.png)
ipyparallel
IPython은 병렬 컴퓨팅과 분산 컴퓨팅을 제공한다. 벙렬 컴퓨팅과 분산 컴퓨팅에는 몇가지 방법이 있다. 내가 읽은 문서에는 다음과 같은 방법들을 제시했다.
- Single program, multiple data(SPMD) parallelism
- Multiple program, multiple data(MPMD) parallelism
- Message passing using MPI
- Task farming
- Data parallel
- Combinations of these approaches
- Custom user-defined approaches
IPython은 모든 방법으로 개발하고 실행하고 디버깅하고 모니터링 할 수 있다고 한다. IPython을 활용하는 몇가지 예시상황을 살펴보자
- 간단한 문제들을 빠르게 병렬화할 수 있다. 대부분의 간단한 문제들은 1~2줄의 코드로 병렬화할 수 있다.
- 사용자 컴퓨터의 IPython 세션을 이용해서 MPI 기반의 슈퍼 컴퓨터를 조종할 수 있다.
- 빅데이터를 분석하고 시각화 할 수 있다. matplotlib 처럼..
- 새로운 병렬 알고리즘을 개발, 테스트, 디버깅 할 수 있다. Interactively..
- 서로 다른 시스템에서 실행되고 있는 여러개의 MPI 작업들을 하나의 거대한 병렬분산 시스템으로 묶을 수 있다.
- 병렬화한 작업을 당신의 클러스터에서 시작하고 협업자가 조종할 수 있도록 연결할 수 있다. 그리고 데이터를 뽑아 낼 수 있다. 연결된 사람들의 local Ipython 세션으로 그 데이터들은 가공할 수 있다.
- Dynamic Load Balancing으로 CPU들에게 작업을 분배할 수 있다.
Architecture Overview
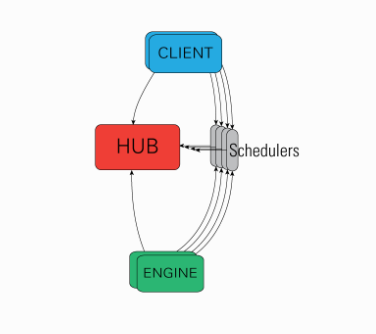
IPython Arichitecture에는 다음과 같이 4개의 컴포넌트가 존재한다.
- IPython Engine
- IPython hub
- IPython schedulers
- IPython client
이 컴포넌트들은 ipyparallel에 존재하고 pip나 conda로 설치할 수 있다.
IPython Engine
IPython Engine은 Jupyter의 IPython kernel의 확장기능이다. Engine은 네트워크를 통해 Jupyter Notebook으로부터 요청을 받고 코드를 실행하고 결과를 리턴한다. IPython parallel은 Jupyter messaging protocol을 상속받아서 native Python object serialization과 몇가지 추가 명령어들을 지원한다. 여러개의 엔진을 실행시키면 병렬 컴퓨팅과 분산 컴퓨팅이 가능해진다.
IPython Controller
IPython Controller 프로세스들은 IPython Engine들과 작업할 수 있는 인터페이스를 제공한다. 일반적으로 Controller는 IPython Engine과 클라이언트를 연결할 수 있는 프로세스들의 집합이다. Controller는 Hub와 Scheduler 집합으로 구성되어 있다. Scheduler는 허브와 동일한 시스템에서 별도의 프로세스로 실행된다.
Controller는 Controller와 연결되어 있는 Engine에게 접근하고 싶어하는 유저에게 단일 접점을 제공한다. Controller와 적업하는 방법에는 몇가지 방법이 있다. IPython에서는 모든 모델이 구현되어 있다.
IPython에서 이러한 모든 모델은 엔진의 하위 집합을 나타내는 View 오브젝트를 생성 한 후 View.apply() 메소드를 통해 구현된다.
Engine과 작업하는 방식에는 가장 중요한 2가지 모델이 존재한다.
Direct Interface: Engine이 명시적으로 address되는 방식Load Balanced interface: Scheduler가 적절하게 작업을 분배하도록 하는 방식
IPython Hub
IPython Cluster의 중심은 Hub이다. Hub는 엔진 집합, 스케쥴러 클라이언트, 요청된 모든 작업들과 결과를 지속적으로 추적할 수 있게 하는 프로세스이다. 허브의 주요 역할은 클러스터 상태 쿼리를 용이하게하고 새 클라이언트 및 엔진 연결과 관련된 많은 연결을 설정하는 데 필요한 정보를 최소화하는 것입니다.
IPython Schedulers
모든 작업들은 Scheduler를 거쳐 engine에서 수행된다. 사용자의 코드가 실행될 때 엔진 자체가 차단되는 반면, Scheduler는 Engine set에 대해 완전한 비동기식 인터페이스를 제공하기 위해 이 사실을 숨긴다.
Ipython client and views
Client는 Cluster에 연결하기 위한 아주 중요한 오브젝트 중 하나이다. 각각의 실행 모델 마다에는 실행모델에 맞는 View가 존재한다. View들은 인터페이스를 통해 사용자가 Engine을 사용할 수 있도록 한다.
다음과 같이 default view는 2가지가 존재한다.
DirectView class: 명시적으로 address되는 방식을 위함(아마도 Direct Interface)LoadBalancedclass: 목적지에 구애받지 않는 스케쥴링 방식을 위함(아마도 Load Balanced Interface)
Security
IPython은 네트워킹을위해 ZeroMQ를 사용한다. ZeroMQ는 아직 암호화와 인증을 지원하지 않는다. 기본적으로 IPython connection은 암호화되어 있지 않지만 localhost의 port만 사용한다. IPython의 유일한 암호화는 ssh-tunnel이다. IPython connection은 shell, paramiko 기반 터널을 모두 지원한다.
DirectView
IPython Engine 세트와 함께 작업할 수 있는 인터페이스 중 하나이다. Multiengine Interface는 각 엔진들이 직접적으로 사용자에게 제공되는 것이다. 각 엔진들에 id가 부여되고 사용자는 그 id를 사용해서 작업을 분배할 수있다. Direct Interface는 직관적으로 디자인되어 있기 때문에 IPython 초보자에게 추천하는 방식이다.
Getting Started
Install ipyparallel
ipyparallel 4.0 버전부터는 stand-alone package라고 한다. 다음 명령어로 설치하자
conda install ipyparallel
주의사항: ipyparallel을 설치하기 이전에 jupyter notebook이 설치되어 있어야 하는 듯 하다.

필자 같은 경우에는 ipy관련한 패키지들이 설치가 되었다. ipyparallel은 6.3.0 버전이다.
Start controller and engines
ipcluster command를 사용해서 하나의 컨트롤러와 4개의 엔진을 생성하자. 위에어 언급지만 컨트롤러들이 엔진들과 클라이언트를 연결하는 프로세스이다. Hub와 Scheduler의 집합이다. 어쨌든 터미널에서 다음 명령어를 입력하자 ipcluster start

Create client
import ipyparallel as ipp
c = ipp.Client()
c.ids
c[:].apply_sync(lambda: "Hello, World!")Quick and Easy Parallelism
파이썬 함수를 병렬로 처리하고 싶을 때 DirectView.map 을 사용하면 목적을 달성할 수 있다.
Parallel map
파이썬 내장함수 map() 은 각 원소마다 함수의 동작을 실행시킬 수 있다. map() 같은 유형의 동작을 하는 코드들은 병렬화 시키기가 쉽지가 않다. 반면에 IPython Interface는 모든 함수에 적용이 가능하다. 내장 map() 과 RemoteFunction 을 사용해도 되고 DirectView.map() 를 사용해도 된다.
serial_result = list(map(lambda x:x**2**2, range(30)))
parallel_result = dview.map_sync(lambda x:x**2**2, range(30))
serial_result==parallel_result # TrueRemote Function Decorators
Remote Function은 일반적인 함수처럼 보이지만 호출될 때 하나 이상의 엔진을 실행시킨다. 아래와 같이 두 개의 decorator를 제공한다.
@dview.remote(block=True)
def getpid():
import os
return os.getpid()
import numpy as np
A = np.random.random((64,48))
@dview.parallel(block=True)
def pmul(A,B):
return A*B
C_local = A*A
C_remote = pmul(A,A)
(C_local == C_remote).all() # True@parallel 은 병렬 함수를 생성한다. 엘리먼트들을 알아서 분할하고 각 엔진들에게 분산하고 다시 합쳐준다. 고마운 친구! @parallel 은 map을 호출하는 친구가 아니다. Sequence Data 타입 엘리먼트[ex) array]들을 분할하고 분배하는 친구이다. map 동작을 원하면 map을 쓰자 아래 표 참고
| call | pfunc(seq) | pfunc.map(seq) |
|---|---|---|
| # of tasks | # of engines (1 per engine) | # of engines (1 per engine) |
| # of remote calls | # of engines (1 per engine) | len(seq) |
| argument to remote | seq[i:j] (sub-sequence) | seq[i] (single element) |
아래 예제 코드를 참고해서 차이를 살펴보자
@deview.parallel(block=True)
def echo(x):
return str(x)
echo(range(5)) # Return Sequence Element
# ['range(0, 1)', 'range(1, 2)', 'range(2, 3)', 'range(3, 4)', 'range(4, 5)']
echo.map(range(5)) # Return Single Element
# ['0', '1', '2', '3', '4']Calling Python Functions
엔진에서 수행할 수 있는 가장 기본적인 작업 유형은 Python 코드를 실행하거나 Python 함수를 호출하는 것이다. 파이썬 코드는 View.excute(), View.applu 메소드를 통해 Blocking, Non-Blocking 두 가지로 실행될 수 있고 Non-Blocking이 기본값이다.
Apply
View.applu() 는 함수를 실행 시키는 작업을 하는 함수 중 가장 중요한 함수이다. 실제로 엔진과 소통하는 메소드들이 모두 apply() 위에 구현이 되어 있다.
Apply's Methods
- apply
- apply_async
- apply_sync
apply 함수는 DirectView의 flag 들에 의해 속성을 설정할 수 있다.
DirectView's Flag
- dv.block (bool)
- dv.track (bool)
- dv.targets (int, list of ints)
Blocking Execution
Blocking 모드에서는 DirectView 객체가 컨트롤러에게 커맨드를 제출하여 엔진 큐에 명령을 실행한다. 한 마디로 동작이 끝날 때까지 기다려준다는 것이다. 동기 동작이다. 당연히 Non-Blocking은 비동기 동작이다.
Moving Python objects around
함수를 호출하는 것뿐아니라 파이썬의 객체를 IPython session과 엔진에 전달할 수 있다. 이것을 가능하게 하는 메소드는 push 와 pull 이다. 또한 python의 dictionary interface를 사용할 수 있다.
ex) dview['a'] = ['foo','bar']
return: [['foo', 'bar'], ['foo', 'bar'], ['foo', 'bar'], ['foo', 'bar']]
Scatter and gather
각 엔진들에게 sequence를 나눠서 할당하는 것이 유용할 때가 많다. MPI에서는 이것을 scatter, gather 라고 부르는데 IPython도 MPI를 따르기로 했다.
dview.scatter('a',range(16))
return: [range(0, 4), range(4, 8), range(8, 12), range(12, 16)]
AsyncResult
IPython의 많은 함수들이 AsyncResult 타입을 리턴한다. 이 녀석을 자세히 알고 싶다면 다음과 같은 코드를 실행해보자.
ar = dview.apply_async(wait, 2)
ar.get()
ar.metadata.jpg)