우테코 크루들과 위 주제로 토의해보았다.
dao - data access object db에 접근하는 객체
repository - 도메인 객체를 저장하고 조회하는 작업을 추상화한 저장소 계층
둘다 모델 계층에서 데이터 저장에 관심이 있는것은 분명하다.
모델 계층에 dao를 둘수도, repository를 둘수도 있다.
세부적인 두개의 차이점이 무엇인지 알아보자.
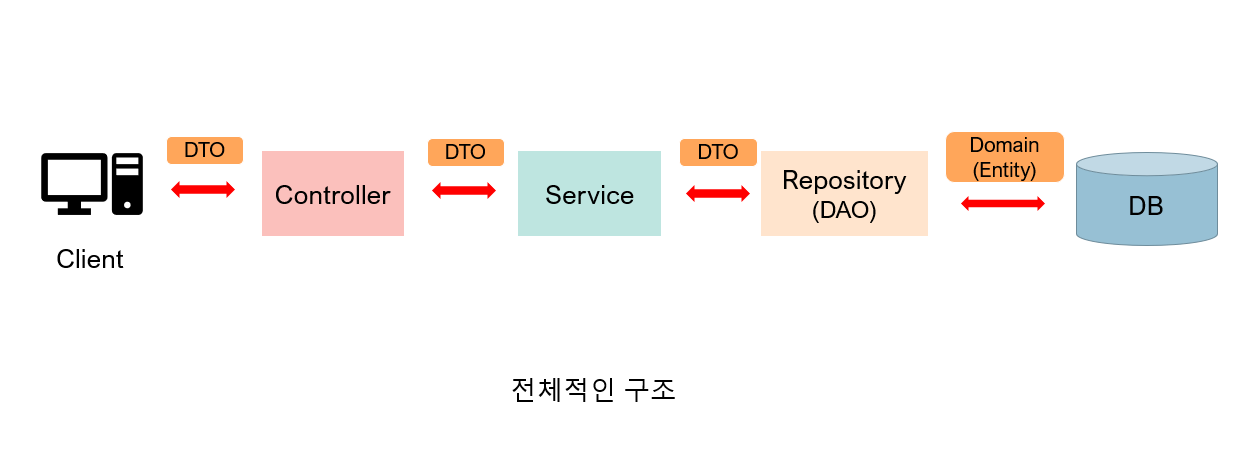
dao vs repo
결론
dao - 데이터 저장을 하고싶은데 "DB"를 쓴다는것
repo - 데이터 저장을 하는데 그것을 위해 DB를쓰던 순수 자바를쓰던 상관쓰지않음
나온 의견
repo는 여러 dao를 가진것이다
-
dao를 여러개 가졌다고 repository가 되는것은 아니라고 생각함
-
repository들이 여러 dao를 가지는 것은 도메인을 수행하기 위해 여러 dao를 가졌던것이지 개수가 중요한것이 아니다.
정리
✅ 언제 DAO를, 언제 Repository를 사용할까?
DAO (Data Access Object)
관심사: DB 테이블, SQL 쿼리, 데이터베이스 작업 자체
모델 계층이 DB 구조와 긴밀하게 연관될 때 적합
이름 자체가 DB 접근을 노출하므로, DB가 주요 관심사일 때 사용
"모델 계층이 DB에 강하게 관심이 있다면 DAO가 자연스럽다."
Repository
관심사: 데이터 저장/조회라는 "행위" 자체에 집중
어디에 저장하는지(DB, 메모리, 파일 등)는 상세 구현에 숨긴다
스프링은 서비스 추상화를 핵심 가치로 삼기 때문에,
Repository를 통해 저장소를 추상화하는 패턴을 권장한다.
"DB건 파일이건 메모리건, 저장 행위 자체를 추상화하고 싶으면 Repository를 쓴다."
📚 요약
"모델이 DB에 직접 관심 있으면 DAO를, 저장 행위만 관심 있으면 Repository를 쓴다.
스프링은 추상화를 중요하게 생각하므로 Repository를 기본 선택으로 삼는다."
