2020 3분기 KISTI 슈퍼컴퓨팅인프라센터 아르바이트 일지
1.Fetch API
웹 개발을 할 때 ajax 통신을 자주 사용한다. ajax를 사용할 때 XHR, JQuery, Fetch 등의 선택지가 있지만 셋 다 사용해봤을 때 JQuery와 Fetch가 당연한 소리지만 압도적으로 좋은 것 같다. (생산성 측면에서) 앞으로 추세가 JQuery를 쓰
2.conda란?

운이 좋게 이번 방학에 KISTI 슈퍼컴퓨팅인프라센터에서 알바를 하게 되었다. 슈퍼컴퓨터의 OS는 당연히 linux이고 Centos를 사용하고 있었다. 개발을 하던 도중 깔려있지 않은 파이썬 패키지를 발견했고 설치하려고 pip install {패키지명}을 입력하는 찰나
3.JQuery AJAX
지옥의 Legacy CODE 아르바이트 업무 수행 중 JupyterHub에서 짜놓은 JQuery AJAX, 아르바이트 전임자가 짜놓은 JQuery, 아르바이트 전임자가 짜놓은 Fetch, 내가 짠 Fetch까지 해서 지옥의 LEGACY CODE를 유지보수하고 있다. 유
4.Ipyparallel 문서 읽기
.png)
ipyparallel IPython은 병렬 컴퓨팅과 분산 컴퓨팅을 제공한다. 벙렬 컴퓨팅과 분산 컴퓨팅에는 몇가지 방법이 있다. 내가 읽은 문서에는 다음과 같은 방법들을 제시했다. Single program, multiple data(SPMD) parallelism
5.IPython Magic Command

40TB에 달하는 위성 데이터를 전처리 하기 위해서 IPyparallel을 활용해 코드를 병렬화하는 중 전처리 코드에서 어떤 부분이 시간이 오래걸리는지 확인을 해야 했다. 그래서 함수들을 벤치마크하는 중 Magic Command를 알게 되었다. Magic Command
6.IPyparallel 도입 실패
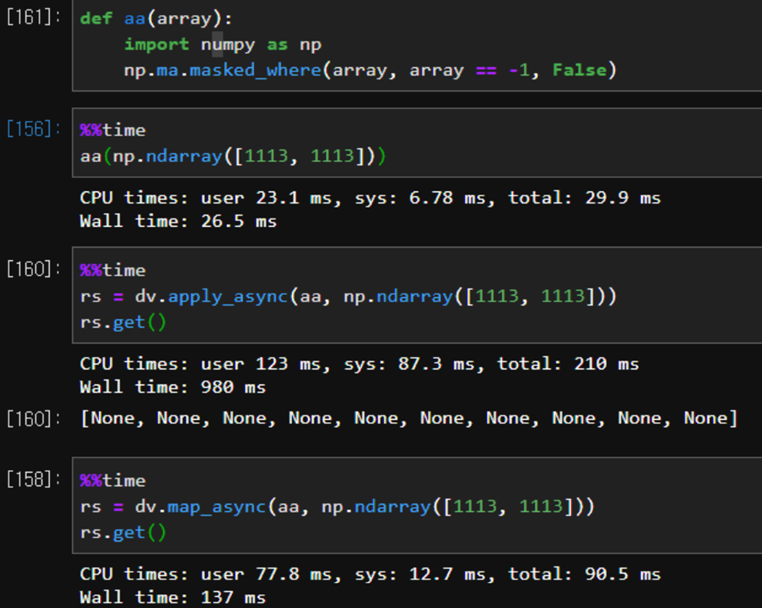
병렬 컴퓨팅 실패~! 이번 아르바이트를 하며 병렬컴퓨팅에 도전하고 논문각까지 보고 있었는데 보기좋게 실패했다. 실패한 이유를 살펴보자IPyparallel은 Sequencial Data Type을 Iterating 할 때 두각을 나타낸다. 예를들어 거대한 크기의 np.a
7.tensorflow 학습 기록하기
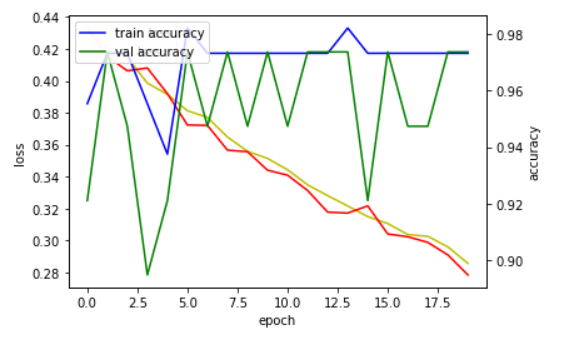
논문을 작성하기 위해 기웃거리던 중 기록이 가장 중요하다는 것을 알았다. 데이터의 형태, 모델의 구성, 학습의 결과 등 논문을 구성하는 요소는 많지만 이런 것들을 잘 기록을 해야한다. 그래서 이번에는 학습의 결과를 기록하는 방법에 대해서 알아보려고 한다. keras h
8.tensorflow 분산처리

아르바이트를 하다보니 GPU를 2개씩 사용할 수 있게 되었다. 그런데 분산처리에 대한 코드를 작성하지 않으면 GPU를 하나만 사용할 수 있다. 이게 너무 아까워서 분산처리를 공부하려고 한다. 공식문서를 읽어보자.tf.distribute.Strategy 는 다수의 GPU
9.Python subprocess, pexpect

flask api 서버와 os와 상호작용하기 아르바이트 중 이런 업무를 할당 받았다. root 권한에서 특정 user 권한으로 진입하기 (su - {username}) 특정 user 권한에서 conda 환경 activate 하기 (conda activate {envs