RNN은 시계열 데이터와 같은 sequential 데이터에 최적화
1. 패키지 설치
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt2. 데이터 불러오기
다음과 같은 주가 데이터가 있다고 가정
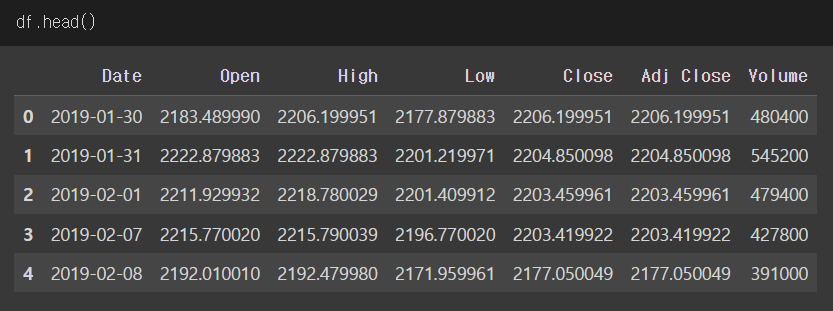
3. 데이터 전처리
open, high, low, volume으로 close 예측!
scaler = MinMaxScaler() # 단위가 다르기 때문에 scaling
df[['Open','High','Low','Close','Volume']] = scaler.fit_transform(df[['Open','High','Low','Close','Volume']])간단한 전처리 EDA 결과
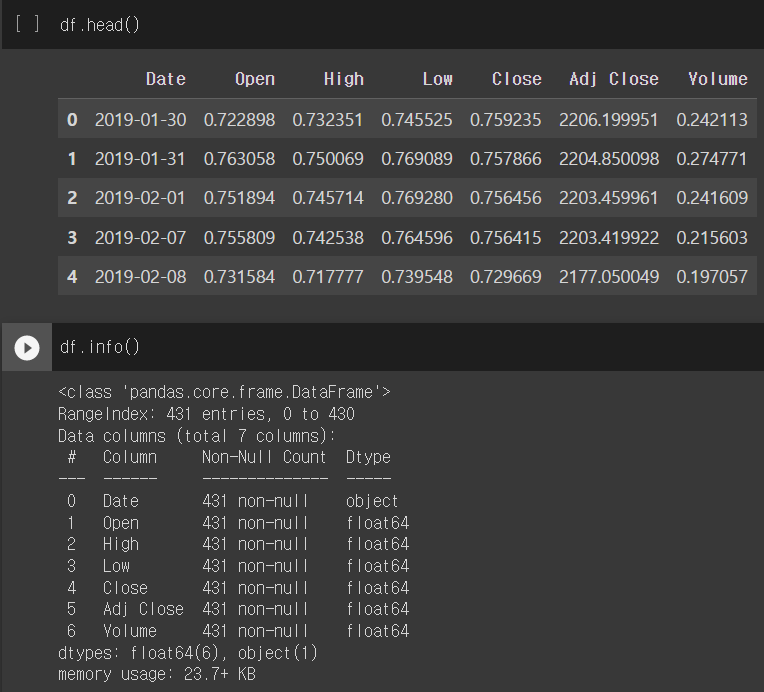
4. Torch에 사용할 Tensor 데이터 만들기
변수 4개를 가지고 있는 데이터 (input size = 4) 200개로
지난 5일의 데이터를 기준으로 (sequence length of X = 5)
그 다음날의 데이터를 예측하는 모델 (target, Y) = 1
# GPU 사용
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f'{device} is available.')
# Dataset
X = df[['Open','High','Low','Volume']].values # 변수 4개
y = df['Close'].values # 타겟 1개
# seq_data 함수 만들기
def seq_data(x, y, sequence_length): # RNN을 사용하기 위해선 sequence length가 무조건 필요!
x_seq = []
y_seq = []
for i in range(len(x)-sequence_length):
x_seq.append(x[i:i+sequence_length]) # a[2:6] -> 2,3,4,5 # 지난 5일의 데이터로
y_seq.append(y[i+sequence_length]) # 그 다음날 데이터 예측
return torch.FloatTensor(x_seq).to(device), torch.FloatTensor(y_seq).to(device).view([-1, 1])
# x_seq과 y_seq GPU에 올리기5. Train/Test Split & Loader
split = 200 # 하이퍼 파라미터
sequence_length = 5 # RNN을 사용하기 위해선 sequence length를 사용해야 한다
x_seq, y_seq = seq_data(X, y, sequence_length)
x_train_seq = x_seq[:split] # Train (~200)
y_train_seq = y_seq[:split]
x_test_seq = x_seq[split:] # Test (200~)
y_test_seq = y_seq[split:]
print(x_train_seq.size(), y_train_seq.size())
print(x_test_seq.size(), y_test_seq.size())
# Result
torch.Size([200, 5, 4]) torch.Size([200, 1]) # 200개의, 5일간, 변수 4개로 200개의 종가 예측
torch.Size([226, 5, 4]) torch.Size([226, 1])
# Dataset
train = torch.utils.data.TensorDataset(x_train_seq, y_train_seq)
test = torch.utils.data.TensorDataset(x_test_seq, y_test_seq)
# Dataloader
batch_size = 20
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=batch_size, shuffle=False)6. Hyperparameter & 모델구축
RNN 모델은 "input size, hidden size, num layers, sequence length" 필요
# RNN
input_size = x_seq.size(2) # 4 = 데이터 변수의 개수 ('Open','High','Low','Volume')
num_layers = 2
hidden_size = 8
# RNN Model
# batch _first: pytorch의 RNN은 sequence의 길이가 먼저 들어와야함
# 그런데 데이터는 batch 가 앞에 있음
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(VanillaRNN, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 중요
self.fc = nn.Sequential(nn.Linear(hidden_size*sequence_length, 1), nn.Sigmoid())
# input으로 받는 (sequence length * hidden size) -> 1
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
out, _ = self.rnn(x, h0)
# h0 초기 hidden state 설정
out = out.reshape(out.shape[0], -1) # many to many 전략 (batch, length*hidden size)
# self.fc = nn.Sequential(nn.Linear(hidden_size*sequence_length, 1) 생각하면 편함
out = self.fc(out)
return out
# out: RNN의 마지막 레이어로 부터 나온 output feature 반환
# RNN 모델은 input size, hidden size, num layers, sequence length 필요
model = VanillaRNN(input_size=input_size,
hidden_size=hidden_size,
sequence_length=sequence_length,
num_layers=num_layers,
device=device).to(device)
# Criterion, Loss, Epochs, Optimizer 설정
criterion = nn.MSELoss()
lr = 1e-3
num_epochs = 200
optimizer = optim.Adam(model.parameters(), lr=lr)7. 모델 학습 및 시각화
loss_graph = [] #epoch -> batch
n = len(train_loader)
for epoch in range(num_epochs): #epoch -> batch
running_loss = 0.0
for data in train_loader:
seq, target = data # 배치 속 데이터
out = model(seq)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() # 이 구조도 암기!!
loss_graph.append(running_loss/n)
if epoch % 100 == 0:
print('[epoch: %d] loss: %.4f' %(epoch, running_loss/n))
# 시각화
plt.figure(figsize=(20,10))
plt.plot(loss_graph)
plt.show() 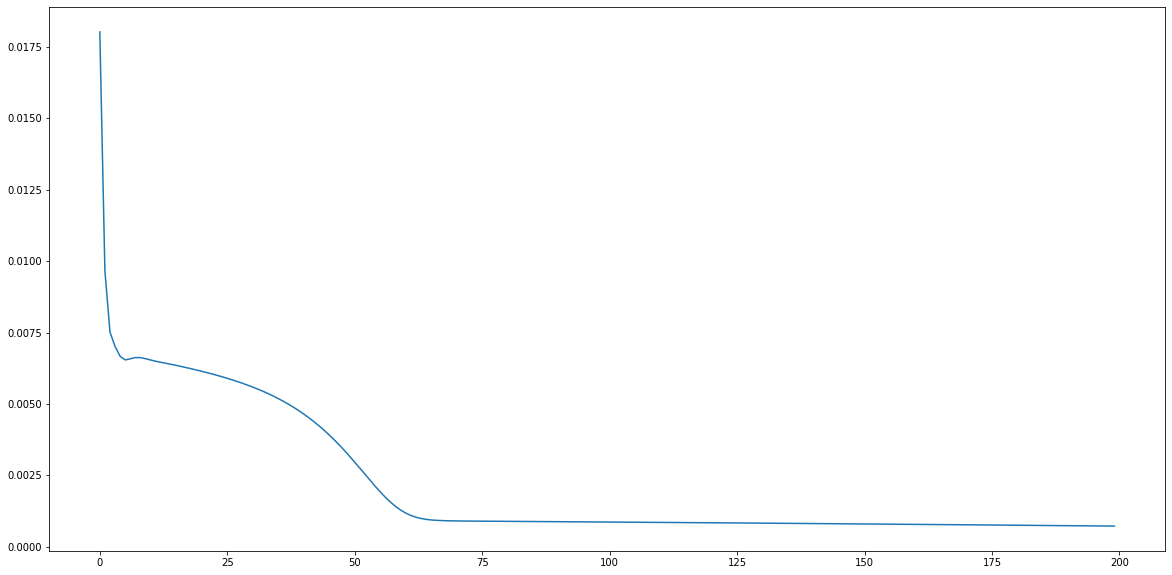
8. 실제 데이터와 비교
def plotting(train_loader, test_loader, actual):
with torch.no_grad():
train_pred = []
test_pred = []
for data in train_loader:
seq, target = data # 배치 데이터
out = model(seq)
train_pred += out.cpu().numpy().tolist()
for data in test_loader:
seq, target = data # 배치 데이터
out = model(seq)
test_pred += out.cpu().numpy().tolist()
total = train_pred+test_pred
# 시각화
plt.figure(figsize=(20,10))
plt.plot(np.ones(100)*len(train_pred),np.linspace(0,1,100),'--', linewidth=0.6)
plt.plot(actual,'--')
plt.plot(total,'b', linewidth=0.6)
plt.legend(['train boundary','actual','prediction'])
plt.show()
plotting(train_loader, test_loader, df['Close'][sequence_length:].values) 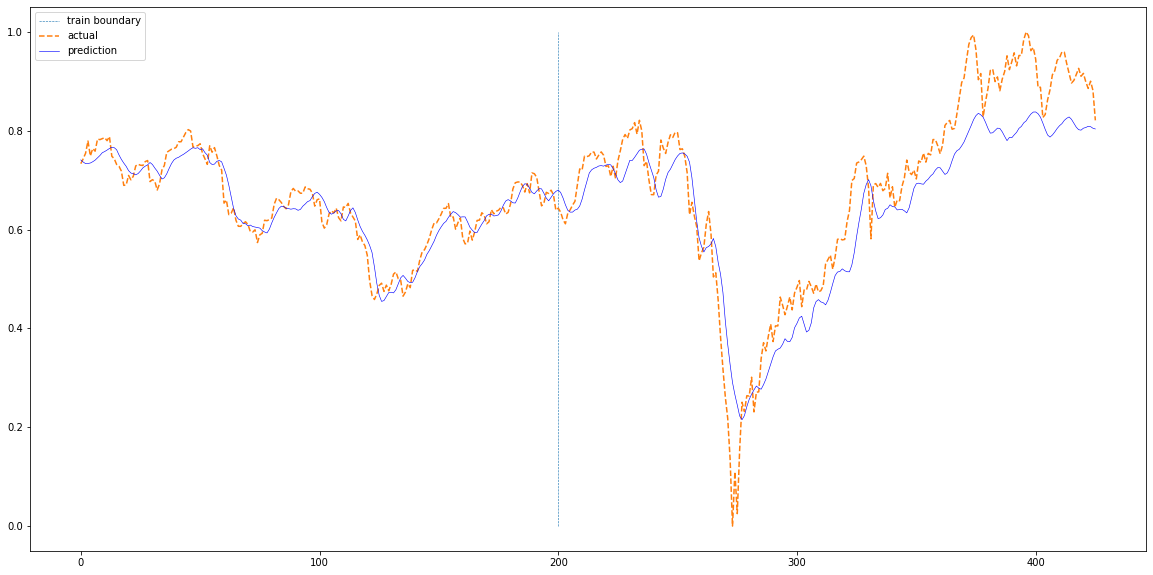
RNN 모델(nn.RNN)에 들어가는 변수가 헷갈리면 torch 공식 문서 참고!
input size = the number of expected features in the input ('Open','High','Low','Volume' 4개)

input 데이터와 out 데이터의 형태 확인

Pytorch RNN
1. https://pytorch.org/docs/stable/generated/torch.nn.RNN.html

pppanghyun