주요 CNN 모델
-
CNN 기반의 주요 모델들과 그 모델에 쓰인 주요 기법
- VGGNet
- ResNet
- Mobilenet
-
VGGNet(VGG16)
- 16개의 Layer을 사용한 것이다.
- 복잡한 데이터에서 특성을 많이 뽑아내기 위해 Layer을 쌓는 것은 좋은데 임계점을 넘어가면 성능이 오히려 떨어진다.
- 3 x 3 필터 두개를 쌓는 것이 5 x 5 하나를 사용하는 보다 더 적은 파라미터를 사용하며 성능이 더 좋다.
- VGG16의 단점은 마지막에 분류를 위해 Fully Connected Layer 3개를 붙여 파라미터 수가 너무 많아 졌다.
-
ResNet (Residual Networks)
- layer를 깊게 쌓으면 성능이 더 좋아지지 않을까라는 가설에서 시작하여 → layer를 깊게 쌓으면 비선형성이 더 많이 추가되어 더 많은 특성을 추출할 수 있어 성능이 더 좋아질 수 있어다.
- Trian, test set에서 성능이 나쁘게 나옴
→ Layer를 깊게 쌓으면 weight들이 더 많이 생기므로 최적화가 어려워진다.
BUT
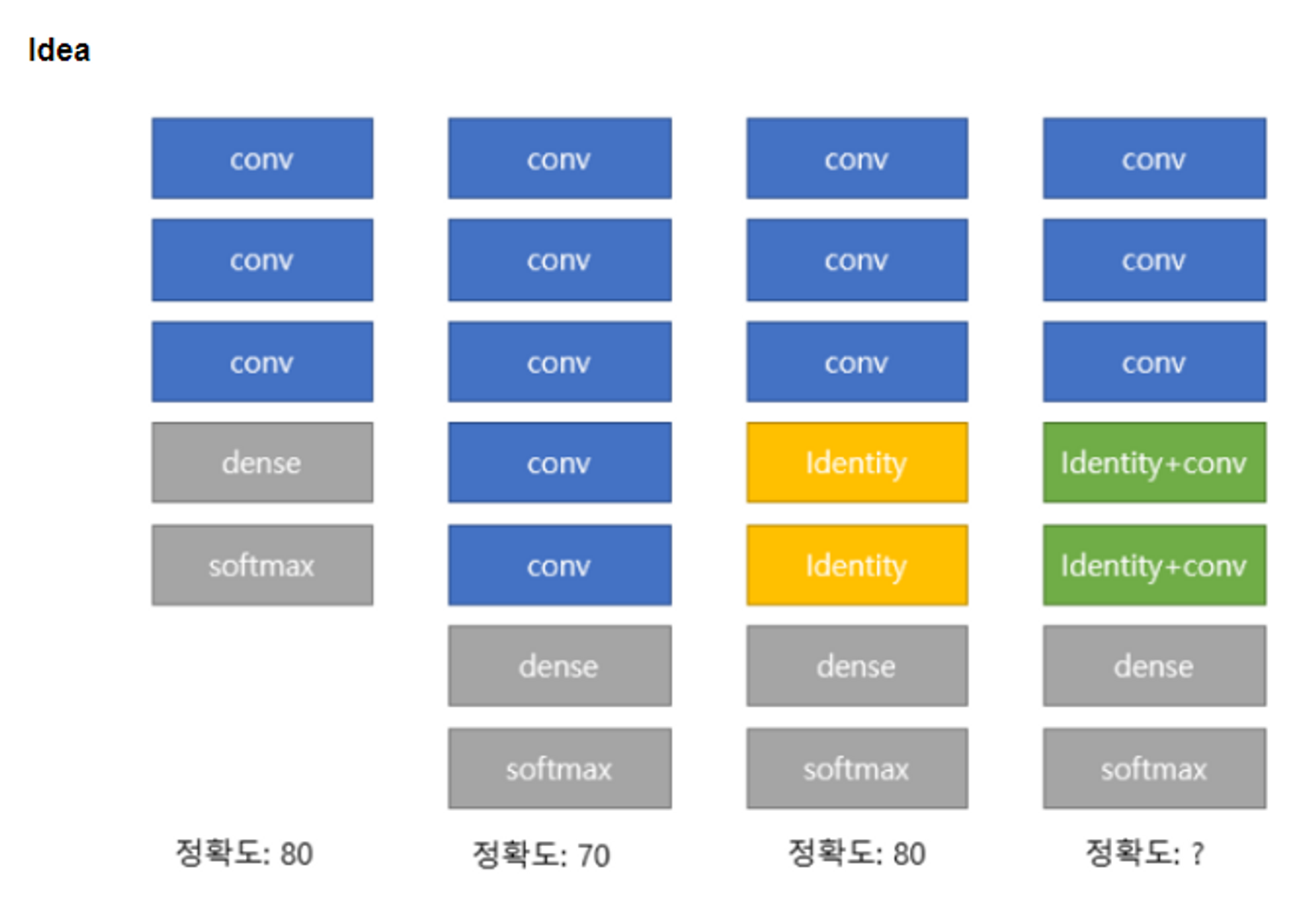
-
identity: 입력과 출력이 일정하게 한다.(ex) 10개를 입력하면 10개의 출력이 나온다.)
- ResNet은 layer를 통과해서 나온 값이 입력값과 동일하게 만드는 것을 목표로 하는 Identity block을 구성한다.
- ResNet은 매우 깊은 네트워크를 효과적으로 학습할 수 있도록 하는 주요 아이디어로 "residual block"을 도입하여 네트워크를 구성
-
MobileNet
- Google에서 개발한 경량화된 딥러닝 모델 중 하나이다.
- 모바일 기기에서도 빠르고 효율적으로 실행되도록 설계된 네트워크로, 특히 모바일 환경에서 실시간으로 이미지 분류, 객체 감지 등의 작업을 수행하는 데 적합하다.
- 저성능 컴퓨팅 환경에서 실행할 수 있도록 하기 위해 딥러닝 네트워크를 가볍게 구성하는 (경량 네트워크-Small Deep Neural Network) 방법
- MobileNet은 두 가지 기법을 사용해서 가벼운 모델을 만는다.
- 첫 번째는 Depthwise Separable Convolution이라는 방법입니다.
- 이 방법은 하나의 큰 계산을 여러 개의 작은 계산으로 나눠서 처리하는 것과 같다.. 이렇게 하면 모델이 적은 계산량으로도 좋은 성능을 낼 수 있다.
- 두 번째는 1x1 Convolution이라는 방법
- 이 방법은 채널의 수를 조절하거나 다양한 특성을 추출할 수 있도록 도와준다.
- 첫 번째는 Depthwise Separable Convolution이라는 방법입니다.
-
특징
- 적은 연산량(낮은 계산의 복잡도)을 통한 빠른 실행
- 작은 모델 크기
- 충분히 납득할 만한 정확도
- 저전력 사용
-
목적
- 기존의 성능만을 신경쓴 모델 보다 적은 연산량으로 빠르게 추론할 수 있으되 납득할 수 있는 성능을 내야 한다.
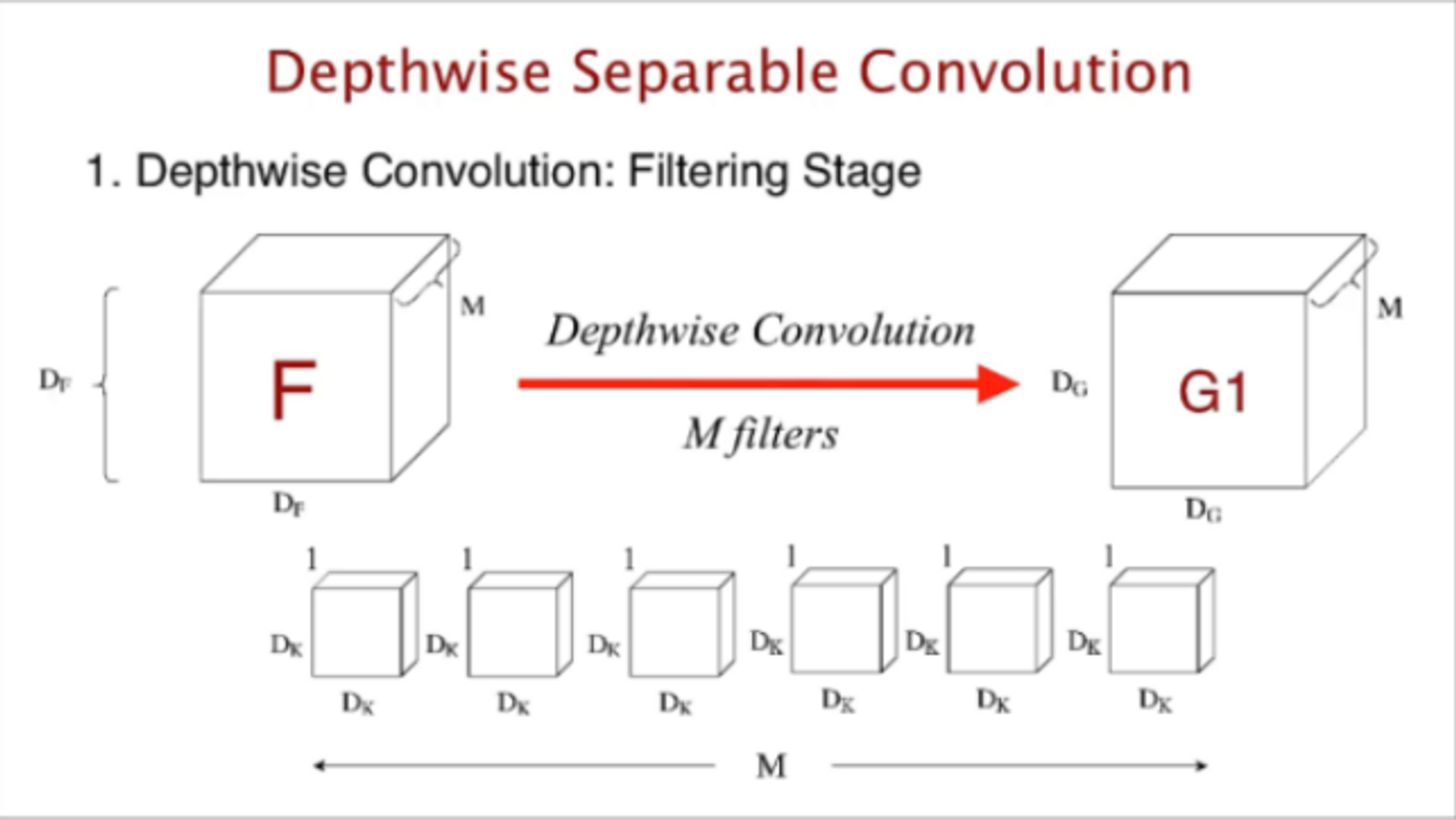
- **Depthwise Separable Convolution**
- Depthwise Convolution과 Pointwise Convolution의 조합으로 구성
- Depthwise Convolution은 입력 이미지의 각 채널에 대해 각각 따로 컨볼루션 연산을 수행한다. 따라서 입력 채널 수만큼 필터를 사용하여 특징을 추출
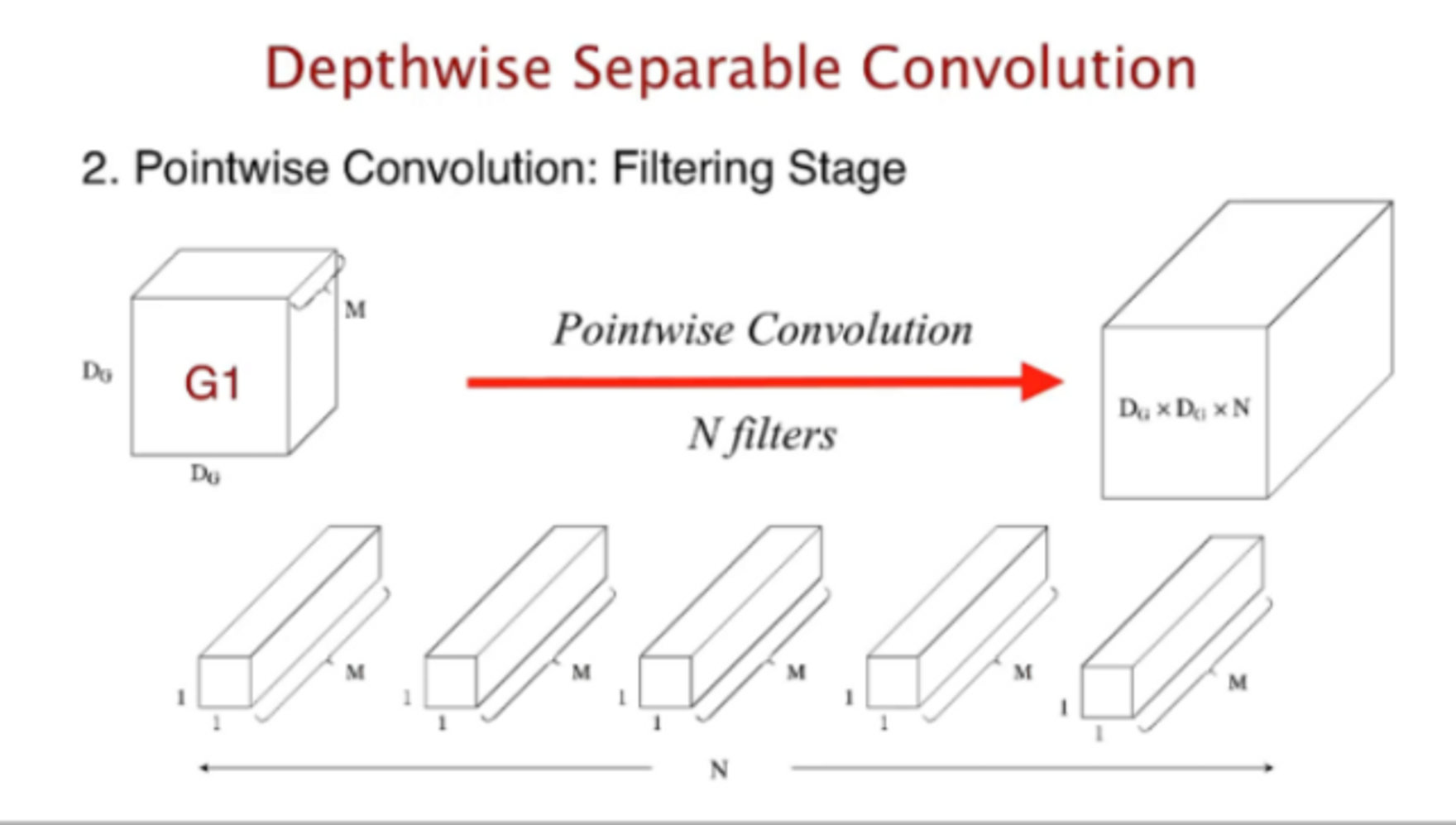
- Pointwise Convolution은 1x1 크기의 필터를 사용하여 Depthwise Convolution의 출력 채널을 조절하고, 다양한 특징을 합성하는 역할을 한다.
- Depthwise Separable Convolution은 일반적인 Convolution에 비해 훨씬 적은 파라미터 수를 사용하여 계산량을 줄이고, 경량화된 모델을 만드는데 사용
- Pointwise Convolution
- Depthwise Separable Convolution과는 달리, 단독으로 사용되는 컨볼루션 기법이다.
- 1x1 크기의 필터를 사용하여 입력 이미지의 각 채널에 대해 독립적으로 선형 변환을 수행
- 입력 이미지의 채널 수를 조절하거나, 채널 간 상호작용을 강화하는데 사용
- 채널 수를 줄여서 다양한 특징을 합성하거나, 모델의 표현력을 높이는데 효과적이다.
- 표준 Convolution과 Depthwise Separable Convolution의 연산량 비교
- 표준 Convolution의 연산량
- 표준 Convolution은 입력 이미지의 모든 채널과 필터의 모든 채널 간의 모든 위치에서 연산을 수행한다.
- 따라서 입력 채널 수와 출력 채널 수, 필터 크기에 따라 연산량이 증가한다.
- 입력 채널 수: C_in
- 출력 채널 수: C_out
- 필터 크기: F(filter의 높이와 너비)
- 입력 크기: H (높이), W (너비)
- 연산량: C_in x C_out x F x F x H x W
- Depthwise Separable Convolution의 연산량
- Depthwise Convolution은 입력 이미지의 채널 수만큼 각각 독립적인 연산을 수행 → 채널 간 상호작용이 없기 때문에 연산량이 크게 감소
- Pointwise Convolution은 1x1 크기의 필터를 사용하므로 입력 채널 수와 출력 채널 수가 크게 영향을 미치지 않는다.
- 입력 채널 수: C_in
- 출력 채널 수: C_out
- Depthwise 필터 크기: F_d (Depthwise Convolution에 사용되는 필터 크기)
- Pointwise 필터 크기: F_p (Pointwise Convolution에 사용되는 필터 크기)
- 입력 크기: H (높이), W (너비)
- 연산량: (C_in x F_d x F_d x H x W) + (C_in x C_out x F_p x F_p x H x W)
- 표준 Convolution 과 Depthwise Separable Convolution 연산량 비교
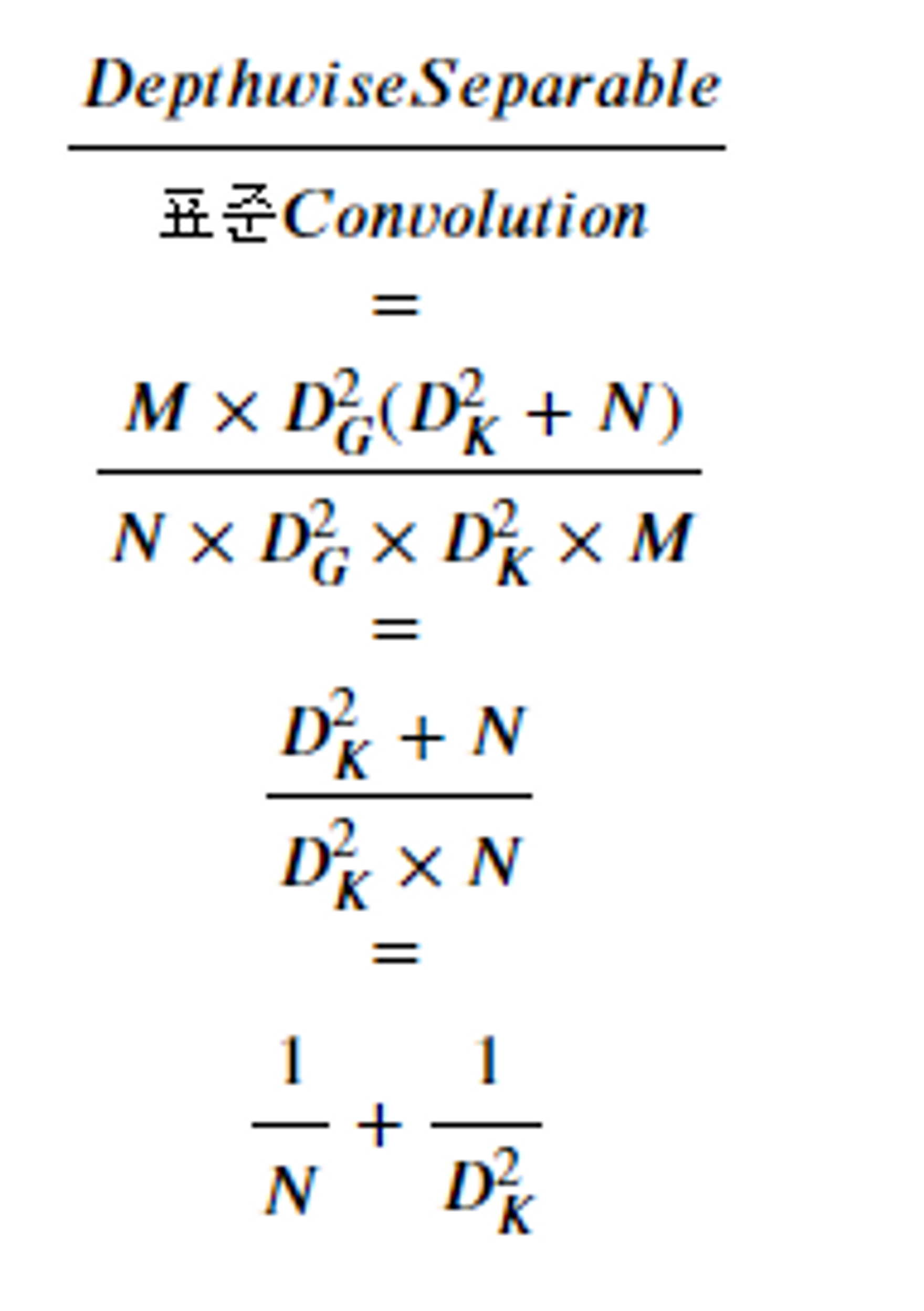

- 표준 Convolution의 연산량
result = (1/1240) + (1/3**2)
print(result) # 결과 0.1112087673611111
Hi
잘 읽었습니다. 정리가 잘 된 글이네요.