LSTM은 RNN 모델이 장기 기억력이 낮다는(?) 문제를 해결한 방법 (cell state를 통해)
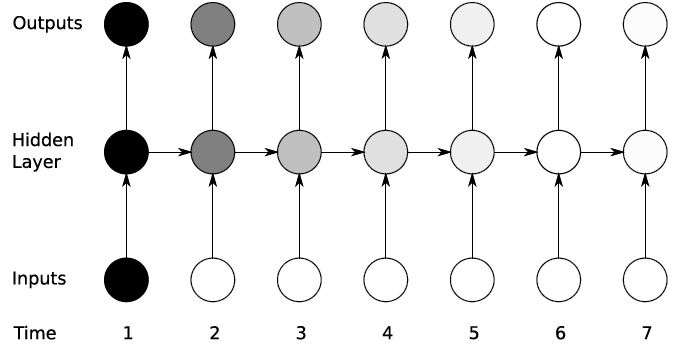
RNN 모델 구조
(아래 그림처럼 RNN은 시간이 지날 수록 Gradient vanishing 현상이 나타남)
LSTM 모델 구조 (Ct = cell state!)
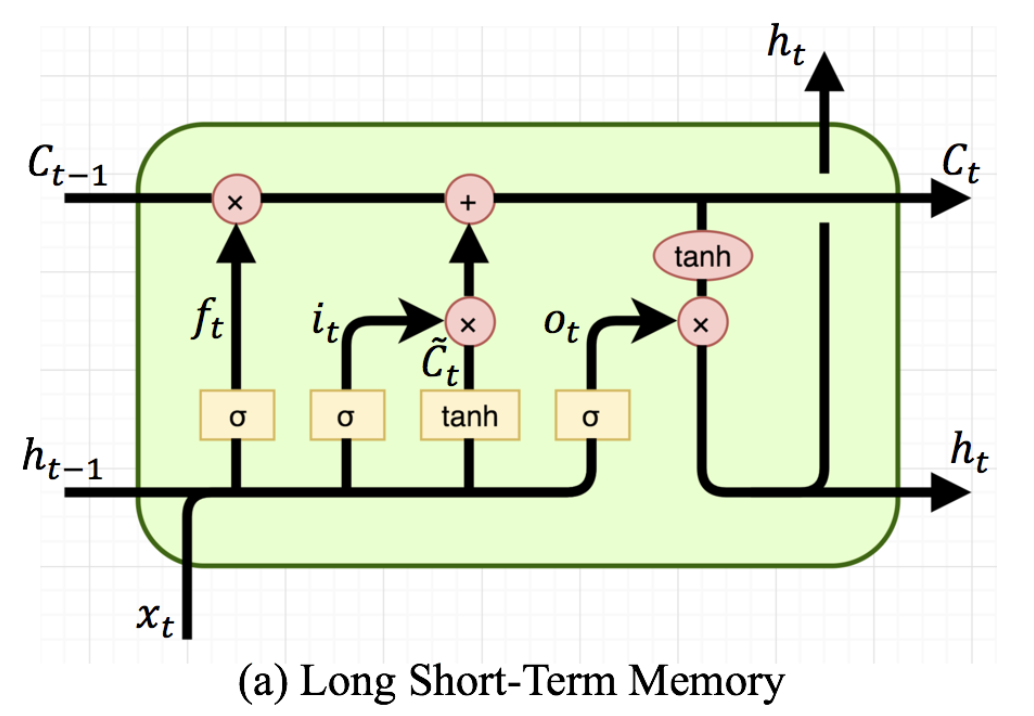
*이전 단계까진 RNN 모델과 동일
1. LSTM Hyperparameter 및 모델 만들기
RNN에서는 없었던 'cell state'가 추가된다 (장기 기억력을 올려주는 역할)
torch의 nn.lstm 모델은 보통 input size, hidden size, num layers 를 인풋으로 받음
# LSTM Hyperparameter
# RNN과 매우 비슷함
# 너무 많은 num layers 와 hidden size는 overfitting 을 유발
input_size = x_seq.size(2) # 변수의 개수(데이터의 개수 X,The number of expected features in the input x)
num_layers = 2
hidden_size = 8
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(LSTM, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1) # length 마다 hidden size!
def forward(self, x): # <- cell state 추가, x.size()[0] = 변수 개수
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
out, _ = self.lstm(x, (h0, c0)) # output, (hn, cn)
out = out.reshape(out.shape[0], -1)
out = self.fc(out)
return out
# make LSTM 모델
model = LSTM(input_size=input_size,
hidden_size=hidden_size,
sequence_length=sequence_length,
num_layers=num_layers,
device=device)
model = model.to(device)2. Criterion, learning rate, epochs, optimizer 설정
criterion = nn.MSELoss()
lr = 1e-3
num_epochs = 201
optimizer = optim.Adam(model.parameters(), lr=lr)3. 모델 학습하기 및 시각화
loss_graph = []
n = len(train_loader)
for epoch in range(num_epochs): # epoch
running_loss = 0.0
for data in train_loader: # batch
seq, target = data # 배치 데이터
out = model(seq)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_graph.append(running_loss/n)
if epoch % 100 == 0:
print('[epoch: %d] loss: %.4f' %(epoch, running_loss/n))
# 시각화
plt.figure(figsize=(20,10))
plt.plot(loss_graph)
plt.show() 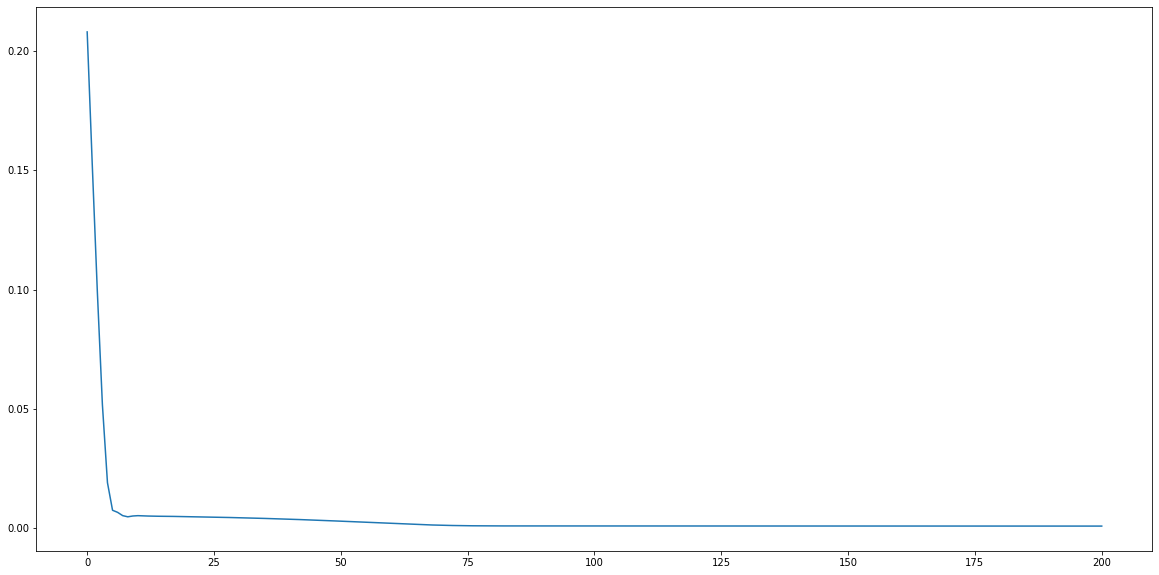
4. 실제 데이터와 비교
def plotting(train_loader, test_loader, actual):
with torch.no_grad():
train_pred = []
test_pred = []
for data in train_loader:
seq, target = data # 배치 데이터
#print(seq.size())
out = model(seq)
train_pred += out.cpu().numpy().tolist()
for data in test_loader:
seq, target = data # 배치 데이터
#print(seq.size())
out = model(seq)
test_pred += out.cpu().numpy().tolist()
total = train_pred+test_pred
plt.figure(figsize=(20,10))
plt.plot(np.ones(100)*len(train_pred),np.linspace(0,1,100),'--', linewidth=0.6)
plt.plot(actual,'--')
plt.plot(total,'b', linewidth=0.6)
plt.legend(['train boundary','actual','prediction'])
plt.show()
plotting(train_loader, test_loader, df['Close'][sequence_length:].values) 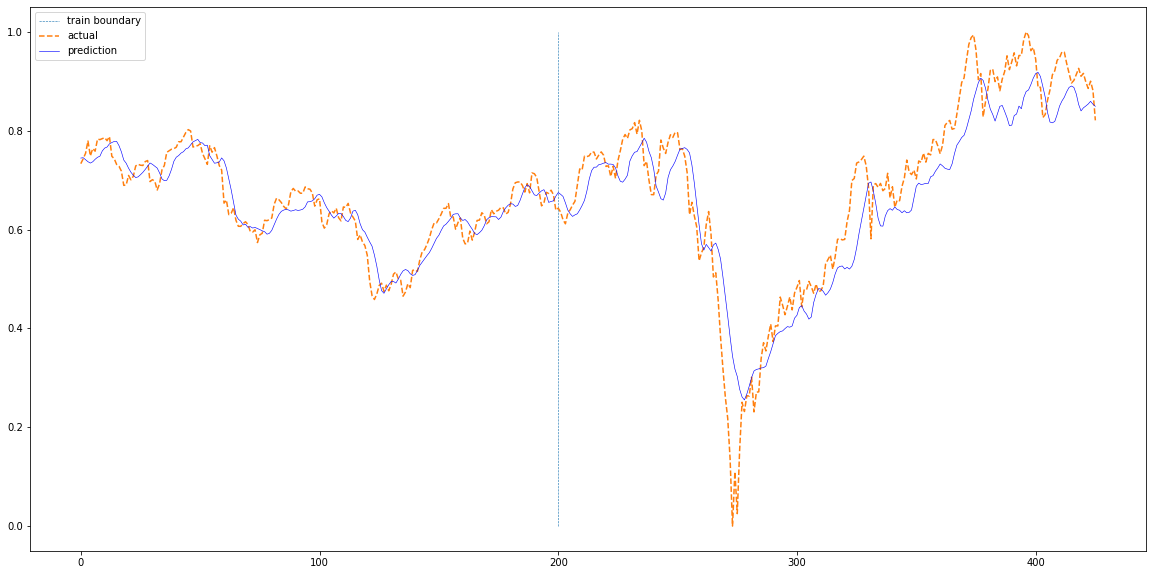
개인적으로 LSTM은 실제 프로젝트나 분석에서 사용할 일이 많다고 느낌. 등장한지는 엄청 오래된 모델인데 RNN 보다는 조금 모델 구조가 복잡함. torch 공식 documentation을 보고 한 줄씩 뜯어보면 도움이 될 것으로 예상함. (parameter, input, output 구조 위주)
다음은 torch의 LSTM 공식 document
- (c0, h0 으로 초기값을 설정해준, cell state와 hidden state에 대한 설명 참고)

- LSTM에 들어가는 parameter의 의미
(input size는 변수의 개수, hidden size와 num layers는 hyperparameter인데 num layers는 보통 1(default)이나 2를 사용)

- torch.nn.lstm이 input으로 받는 구조는 다음과 같음
input은 (L,H) 형태의 tensor 데이터(x)이고, h0, c0은 위에서 언급한 hidden, cell state의 초기(t=0)값
out, _ = self.lstm(x, (h0, c0)) 에서 (x, (h0, c0)) 부분

4. torch.nn.lstm의 output 구조
위의 식의 out, _ 부분
위의 코드에서 out은 결국 document 기준 ouput만 을 받는 것인데, output은 결국 다시 (L,D*H) 형태의 tensor임

결론은 그냥 cell state를 통해 RNN 대비 장기기억력이 올라갔다는 것 ~
*개인적으로 도움이 많이 되었던 참고자료
- torch documentaion
https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html - Advanced Architectures of RNN (LSTM, GRU) - 딥러닝 홀로서기
https://www.youtube.com/watch?v=cs3tSnAsyRs

pppanghyun