
생성한 테스트 추천 시스템을 가지고 FAST API에서 작동을 확인해 볼것이다.
FAST API란
FastAPI는 Python으로 작성된 빠르고 효율적인 웹 프레임워크로, 웹 API를 빠르게 개발하고 문서화하는 데 사용됩니다. 주로 성능에 중점을 두며, Type Hints와 Pydantic을 활용하여 코드의 가독성을 높이고 자동으로 API 문서를 생성합니다. FastAPI를 사용하면 높은 성능과 개발 생산성을 동시에 얻을 수 있습니다.
FastAPI의 특징
-
빠른 속도: FastAPI는 Starlette와 Pydantic 등의 빠른 라이브러리를 기반으로 하여 높은 성능을 제공합니다.
a. Starlette : Python으로 작성된 경량의 비동기 웹 프레임워크입니다.
역할 : FastAPI와 함께 사용되어 웹 애플리케이션의 기본적인 기능을 처리하고, 비동기 요청 및 응답을 다룹니다.
b. Pydantic : Pydantic은 데이터 검증, 직렬화 및 구조적 데이터 모델링을 위한 Python 라이브러리로 데이터의 형식을 정의하고 유효성을 검사할 수 있습니다.
역할 : FastAPI에서 Pydantic 모델을 사용하여 클라이언트로부터의 요청 데이터 및 서버에서의 응답 데이터의 형식을 정의하고 검증합니다. -
자동 문서화: Type Hints를 기반으로 자동으로 API 문서를 생성하므로, API를 설계하면서 동시에 문서도 생성할 수 있습니다.
a. Type Hints : Python 3.5 이상에서 도입된 Type Hints는 코드에 타입 정보를 제공하는 기능입니다. 함수의 매개변수와 반환 값에 대한 예상 타입을 주석으로 추가할 수 있습니다.
역할 : FastAPI에서 Type Hints는 코드의 가독성을 높이고, 자동으로 API 문서를 생성하는 데 사용됩니다.
b. API 문서 생성 및 설계 : API 문서 생성은 API의 동작 및 사용법에 대한 문서를 자동으로 생성하는 과정을 의미합니다. FastAPI는 코드의 Type Hints와 Pydantic 모델을 기반으로 자동으로 API 문서를 생성합니다.
역할 : 사용자에게 API의 기능 및 사용법을 이해하기 쉽게 제공하며, 개발자가 API를 더 쉽게 설계하고 유지보수할 수 있도록 도움을 줍니다. -
데이터 유효성 검사: Pydantic을 사용하여 요청 및 응답 데이터의 유효성을 자동으로 검사하고 변환합니다.
-
비동기 지원: 비동기 및 동기 코드를 모두 지원하여 성능 최적화에 유리합니다.
-
코드 가독성: 간결하고 가독성이 좋은 코드를 작성할 수 있도록 도와줍니다.
-
모델 사용: Pydantic 모델을 사용하여 데이터의 형식과 유효성을 관리하고, 이를 이용해 자동으로 OpenAPI 및 JSON Schema 문서를 생성합니다.
a. OpenAPI : OpenAPI는 웹 서비스 API를 설명하기 위한 명세로, API의 기능, 엔드포인트, 매개변수, 응답 등에 대한 표준을 제공합니다.
역할 : FastAPI는 자동으로 OpenAPI 명세를 생성하여 API의 기능 및 구조를 표준화하고, 클라이언트 및 다른 개발자들이 쉽게 API를 이해하고 활용할 수 있도록 합니다.
b. JSON Schema : JSON 데이터의 구조를 정의하기 위한 스키마 언어로서 JSON Schema를 사용하면 JSON 데이터가 특정 형식에 맞는지, 필수 속성이 있는지, 값의 유효성 등을 정의할 수 있습니다. 이를 통해 JSON 데이터의 유효성을 검사하고, 데이터 교환 시의 일관성을 확보할 수 있습니다.
FAST API사용방법
- 가상환경 실행하기
가상환경 실행이유는 로컬에서 여러가지를 다운받지 않고 격리된 환경에서 설치 및 테스트를 진행하기 위해서이다.
$ python3 -m venv ~/ML
$ source ~/ML/bin/activate

[만약 가상환경이 없는 경우]
$ mkdir ~/ML
$ python3 -m venv ~/ML
$ source ~/ML/bin/activate

- FastAPI설치하기
pip install fastapi- FastAPI 애플리케이션을 실행하기 위해 Uvicorn을 설치
pip install uvicorn- FastAPI 앱 만들기
FastAPI를 테스트를 진행하려는 프로젝트로 이동하여 app.py를 생성한 후 FastAPI를 정의한다.
[정보]
필자는 이전페이지에서 추천시스템을 작성하였던 폴더와 branch에서동일하게 진행하였다. -> 이후 실제데이터로 동일하게 테스트하는 것은 0.1.1/FAST_API에서 실행할 것이다.
# 필요한 라이브러리 및 모듈 import
import os # 운영 체제와 상호 작용하기 위한 모듈
import pandas as pd # 데이터 조작 및 분석을 위한 라이브러리
import numpy as np # 수치 계산을 위한 라이브러리
from konlpy.tag import Okt # 한국어 형태소 분석을 위한 라이브러리
from gensim.models.word2vec import Word2Vec # 단어 임베딩을 위한 Word2Vec 모델
import re # 정규 표현식을 사용하기 위한 라이브러리
import html # HTML 엔터티를 변환하기 위한 라이브러리
from sklearn.metrics.pairwise import euclidean_distances # 유클리디언 거리 계산을 위한 라이브러리
from sklearn.preprocessing import StandardScaler # 데이터 스케일링을 위한 라이브러리
from fastapi import FastAPI # FastAPI 웹 프레임워크
# FastAPI 애플리케이션 초기화
app = FastAPI()
# Java 환경 변수 설정
os.environ["JAVA_HOME"] = "C:\Program Files\Java\jdk-11"
# 뮤지컬 데이터 파일 URL
file = "https://drive.google.com/uc?id=구글드라이브 해당 csv파일의 id값을 넣기"
# CSV에서 뮤지컬 데이터 불러오기
musical_data = pd.read_csv(file, encoding='utf-8')[여기서 잠깐!!!]
구글드라이브의 csv파일을 read하는 방법
1. 우선 구글드라이브에 사용할 csv파일을 넣기

2. 해당 파일을 우클릭하여 링크복사하기

링크를 보면 d/경로안에 암호처럼 생긴게 있는 것을 볼 수 있다. 이것이 해당 csv파일의 id값이다. 해당부분을 복사하여 file = "https://drive.google.com/uc?id=구글드라이브 해당 csv파일의 id값을 넣기" 부분에 넣어주면 된다.
그럼 다시 이어서 app.py를 작성해자.
# 모든 열에서 특수 문자와 HTML 엔터티 정제
for col in musical_data.columns:
musical_data[col] = musical_data[col].apply(lambda x: re.sub(r'[^\w\s]', '', html.unescape(str(x))))
# Konlpy를 사용한 텍스트 전처리
twitter = Okt()
# 텍스트 전처리 함수
def preprocessingText(synopsis):
stems = [] # 형태소 추출 결과를 저장할 리스트
tagged_review = twitter.pos(synopsis, stem=True) # 한국어 형태소 분석기를 사용하여 형태소 추출
# 각 단어와 형태소의 품사에 대해 반복
for word, pos in tagged_review:
# 명사(Noun) 또는 형용사(Adjective)인 경우에만 추출 리스트에 추가
if pos == "Noun" or pos == 'Adjective':
stems.append(word)
# 공백을 이용하여 추출한 형태소들을 하나의 문자열로 결합하여 반환
return " ".join(stems)
# 각 시놉시스에 대해 전처리 함수 적용
musical_data['synopsis_clear'] = musical_data['synopsis'].fillna('').apply(preprocessingText)
# 시놉시스 데이터를 리스트로 변환
sentences = musical_data['synopsis'].tolist()
# 시놉시스 열의 각 텍스트에 대해 앞서 정의한 전처리 함수(preprocessingText)를 적용하고 NaN 값은 빈 문자열로 대체
tokenized_data = musical_data['synopsis'].apply(lambda x: preprocessingText(str(x))).fillna('')
# 새로운 열 'synopsis_clear'에 전처리된 텍스트 추가 및 공백 추가
musical_data["synopsis_clear"] = musical_data['synopsis_clear'].astype(str) + " "
# 'synopsis_clear' 열의 각 텍스트를 공백을 기준으로 분할하여 리스트로 변환하여 'tokenized_data' 열에 추가
musical_data["tokenized_data"] = musical_data["synopsis_clear"].apply(lambda data: data.split(" "))
model = Word2Vec(musical_data["tokenized_data"],
vector_size=100,
window=3,
min_count=2,
sg=1)
model.save("word2vec_model2.bin")
# WordVector 단어를 문자열로 변환
word2vec_words = model.wv.key_to_index.keys()
# 시놉시스를 벡터화하고 문자열로 저장
string_array = []
# 데이터프레임의 행 수 만큼 반복
for index in range(len(musical_data)):
# 각 행에서 'musical_id', 'title', 'tokenized_data' 열의 데이터 추출
NUM = musical_data.loc[index, "musical_id"]
TITLE = musical_data.loc[index, "title"]
LINE = musical_data.loc[index, "tokenized_data"]
# 문장 벡터 초기화
doc2vec = None
# 해당 문장에 포함된 단어 수 초기화
count = 0
# 각 단어에 대해 Word2Vec 모델 적용
for word in LINE:
# 모델이 학습한 단어일 경우
if word in word2vec_words:
# 해당 단어의 벡터를 더함
count += 1
if doc2vec is None:
doc2vec = model.wv[word]
else:
doc2vec = doc2vec + model.wv[word]
# 문장의 벡터값 계산 (평균값)
if doc2vec is not None:
doc2vec = doc2vec / count
# 문자열로 변환하여 저장
string_array.append(doc2vec.tostring())
# 데이터프레임에 새로운 열 추가
musical_data["doc2vec_vec"] = string_array
# 날짜에서 start_date와 end_date 추출
musical_data['start_date'] = pd.to_datetime(musical_data['date'].str[:8], format="%Y%m%d")
musical_data['end_date'] = pd.to_datetime(musical_data['date'].str[:6], format="%Y%m")
# 열 재정렬
musical_data = musical_data[['musical_id', 'title', 'poster_url', 'genre', 'date', 'start_date', 'end_date', 'location',
'actors', 'age_rating', 'running_time', 'describe', 'synopsis', 'synopsis_clear',
'tokenized_data', 'doc2vec_vec']]
# 필요시 CSV로 저장
# musical_data.to_csv('../musical_data_vector.csv', index=False, encoding='utf-8')
# 추천 시스템
# doc2vec_vec을 numpy 배열로 변환
musical_data["doc2vec_numpy"] = musical_data["doc2vec_vec"].apply(lambda x: np.fromstring(x, dtype="float32"))
# 데이터 스케일 조정
scaler = StandardScaler()
scaler.fit(np.array(musical_data["doc2vec_numpy"].tolist()))
musical_data["doc2vec_numpy_scale"] = scaler.transform(np.array(musical_data["doc2vec_numpy"].tolist())).tolist()
# 유클리디언 거리 계산
sim_score = euclidean_distances(musical_data["doc2vec_numpy_scale"].tolist(), musical_data["doc2vec_numpy_scale"].tolist())
sim_df = pd.DataFrame(data=sim_score, index=musical_data["title"], columns=musical_data["title"])
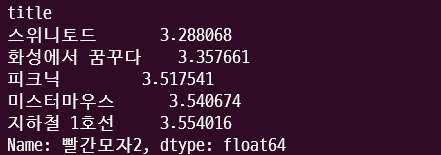
# 예시: "빨간모자2"와 유사한 5개의 뮤지컬 가져오기
similar_musicals = sim_df["빨간모자2"].sort_values()[1:6]
# FastAPI 초기 엔드포인트용 route
@app.get("/")
def init():
return similar_musicals이전페이지에서 작성했던 컨텐츠 기반 추천 시스템 코드를 REST API에서 응답을 확인하기 위해 app.py로 이동하였다.
- FastAPI 애플리케이션을 실행
방법1
uvicorn app:app --reloadhttp://127.0.0.1:8080 을 브라우저에서 실행해보기
방법2
uvicorn app:app --reload --host 0.0.0.0 --port 8080--host 0.0.0.0은 모든 IP 주소에서의 연결을 허용하도록 설정하고, --port 8080은 8080 포트를 사용하도록 설정합니다. 이렇게 하면 http://127.0.0.1:8080 에서 FastAPI 서버에 액세스할 수 있다.

branch: 0.0.3/work2vec에 내용에 해당하는 코드파일이 포함되어있으니 참고바랍니다.
tmi: branch명을 word2vec로 한다는걸 너무 자연스럼게 work2vec로 하고 너무 많은일들을 해서 그냥..흐린눈하기로 했다..^^ 다음부터는 정신차리고 제대로 생성하기!!
프로젝트 관련 코드는 아래의 주소에서 확인할 수 있습니다
i-Five
