 synopsis_vector 컬럼을 numpy 배열로 변환하여 synopsis_numpy 컬럼에 대입
- 데이터의 각 열의 평균을 뺀 다음 표준편차로 나눈 후 평균을 0로 표준편차를 1로 변환하여 리스트로 변환해서 synopsis_numpy_scale 컬럼에 대입(StandardScaler 객체 이용)
- /data/past_numpy_scale.csv 로 저장
유사도 측정 예시 (train 데이터끼리의 유사도 측정함)
- synopsis_numpy_scale 컬럼의 유클리드 거리를 계산
- sim_score (synopsys_vector_numpy_scale 컬럼의 유클리드 거리) DataFrame 으로 변환
- sim_df의 인덱스에 musical_id 대입 → title로 하면 겹치는 작품이 많음!!
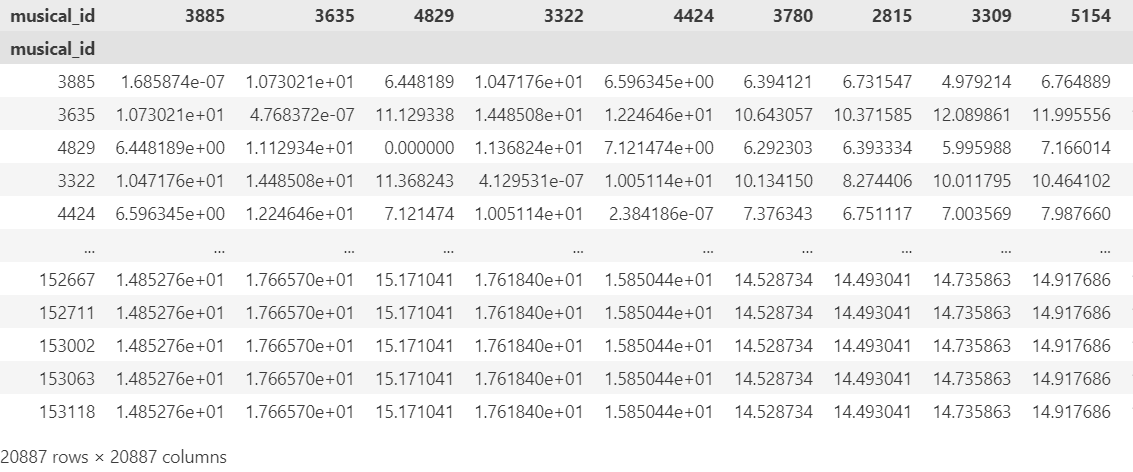
[결과]
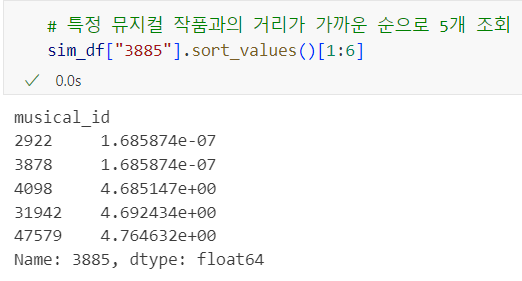
=> train데이터를 태그값 삭제, 벡터화, 장르세분화한것과 동일하게 present데이터 또한 동일하게 진행해 주었다.
파일명 정리
train.csv : 과거 데이터 원본
cleaned_train : train.csv의 특수문자 및 HTML 엔터티 코드 제거한 파일
벡터화 : train_synopsis_vector.ipynb, present_synopsis_vector.ipynb
train_synopsis_vector.ipynb의 csv파일 : past_vector.csv (날짜 처리 및 시놉시스 벡터 컬럼 추가됨)
present_synopsis_vecto.ipynbr의 csv파일 : present_vector.csv
tag : train_tag, present_tag
해당 코드는 branch 0.1.1/vector_tag에서 확인할 수 있습니다.
프로젝트 관련 코드는 아래의 주소에서 확인할 수 있습니다
i-Five
