DataFrame
PySpark에서 DataFrame은 데이터를 테이블 형태로 구조화하여 저장하고 처리하는 데 사용되는 분산 데이터 컬렉션입니다. 쉽게 말해, 엑셀 스프레드시트처럼 행과 열로 구성된 데이터를 다루는 방식이라고 생각하시면 됩니다.
스키마 (Schema): 각 열에는 이름과 데이터 유형 (정수, 문자열, 부동 소수점 등)이 정의되어 있습니다. 이 스키마는 데이터의 구조를 명확하게 파악하고 유효성을 검사하는 데 도움을 줍니다.
다양한 데이터 소스 지원: CSV, JSON, Parquet, JDBC 등 다양한 형식의 데이터를 DataFrame으로 로드하고 저장할 수 있습니다.
FakeData생성
github.com/lucapette/fakedata 활용
data sample ( income.txt)
구분자 '|'
Kam Long|Dominica|VinThomas@example.taobao|137611
Jamey Warner|Botswana|badlittleduck@test.gf|134999
Theola Page|Malawi|sharvin@test.mint|171808
Wes Simpson|Turkmenistan|joshuasortino@example.moto|65429
Loriann Hammond|Argentina|osvaldas@example.dating|183451
Dannie Watts|Virgin Islands, British|abdullindenis@test.fairwinds|194254
Darby Sanders|Timor-Leste|suprb@example.xn--nqv7fs00ema|195497
Willian Cummings|Senegal|areus@test.canon|77369
Patricia Lindsey|Bhutan|mikemai2awesome@test.final|141602
Fae Howell|Timor-Leste|wr@example.xn--3oq18vl8pn36a|147314
Annalee Pearson|Martinique|benefritz@test.furniture|175067코드 설명
from pyspark.sql import Row, SparkSession
from pyspark.sql.functions import col, asc, desc
spark = SparkSession.builder.appName("SparkSQL").getOrCreate()
lines = spark.sparkContext.textFile("file:///home/jovyan/work/sample/income.txt")
income_data = lines.map(parse_line)SparkSession 생성
spark =SparkSession.builder.appName("SparkSQL").getOrCreate():
SparkSession은 PySpark 애플리케이션의 시작점으로, DataFrame API, Spark SQL, Structured Streaming 등 Spark의 다양한 기능을 사용할 수 있도록 해주는 객체입니다.
builder.appName("SparkSQL")은 애플리케이션 이름을 설정하는 부분입니다. Spark UI에서 이 이름을 확인하여 실행 중인 애플리케이션을 식별할 수 있습니다.
getOrCreate() 메서드는 기존에 생성된 SparkSession이 있으면 해당 객체를 반환하고, 없으면 새로운 SparkSession을 생성하여 반환합니다.
SparkContext의 주요 역할:
spark.sparkContext는 Spark 애플리케이션의 핵심 구성 요소 중 하나로, Spark의 기본 연산과 기능을 제공하는 SparkContext 객체를 나타냅니다.
클러스터 연결:
SparkContext는 Spark 애플리케이션을 클러스터와 연결하는 역할을 합니다. 로컬 머신에서 실행되는 단일 노드 모드부터 분산 클러스터 환경까지, SparkContext를 통해 클러스터 리소스를 관리하고 작업을 분산 실행할 수 있습니다.
RDD 생성 및 관리:
SparkContext는 RDD(Resilient Distributed Dataset)를 생성하고 관리하는 주요 인터페이스입니다. textFile()과 같은 메서드를 사용하여 데이터를 RDD로 불러오거나, parallelize()를 사용하여 기존 컬렉션을 RDD로 변환할 수 있습니다.
공유 변수 (Shared Variables):
SparkContext는 애플리케이션 내에서 공유 변수를 생성하고 관리합니다. 공유 변수는 브로드캐스트 변수 (Broadcast Variables)와 누산기 (Accumulators)로 나뉘며, 분산 환경에서 작업 간에 데이터를 효율적으로 공유하고 집계하는 데 사용됩니다.
환경 설정:
SparkContext는 Spark 애플리케이션의 전반적인 실행 환경을 설정합니다. 로깅 레벨, 실행 모드, 설정 파일 등을 지정하여 Spark 애플리케이션의 동작을 제어할 수 있습니다.
텍스트 파일 불러오기
spark.sparkContext.textFile("file:///home/jovyan/work/sample/income.txt")
spark.sparkContext는 Spark의 기본 연산을 담당하는 SparkContext 객체입니다.
textFile() 메서드는 지정된 경로에 있는 텍스트 파일을 불러와 각 행을 원소로 가지는 RDD(Resilient Distributed Dataset)를 생성합니다.
file:///home/jovyan/work/sample/income.txt는 로컬 파일 시스템의 /home/jovyan/work/sample 디렉토리에 위치한 income.txt 파일을 가리키는 경로입니다.
RDD 변환
income_data = lines.map(parse_line)
map(parse_line)은 lines RDD의 각 행에 parse_line 함수를 적용하여 새로운 RDD income_data를 생성합니다.
parse_line 함수는 텍스트 파일의 각 행을 원하는 형태의 데이터로 변환하는 함수입니다. 예를 들어, 각 행을 쉼표(,)로 구분된 값으로 분리하고 특정 열을 정수형으로 변환하는 등의 작업을 수행할 수 있습니다.
PySpark에서 RDD 형태의 데이터를 DataFrame 형태로 변환하고, 메모리에 캐싱하는 과정
전체 과정:
income_data RDD에 저장된 데이터를 Spark DataFrame으로 변환합니다.
이때, parse_line 함수를 통해 변환된 데이터의 형태 (스키마)가 DataFrame의 스키마로 설정됩니다.
생성된 DataFrame을 schema_income 변수에 할당합니다.
cache() 메서드를 호출하여 DataFrame을 메모리에 캐싱합니다.
schema_income = spark.createDataFrame(data=income_data).cache()
- spark.createDataFrame() 함수는 RDD 또는 다른 데이터 소스를 Spark DataFrame으로 변환합니다. 이때, data 매개변수에 변환할 데이터를 전달합니다.
- income_data는 앞서 텍스트 파일을 불러와 parse_line 함수를 적용하여 변환한 RDD입니다. parse_line 함수는 각 행을 원하는 형태의 데이터 (예: 튜플)로 변환
- cache() 메서드는 생성된 DataFrame을 메모리에 캐싱합니다. 이는 DataFrame을 재사용하는 경우 계산을 반복하지 않고 메모리에서 바로 읽어올 수 있도록 하여 성능을 향상시킵니다
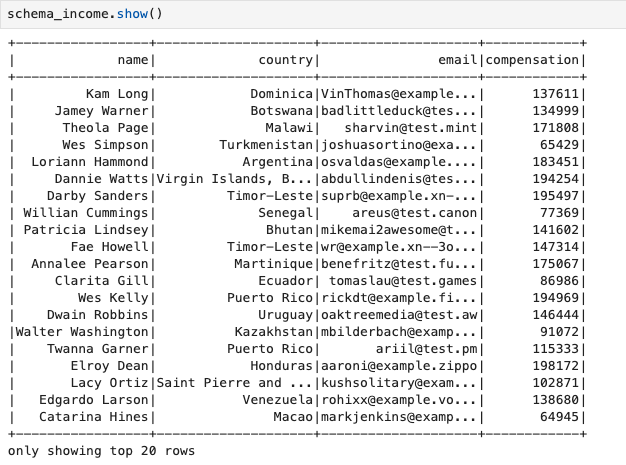
#샘플 확인
schema_income.show()
임시 뷰(view) 생성
PySpark DataFrame schema_income을 임시 뷰 "income"으로 등록하는 코드. 이렇게 등록된 임시 뷰는 Spark SQL 쿼리를 사용하여 데이터를 쉽게 조작하고 분석할 수 있게 해줍니다.
schema_income.createOrReplaceTempView("income")
임시 뷰 : SparkSession 내에서만 유효한 가상 테이블입니다.
SparkSession이 종료되거나 명시적으로 삭제될 때까지 유지됩니다.
SQL 쿼리를 사용하여 데이터를 쉽게 질의하고 조작할 수 있도록 해줍니다.
createOrReplaceTempView("income"):
createOrReplaceTempView 메서드는 임시 뷰를 생성하거나, 이미 존재하는 경우 기존 뷰를 교체합니다.
"income"는 생성할 임시 뷰의 이름입니다. 이 이름은 SQL 쿼리에서 테이블 이름처럼 사용됩니다.
