Pandas는 데이터 조작 및 분석을 위한 파이썬 라이브러리입니다. Pandas는 데이터를 구조화하고 조작하는 데 사용되며, 주로 데이터 프레임(DataFrame)과 시리즈(Series)라는 두 가지 주요 데이터 구조를 제공합니다. 이러한 구조를 사용하여 데이터를 효율적으로 저장하고 처리할 수 있습니다.
주요 특징과 기능은 다음과 같습니다:
데이터 프레임(DataFrame) : 데이터를 테이블 형식으로 나타내며, 각 열(column)은 서로 다른 데이터 유형을 가질 수 있습니다. 이를 통해 데이터를 로우(row) 및 컬럼(column)으로 조작할 수 있습니다.
시리즈(Series) : 1차원 배열 형태로 데이터를 표현하며, 데이터 프레임의 열은 모두 시리즈로 구성됩니다. 시리즈는 라벨링된 데이터와 함께 인덱싱할 수 있습니다.
데이터 로딩 및 저장 : Pandas는 다양한 데이터 소스에서 데이터를 로드하고 다양한 형식으로 데이터를 저장할 수 있는 기능을 제공합니다. 예를 들어 CSV, Excel, SQL 데이터베이스, JSON 등의 형식을 다룰 수 있습니다.
데이터 정렬, 필터링 및 변환 : 데이터를 원하는 방식으로 정렬, 필터링, 그룹화 및 변환할 수 있습니다.
결측값 처리 : Pandas는 결측값(누락된 데이터)을 다루는데 유용한 기능을 제공하며, 이를 효과적으로 처리할 수 있습니다.
시계열 데이터 처리: Pandas는 시계열 데이터(날짜 및 시간 데이터)를 처리하는 기능을 지원합니다.
데이터 시각화 : Pandas 데이터를 시각화하기 위한 통합된 기능을 제공하지는 않지만, 다른 라이브러리인 Matplotlib, Seaborn 등과 함께 사용하여 데이터를 시각화할 수 있습니다.
Pandas는 데이터 과학 및 데이터 분석 작업에서 매우 인기 있는 도구 중 하나이며, 데이터 전처리, 탐색적 데이터 분석(EDA), 데이터 정제, 데이터 시각화, 기계 학습 모델 개발 등 다양한 작업에 활용됩니다.
1. pandas 패키지 로드
* 판다스 패키지는 파이썬으로 데이터를 다룰 때 빠질 수 없는 중요한 패키지다.
* 판다스 패키지를 이용하면 다양한 방법으로 데이터를 조작할 수 있다.import pandas as pd
2. pandas 의 Series 와 DataFrame
# python의 리스트 [1,2,3,4] Series함수에 넣으면 pandas.Series데이터 변수를 생성
pd.Series([1, 2, 3, 4])
a = [1, 2, 3, 4]
pd.Series(a)
mylist = [1, 2, 3, 4]
test = pd.Series(mylist)
type(test)
# 이 셀에서는 Pandas seires 데이터를 생성
test
2-2. DataFrame
방법 1. list로 만들기
# 2차원 리스트로 values값을 생성 2번방 승차 3번방 하차
subway1 = [['1호선','서울역', 17896, 15468],
['2호선','강남', 22794, 21657],
['3호선','신사', 24131, 25592]]
# DataFrame의 왼쪽 첫번째 열은 index이다.
# DataFrame의 첫번째 행은 columns이다.
# 실제 data가 저장된 부분은 values라고 부른다.
# 실제 데이터프레임이 저장되지는 않는다.
pd.DataFrame(subway1)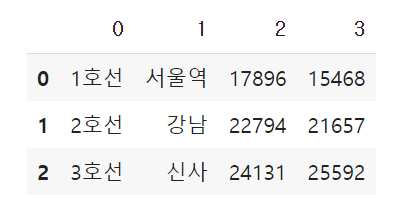
# df1이라는 이름으로 데이터프레임이 저장(생성)
df1 = pd.DataFrame(subway1)
# 아직 컬럼명이 존재하지 않음
df1 #data frame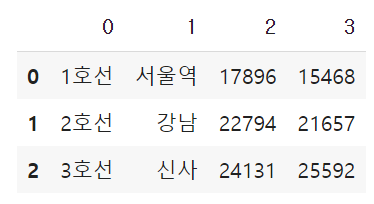
제목컬럼 만들기
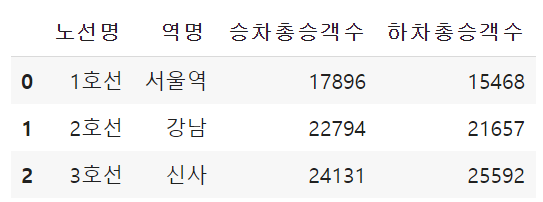
df1.columns = ['노선명', '역명', '승차총승객수','하차총승객수']
df1
방법 2. dict로 만들기
# 데이터프레임을 생성할 때, dict타입으로 생성하면, columns와 values를 입력하고 시작
# dict의 key값은 column
# dict의 value는 values->리스트
subway2 = {'지하철노선':['1호선', '2호선', '3호선'],
'역명': ['서울역','강남','신사'],
'승차총승객수': [17896, 22794, 24131],
'하차총승객수': [15468, 21657, 25592]
}
df2 = pd.DataFrame(subway2)
df2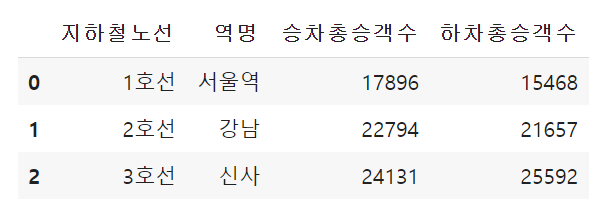
index를 특정 column으로 지정하기
df1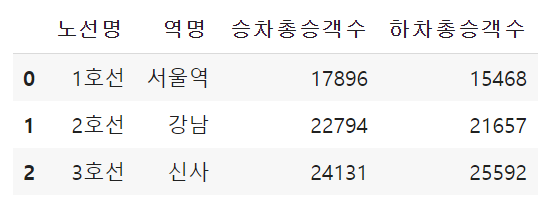
# index값을 특정 column으로 대치하기
df1.index = df1['노선명']
df1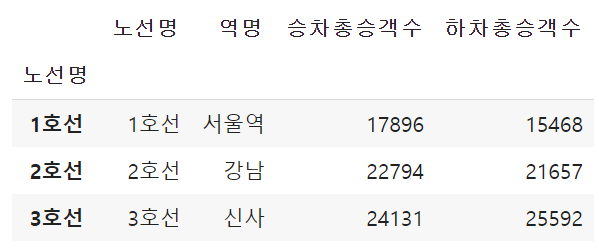
series = column 이라고 하였습니다. 확인해 볼까요? 시리즈 = 인덱스 + 컬럼
df1['역명']
type(df1['역명'])
