주제 : csv나 txt에서 header가 없을 때
1. Header누락에 따른 추가
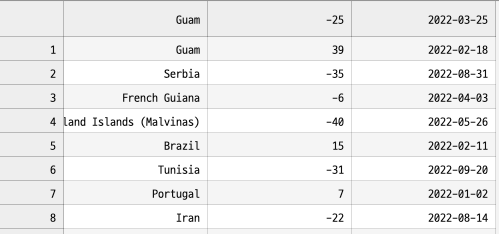
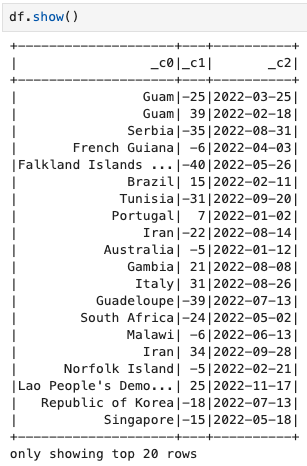
여러가지 방법이 있는듯 하나, 일단 강의에서는 structType을 활용
1-1. types.StructType
유의사항: spark.read.schema(table_schema).csv(csv_file_path) 스키마 먼저 -> csv 읽기
스키마 타입도 명시적으로 제어할수 있음. 스키마 변경 시 코드 수정이 필요
from pyspark.sql import types as t
table_schema = t.StructType([
t.StructField("country", t.StringType(), True),
t.StructField("temperature", t.FloatType(), True),
t.StructField("observed_date", t.StringType(), True)])
])
df = spark.read.schema(table_schema).csv(csv_file_path)1-2. toDF() 사용
개인적으로 toDF() 가 가장 쉽게 사용할수 있을것 같음 .
# 새로운 헤더 정의
new_header = ["column1", "column2", "column3"] # 원하는 헤더 이름으로 변경
# 헤더 추가
df_with_header = df.toDF(*new_header)
# 결과 확인
df_with_header.show()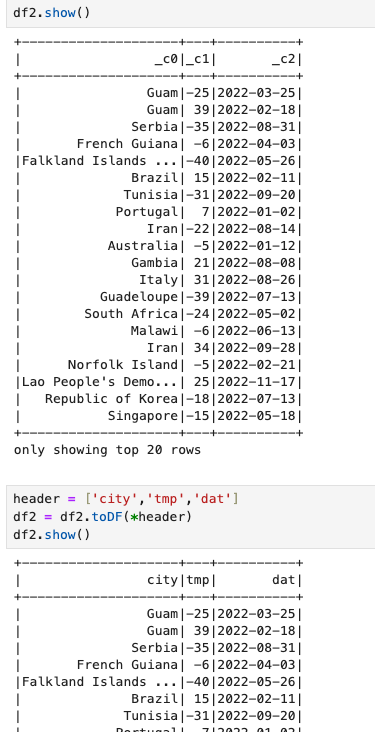

다소Good한 데이터 엔지니어