순환신경망 (RNN - Recurrent Neural Network)
- recurrent: 되풀이되는, 반복되는
- Sequence Data(순차데이터) 분석을 위한 모형
- Sequence Data(순차데이터)
- 신경망은 순차적인 데이터, 즉 시퀀스 데이터를 처리하는 데 특화되어 있다. 즉, 순서가 의미가 있으며 이로인해 순서가 달라질 경우 의미가 바뀌거나 손상되는 데이터이다.
- 신경망은 순차적인 데이터, 즉 시퀀스 데이터를 처리하는 데 특화되어 있다. 즉, 순서가 의미가 있으며 이로인해 순서가 달라질 경우 의미가 바뀌거나 손상되는 데이터이다.
- RNN은 시계열 데이터를 처리하는 데 특화된 모델이다.
- 시계열 데이터
- 시계열 데이터는 시간의 흐름에 따라 기록된 데이터로, 각 데이터 포인트들은 시간적으로 순서가 있는 연속적인 값들로 이루어져 있다.
- 예를 들어, 일기예보 데이터, 주식 가격 데이터, 센서로부터 수집된 시계열 데이터 등이 시계열 데이터에 해당합니다. 이러한 데이터들은 시간적인 순서에 따라 상관관계가 있을 수 있다. → 이러한 상관관계를 파악하고 예측하는 것이 시계열 데이터의 특징이다.
- 시계열 데이터
- RNN은 이러한 시계열 데이터의 특성을 잘 반영하여 각 시점의 데이터를 순차적으로 입력 받아 이전 시점의 정보를 활용하여 다음 시점의 값을 예측하거나 분류하는 등의 작업에 사용한다.
- Memory System"으로서의 역할
-
RNN의 은닉 상태가 이전 시점의 정보를 기억하고 전달하기 때문에 시퀀스 데이터의 패턴을 파악하는 데 유용하다.
but
기본적인 RNN은 긴 시퀀스에 대해 장기 의존성을 처리하는데 어려움을 겪을 수 있다. 이는 긴 시퀀스에서 과거 정보를 적절히 기억하지 못해 정보가 소실되거나 불필요하게 강조되는 문제를 의미한다.
⇒ 그래서 긴 시퀀스에 대해서도 장기 의존성 문제를 해결하는 LSTM과 GRU와 같은 변형된 RNN 모델들이 주로 활용된다.
-
RNN을 이용한 Sequence data 처리 예
- Sequence-to-vector (many to one)
입력------------출력 - 여러개가 들어와서 하나의 값이 나온다.
- Sequence Data(순서가 있는 데이터)가 입력으로 들어가 Vector(하나)가 출력된다.
- 예: 주가예측 : 4일간의 주가가 들어가면 그 다음날 주가가 나온다.
- Input: 4일간 주가
- Output: 5일째 주가

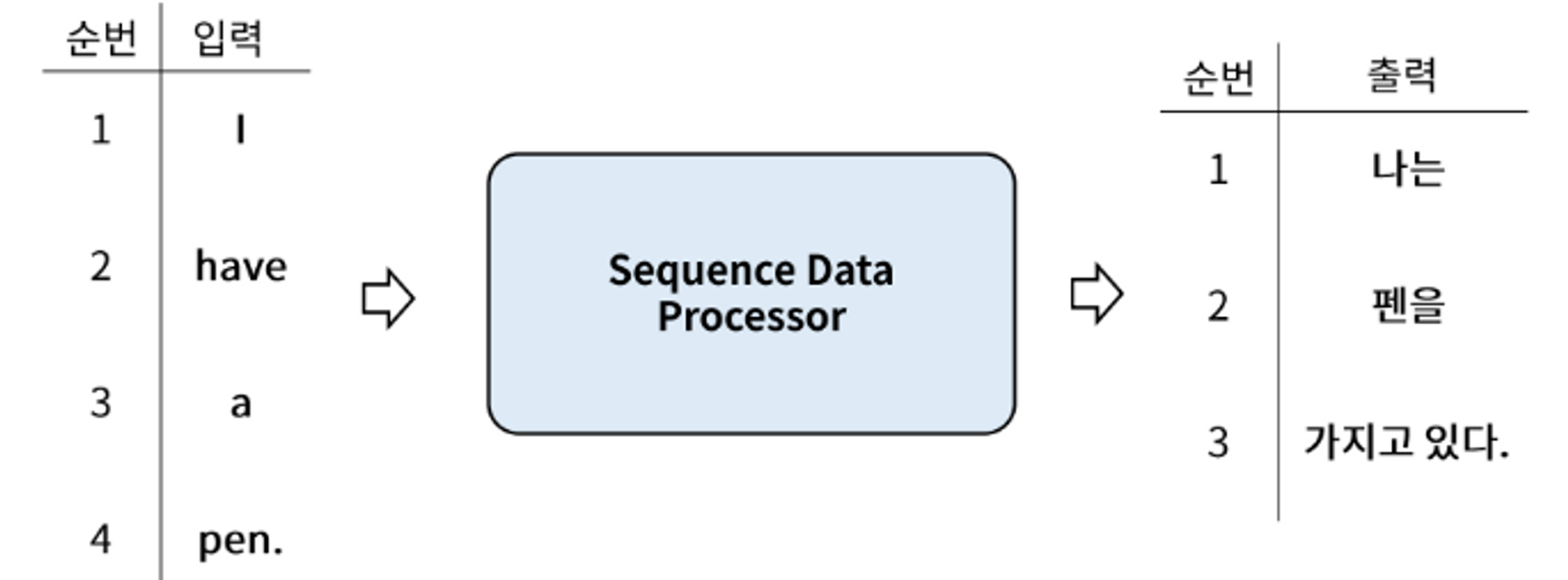
- **sequence-to-sequence(many to many)** 입력 출력
- 여러개가 들어와서 여러개의 값이 나온다.
- Sequnece data가 입력으로 들어가 Sequence Data가 출력된다.
- Input: 영어 문장 전체를 단어 단위로 순차적 입력
- Output: 번역된 한글 문장을 단어 단위로 순차적 출력
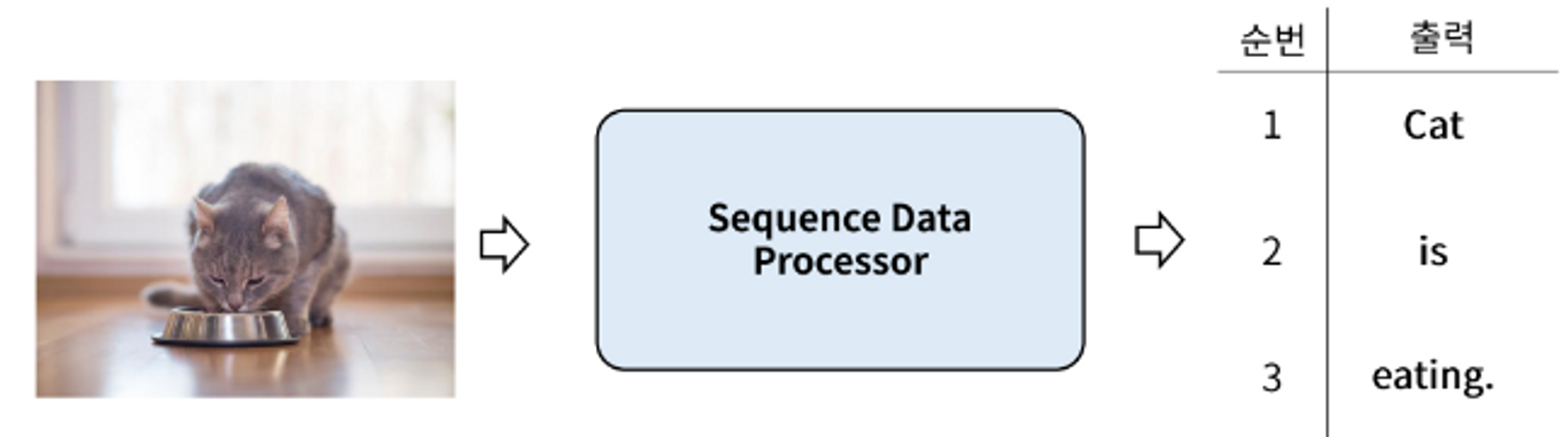
- **Vector-to-sequence (one to many)**
- 하나가 들어가서 여러개의 값이 나온다.
- 하나의 데이터가 입력으로 들어가 Sequence Data가 출력된다.
- 예: Image captioning (이미지를 설명하는 문장을 만드는 것)
- 이미지가 입력되면 이미지에 대한 설명이 문장(들)으로 출력된다.
- Input: 이미지
- Output: 이미지에 대한 설명을 단어 단위로 순차적으로 출력
RNN (Recurrent Neural Networks)
- Simple RNN
- tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x))
- tanh 함수는 입력으로부터 출력까지의 범위가 -1에서 1까지이며, 중심이 원점 (0, 0)이다.
- tanh 함수는 sigmoid 함수와 비슷한 형태를 가지지만, 출력 범위가 더 넓고 입력의 대칭을 가지는 특징이 있다.
Simple RNN의 문제
-
Sequence가 긴 경우 앞쪽의 기억이 뒤쪽에 영향을 미치지 못해 학습능력이 떨어진다.
LSTM (Long Short Term Memory)
-
오래 기억할 것은 유지하고 잊어버릴 것은 빨리 잊어버리자
-
LSTM은 장기 의존성을 더욱 효과적으로 기억하고 전달하기 위한 메커니즘을 가지고 있다.
-
LSTM은 기본적으로 은닉 상태(hidden state)와 장기 상태(long-term state)라는 두 가지 상태를 가지고 있다.
-
LSTM은 게이트라 불리는 구조를 사용하여 장기 상태와 은닉 상태를 제어하고 업데이트한다.
- 게이트는 정보가 흐르는 양을 결정하는 역할을 하며, 입력, 삭제, 출력 등의 기능을 담당한다.
-
장기 상태(long-term state)는 과거 정보를 기억하는데 사용
-
은닉 상태(hidden state)는 현재 입력과 과거 정보를 바탕으로 계산되는 새로운 정보를 담고 있다,
-
LSTM 이전 기억
- Cell State
- Long term memory 로 전체 step에 대한 누적 기억값(처리결과)
- Hidden State
- Short term memory 로 이전 sequence 에 대한 기억값(처리결과)
- Cell State
-
LSTM의 구조
-
Forget gate
-
입력된 cell state에서 얼마나 잊어 버릴지를 처리.
-
입력: 이전 시점의 은닉 상태 (h_t-1)와 현재 시점의 입력 (x_t)
-
출력: 0과 1 사이의 값으로 이루어진 벡터 f_t
계산 방법:
forget gate의 계산은 시그모이드 함수를 사용하여 이루어집니다.
f_t = sigmoid(W_f * [h_t-1, x_t] + b_f)
-
-
Input gate
-
현재 sequence의 입력데이터를 cell state(Long term memory)에 더한다.
-
Input gate는 현재 입력과 이전 장기 상태로부터 어떤 정보를 기억해야 할지를 결정한다.
-
입력: 이전 시점의 은닉 상태 (h_t-1)와 현재 시점의 입력 (x_t)
-
출력: 0과 1 사이의 값으로 이루어진 벡터 i_t
계산 방법:
input gate의 계산은 시그모이드 함수를 사용하여 이루어집니다.
i_t = sigmoid(W_i * [h_t-1, x_t] + b_i)
-
-
Output gate
- 현재 sequnce의 입력데이터를 처리해서 output으로 출력(output으로도 보내주고 hidden state로 보내진다.)
- Output gate는 현재 시점의 입력과 이전 장기 상태를 바탕으로 현재 은닉 상태를 어떻게 계산할지를 결정한다.
- 입력: 이전 시점의 은닉 상태 (h_t-1)와 현재 시점의 입력 (x_t)
- 출력: 0과 1 사이의 값으로 이루어진 벡터 o_t계산 방법:
💡 Cell State,Input gate는 무엇을 잊어버리고 현재 데이터로 할지 output gate는 현재 데이터로 어떻게 출력할지
output gate의 계산은 시그모이드 함수를 사용하여 이루어집니다.
o_t = sigmoid(W_o * [h_t-1, x_t] + b_o)
-
LSTM_stockprice
- Yahoo Finance 에서 주가 데이터 다운로드 (https://finance.yahoo.com/)

- 기간 선택 후 Apply -> Download 클릭


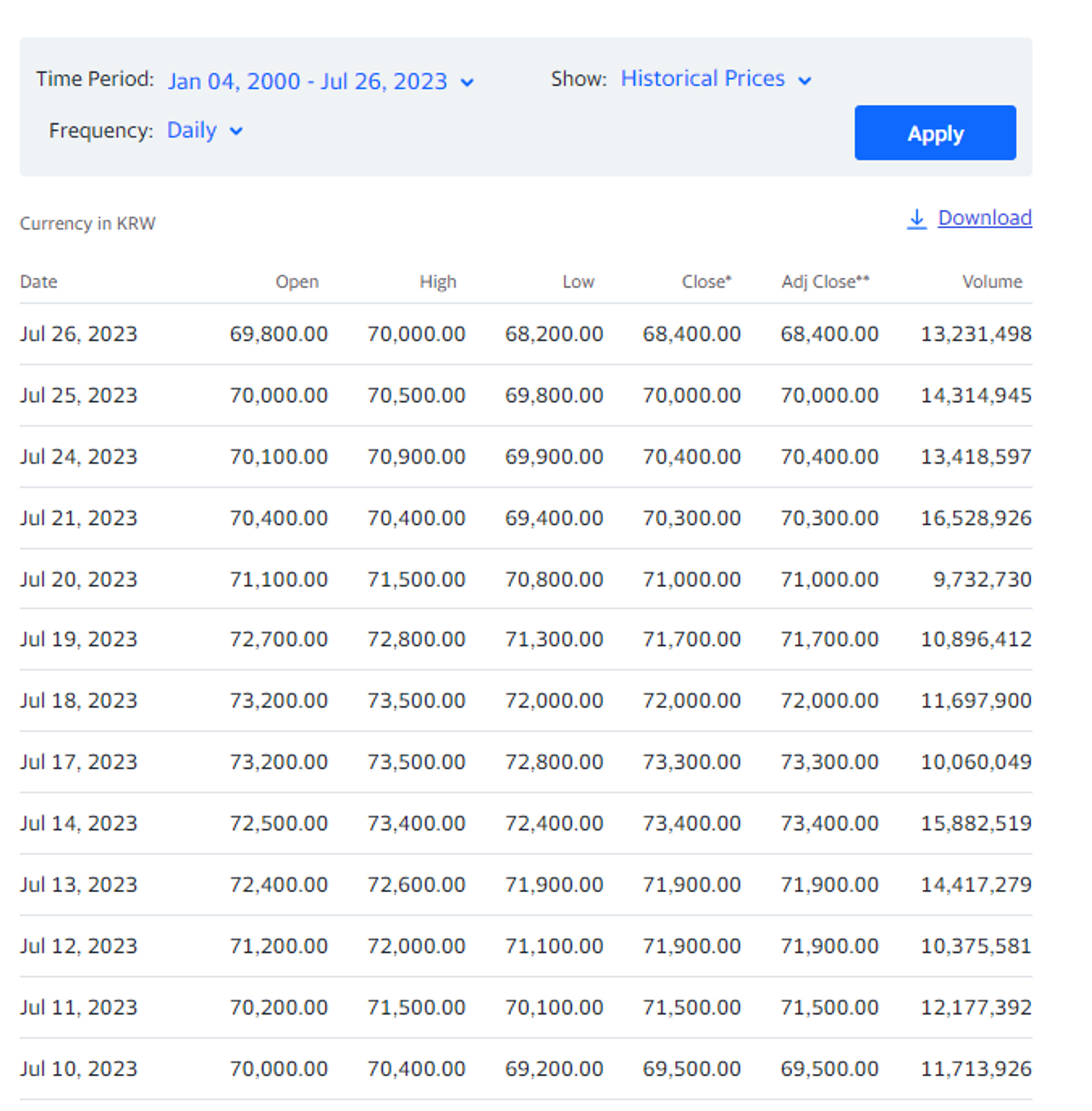
- csv파일을 폴더로 이동
이제 read_csv해서 실습시작!!
4일치의 주가를 보고 5일치의 close(마감주가)를 예측하는 방식이다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
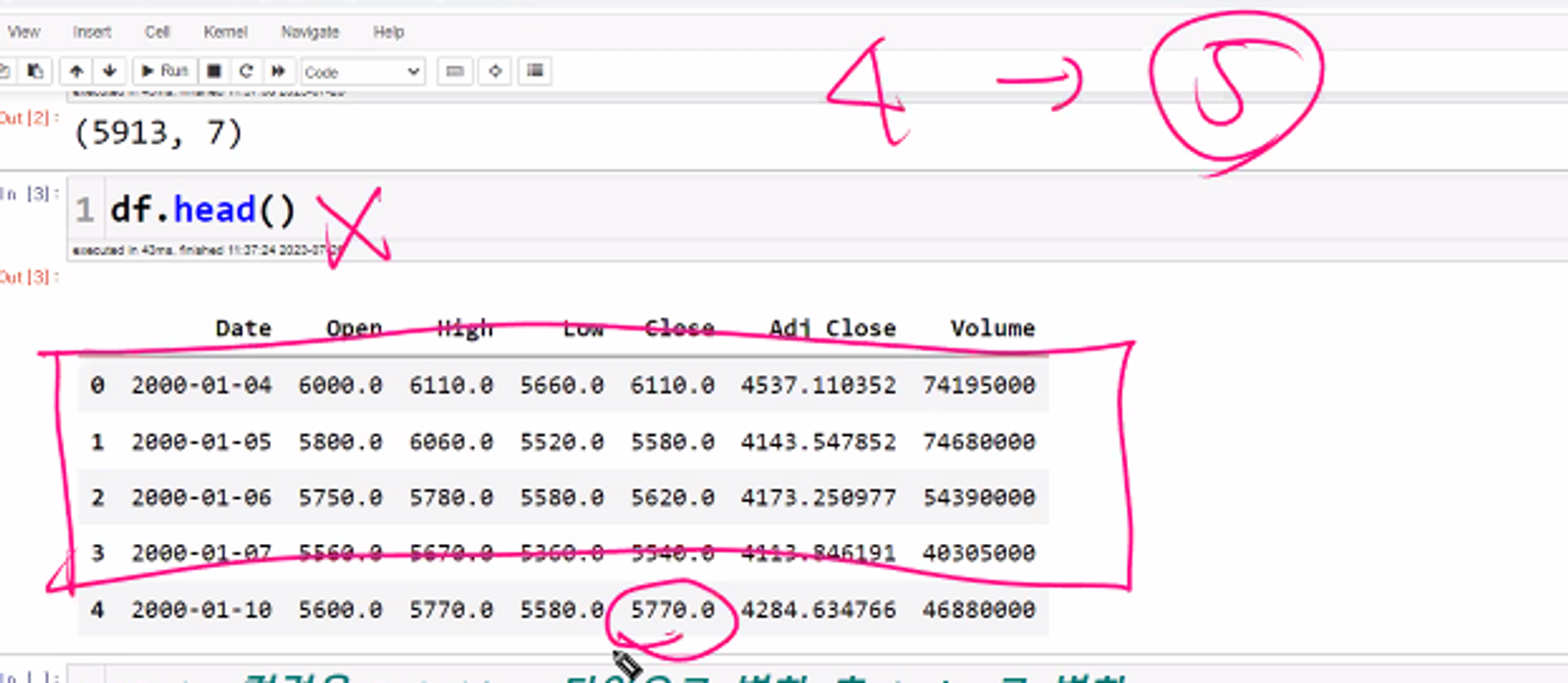
df = pd.read_csv('005930.KS.csv')
df.shape # (5913, 7)
df.head() # Volume: 거래량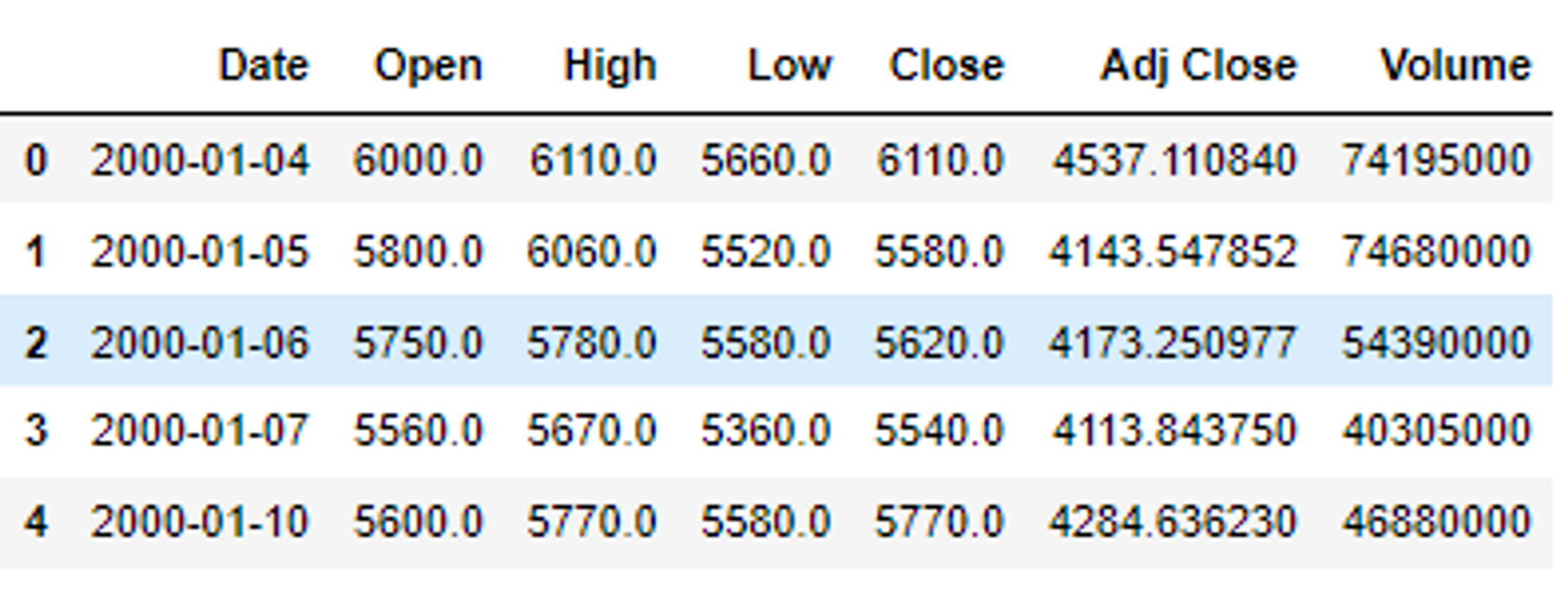
df.info() # object 타입을 Datetime타입으로 변환해야한다는 것을 알 수 있다.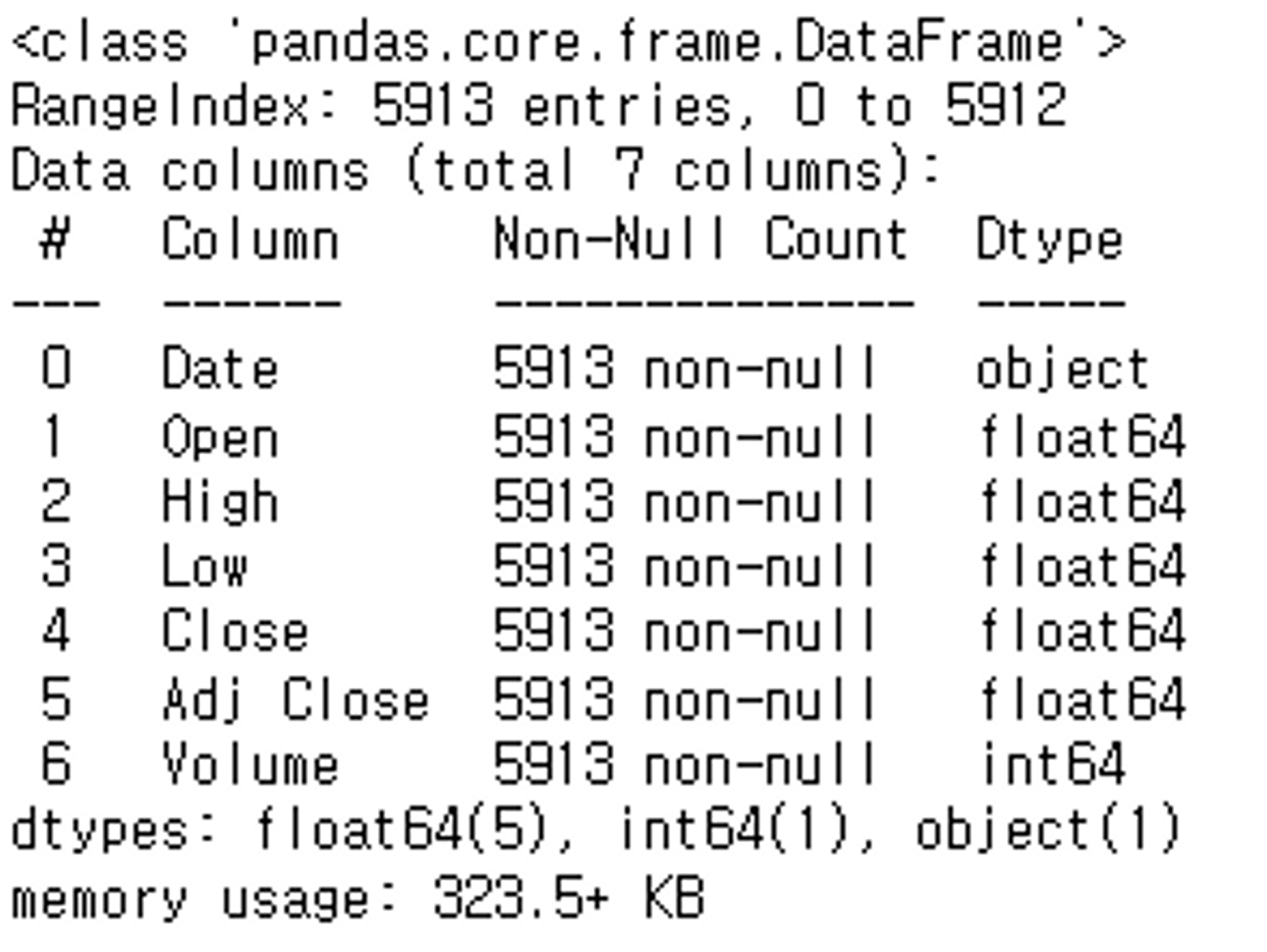
#Date 컬럼을 Datetime 타입으로 변환 후 index로 변환
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True) # Date컬럼을 행인덱스로 빼줄것이다. 왜? 굳이 필요없어서
df.head() # 다시 확인해보자. 잘 반영되었다.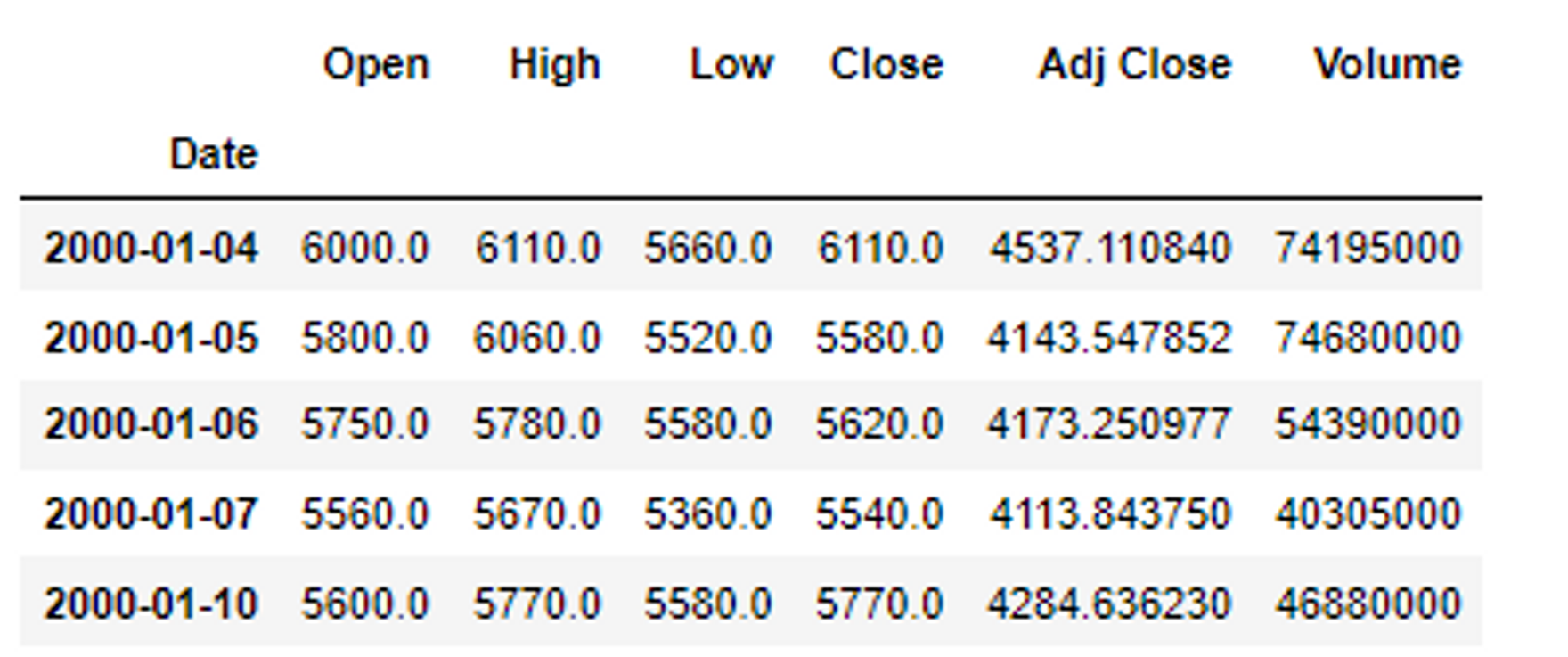
df[['Open', 'Close']].plot(figsize=(20,5), alpha=0.5)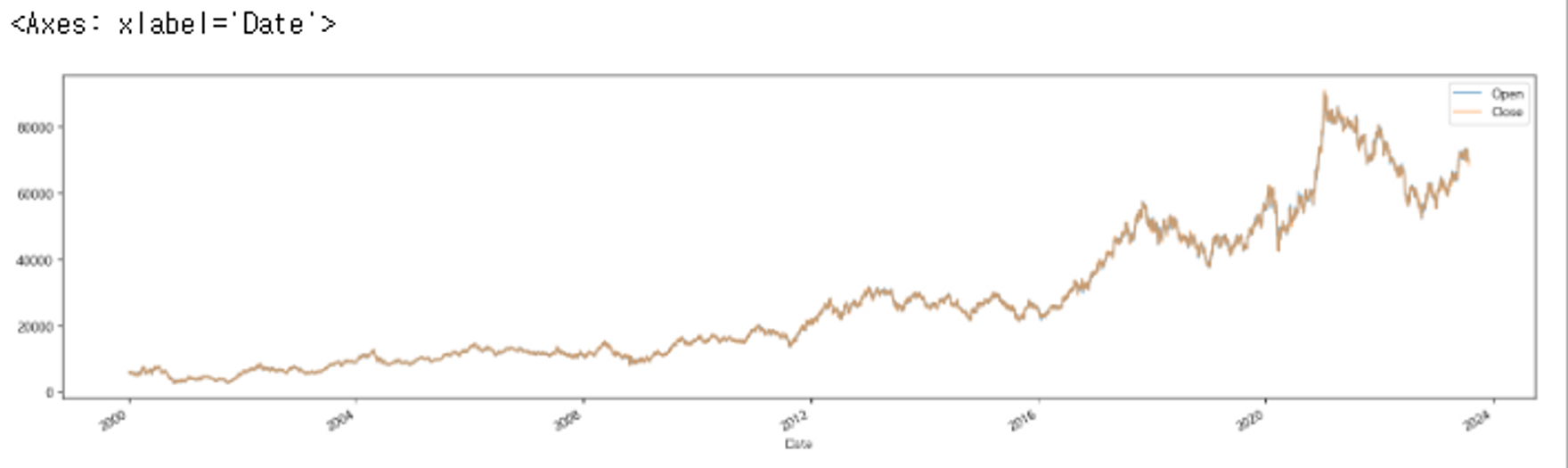
df[['Open', 'Close']].iloc[:50].plot(figsize=(20, 5), marker='*'); # iloc: 앞의 50만 보겠다.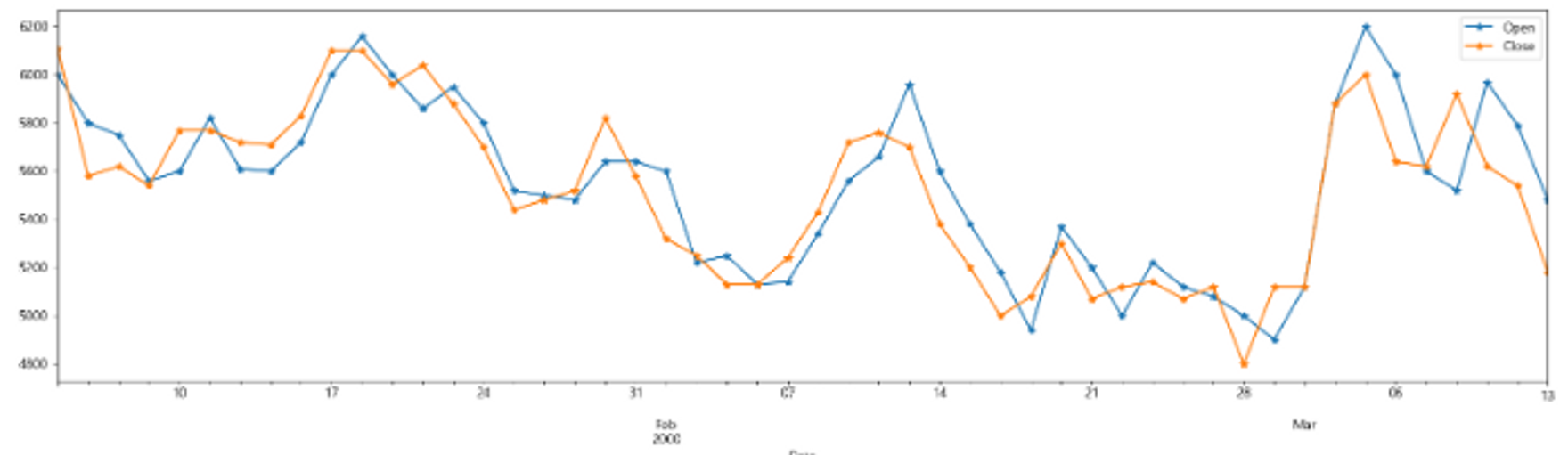
전처리
- date를 index
- 결측치 제거
- Adj Close 컬럼 제거
- MinMaxScaling
df.drop(columns=['Adj Close'], inplace=True) # Adj Close 컬럼 제거
df.head()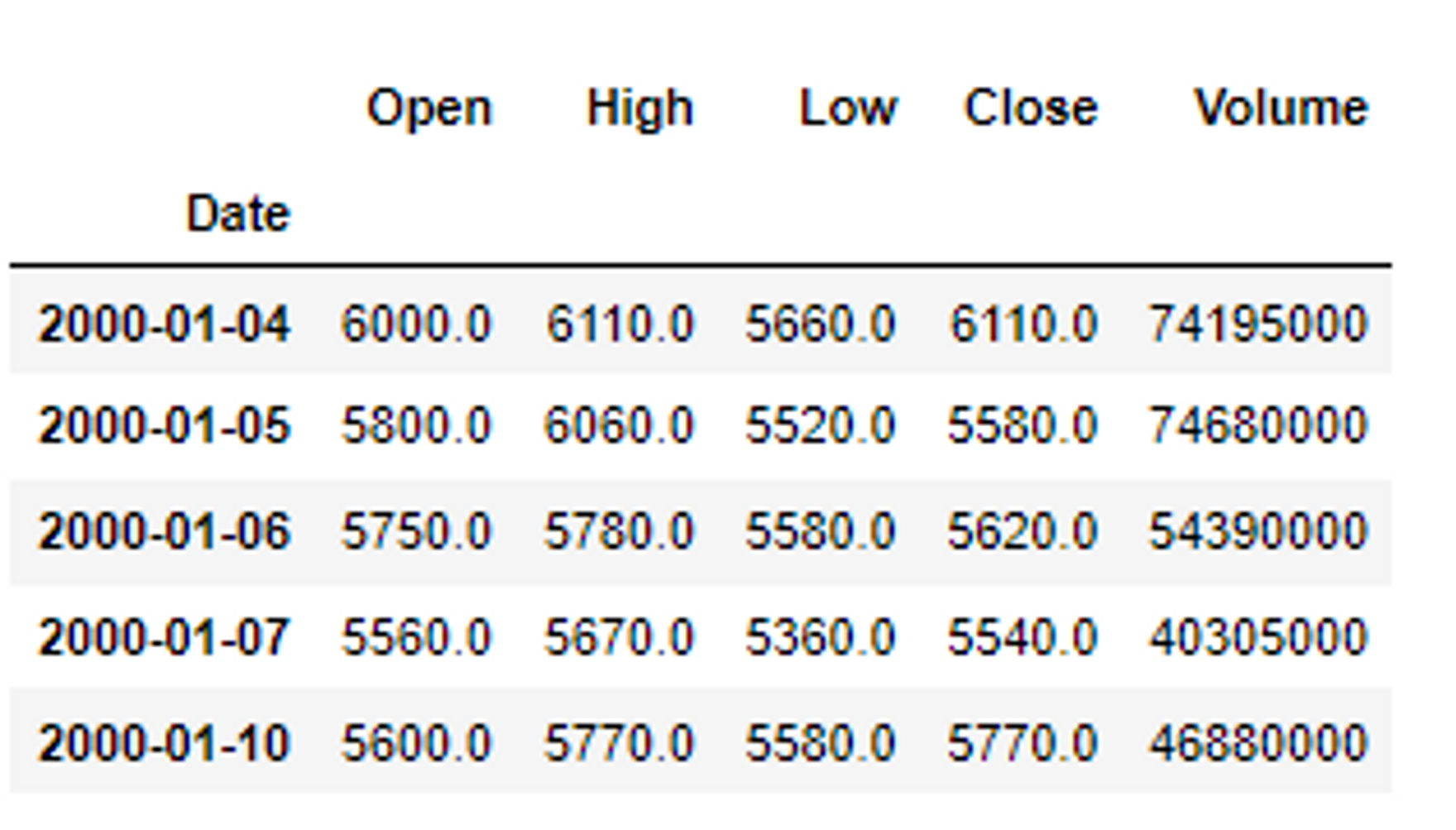
⇒ 입력값이 5개이니 weight도 5개이다.
X, y 분리
df_y = df['Close'].to_frame() # Series.to_frame(): Series를 DateFrame으로 변환(1차원->2차원 구조)
df_x = dfScaling - MinMaxScaler
- Scaler를 X, y 용 따로 만든다.
- y를 inverse 하기 위해
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
y_scaler = MinMaxScaler()
X = scaler.fit_transform(df_x)
y = y_scaler.fit_transform(df_y)
X.shape, y.shape # ((5913, 5), (5913, 1))전처리 후 이제 묶어주기!
연속된 날짜를 지정
연속된 날짜가 5인 경우
day1~day5의 데이터를 보고 day6를 예측하도록
한칸씩한칸씩 움직이면서 예측하도록한 것이다.
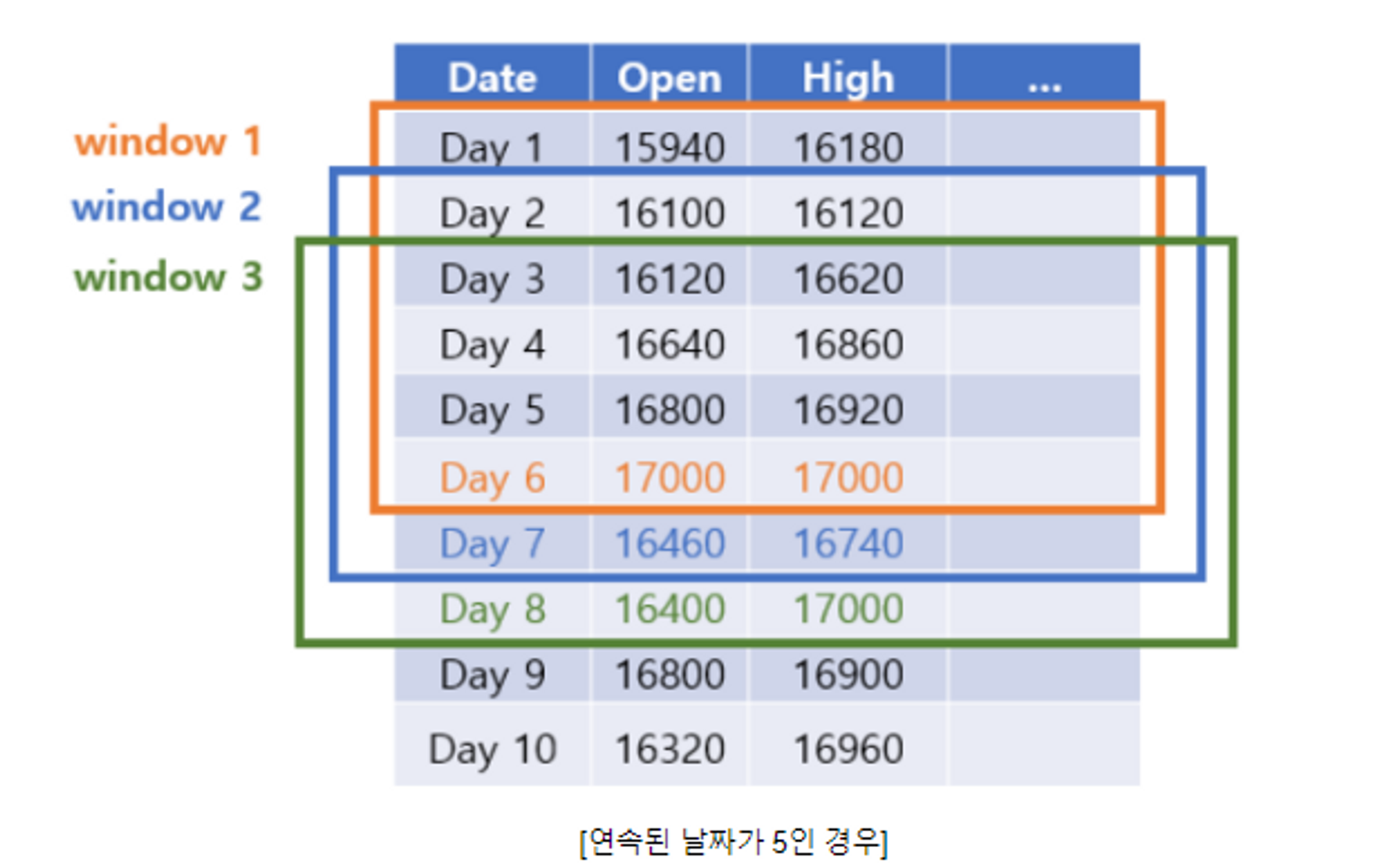
⇒ 이런 방식을 사용해 우리는 연속된 날짜를 50으로 해서 한칸씩 움직이면서 예측하도록 한다는 것이다.
window_size = 50 # 몇일 치를 한 단위로 묶을지 설정(50일치)
data_x = [] # input data들을 저장할 리스트 ex) [[1-50],[2,51,[3,52], ...]
data_y = [] # output data를 저장할 리스트 / 예측된 값인 [[51],[52],[53]]의 close 가격
# y.size - 50
for i in range(0, y.size - window_size): # windowsize +1개의 행(x: window_sizw행, y:1행)이 확보될때까지 반복문을 실행.
# 뒤로갈수록 windowsize를 반복시 예측될 close가 없을 수 있으므로
_X = X[i:i+window_size] # 처음에는 [0:50]-0~49까지 반복 / [1:51] - 1~50까지 반복
_y = y[i+window_size] # 50 / 51
data_x.append(_X)
data_y.append(_y)
np.shape(data_x) # (5863, 50, 5)
np.shape(data_y) # (5863, 1)Train, Test 분리
Train : 8, Test: 2의 비율로 나눈다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_x, data_y,
test_size=0.2,
random_state=0)
type(X_train) # list
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
type(X_train) # numpy.ndarrayimport
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers하이퍼파라미터 정의
LEARNING_RATE = 0.001
N_EPOCH = 100 # 우선 10 로 실행해봄
N_BATCH = 200Dataset 생성
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))\
.shuffle(X_train.shape[0])\
.batch(N_BATCH, drop_remainder=True)
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(N_BATCH)모델 생성, 컴파일
def get_model():
model = keras.Sequential()
model.add(layers.InputLayer(input_shape=(window_size, 5)))
model.add(layers.LSTM(32, return_sequences=False, activation='tanh')) # 32가지의 특성을 찾아봐
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=keras.optimizers.Adam(LEARNING_RATE), loss='mse')
return modelmodel = get_model()
model.summary()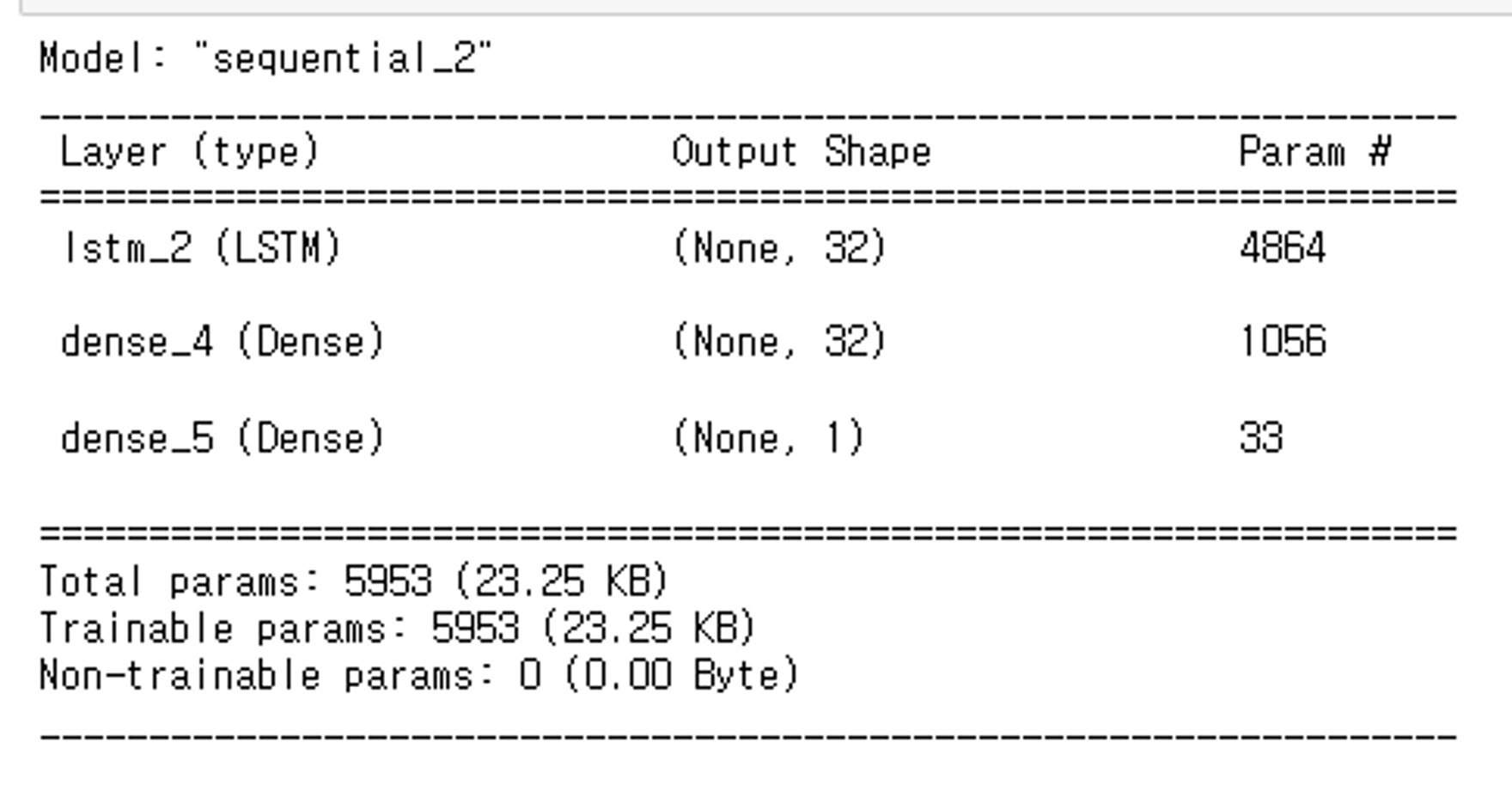
모델 학습, 평가
hist = model.fit(train_dataset,
epochs=N_EPOCH,
validation_data=test_dataset)
결과 시각화
plt.plot(hist.epoch, hist.history['loss'])
plt.plot(hist.epoch, hist.history['val_loss']);
plt.ylim(0,0.001)
plt.show()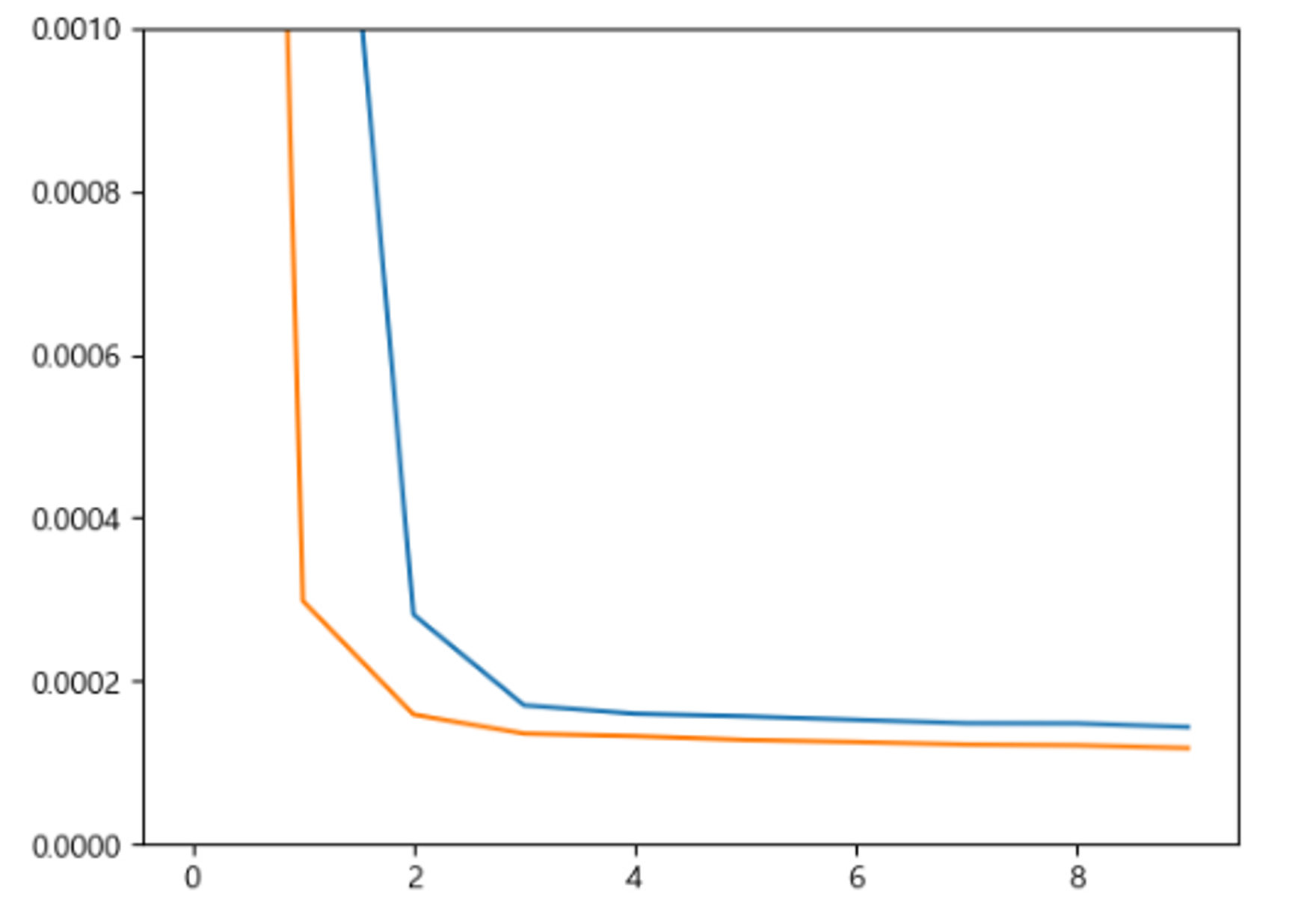
*최종평가*
model.evaluate(test_dataset)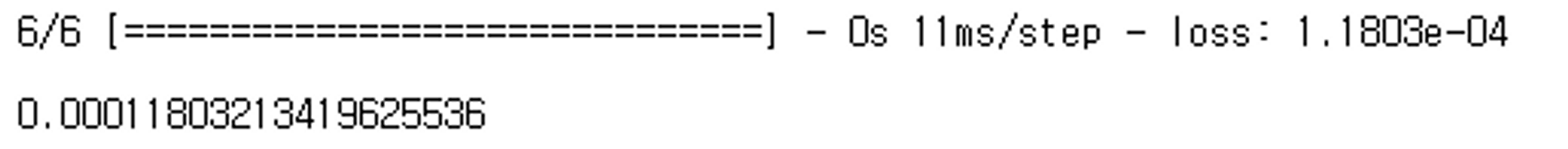
다음날 주가 예측
- 마지막 50일치로 내일 주가를 예측해 본다.
X[-50].shape # (5,)
X[-50:][np.newaxis, ...].shape # (1, 50, 5)
pred = model.predict(new_data) # 1/1 [==============================] - 0s 397ms/step
pred # minmax scaling # array([[0.7722465]], dtype=float32)
y_scaler.inverse_transform(pred) # array([[70896.195]], dtype=float32)GAN (Generative Adversarial Network-생성적 적대 신경망)
- Generative (생성적)
- GAN은 생성모델임. 생성모델이란 그럴듯한 가짜를 만들어내는 모델을 말한다.
- 그럴듯하단의 수학적 의미: 실제 데이터의 분포와 비슷한 분포를 가지는 데이터
- 두 개의 신경망, 즉 생성자(Generator)와 판별자(Discriminator)가 서로 대립적으로 학습하는 모델이다.
- 생성자 (Generator):
- 생성자는 랜덤 노이즈 벡터나 난수를 입력으로 받아 실제와 같은 가짜 데이터를 생성하는 역할을 합니다. 생성자의 목표는 실제 데이터와 구분할 수 없는 고품질의 가짜 데이터를 만들어내는 것이다.
- 판별자 (Discriminator):
- 판별자는 입력으로 실제 데이터와 생성자가 생성한 가짜 데이터를 받아 이 둘을 구분하는 역할을 합니다. 판별자의 목표는 실제 데이터와 가짜 데이터를 올바르게 분류하는 것이다.
- 생성자 (Generator):
Generator와 Discriminator 네트워크
- Generator
- 입력: 랜덤한 숫자로 구성된 벡터(잡음)
- 출력: 최대한 진짜 처럼 보이는 가짜 샘플
- 목표: 훈련 데이터셋에 있는 샘플과 구별이 불가능한 가짜 샘플만들기
- Discriminator
- 입력
- 훈련데이터셋에 있는 진짜 샘플
- Generator가 생성한 가짜 샘플
- 출력: 입력 샘플이 진짜일 예측 확률
- 목표: 생성자가 만든 가짜 샘플과 훈련 데이터셋의 진짜 샘플을 구별하기
- 입력
- Generator 학습시키는것이 주 목적이고 Generator을 학습시키기위해서 Discriminator을 학습시키는 것이다.
훈련
생성자생성후 판별자가 학습 시 분류 오차가 크면 가짜오차를 발견하지 못한것이다. 분류오차가 작을 수록 가짜 샘플을 잘 판별한 것이다.
⇒ 오차 역전파를 이용해 판별자를 업데이트한다.
- 가짜입력: 이건 가까야!라고 판단하기
⇒ 생성자를 생성 후 판별자가 학습시 분류오차가 0이라면 내가 만든 가짜 샘플을 너무 잘 판별한것이다. 분류오차가 높을 수록 가짜샘플을 잘 생성한것이다.
⇒ 생성자업데이트는 생성자가 한다.
- 가짜입력: 이건 진짜야!라고 판단하기
다음으로는 GAN의 기본 구조에 딥러닝의 기술인 합성곱 신경망(Convolutional Neural Network, CNN)을 적용한 GAN에 대하여 알아볼 것인데 그전에 Down sampling과 Up sampling에 대하여 먼저 알아보자.
Down sampling과 Up sampling
- 다운샘플링(Down Sampling)과 업샘플링(Up Sampling)은 주로 이미지나 음성과 같은 다양한 데이터의 크기를 조정하는데 사용되는 기법
- 다운샘플링 (Down Sampling):
- 다운샘플링은 데이터의 크기를 줄이는 과정을 말한다. 특히 이미지에서는 이미지의 해상도를 줄이거나 픽셀을 합치는 방식으로 다운샘플링을 수행한다. 이를 통해 이미지의 크기를 줄이고, 계산량을 줄이며, 불필요한 정보를 제거한다. 주로 Max Pooling과 Average Pooling이 다운샘플링에 사용되며, 일반적으로 CNN(Convolutional Neural Network)에서 사용한다.
- Max Pooling: 주어진 영역에서 최대값만 선택하여 다운샘플링한다. 특징 맵의 크기를 줄이면서 중요한 특징을 강조하는 효과가 있다.
- Average Pooling: 주어진 영역의 평균값을 선택하여 다운샘플링한다. 특징 맵의 크기를 줄이면서 노이즈를 감소시키는 효과가 있다.
- 업샘플링 (Up Sampling):
- 업샘플링은 데이터의 크기를 늘리는 과정을 말합니다. 이미지에서는 이미지의 해상도를 늘리거나 픽셀을 쪼개는 방식으로 업샘플링을 수행한다. 이를 통해 이미지의 크기를 늘리고, 더 자세한 정보를 얻을 수 있다.
- tensorflow.keras.layers.UpSampling2D 사용
- 하이퍼파라미터
- size=(2,2) : 입력을 몇배로 크게 만들지 지정
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
X = np.arange(1, 5).reshape(1, 2, 2, 1)
X.shape
# interpolation='nearest' : default, 'bilinear' 두가지 방식 제공
model = keras.Sequential()
model.add(layers.UpSampling2D(size=2, input_shape=(2,2,1)))
model.summary() # (1, 2, 2, 1)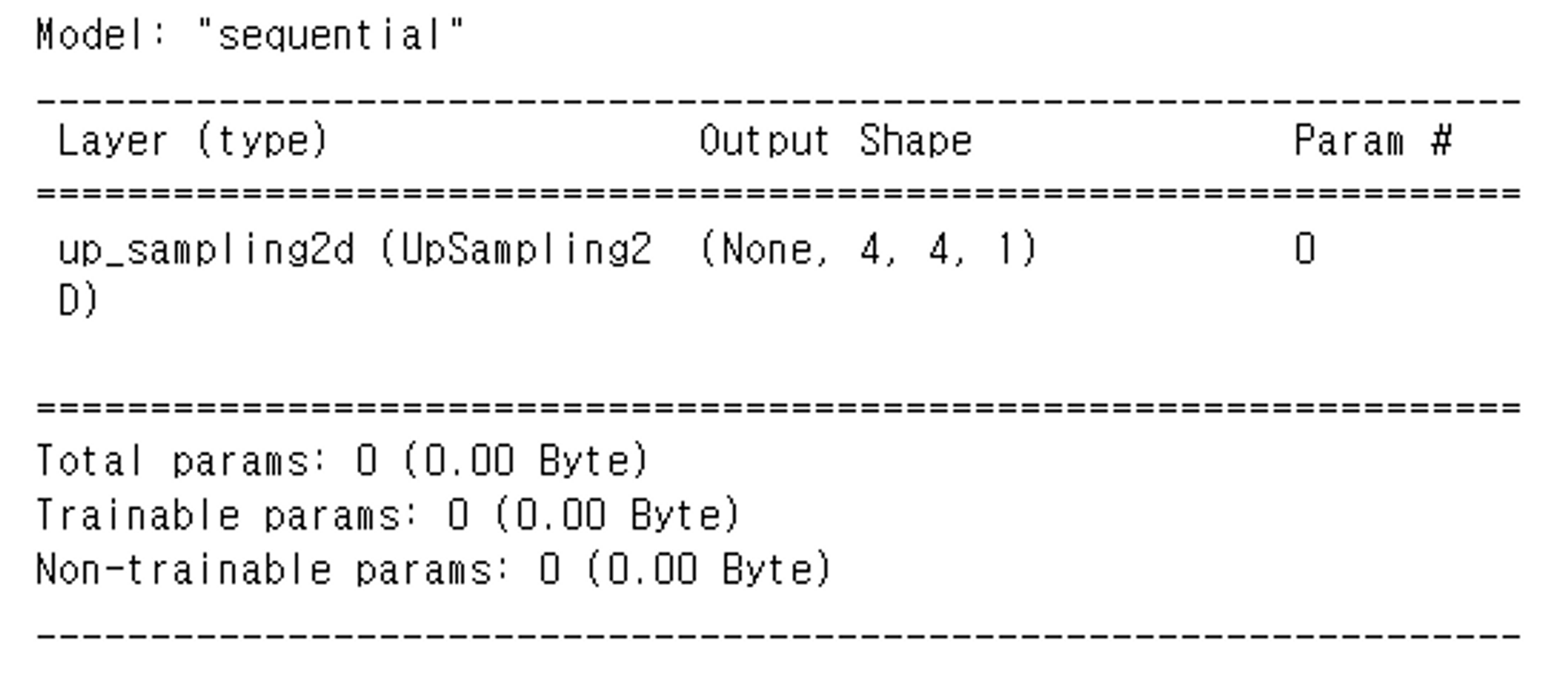
X_up = model.predict(X)
X_up.shape, X.shape # ((1, 4, 4, 1), (1, 2, 2, 1))
X_up.squeeze()
# interpolation='nearest' : default, 'bilinear' 두가지 방식 제공
model = keras.Sequential()
# 'bilinear'은 선형 보간법의 일종으로, 주어진 4개의 가장 가까운 픽셀 값을 사용하여 새로운 픽셀 값을 추정하는 방법
# 업샘플링할 때 이미지의 픽셀 값을 채우는데, 이웃하는 4개의 픽셀 값으로부터 새로운 픽셀 값을 계산하는 방식이기 때문에 비교적 계산량이 작으면서도 자연스러운 이미지를 얻을 수 있다.
model.add(layers.UpSampling2D(size=5, interpolation='bilinear', input_shape=(2,2,1)))
model.summary()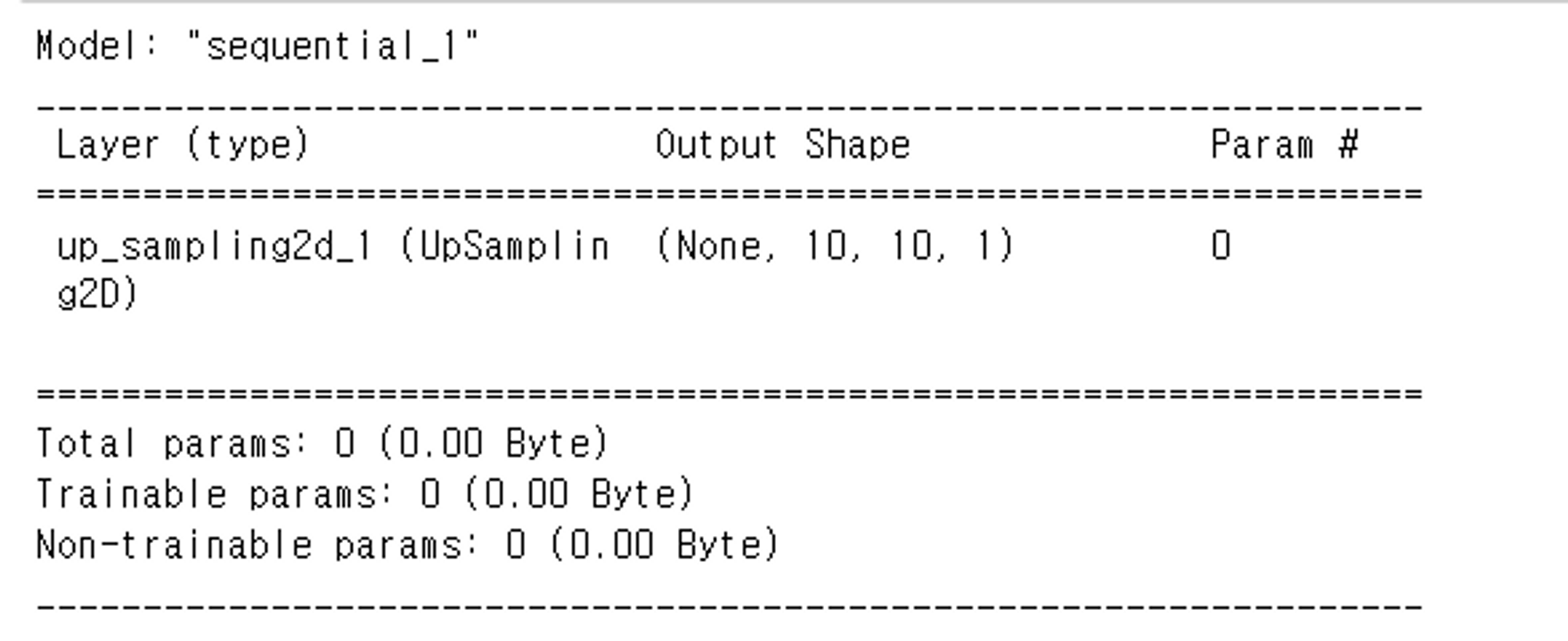
X_up = model.predict(X)
X_up.shape, X.shape # ((1, 10, 10, 1), (1, 2, 2, 1))
X_up.squeeze()
Transpose Convolution
- Transpose Convolution(전치 합성곱), 또는 Deconvolution(역 합성곱)은 Convolution의 반대 개념으로 작동하는 연산이다. Convolution이 입력 데이터에 필터를 적용하여 특성 맵(feature map)을 생성하는 것과 달리, Transpose Convolution은 특성 맵을 입력 데이터로부터 복원하여 더 큰 공간 크기의 출력을 얻는 것을 목표로 한다.
- Transpose Convolution은 주로 이미지 분할(segmentation), 이미지 생성(generative image modeling) 등에서 사용 ⇒ 예를 들어, 이미지 분할에서는 Convolutional Neural Network (CNN)을 통해 이미지의 특성을 추출하고, 이후 Transpose Convolution을 통해 추출된 특성을 원래 이미지 크기로 확장하여 픽셀별로 클래스를 예측하는데 사용
- Convolution과 유사한 방식으로 작동하지만, 패딩(padding)의 개념이 반대로 적용되고, stride 대신 stride의 역수를 사용하여 공간 크기를 확장한다. 이로 인해 출력 특성 맵의 크기가 더 크게 되며, 이 때문에 "역 합성곱"이라는 이름이 붙었다. 이 과정에서 입력 데이터 사이의 공간적 상관 관계를 보존하면서 특성을 업샘플링하는 효과를 얻을 수 있다.
- Transpose Convolution은 CNN 모델의 역전파(backpropagation) 과정에서도 사용되어 학습 가능한 파라미터(가중치)를 업데이트하는 데에도 활용한다. 따라서 CNN 모델에서 특성 맵의 공간 크기를 조정하는데 유용한 기법으로 자주 사용된다.
- tensorflow.keras.layers.Conv2DTranspose 를 이용
- padding을 same으로 하고 strides로 크기를 정한다.
- size가 strides로 지정한 배수 만큼 늘어난다.
model = keras.Sequential()
model.add(layers.Conv2DTranspose(kernel_size=3, filters=12, strides=2, padding='same', input_shape=(2,2,1)))
X_up2 = model.predict(X)
X.shape, X_up2.shape # ((1, 2, 2, 1), (1, 4, 4, 12))
X_up2[0]
DCGAN
- DCGAN은 GAN의 기본 구조에 딥러닝의 기술인 합성곱 신경망(Convolutional Neural Network, CNN)을 적용한 것
- DCGAN의 특징과 주요 구성 요소
- 생성자(Generator): 랜덤한 잡음을 입력으로 받아 실제 이미지와 유사한 가짜 이미지를 생성하는 역할을 한다. 이를 통해 진짜와 가짜를 잘 구분할 수 없는 이미지를 생성하도록 학습한다.
- 판별자(Discriminator): 입력으로 실제 이미지와 생성자가 생성한 가짜 이미지를 받아 진짜와 가짜를 판별하는 역할을 한다. 진짜 이미지에는 높은 확률을, 가짜 이미지에는 낮은 확률을 부여하도록 학습된다.
- Convolutional Layers: DCGAN은 CNN을 사용하여 생성자와 판별자를 구성한다. CNN은 이미지 처리에 효과적인 합성곱과 풀링 연산을 이용하여 이미지의 특징을 추출하는 데 사용되는 것이다.
- Batch Normalization: 배치 정규화는 학습 과정에서 각 레이어의 입력을 정규화하는 방법으로, 학습을 안정화하고 더 빠르게 수렴하도록 도와준다.
DCGAN의 안정적 학습을 위한 가이드라인
- Convolution 레이어에 Pooling Layer를 사용하지 않는다.
- 안정적 학습을 위해 BatchNormalization 사용.
- Fully Connected Layer (Dense) 를 사용하지 않는다. (Discriminator의 출력은 예외)
- Generator의 Hidden Layer에는 LeakyReLU activation을 사용하고 출력 Layer는 Tanh를 사용.
- Discriminator의 모든 Layer는 LeakyReLU activation을 사용한다. (Discriminator의 출력은 예외)
img_shape = (28, 28, 1) # 판별자의 input shape
z_dim = 100생성자
- 이미지 upsampling
- 7X7 => 14X14 => 28X28 로 키운다.
- Transpose Convolution 사용
- Conv2DTranspose
def create_generator(z_dim=100):
model = keras.Sequential()
model.add(layers.Dense(7*7*256, input_shape=(z_dim, )))
model.add(layers.Reshape((7, 7, 256)))
# image size는 두배씩 늘리고 channel은 두배씩 줄인다.
# Convolution block : Conv2DTranspose -> BatchNormalization -> Activation(LeakyReLU)
model.add(layers.Conv2DTranspose(filters=128, kernel_size=3, strides=2, padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=0.01))
# 채널만 절반으로 줄임.
model.add(layers.Conv2DTranspose(filters=64, kernel_size=3, strides=1, padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=0.01))
# size는 절반으로 늘림. 14 X 14 => 28 X 28, channle: 1 (grayscale)
model.add(layers.Conv2DTranspose(filters=1, kernel_size=3, strides=2, padding='same'))
model.add(layers.Activation("tanh"))
return model판별자
- 28 X 28 input => 14 X 14 => 7 X 7 => 3 X 3으로 절반씩 down sampling
def create_discriminator(img_shape):
model = keras.Sequential()
# pooling layer를 사용하지 않고 stride를 이용해서 size를 줄인다.
# size를 절반씩 줄여나간다. filter(channel)는 32->64->128 늘린다.
model.add(layers.Conv2D(filters=32, kernel_size=3, strides=2, padding='same',
input_shape=img_shape))
model.add(layers.LeakyReLU(alpha=0.01))
model.add(layers.Conv2D(filters=64, kernel_size=3, strides=2,padding='same'))
model.add(layers.LeakyReLU(alpha=0.01))
model.add(layers.Conv2D(filters=128, kernel_size=3, strides=2,padding='same'))
model.add(layers.LeakyReLU(alpha=0.01))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid')) # 출력: 이진분류 - 0:fake, 1:real
return modelLeakyReLU란
- LeakyReLU(Leaky Rectified Linear Unit)는 Rectified Linear Unit (ReLU) 함수의 변형이다.
- ReLU 함수는 입력값이 양수인 경우에는 그 값을 그대로 출력하고, 음수인 경우에는 0을 출력하는 함수이다. → 이러한 특성으로 인해 ReLU 함수는 비선형 활성화 함수로서 신경망에서 많이 사용되는데, 학습이 빠르고 계산이 효율적이라는 장점이 있다.
- LeakyReLU는 ReLU 함수의 변형으로서, 입력값이 음수일 때도 작은 기울기를 갖는 선형 함수를 사용
- LeakyReLU의 수식
- f(x) = x (x >= 0)
f(x) = ax (x < 0) - a는 0보다 크고 1보다 작은 작은 양수 값
- f(x) = x (x >= 0)
⇒ GAN(Generative Adversarial Networks)과 같이 비선형성을 강조하는 모델에서 LeakyReLU를 사용하여 좀 더 안정적인 학습을 도모하는 경우가 많다.
GAN 모델
- 생성자 + 판별자
def create_gan(generator, discriminator):
model = keras.Sequential()
model.add(generator)
model.add(discriminator)
return model모델 생성 및 컴파일
# 판별자 생성 + 컴파일
discriminator = create_discriminator(img_shape) #(28, 28, 1)
discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 생성자 생성
generator = create_generator(z_dim)
discriminator.trainable=False # GAN 모델의 discriminator(layer)를 Frozen(학습할때 weight가 update되지 않게함.)
# GAN 모델 생성
gan = create_gan(generator, discriminator)
gan.compile(optimizer='adam', loss='binary_crossentropy')훈련
import matplotlib.pyplot as plt
def sample_images(generator, image_grid_row=4, image_grid_col=4):
"""
Generator를 이용해 가짜 이미지를 생성해 그리는 함수.
그리드 행, 열의 개수를 받아 행 * 열 개수만큼 그린다.
[매개변수]
generator: Generator 모델
image_grid_rows: 이미지를 그릴 grid 행수 (기본값 : 4)
image_grid_columns: 이미지를 그릴 grid 열수(기본값 : 4)
"""
z = np.random.normal(0, 1, (image_grid_row*image_grid_col, z_dim))
gen_images = generator.predict(z)
plt.figure(figsize=(7,7))
for i in range(image_grid_row * image_grid_col):
plt.subplot(image_grid_row, image_grid_col, i+1)
plt.imshow(gen_images[i, :, :, 0], cmap='gray')
plt.axis('off')
plt.show()
sample_images(generator)
**training 함수**
loss_list = [] # step 별 loss를 저장할 리스트
acc_list = [] # step 별 acc를 저장할 리스트
iteration_list = [] # loss, acc를 저장할 step 수를 저장할 리스트
def train(train_image, iterations, batch_size, sample_interval):
"""
[parameter]
train_image: 진짜 이미지데이터셋
iterations : 총 step수
batch_size : batch size
sample_interval: 몇 iteration당 한번씩 훈결결과를 출력/저장할지 간격
"""
train_image = train_image/127.5-1 # -1 ~ 1사이로 scaling # 전처리
train_image = train_image[..., np.newaxis] #채널 차원 증가. (28, 28) => (28, 28, 1)
# Label 생성: fake-0, real: 1
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# 학습.
for iteration in range(iterations):
#################################### 판별자 훈련
# 정답에서 추출할 이미지의 index를 random 함수를 이용해 batch 개수만큼 조회
idx = np.random.randint(0, train_image.shape[0], batch_size)
# 학습에 사용할 정답 이미지들 조회
real_imgs = train_image[idx]
# Fake image를 만들기 위해 generator에 넣어줄 잡음 생성.
z = np.random.normal(0,1, (batch_size, 100))
# Generator를 이용해 Fake image 생성
gen_imgs = generator.predict(z)
#진짜 이미지로 학습
d_loss_acc_real = discriminator.train_on_batch(real_imgs, real) # 한스텝 학습시키는 메소드
#생성자가 만든 가짜 이미지로 학습
d_loss_acc_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss, acc = np.add(d_loss_acc_real, d_loss_acc_fake)*0.5
####################################생성자 훈련 - gan을 이용해서 훈련.
z = np.random.normal(0, 1, (batch_size, 100))
gan_loss = gan.train_on_batch(z, real) # input으로 잡음과 정답을 전달
# 중간결과 확인
if iteration % sample_interval == 0:
loss_list.append((d_loss, gan_loss))
acc_list.append(acc)
iteration_list.append(iteration)
print(f'판별자 손실:{d_loss}, 판별자정확도:{acc}, gan 손실:{gan_loss}')
sample_images(generator)import time
(X_train, y_train), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
iterations = 10000
batch_size=100
sample_interval=500
start = time.time()
train(X_train, iterations, batch_size, sample_interval)
end = time.time()
print((end-start)/60, '분')
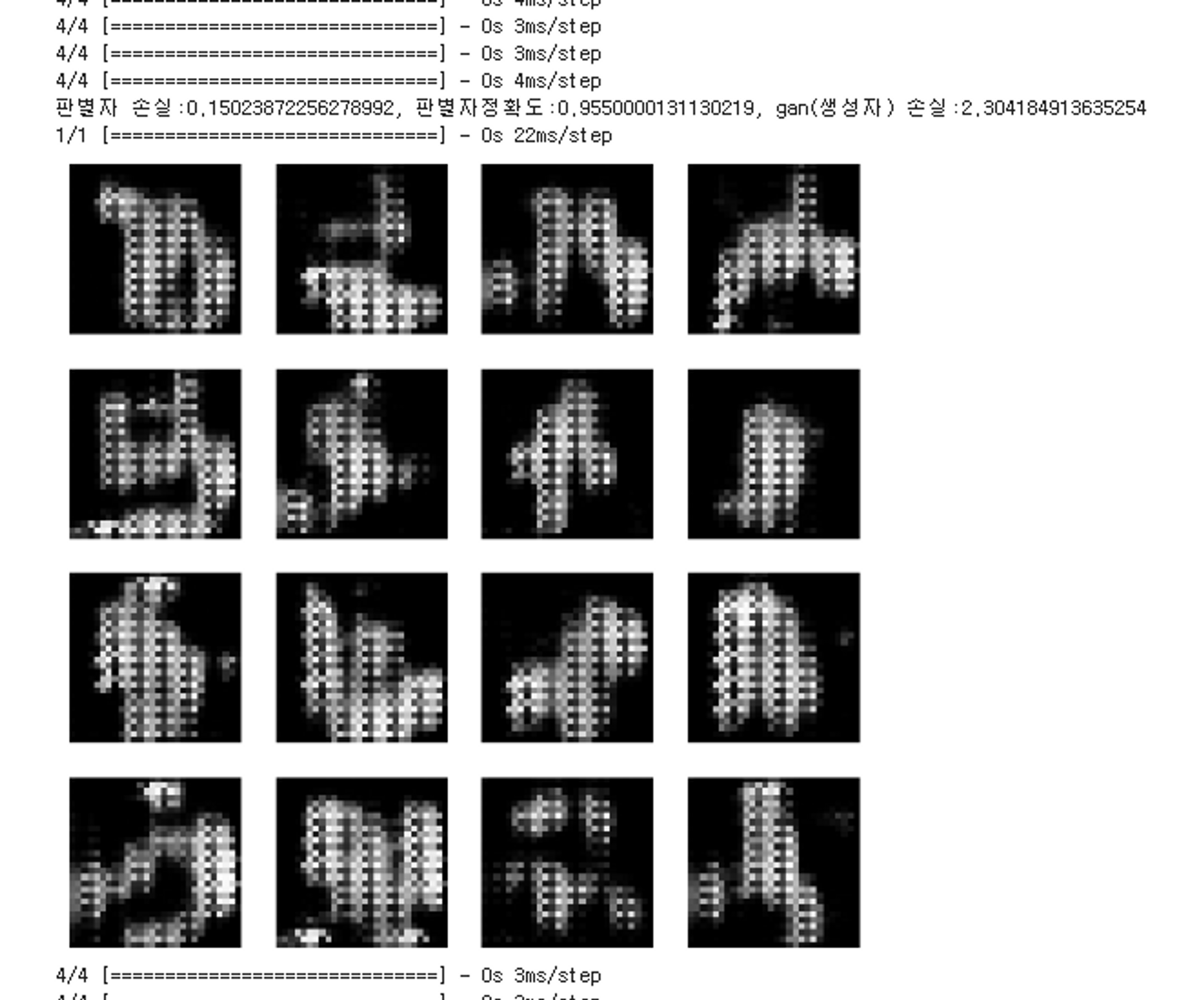

이미지 생성
import tensorflow as tf
save_path = '/content/drive/MyDrive/saved_model/fashion_mnist_gan'
saved_generator = tf.keras.models.load_model(save_path)z = np.random.normal(0, 1, (3, 100))
pred = saved_generator.predict(z)
plt.figure(figsize=(10,5))
for i in range(3):
plt.subplot(1, 3, i+1)
plt.imshow(pred[i].reshape(28,28), cmap='gray')
plt.axis('off')
plt.show()
