Introduction to Machine Learning in Production - Week 1
Week 1: Overview of the ML Lifecycle and Deployment
The Machine Learning Project Lifecycle
Steps of an ML Project
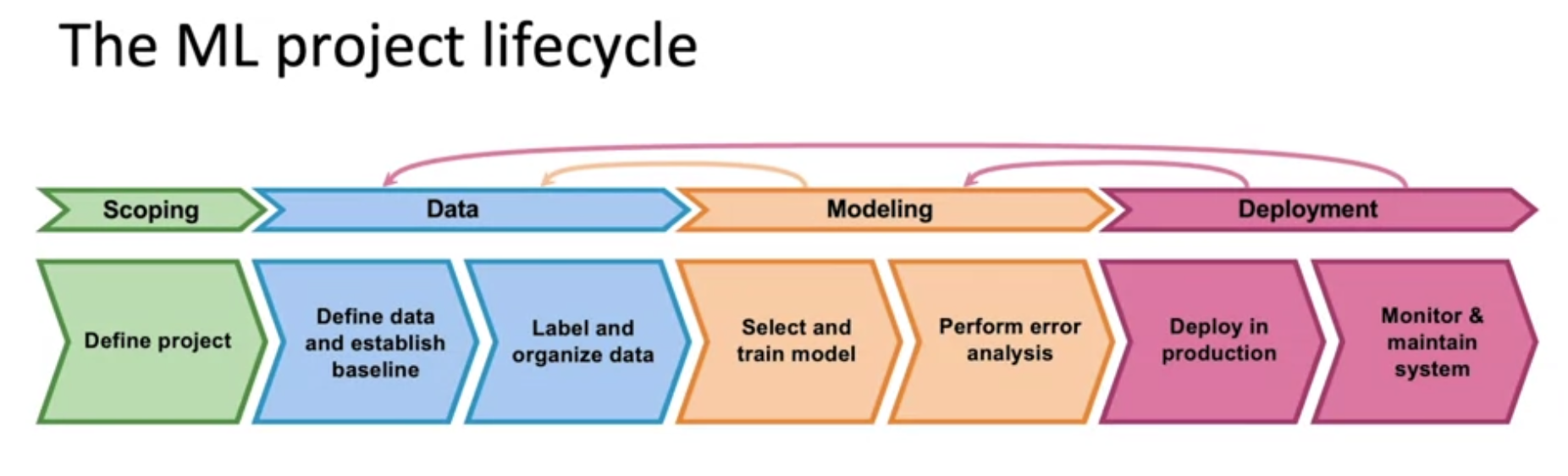
Scoping
- 프로젝트 정의 및 결정. 기계 학습을 어떤 문제에 적용할지, X(입력)와 Y(출력)가 무엇인지를 정합니다.
Data
- 알고리즘에 필요한 데이터 수집 및 데이터 정의
- 라벨링에 필요한 기준을 정하고 Label & Organize
Model Training
- 모델 선택 및 훈련, 오류 분석 수행
- ML은 오류 분석 과정에서 모델을 수정하거나 추가 데이터 수집이 필요할 수 있음
- 시스템의 성능이 충분히 좋고 신뢰할 수 있는지 최종 점검을 수행
Deploy
- Deploy는 전체 작업의 절반까지 왔다고 생각
- 시스템을 배포하고, 필요한 소프트웨어 작성, 시스템 모니터링, 데이터 추적 및 유지 관리
- 데이터 분포가 변경되면 모델을 업데이트를 할 수도 있음
- 초기 배포 후, 더 많은 오류 분석을 수행하고 모델을 재훈련
- 실시간 데이터를 사용하여 데이터셋을 업데이트하고 모델을 개선
Case study: speech recognition
- 음성인식을 ML로 해결하려고 했을때, 어떤 시스템이 필요할지에 대한 내용
Scoping
- 음성 인식에 대한 프로젝트를 정의
- 주요 지표를 추정, 정확도, 지연 시간, 처리량 등을 고려
- 리소스와 개발 시간을 예상
Data
- 데이터 정의, 기준선 설정, 라벨링 및 구성.
- 데이터의 일관된 라벨링이 중요하며, 오디오 클립을 어떻게 변환할지 결정
- 데이터 라벨링에 대한 가이드 라인, 기준이 상당히 중요하다.
- 추후 데이터를 어떻게 처리할것인지도 여기서 논의.
Modeling
- Code(algorithm / Model), Hyperparameters, 데이터가 중요
- 오류 분석을 통해 모델의 부족한 부분을 파악하고 데이터를 개선해야함.
- 연구나 학교에서는 데이터를 고정하고 다른것들을 수정
- product 환경에서는 코드를 고정하고 나머지를 수정하는게 효과적일 수 있음
Deployment
- Edge Device에 소프트웨어를 배포
- 배포된 시스템의 성능 모니터링 및 유지 관리
- 데이터 분포에 적절한 대응을 하는것이 중요함(Concept / Data Draft 에 대응)
Deployment
Key Challenges
Concept Drift & Data Drift(ML/통계적 문제)
- Concept Draft : x,y의 관계가 시간이 지남에 따라 달라짐
- Data Draft : x의 분포가 시간이 지남에 따라 달라
- 데이터의 변화는 점진적일 수도 있고 갑작스럽게 발생할 수도 있음.
- 변화하는 데이터에 대해 어떻게 대응하는지가 중요
SW Engineering 문제
- Realtime vs Batch에 대한 결정
- Cloud vs Edge/Browser에 대한 결정
- Compute resources(CPU/GPU/momory)
- Latency, Throughput(QPS)
- Logging
- Security and Privacy
Deployment patterns
Common deployment cases
- New Product/capability
- Automate/assist with manual task
- Replace previous ML system
- A/B 테스트가 중요 with monitoring(Gradual ramp up)
- 또한 Rollback에 대한 대응이 있어야함
- Shadow Mode : 사람과 ML이 같이 진행
- Canary : 점차 트랙픽을 늘림
- Blue-green : Old -> New로 바로 혹은 점진적으로 전환, 그러나 동시에 운영함으로서 롤백에 빠르게 대응
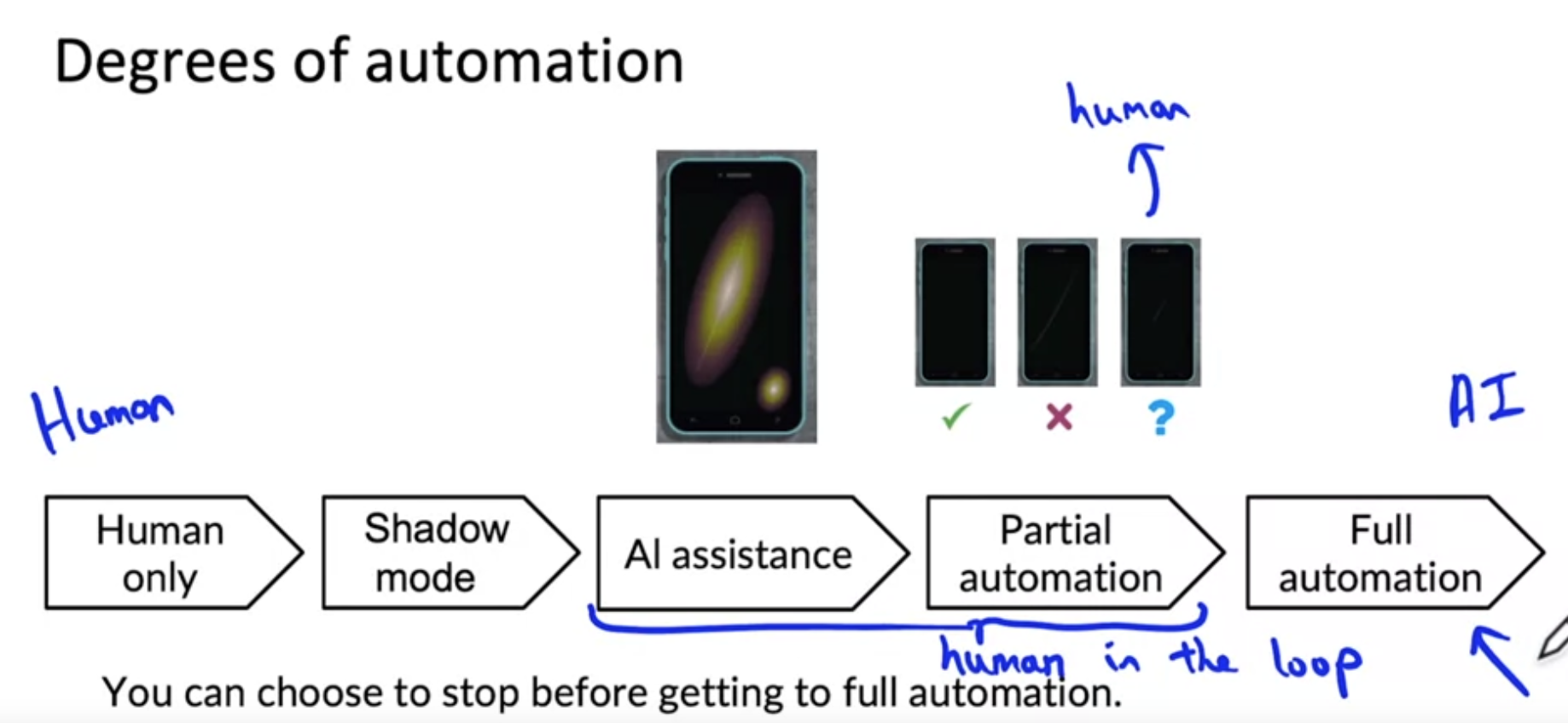
Degrees of automation
- 현재 시스템에 맞는 자동화 정도를 정하는것이 중요하다.
Monitoring
Dashboard
- 가장 일반적인 방법
- 서버의 부하나 비정상 출력이나 입력에 대한 그래프 등등
Examples of Metric to track
- Software metric
- Memory, compute, latency, throughput, server load
- Input metric
- Avg Input length
- Avg input volume
- Num missing values
- Avg image brghtness
- Output metrics
- times return null
- times user redoes search
- times user switches to typing
- CTR(Click-Though Rate)
Iterative deployment
- 모델링도 반복하듯이, 배포도 반복되어야 한다.
- 모니터링하며 실제 사용자의 데이터나 트래픽을 기반으로 선능을 분석하고 모델을 반복적으로 업데이트 해야함
- 새로운 metric을 추가하거나 기존의 metric이 쓸모 없어 질수도 있으니 metric에 대한 고찰도 계속 해야함
Alert
- Monitoring 시스템에서 특정 구간을 정하고 특정 구간을 벗어나는 데이터가 발생 할 시 알람을 주는 방식을 취해야함
Pipeline monitoring
- AI 시스템은 모델 뿐만 아니라 여러 단계의 pipeline으로 이루어짐
(ML과 무관한 단계 포함)
- 각 구성 요소의 입출력 Metric을 모니터링 하면 데이터의 변화를 좀더 효과적으로 감지 할 수 있음
참고
