Introduction to Machine Learning in Production - Week 2
Week 2: Select and Train a Model
Modeling Overview
- Model-centric AI development
- Data-Cetnric AI develpopment
- AI 뿐만 아니라 데이터에 신경 써서 학습하면 좀더 효과적인 모델을 만들 수 있음
Key Challenges
-
AI System = Code(algorithm/model) + data
-
모델의 경우 많은 발전이 있어 왔기에 데이터 개선하는데 시간을 투자하는 것이 더 효율적일 수 있음
-
그림과 같은 Iteration을 빠르게 여러번 진행할 수 있는것이 성능 향상의 핵심
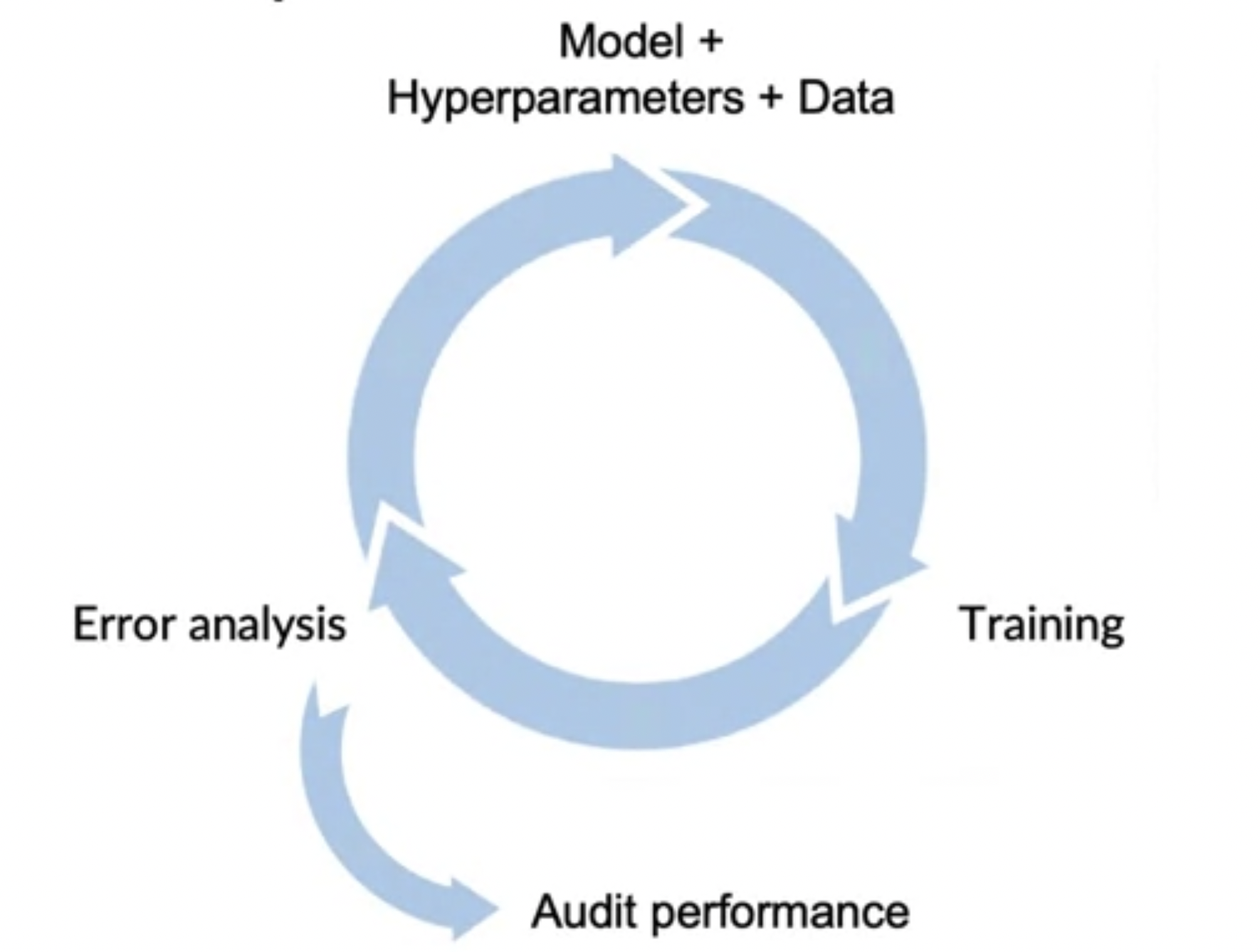
-
프로젝트가 달성하고자하는 이정표
- Doing well on training set
- Doing well on dev/test sets
- Doing Well on business metrics/project goals
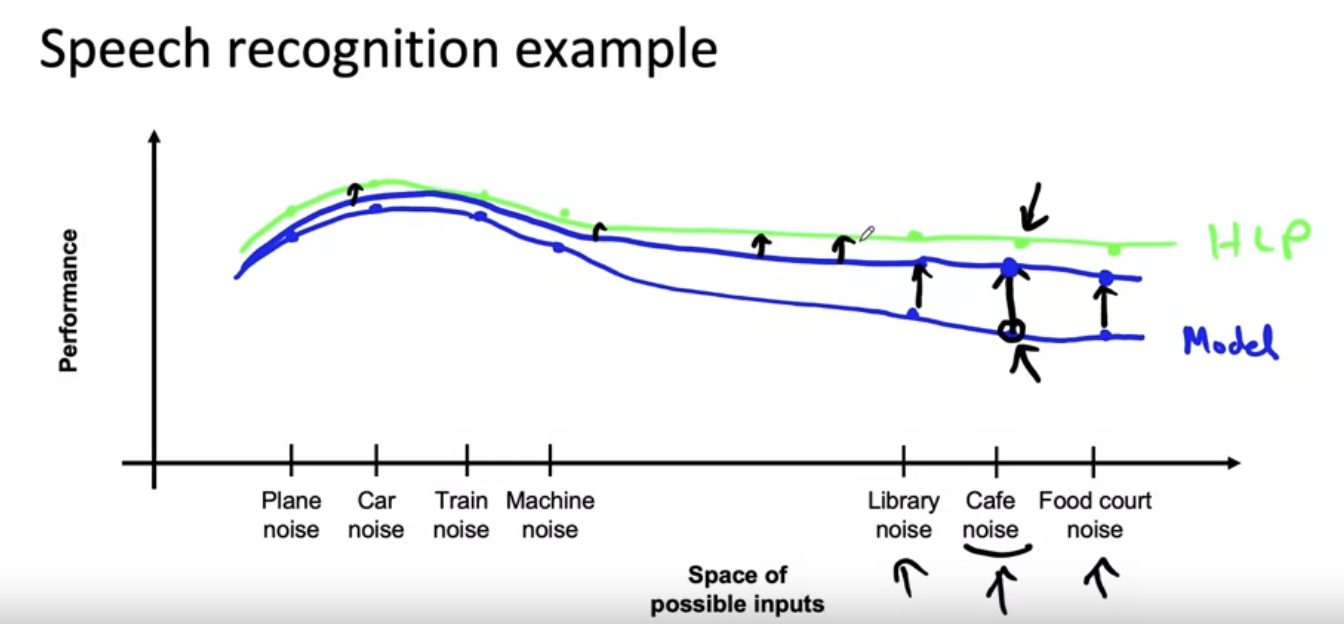
Why low average error isn't good enough
- dev/test 에서 low error를 달성 했더라고 해도 실제 환경에서 적절하지 않을 수 있음
- 평균적인 상황이 잘 나오더라도 특정 상황의 데이터를 잘못 판단 했을 시 좀 더 문제가 될 수있음
- 이럴 경우 이러한 데이터에 가중치를 주거나 하는 방법이 있을 수 있지만,
이것은 항상 문제를 해결할 수는 없음
고려해야될 데이터
- Key Slice of th Dataset
ex) 대출 승인 시스템은 인총, 성별, 위치, 언어 등에 대한 bias를 가지면 안된다. - Rare Classes
ex) 진단과 같은 분야에서 환자가 정상보다 극히 적기 때문에 Accuracy에만 집중해선 안된다.
Establish a baseline
- Baseline이 있어야 이를 개선하는데 필요한 것들을 개발 할 수 있음
- Baseline은 문제에 대해 무엇이 가능할지 판단하는데 도움을 줌
- 이론적으로 해결 불가능한 error(Bayes error)가 무엇인지 이해하는데 유용함
- 초기 단계의 집중할 부분을 판단하는 것과 장기적 성공에 중요
Ways to eatablish a baseline
- Human level performance(HLP)
- 일반적으로 비정형 데이터일때 효과적
- Literature search for state-of-the-art/open source
- SOTA 나 open source들의 Metric/perfomance 조사 및 비교
- Quick-and-dirty implementation(PoC / MVP)
- Performance of older system(성능 개선)
Tips for getting started
- Literacture search
- 실용적인 시스템을 구축하는게 목표라면 최신 알고리즘 보단 블로그같은 것들이 도움이 될 수 있음
- Find Open Source(적용 가능한걸로)
- Using reasonable Model With good Data & Quick Start
- 배포 제약 조건 고려
- baseline이 이미 있고 프로젝트가 성공적이라면 고려해야함
- 아직 그렇지 않다면 고려하지 않고도 빠르게 시도
- Sanity-check(code & algorithm)
- 처음부터 모든 데이터를 사용하기 보단 작은 데이터를 사용해서 잘 작동하는지 확인
Error analysis and performance auditding
Error analysis example
- 모델은 처음부터 완벽하지 않기 때문에 개발 과정의 핵심은 Error anlysis이다.
- Error anlysis를 통해 좀더 효율적으로 개발을 할 수 있음
- Label과 Prediction을 비교하고 분석하는 과정을 반복(데이터에 특정 Tag를 다는 방식으로 분석)
- 이것을 좀더 효율적으로 할 수 있는 도구를 만드는 것도 MLOps의 일부라고 할 수 있음
- 특정 Tag중에 Error를 발생 시키는 비율
- 잘못된 라벨링이 있는 것들의 비율
- 특정 Tag의 비율
- 데이터 개선 가능성에 대한 고려
- 분석 후 특정 Label에 대한 성능 등을 확인하고 데이터를 개선하는 것을 반복
Prioritizing what to work on
- 분석한 결과를 통해 해당 Tag나 카테고리에 대해 얼마나 개선되어야 할지에 대해 판단
- 성능이 안나오는 특정 Tag나 카테고리에 대해서 개선을 한다고 해서 전체 성능에 대해 큰 영향을 안줄수 있으므로 어떤 특정 부분에 집중을 할때는 여러가지를 고려 해야함
- 어떠한 문제를 해결하면 얼마나 가치가 있는지 판단 해야함
- 개선 가능성, 빈도, 난이도 등을 고려
- 개선할 카테고리을 위해 데이터를 추가하거나 개선하는 작업을 할 수 있음
Skewed datasets
- Confusion Matrix 사용함으로서 편향된 데이터를 잘 평가 할 수 있음
- F1 score 또한 도움이 된다.
- 다중 클래스를 판단하는데도 도움이 됨.
Performance audditing
- dev/test에서 성능이 잘 나온다고 해도 실제 배포 전에 선능 검사를 수행 해야한다
- System이 잘못 되었을 수도 있을 가능성에 대한 Brainstorm
- subsets of data, Skew data 등에 대한 성능
- Brainstorm을 통해 나온 문제들을 잘 처리할 Metric 확인이나 자동화
- 팀에서만 Brainstorm을 할게 아니라 다른 사람 혹은 다른 팀과 함께 하는게 좋다!
Data iteration
Data-centric AI development
- Model Centric : 주어진 데이터에 대해 가능한 잘 수행 하는 모델 개발
- Data Centric : 데이터 품질 개선을 통해 모델이 잘 수행 하도록 개발
A useful picture of data augmentation
- data augmentation을 통해 특정 데이터의 성능을 향상 시킬 경우, 이와 유사한 데이터의 성능도 오를 가능성이 있다.
Data augmentation
- Checklist
- Augmentation 결과가 현실성이 있는가?
- x -> y mapping이 제대로 되어 있는가?
사람은(or other baseline) 잘하는가?(사람도 못 구분할 정도의 데이터는 의미 없다) - 현재 알고리즘이 잘 수행하지 못하는가?(잘하고 있다면 굳이 할 필요 X)
- Data iteration loop
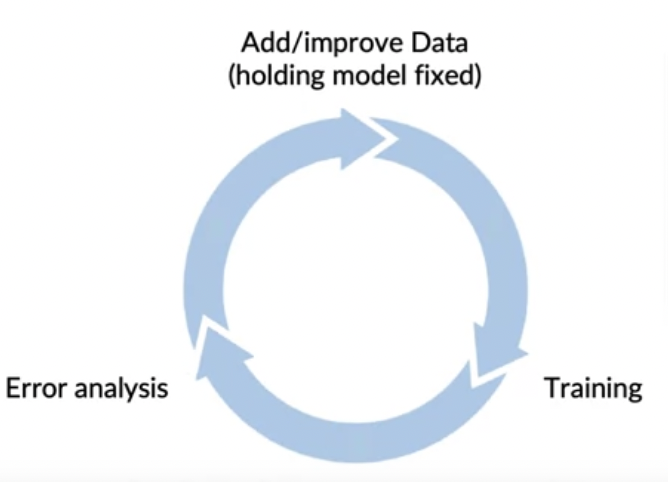
Can adding data hurt
- 데이터 추가(or Augmentation)에 의해 Train과 Test가 다른 분포를 가졌을때, 일반적으로 비정형 데이터에서는 크게 문제되지 않는다.
- 비정형 데이터 문제에서 Large model(low bias), x->y mapping clear(라벨링이 정확할 경우) 모델 성능을 해치지 않음
- 모델이 작을 경우 bias가 생길 가능성이 있음
- x-> y의 mapping이 명확하지 않다면 새로운 데이터를 추가하는게 성능에 안좋을 수 있음
- 대부분의 경우 Augmentation이나 data를 추가하는 것이 성능 향상에 도움을 줌
Adding features
- 정형 데이터를 사용할때 Feature 추가를 통해 데이터를 늘릴 수 있음
- 정형 데이터에서 Data Iteration
- Error Analysis, User Feedback, 경쟁사 벤치마킹을 통해 개선 방법을 찾고 필요한 특성을 추가하는 방식
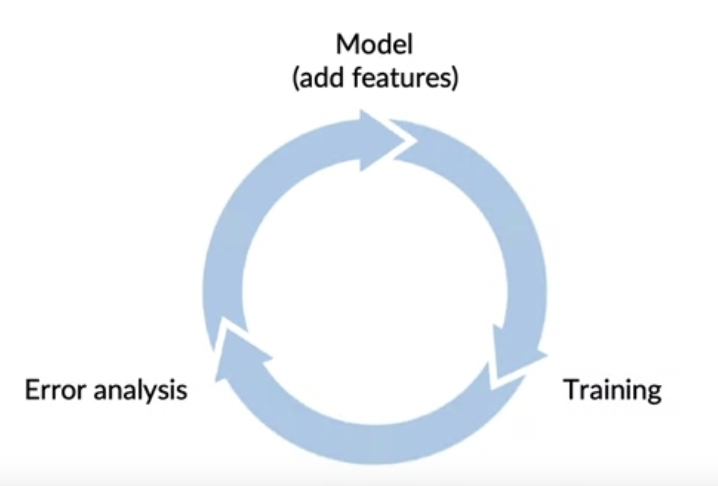
- Error Analysis, User Feedback, 경쟁사 벤치마킹을 통해 개선 방법을 찾고 필요한 특성을 추가하는 방식
Experiment tracking
- 수 많은 실험을 진행할때, Experiment Tracking하는 시스템을 갖추는 것이 성능 향상 및 결정에 도움이 된다.
- Experiment Tracking시 고려할 요소
- Alcorithm/code Versioning : Reproducibility 고려
- 사용한 데이터 셋
- 하이퍼 파라미터
- Result : Metric과 Model 저장
- Experiment Tracking Tool을 고를때 고려사항
- 결과 재현에 필요한 모든 정보 제공
- 실험 결과를 빠르게 이해할 수 있는 요약 지표 및 분석 도구
- 리소스 모니터(GPU, CPU, Memory...), 시각화, Model Error Analysis
EX) Weight & Biases, Comet, MLflow, SageMaker Studio
From big data to good data
- BigData뿐만 아니라 Good Data에 중점을 두는것이 중요
- Good Data란?
- Cover important cases(다양한 입력에 대한 충분한 데이터)
- 일관된 Labels Y(명확하고 일관되게 라벨링 되어야한다)
- Production Data에 대한 Feedback(concept & data drift에 대한 대응)
- 합리적인 Dataset size
