PySpark에서 map과 flatMap은 모두 RDD(Resilient Distributed Dataset)나 DataFrame의 각 요소에 함수를 적용하여 새로운 RDD 또는 DataFrame을 생성하는 변환 연산입니다. 하지만, 결과를 생성하는 방식에 차이가 있습니다.
1. map:
일대일 변환:
각 입력 요소에 대해 하나의 출력 요소를 생성합니다. 즉, 입력 RDD/DataFrame의 파티션 수와 출력 RDD/DataFrame의 파티션 수가 동일합니다.
사용 예시: 각 단어를 대문자로 변환하거나, 숫자에 1을 더하는 등 간단한 변환 작업에 적합합니다.
sc = pyspark.SparkContext.getOrCreate();
rdd = sc.parallelize([("name", "joe,sarah,tom"), ("car", "hyundai")])
result = rdd.map(lambda x: x[1].split(","))
print(result.collect())
#[['joe', 'sarah', 'tom'], ['hyundai']]2. flatMap:
일대다 변환:
각 입력 요소에 대해 0개 이상의 출력 요소를 생성하고, 결과를 평평하게 펼칩니다. 즉, 입력 RDD/DataFrame의 파티션 수보다 출력 RDD/DataFrame의 파티션 수가 더 많을 수 있습니다.
사용 예시: 문장을 단어로 분리하거나, 리스트를 개별 요소로 분해하는 등 복잡한 변환 작업에 적합합니다.
rdd = sc.parallelize([("name", "joe,sarah,tom"), ("car", "hyundai")])
result = rdd.flatMap(lambda x: x[1].split(","))
print(result.collect())
# ['joe', 'sarah', 'tom', 'hyundai']1. map Vs flatmap
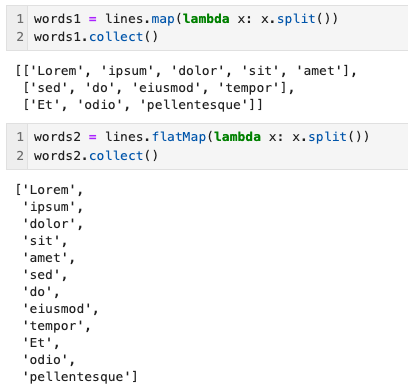
words1 = lines.map(lambda x: x.split())
words2 = lines.flatMap(lambda x: x.split())2. 함수 return 값
같은 정렬인데 리턴하는 타입이 달라.
words.countByValue()
words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
1번 방법 (countByValue):
반환 값: 각 단어(key)와 해당 단어의 개수(value)를 담은 딕셔너리(Python dictionary)를 반환합니다.
장점: 간결하고 직관적인 코드로 단어별 개수를 쉽게 얻을 수 있습니다.
단점: 모든 단어와 개수를 메모리에 저장하므로, 매우 큰 텍스트 파일을 처리할 때 메모리 문제가 발생할 수 있습니다.
2번 방법 (map, reduceByKey):
반환 값: 각 단어(key)와 해당 단어의 개수(value)를 담은 (key, value) 쌍의 RDD를 반환합니다.
장점: 각 파티션에서 단어별 개수를 계산하고 병합하므로, 메모리 효율성이 높습니다. 대용량 데이터 처리에 적합합니다.
단점: 1번 방법보다 코드가 조금 더 복잡합니다.
3. key, value 위치 밖아서 sortByKey로 정렬
cnt.map(lambda x : (x[1] , x[0])).sortByKey(ascending=False).collect()

4. split() vs split(" ")
test_file = "file:///home/jovyan/work/sample/lorem_ipsum.txt"
lines = sc.textFile(test_file)
words = lines.flatMap(lambda x: x.split())
split() vs split(" ")
.split()은 일반적인 공백 문자를 기준으로 문자열을 깔끔하게 분리할 때 유용합니다.
.split(" ")은 스페이스를 기준으로 문자열을 분리하고, 빈 문자열을 유지해야 할 때 사용합니다.
