functions.split()
pyspark.sql.functions.split() 함수는 문자열 컬럼을 특정 구분자(delimiter)를 기준으로 분할하여 배열(Array) 타입의 컬럼으로 변환하는 데 사용됩니다.
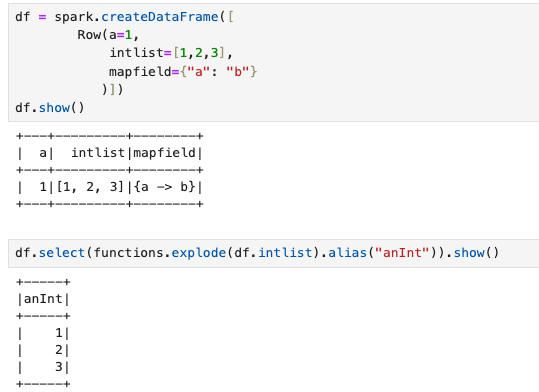
functions.explode()
쉽게 말해 배열이나, map 처럼 한 컬럼에 복수 개 있는 변수를 row 단위로 내려준다.
pyspark.sql.functions.explode() 함수는 배열(Array) 또는 맵(Map) 타입의 컬럼을 각 요소별로 새로운 행으로 분리하는 데 사용됩니다. 즉, 하나의 행에 여러 개의 값이 포함된 컬럼을 여러 행으로 확장하여 각 행에 하나의 값만 포함되도록 변환합니다.
Sample (lorem_ipsum.txt)

2줄 여러문장 .
csv_file_path = "file:///home/jovyan/work/sample/lorem_ipsum.txt"
df = spark.read.text(csv_file_path)
df.show()

step1 . functions.split(' ')
row에 ',' 단위로 나누기
word = df.select(functions.split(df.value, ' ').alias('word'))
word.show()

step2 . functions.explode
words = df.select(functions.explode(functions.split(df.value, ' ')).alias("word"))

step3 . groupBy / orderBy
유의 사항 :
words.groupBy(words.word).count() 의 결과 값인 '카운드' 순으로 정렬을 해야 하는데 functions.col('count')라는 변수를 써서 앞의 값을 불러와야 한다.
words.groupBy(words.word).count().orderBy(functions.col('count').desc()).show()

