Introduction to Machine Learning in Production - Week 3
Week 3: Data Definition and Baseline
Define Data and Establish Baseline
Why is data definition hard?
- 라벨링에 대한 가이드가 조금이라도 명확하지 않을 경우 같은 데이터라도 다른 라벨링이 나올 가능성이 높음
- 같은 데이터가 다른 라벨이 나올 경우 모델 성능이 낮아질 가능성이 있음
- 일관된 라벨링 가이드는 모델 성능에 상당히 중요함
- x, y에 대한 정확한 정의가 있어야 라벨링이 일정해지고 모델의 성능을 올릴 수 있음
- What is the input X?
- 정확한 입력의 정의와 품질을 지켜야함
- 포함해야하는 feature가 무엇인가?(정형 데이터의 경우)
- What is the target label y
Major types of data problems
- 비정형 데이터에서 데이터가 적을 경우 Augmentation과 같은 것들이 효과적일 수 있고 데이터를 추가로 수집하는것도 비교적 쉬움
- 정형 데이터의 경우에는 Augmentation이 효과적이지 않을 수 있으며 추가적인 데이터를 수집하는게 비교적 어려움
- 데이터가 적을수록 Data Cleansing이 중요함
- 데이터가 많아진다면 Cleansing이 어려워 지므로 Data Process에 집중을 해야함
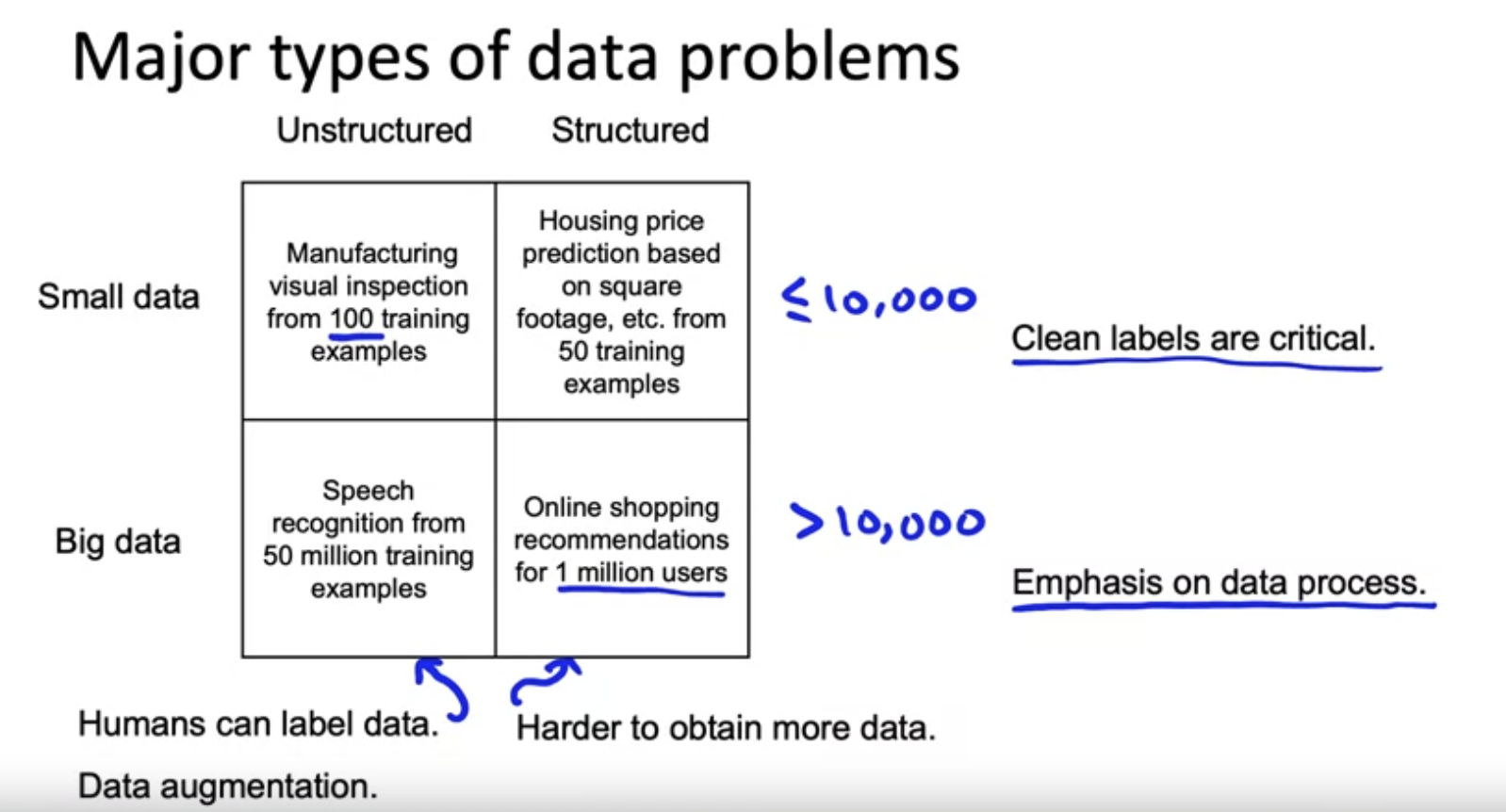
Small data and label consistency
- 일관성 있는 라벨링과 클렌징된 데이터....
- 데이터가 큰 경우에도 Rare Data에 대한 문제가 발생할 수 있으므로 데이터가 크던 작던 일관성있는 데이터는 중요하다
Improving label consistency
- Improving label consistency
- 같은 데이터를 여러 Lableler가 라벨링 진행
- 불일치시, 라벨 정의에 대한 논의를 한다(MLE와 여러 전문가가 함께)
- 입력 X가 충분한 정보를 제공하지 않는 경우 X를 변경하는 것도 고려
- 위 과정을 반복!
- Standardize Labels
- 여러 경우가 나올수 있는 Label들을 하나의 Label로 통일
- Merge Classes
- 하나로 표시하기 힘든 경우를 찾기 위해 두개의 Class를 하나의 클래스로 병합하는 방법(Deep Scratch + Shallow Scratch -> Scratch)
- Class/Label with Uncertainty
- Consensus labeling은 라벨의 정확도를 올리지만, 최후의 수단으로 사용하는게 좋다. 이것 보다는 labeler의 선택 자체를 덜 Noisy 하게 하는것이 바람직함
- Label이 일치하지 않는 것을 인지하고 개선하는 도구가 필요
- Bayes error 추정 및 우선 순위 설정에 도움을 주는 Baseline
- 학술적인 벤치마크로도 사용
- 인간의 성능을 능가하는 것이 성능을 증명 할 수도 있지만, 실제로 작동하지 않을 가능성이 있다.
- Label Guide가 명확하지 않으면 더 문제가 됨
- HLP를 사용하는 유용하지만 사람을 능가한다고 하는 것을 증명할때 사용하기엔 무리가 있음
- 실제 어플리케이션을 만들때 인간의 성능을 능가하는 것 보다 인간의 성능을 향상시키는데 초점을 맞추는게 더 도움이 될 수 있음
Raising HLP
- 사람의 능력이 100%가 되지 않을때 HLP는 좋은 측정 기준이 아닐 수 있음.
- 그러나 이를 통해 Labelling Guide를 개선하고 HLP자체를 개선하면 최종적으로 데이터 품질 & ML의 성능을 올릴 수 있음
- HLP가 완벽하지 않다면 레이블링 프로세스를 재 검토하고 개선해야 한다는 알림
- HLP는 유용하지만 데이터의 일관성이 더 중요
Label and Organize Data
Obtaining data
- 초기 데이터셋을 수집하는데 너무 집중하기 보단 가능한 빠르게 학습 Iteration에 돌입 해야함
- 얼마나 많은 데이터가 필요한지 모를때, 빠른 Iteration과 오류 분석을 통해 어떤 데이터를 모을지에 대해 좀더 고민하는게 좋음
- Inventory Data
- Data Source에 대해 Brainstorm
- 각 데이터 소스와 관련된 비용과 시간을 평가
ex) 크라우드 소싱, 라벨링 비용 지불, 데이터 구입
- Labeling Data
- In-house vs outsourced vs crowdsourced
- MLEs에 의한 라벨링 -> 고비용이지만 초반엔 괜춘..?
(데이터에 대한 직관을 기르기 좋음)
- 데이터에 따라 전문가가 필요하거나 아무나 labelling을 할 수 있음
- 데이터를 한번에 너무 많이 늘리면 안좋음(ex 10배)
점차적으로 데이터를 늘리고 Iteration을 반복
데이터에 너무 많은 투자를 하는 것을 피하고, 수집한 데이터의 유용성 평가해야함
Data pipeline
- Data pipeline : 최종 ouput에 도달하기 전 여러 단계를 거치는 것
- POC일때는 데이터 전처리가 수동적이어도 괜찮지만 Production Phases에서는 자동화를 하여 재현성을 확보해야함
- TensorFlow Trnasform, Apache Beam, Airflow 등을 사용 할 수 있음
- Meta-data
- 데이터에 대한 데이터(데이터를 설명하는 데이터)
- Error Analysis에 유용 할 수 있음
- Data Provenace
- Data Lineage
- Data pipeline 끝에 도달하기위해 필요한 단계의 순서
- 문서화로 추적 할 수도 있지만 Tensorflow Transform과 같은 걸로 관리할 수 있음
Balanced train/dev/test splits
- 데이터가 적을 경우 균형잡힌 split이 중요하다
Scoping
What is scoping?
- 올바른 프로젝트를 선택하는 것, 프로젝트의 범위를 정하는 것
Scoping process
- 비즈니스 문제와 AI Solution을 분리하여 생각하는 것이 중요
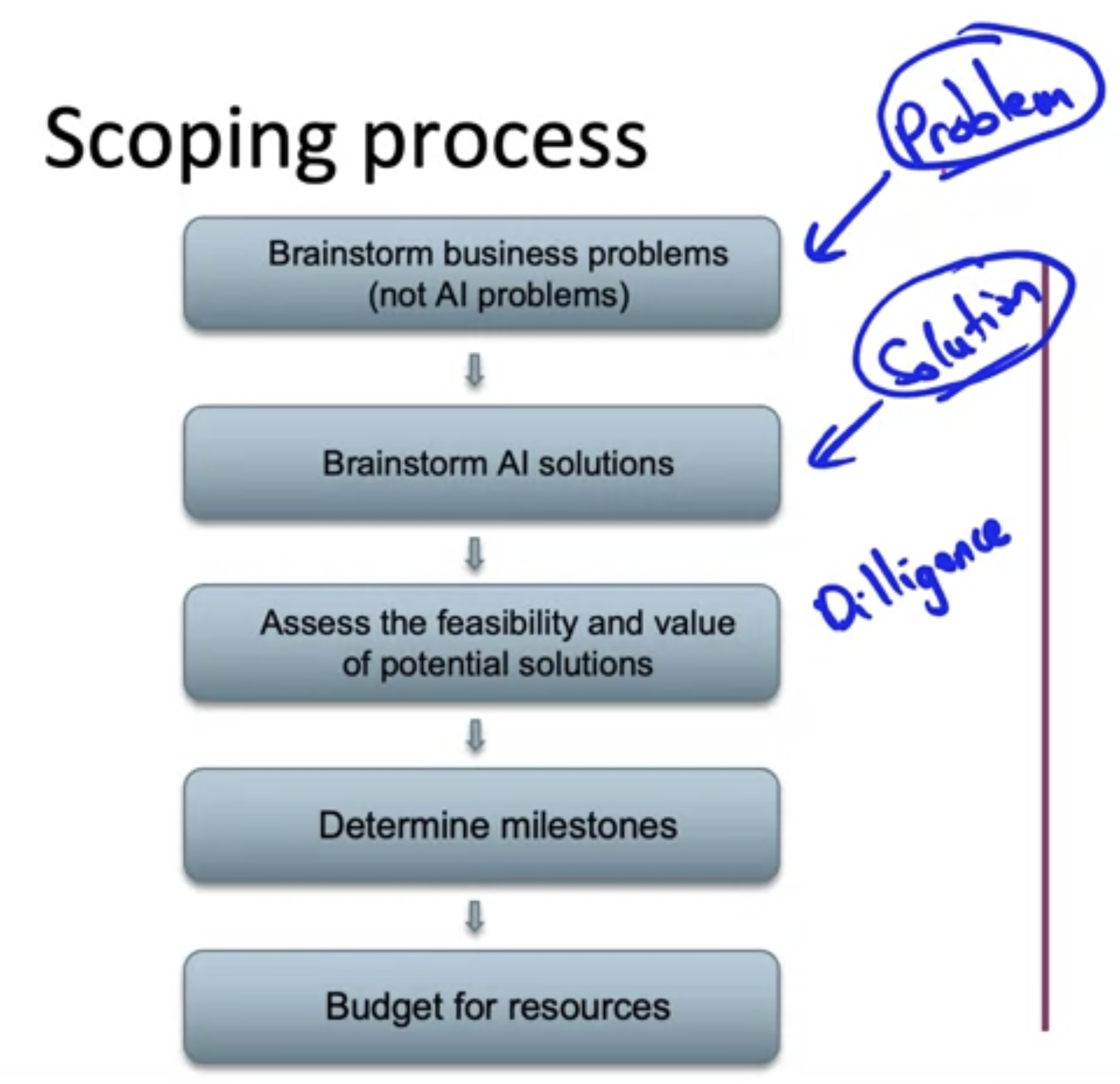
- 하나의 프로젝트에 바로 뛰어들기 보다는 여러 가능한 솔루션을 브레인스토밍 후에 가장 가능성 있는 프로젝트를 선정하고 집중하는 것이 좋음
Diligence on feasibility and value
- 프로젝트의 실행 가능성과 가치 파악
- 외부 벤치마크 사용(literature, other company, competitor)
- 비정형 : HLP가 가능한지 확인
- 정형 : 예측 가능한 Feature가 있는지 확인
- History of Proejct
- 미래 개선 가능성을 예측하는데 도움을 줄 수 있음
Diligence on value
- 개발과 비즈니스에서 중요시하는 Metric이 서로 달라질 수 있음
- 양측 모두 합의할수있는 Metric을 도출하는것이 중요
- Ethical considerations
- 사회에 긍정적인 가치를 창출하는지?
- 공정하고 편견이 없는지?
- 윤리적 고려사항이 충분히 논의 되었는지?
Milestones and resourcing
- ML metrics
- Software metrics
- Business metric
- Resources needed
- Timeline
