병렬 컴퓨팅 실패~! 이번 아르바이트를 하며 병렬컴퓨팅에 도전하고 논문각까지 보고 있었는데 보기좋게 실패했다. 실패한 이유를 살펴보자
IPyparallel의 전공
IPyparallel은 Sequencial Data Type을 Iterating 할 때 두각을 나타낸다. 예를들어 거대한 크기의 np.array 를 다루거나 엄청난 횟수의 반복작업을 수행할 때 두각을 나타낸다. IPyparallel은 Sequencial Data Type을 쪼갠다. 그리고 가지고 있는 engine들이 (direct view 기준) 작업을 나눠가지고 작업을 수행한 후 필요하면 결과를 합치거나 그냥 그대로 리턴한다.
적용하려고 했던 대상
여기서 적용하려고 했던 대상(코드)은 많은 수의 반복은 있었지만 연산이 아니었다. gdal 이라는 패키지의 멤버 함수를 사용하는 코드였다. 실제로 cProfile 을 사용해서 프로그램의 퍼포먼스를 함수단위로 체크한 결과 프로그램의 소요 시간의 95%를 그 함수가 차지하고 있었다.
그 함수를 쪼개면 되는거 아니야?
그럴 것 같아서 그 함수를 대상으로 apply_async() 를 적용했다. 실제로 IPypallel이 쪼개려고 시도를 할 때 쪼갤 수 없는 함수라고 오류를 뱉었다. 그 함수는 File I/O가 발생하는 함수였고 can't pickle SwigPyObject 가 발생했다.
다른 연산에 도입해보자
실행 시간을 조금이라도 줄여보고자 np.random() 이나 사칙연산들에 도입을 하고자 했다. 일단 numpy 연산에 도입을 시도했고 결과는 다음과 같았다.
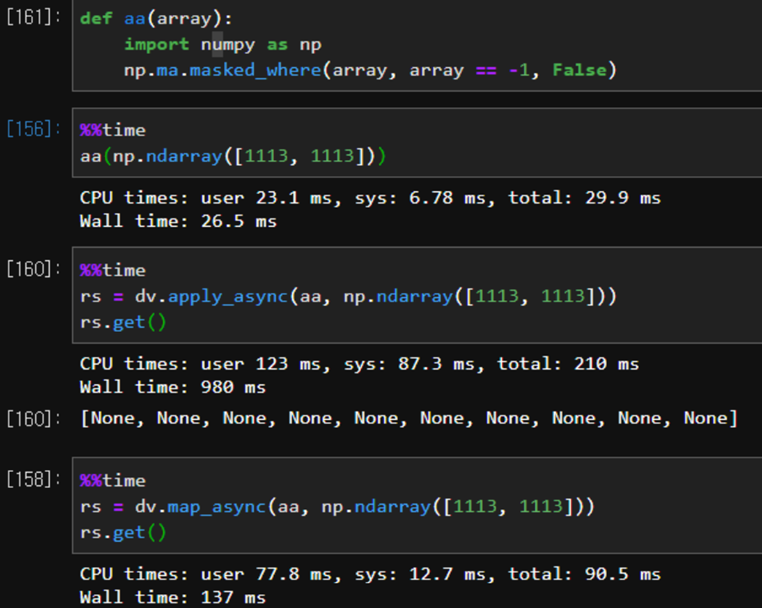
- Non-Ipyparallel: 26.5ms
- apply_async: 980ms
- map_async: 137ms
map_async는 약 6배 증가, apply_async는 약 40배 증가했다. 반복하지 않으니 오히려 시간이 증가해버린다.
다음엔 date 패키지의 멤버함수에 도입해봤다.
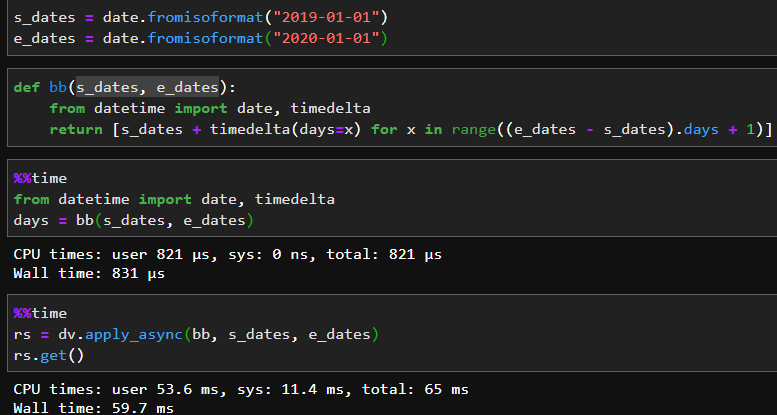
- Non-Ipyparallel: 831μs
- apply_async: 59.7ms
이번엔 아예 단위가 바뀔정도로 크게 증가해버렸다.
결론
Ipypallel은 반복 횟수가 많거나 shape이 큰 Sequencial Data Type에 도입하자
.jpg)