데이터 분석과 소통의 중요성
성능 향상을 위해서 모델만을 중요하게 생각했던 나에게 데이터의 중요성을!
LG Aimers : LG Aimers 홈페이지
LG Aimers Online Hackathon (DACON) : 온라인 채널 제품 판매량 예측 AI 온라인 해커톤
PUBLIC SCORE

PRIVATE SCORE

대회 시작 전
LG Aimers 3기 Phase 1 온라인 강의를 듣고 Phase 2가 시계열 데이터를 통해 판매량 예측이라는 것을 알았다.
그래서 대회 시작 7일 전부터 정형 데이터나 시계열 데이터를 어떻게 분석하고 활용해서 성능을 올리는지에 대한 자료를 많이 찾아봤다.
그럼에도 정형 데이터나 시계열 데이터를 다뤄보지 않았던 나는 불안해졌고 팀을 꼭 구해야겠다고 생각했다.
대회 시작 2일 전 쯤인가부터 사람들이 팀원을 모으기 시작해서 대회 경험이나 시계열 데이터를 다뤄본 사람들에게 연락을 남기고 했지만 아무 팀도 가지 못했었다.
이미지 데이터만 다뤄본 나의 큰 욕심이었던 거 같다.
잘하는 사람이 아니어도 다 같이 열심히 해서 올라가보자.
위처럼 생각하고 팀을 찾던 중에 글 하나가 올라왔고 거기에서 같이 시작하기로 했다.
1주차
첫 대회라 그런지 어떻게 될지 몰라서 급하게 이것저것 다 하려고 하였다.(지금 돌이켜 보면 여유롭게 해도 될 것 같다.)
대회 시작하자마자 데이터를 다운 받고 데이터 분석을 위해 데이터구조를 내가 미리 공부하며 봤던 데이터 구조와 비슷하게 수정하고 여러 파일들을 하나의 DataFrame으로 합쳤다.
수정 전
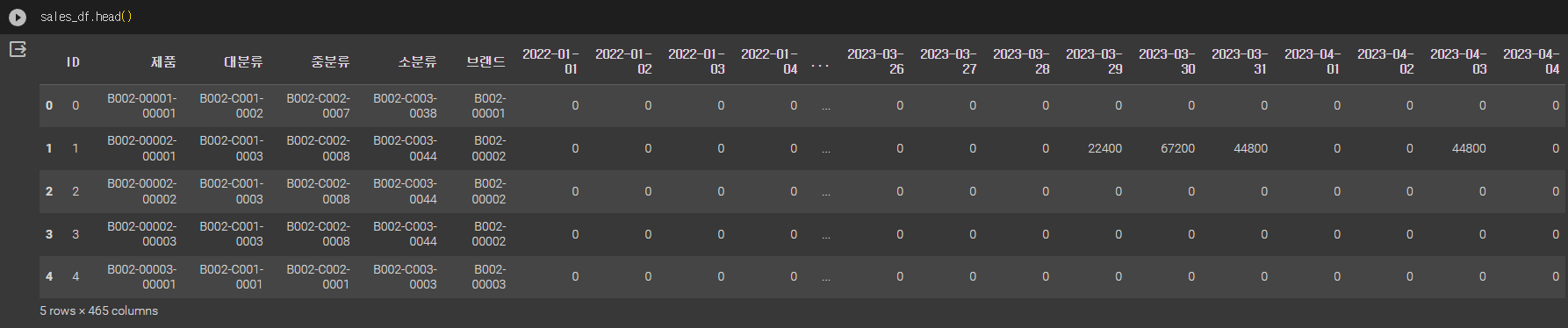
수정 후
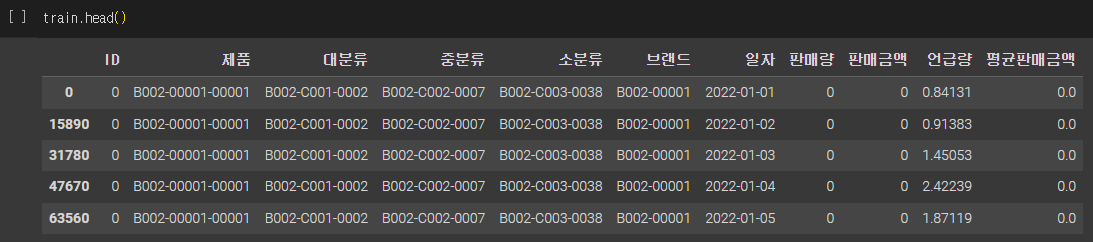
이렇게 수정한 후에 나름대로 여러 분석을 한다고 하는데 딱히 유의미한 분석은 얻지 못했다....
3일 동안의 분석 후 팀원들과 첫 회의를 진행했다.
대회에서의 첫 회의여서 무엇부터 정하고 해야할지 잘 몰라서 팀원들의 말을 따라갔던 것 같다.
회의 날짜, 인사이트 공유, 코드 공유를 어떤식으로 할지 대충 정하고 마지막으로 역할 분담을 진행하였다.
다들 데이터 분석경험이 없다고 하여 모델을 찾아 구현해오겠다고 하였다.
모델링에는 어느정도 자신 있었지만... 그래도 데이터 분석은 해야하고 나름 중요하다고 생각했기 때문에 나는 데이터 분석을 하겠다고 말했던 것 같다.
이렇게 팀이 만들어지고 대회를 진행하게 되니까 설레기도 하고 재밌다는 감정이 들었던 거 같다.
2주차
나름 데이터를 열심히 분석하면서 얻은 결과들을 팀원들과 연락하며 공유해서 어떻게 활용하면 좋을지 이야기 해주면서 한주를 보냈던 거 같다.
가장 기억에 남는 것은 내가 분석한 방법이 실제로 큰 성능을 향상시킨 것이 너무 기뻤다는 것이다.
제품의 개당 판매금액이 일정할 것이라고 판단하여 개당판매금액 속성을 만들었고 실제로 이 속성이 일정하다는 것을 확인했다.
또한 판매금액이 판매량보다 변화량이 적고 경향성이 일정한 것을 확인했다.
이를 활용해 판매량을 직접 예측하는 것보다 판매금액과 개당 판매금액을 예측하여 판매량을 예측하는 것이 더 좋은 성능을 낼 것이라고 생각했다.
판매량을 바로 예측하는 방법의 성능이 0.46이었는데 저 방법을 통해 0.52로 큰 성능 향상을 이뤄냈다.

새벽에 너무 기분이 좋아서 캡처했던 기억이 있다.
이후 2주차 회의에서 팀명을 정하는 과정에서 팀장을 정하기로 하였고 팀장으로 제가 추천되었고 팀장이 됐다.
너무 급격히 진행되어서 당황했다.
얼떨결에 팀장이 되었지만 아마 팀원들과 의견 공유하느라 연락을 하던 이유가 컸던 거 같다.
3주차
그간 팀원들에게 답답함이 생겨났고 계속 혼자 힘들어 하고 있었다.(아마 데이터 분석이 잘 안되고 있었던 이유도 포함 되어있었을 것 같다...)
다들 모델링 파트를 맡고 연구 중이라고 하는데 성능 비교를 위한 기초모델을 잡지도 않고 구조 개선, 하이퍼 파라미터 튜닝에 관한 실험이 전혀 없던 것이다.
너무 답답하여 회의 시간에 대회 기간 동안 어떤 실험을 진행 했는지 물어봤는데 다들 "~모델을 학습시켜봤습니다"가 대답의 끝이었다.
다른 내용은 더 없었다.
솔직히 팀원들을 믿고 모델링을 맡긴 것인데 3주동안 튜닝 없이 학습을 했다 정도가 끝이어서 많이 실망했다....(나도 데이터 분석 처음이고 열심히 하면서 모델 학습도 돌려서 결과 확인했는데...)
물론 중간중간 어떤 걸 했는지 세세하게 물어보지 않은 내 잘못도 있다.
모델링, 데이터 분석 둘 다 어려워 하면 차라리 데이터 분석을 같이 하자
다들 모델링이 중요하다고 생각하여 모델링을 했지만 만족스럽지는 않았다.
그래서 데이터 분석의 중요성과 실험 기록의 중요성을 언급하며 근거 자료를 보여주며 팀원을 설득했던 거 같다.
실험 가이드라인 이상치 확인 가이드라인을 제공하였고 15890개의 제품에 대해서 각자 같은 비율로 나누어 이상치 분석을 진행하였다.
확실히 얘기하고 나니 마음도 편해지고 다들 방향성을 잡게되어 이전보다 실험 속도도 빨라졌다.
협업에서 팀원과의 자세한 의사소통을 하는 것은 중요하다 라는 것을 알게되었다.
4주차
4주차에 데이터 분석 방향성을 잘못 잡은 거 같다...(팀원들에게는 미안했다..)
이전까지는 나름 성능향상을 이루고 있었지만 제품별 상품 설명을 보다가 상품 설명 내에 제품군과 조금 동떨어진 상품 내용이 존재하는 것을 확인했고 여기에 꽂히게 됐다...
제품 군 내에 상품이 잘못 분류 되어 섞여있다고 판단했고 이는 아래와 같이 이상치를 일으켰다고 판단했다.
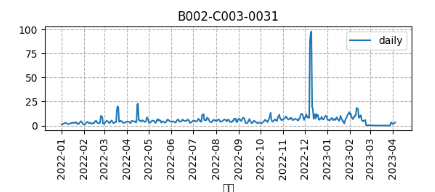
이 때문에 팀원들을 설득하여 모든 상품 내용을 분석하였고 잘못된 것을 바로 잡고 다시 그래프를 그렸는데 달라지는 건 없었다...
마지막 주차인데 3일을 날렸던 거 같아서 팀원들에게 미안했었다...
여차저차 시간이 지나고 마지막 날 모델 결과에 대해 Ensemble을 진행 하였고 마지막까지 성능을 올리게 되었고 Public 37등 Private 45등으로 마무리 하였다.
대회가 마무리 되고
길었던 대회가 마무리 되었다.
대회 내내 정말 신기했던 것 같다.
LSTM의 문제가 장기 의존 문제가 있다고 생각해서 당연히 시계열에서도 Transformer계열의 모델이 있고 더 좋은 성능을 낼 것이라고 판단했었다.
특히 LSTM이 나름 오래된 모델이라고 생각하였어서 더 안좋은 성능을 낼 것이라고 생각하기도 했다.
데이터를 분석하여 더 좋은 특징들을 뽑아내고 모델에게 주니 더 적은 학습으로도 Transformer 모델보다 좋은 성능을 냈다.
평소 모델 구조를 수정해서 성능을 조금씩 올렸엇지만 데이터를 잘 처리 하여 모델을 학습하니 성능이 크게 향상되는 것을 보고 놀랐다.
이 대회를 통해 데이터의 중요성을 깊이 체험한 것 같다.

Private 등수가 나오기 전 Public 등수가 37등이었고 36등까지 97명이었어서 본선 진출을 기대하고 있었다.
아쉽게 Private 등수가 많이 떨어지게 되어 안되겠다고 생각했다.
팀원들도 다들 결과를 보고 서로에게 고생했다고 인사를 나누었다.
그렇게 대회가 잊혀지던 중 DACON에서 전화가 왔는데 들어보니 확인전화였다.
"LG-99 팀에서 코드, 가중치, PPT를 제출하지 않으셔서 누락된 것인지 물어보려고 전화했어요"
"저희 탈락 아닌가요?" 하고 물어보니 제출했으면 가능성이 있었다고 한다....
팀원 모두가 탈락인줄 알고 PPT를 만들 생각도 보낼 생각도 하지 않았다.
규칙을 자세히 보니 '오프라인 해커톤 진출을 희망하는 팀은 코드 제출 후 코드 평가(검증)'이라고 나와 있다.
Private 30등 이내도 아니고 100명 미달도 아니어서 진출 못한 줄 알았었다....
그래도 제출을 안한 거는 맞으니 안했다고 했다.
오프라인 진출 대상자를 보니 더 낮은 점수를 받은 팀들도 진출한 것을 보았다.
그래도 제출했더라도 그 결과는 몰랐을 것 같기 때문에 그나마 좀 괜찮은 것 같았다.
첫 대회였지만 상위 7%라는 좋은 성적을 받은 것으로 위로를 하며 대회를 완전히 마무리 하였다.
여러모로 아쉬운 대회였지만 좋은 경험과 좋은 깨달음을 얻었던 것 같다.

4개의 댓글

재미있는 글 잘 읽었습니다. MIC논문 포스팅을 읽어보려 오다가 여기까지 왔네요 ㅎㅎㅎㅎ
공교롭게도 저도 이번 LG Aimers 4기에 지원하여 2월부터 Phase 2기를 진행합니다!
저도 태훈님처럼 좋은 결과를 얻었으면 좋겠네요 ㅎㅎㅎㅎ
좋은 글 감사합니다. 인공지능을 이제 배워 보려는 학생입니다. 이러한 대회는 머신러닝인가요 딥러닝인가요? AI 라고만 나와있어서 잘 모르겠습니다