포기하지 말고 끝까지!
대회 중 포기할까 고민을 정말 많이 했지만 버텨내서 상위권까지!
※코드와 PPT는 제 Github나 아래 DACON URL에서 코드 공유 게시판에 올려두었습니다.
GitHub : Unsupervised-Domain-Adaptation-with-Distortion-Aware
DACON URL : 2023 Samsung AI Challenge : Camera-Invariant Domain Adaptation
참고한 UDA 방법론 논문 리뷰 : DACS, DAFormer, MIC

PUBLIC SCORE

PRIVATE SCORE

대회 입문
LG Aimers 3기에서 온라인 해커톤을 진행하며 처음 대회에 나가며 DACON을 접했고 대회가 마냥 재미있었다.
이후 다른 대회가 무엇이 있나 보던 중에 Samsung AI Challenge 관련 대회 3개를 보게 되었다.
나는 주로 Segmentation에 대해서 공부하였고 리더보드 성능(mIoU)도 0.1정도를 달성하고 있어 쉬운 대회라고 생각하여 Camera-Invariant Domain Adaptation 분야를 선택해 대회를 참여했다.( 0.1이면 그런 이유가 있을텐데.... )
처음에 Domain Adaptation이라는 것을 보지 못하고 그냥 자율주행용 Image Segmentation 대회라고 생각하였다.
막상 대회에 참여 하려고 하니 데이터 셋에 라벨이 없는 Target Data가 있는 것을 보았고 많이 당황했다.
라벨이 없는 데이터를 사용해 학습에 사용한다고?
항상 라벨이 있는 데이터만 다루다가 라벨이 없는 데이터를 다루는 것은 처음이라 다음에 비슷한 대회를 참여하자 생각하기도 했지만 그냥 머리 박고 해보자라는 생각으로 나의 두번째 대회에 입문했다.
대회 규칙
LG Aimers 온라인 해커톤에서 규칙을 제대로 읽지 않아 오프라인 해커톤 참여를 못했었다.
아래는 LG Aimers 온라인 해커톤 평가 방식이다.

1차평가가 Private Score 100% 라고 해서 상위 30개의 팀만 2차평가 대상인줄 알고 Private 45등을 하여 안되는 줄 알고 그냥 넘어갔다.
나중에 DACON에서 연락이와 PPT나 파일 제출을 안한 것이 맞는지 물어봐서 다시 규칙을 확인해보니 진출을 '희망'하는 팀이라고 되어 있었다...(나중에 알고보니 최대 53등까지 오프라인 해커톤에 진출했다)
기회를 그냥 날린 거 같아서 많이 아쉬웠다.
이런 아픈 경험을 안고 대회 규칙부터 자세히 살펴 보았고 그 중 평가 방식을 주로 보았다.
아래는 삼성 AI Challenge 평가방식이다.
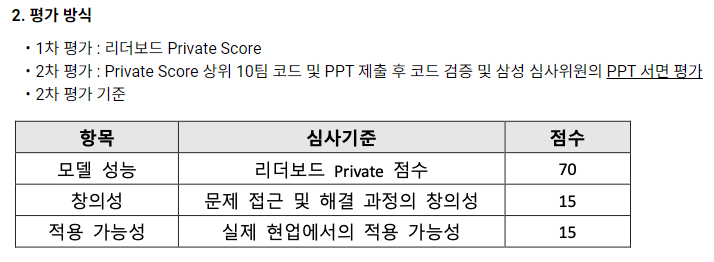
이 규칙을 보고 대회 진행 방향성을 다음과 같이 생각했다.
-
Unsupervised Domain Adaptation(UDA)기법을 사용할 것(대회 목적)
본 대회의 목적 자체가 Source Domain과 Target Domain간의 Gap을 줄이는 것이 목적이다. 특히, 주어진 데이터셋을 충분히 활용하기 위해서 라벨이 없는 Target 이미지도 사용하여야 함은 분명하기 때문이다. -
나만의 Domain Adaptation 기법을 생각할 것(창의성)
본 대회는 다른 UDA 기법들과는 달리 카메라 왜곡에 의한 Domain Gap을 줄이고자 하는 것이다. 확실히 SOTA 모델들을 보면 GTA5, Cityscape 등 왜곡을 고려한 Domain Adaptation 기법은 보이지 않는다. Domain Adaptation에 대해 잘 알지 못하기에 완전히 새로운 방법을 제안하기보다 기존의 방식을 기반으로 본 대회에 맞게 방법론을 고치는 방향으로 가기로 했다. -
연산량을 최대한 줄여볼 것(적용 가능성)
알고리즘을 실제 현업에서 적용하기 위해 고려해야할 부분은 결국 알고리즘의 성능과 처리 속도이다. 단기간 내에 연산량을 신경쓰며 구조, 모델, 파이프라인을 모두 고칠 수는 없지만 가능한 연산량을 줄이며 좋은 성능을 내도록 노력하며 대회를 참여하려고 하였다.
대회 중
방법론 선택
대회는 9월 1일부터 시작을 하였다.
Paper with code 사이트에서 Unsupervised Domain Adaptation 관련 논문들을 읽어보는데 쉽지 않았다.
대부분 데이터셋에서 좋은 성능을 내는 MIC논문을 보니 DAFormer 기반으로 한 논문이고 DAFormer는 DACS에서 사용한 기법을 사용한다고 한다.
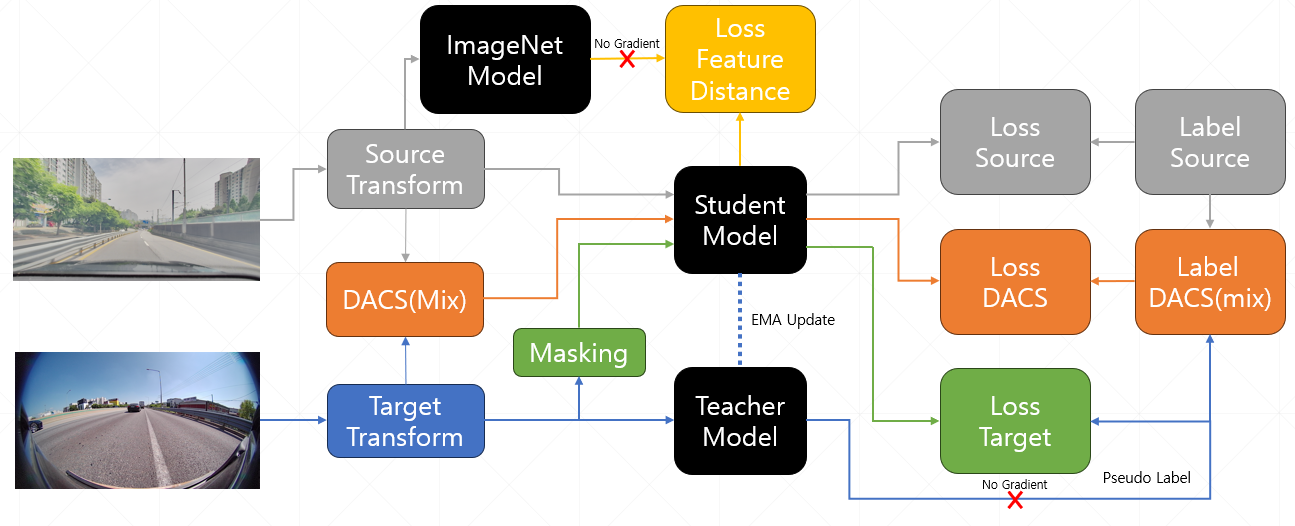
※MIC 구조
구현 내용도 자세히 안나와있고 코드를 봐도 처음보는 mmSegmentation을 사용해서 코드 구조도 파악하기 어려웠었다. 그래서 다른 사람들이 논문 리뷰를 한 자료가 있나 찾아보아도 없었다.
이러다 보니 정말 논문 보고 코드 보고 머리 박으면서 최대한 자세히 구현하려고 노력하였다.
어느정도 파이프라인을 구현하고 Colab에서 Tesla T4를 사용해 약 3000장의 이미지(이미지 해상도 256x512)를 학습해보니 한 에폭당 28분이 나왔다.
논문에서는 40000에폭 학습했다고 한다.
이 때문에 여러 실험을 진행하기 어려울 듯 하여 이미지 크기 줄이기, 데이터 양 1/10로 줄이기로 학습시간을 에폭당 2분으로 줄여 여러 실험이 가능하게 됐고 이에 많은 실험을 진행했다.
양선형 보간법을 이용한 해상도 변경
OpenCV로 Segmentation Mask의 해상도를 줄여 저장하는 과정에서 발생한 문제이다.
파이프라인을 작성하며 Segmentation Map을 시각화 했더니 이미지 내에 차량 보닛이 있는 위치인데 하늘에 해당하는 클래스가 입혀져 있었다.
어디서 문제가 발생했나 생각해보니 Resize 과정에서 발생했을 수도 있다고 생각했다.
※ 나중에 알고보니 데이터셋 문제였다...
그동안 이론적으로는 알고 있었으나 실제로 이 문제를 만나는 것은 처음이라 고민을 조금 많이 했다.
그렇다고 이웃 보간법을 이용해 해상도를 변경하기에는 그냥 기분이 안내켰다.
어떻게 하면 이웃 픽셀을 고려하며 Segmentation Map의 크기를 조절할 수 있을까?
이런 고민을 하며 정리한 내용은 Segmentation과 보간법 게시글에 작성해뒀습니다 ㅎㅎ.
이러한 생각은 아래와 같은 생각으로 이어졌고 모델 구조 개선을 통한 성능 향상으로 이어졌다.
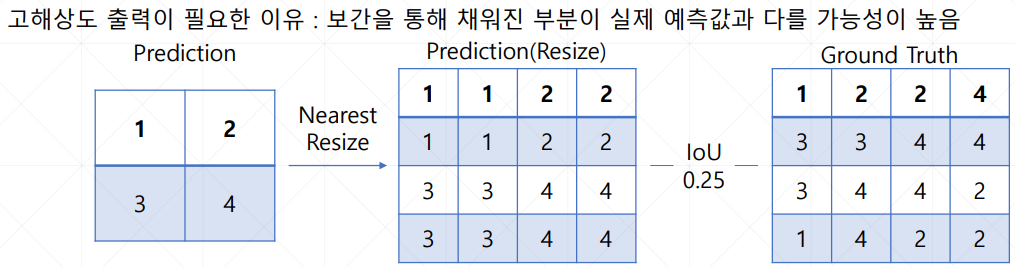
※ 서면 평가용 PPT 속 내용(제 깃허브나 본 대회 DACON 코드 공유란에 올렸습니다.)
Seed 고정을 왜 하지?
처음 여러 실험을 진행할 때 다음과 같은 고민을 많이 했다.
왜 Seed를 고정하며 성능 비교를 할까? 분명 변인 통제를 위한 것이긴 한데 만약 해당 Seed에서만 성능이 좋은 것이면 의미 없는 것이 아닌가?
이전에 프로젝트를 진행하거나 연구를 할 때는 모두 Seed를 고정하고 진행했는데 왜 이런 생각이 들었는지는 모르겠다.
결과는 Seed를 고정하지 않아서 무엇이 성능이 좋아진 것인지 파악하기 어려웠다.
이거 때문에 Colab 컴퓨팅 파워를 많이 날렸다.....
또 학습 때마다 성능이 매번 달라져서 재현도 못하고 실험 성능을 평균적으로 확인하기에는 학습이 너무 오래 걸리는 점이 걸렸다.
그래서 9월 1일에 시작한 대회지만 제대로 된 기록은 9월 11일부터 작성했다.
그래도 Seed를 고정하고 실험하니 결과 비교도 수월하고 신경쓸게 적어져 마음이 너무 편해졌다.
※ 다음부터는 무조건 Seed를 고정해야겠다!
SOTA 방법론 구조변경
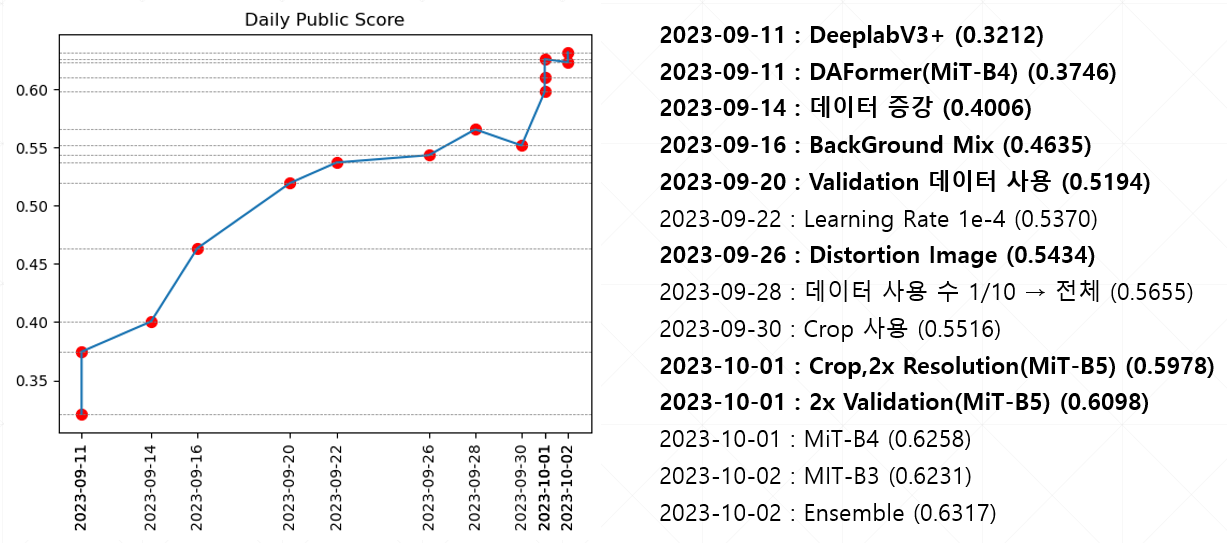
성능 그래프에서 보면 알 수 있지만 20일까지는 성능이 급 상승 하다가 이후로는 성능 변동이 크게 없었다.
데이터 증강 확률 조정, 기법, Validation 데이터 사용, 하이퍼 파라미터 튜닝 등 여러 실험을 했지만 미미한 증가만 있었다.
이제 대회 데이터셋에 맞게 왜곡에 대응할 수 있도록 MIC의 구조를 변경하고자 하였다.
MIC를 사용해서 학습을 하는데 성능은 0.5370 정도가 나오는데 실제 추론 사진을 살펴보던 중 신호등같은 작은 물체를 잘 예측하지 못하던 것을 확인했다.
데이터 증강 중에 Elastic과 Affine으로 인해 원본 이미지에서 작은 물체의 정보가 사라진다고 생각하였다.
실제로 Elastic과 Affine을 제거하면 전체 성능이 감소하는 결과를 보이지만 작은 물체는 잘 구분한다.

왼쪽은 Source 이미지이고 오른쪽은 Target 이미지다.
Target의 가장자리 부분을 보면 왜곡에 의해 Source보다는 회전되어 있는 것처럼 보인다.
성능이 감소하는 이유는 Elastic과 Affine은 그런 왜곡에 대해서 반응을 하기 때문에 이를 제거하면 성능이 감소하는 것이다 라고 판단하였다.
Elastic과 Affine을 사용하면서 이로 인한 정보 손실을 어떻게 방지할 수 있을까?
간단한 해결책은 Elastic과 Affine 증강을 사용한 것과 사용하지 않은 이미지를 둘다 모델에 학습시키는 것이다.
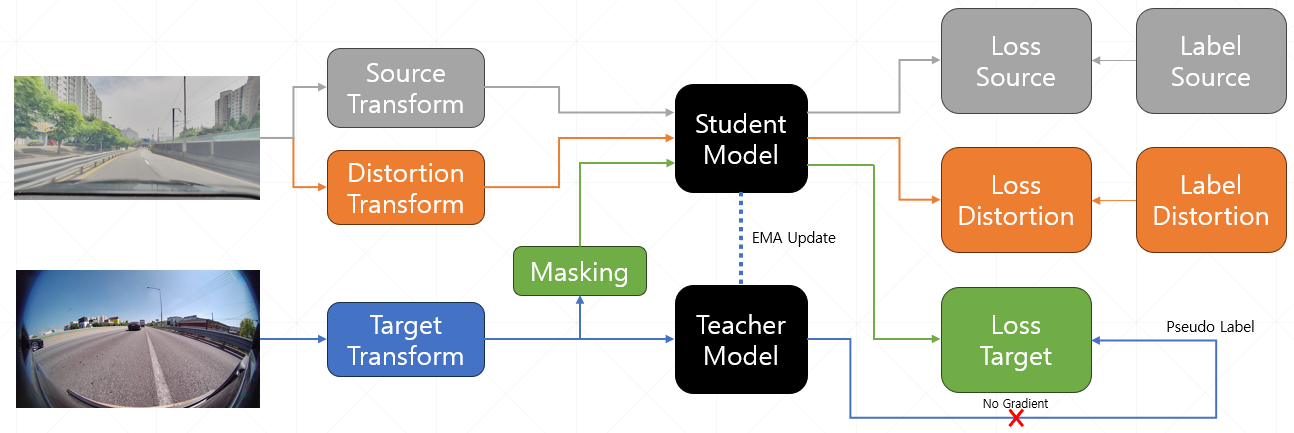
여러 실험 끝에 위와 같은 구조를 생각했다.
-
Rare Class Sampling 삭제 : 사람, 라이더, 보도블럭 등 흔하지 않은 클래스를 더 자주 추출해서 모델에 학습시키는 것인데 데이터셋이 크지 않아 중복되는 데이터가 많아져 모델 학습에 악영향을 줌
-
DACS 삭제 : 오히려 성능에 악영향을 주는 듯 하여 삭제
-
Feature Distance 삭제 : 이 또한 성능에 악영향을 주어 삭제
변경점
- Affine과 Elastic을 적용하는 Distortion 증강 부분과 적용하지 않는 일반 증강으로 나누어 모델에 입력으로 넣음
이 구조로 인해 실제로 작은 물체도 잘 예측하게 되었고 성능도 0.5434로 상승하였다.
비록 큰 상승폭은 아니지만 작은 물체도 잘 구분하게 되었다는 점이 이점으로 다가왔다.
이후 데이터셋의 수를 1/10만 사용하는 것이 아닌 전체를 사용하여 0.5655까지 올렸다.
성능 향상 마지막 희망이던 데이터 셋 전체 사용해도 성능이 많이 안오르네... 포기해야하나?
10등 커트라인 점수가 약 0.59이고 여태 실험들로 거의 다 시도해본 거 같아서 포기할까 고민했었다.
그래도 뭔가 찾아봐서 해봐야지 하고 뭐가 있을까 고민을 해보았고 해상도를 키워보자라는 생각을 했던 거 같았다.
해상도와 Transformer의 연산량
연산량은 추론과도 관계가 있지만 학습 시간과도 관계가 있다.
Transformer의 Self-Attention 연산의 특성상 패치의 크기가 동일하다면 이미지 크기가 2배로 커질 경우 패치의 수는 4배가 되어 연산량이 4배가 된다.
이 때문에 해상도의 이미지를 로 줄이고 학습을 한 것이다.
해상도를 키우면서 연산량을 줄일 수는 없을까?
큰 해상도를 학습하는데 필요한 시간과 자원이 너무 크기 때문에 최대한 효율적인 방법을 생각해보았다.
결국 Crop 방법만이 생각이 난다.
DAFormer의 Encoder는 SegFormer에서 MiT를 사용하는데 MiT의 장점은 학습과 추론에서 이미지의 크기가 달라져도 성능 감소가 적다는 것이다.
그렇다고 해서 성능 감소가 없는 것은 아니기 때문에 Crop을 하여도 원본이미지 전체를 추론할 수 있는 방법을 생각해냈다.
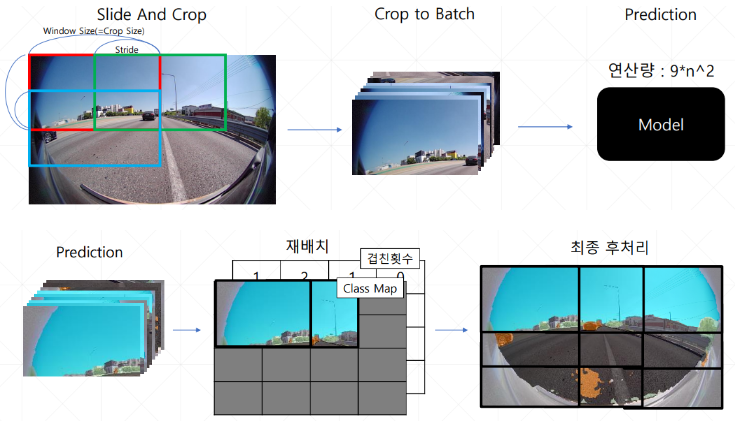
데이터셋 이미지를 로 Resize 하고 로 Crop한 다음 학습을 한다.
Crop한 이미지가 이기 때문에 의 해상도를 가진 하나의 이미지 전체를 넣고 학습하는 것과 같은 연산량을 가진다.
또한 실제 추론 단계에서도 Crop된 이미지들을 Batch로 묶어 추론하기에 메모리 이동에 의한 연산 시간을 제외하면 추론속도는 거의 비슷하다고 생각했다.
그리고 제일 중요한 점은 아래처럼 Crop, Affine, Elastic으로 왜곡에 대응도 가능하다고 생각했다.

모든 이론은 확실하네 빨리 학습하고 제출해보자
우선은 이미지를 으로 Crop하고 학습을 진행했다.
한 A100 GPU로 한 에폭당 8분 걸리던 것이 T4 GPU로 한 에폭당 9분이 걸린다.
기분 좋게 모든 학습이 마무리 되고 제출을 하였는데 오히려 성능이 0.01정도 감소했다...
하.... 왜지? 성능이 더 좋아질 줄 알았는데? 뭐가 문제인 거야
Crop으로 인해 일부 지역만을 보기에 Global Context를 잃는다는 점을 생각하지 않았다.
그래도 성능 차이가 많이 안나니 이미지 크기를 키우면 성능은 오르겠다고 판단하여 이미지 크기를 키우고 학습하여 결과를 제출했다.
결과는 성능이 올라 7위가 됐었고 보자마자 소리내며 엄청 기뻐했던 거 같다.
이후 기존보다 더 가벼운 모델을 사용했는데 오히려 성능이 증가했다.
이 모델들의 결과를 Ensemble 기법을 사용해 Public 6위를 달성하고 대회를 마무리 했다.
포기하지 않길 정말 잘 한 거 같다.
대회가 끝나고
밤을 새며 대회 마무리 후 점수 채점을 하는데에 추가 시간이 걸린다고 했다.
이 정도면 10위 안에도 들고 수상까지 할 수 있는 거 아니야??
그래서 조금 자고 일어나려고 하는데 기대감이 너무 커 잠을 잘 수가 없었다.
기다리다 보니 결과가 뜨고 Private 9등을 달성하였다.
순위가 낮아진 것에 대한 아쉬움과 동시에 서면 평가 기회가 생겼다는 것에 너무 기분이 좋았다.
그러고 거의 기절하듯 잠 든 거 같다.
PPT 작성
결과 발표 후 며칠동안 PPT만 만들다가 대면평가인줄 알고 발표용 PPT를 만들고 있었다.
나중에 알았지만 서면 평가용 PPT였다. (앞으로는 꼼꼼하게 다 잘 봐야겠다....)
그래서 PPT내용을 급하게 수정하고 코드 주석 작성 등 여러 수정을 급하게 진행하여 제출하였다.
필요한 부분도 다 작성한 것 같고 디자인도 괜찮다는 생각으로 계속 수상하는 상상을 했다.
그리고 대회 중 제일 중요한 점을 잘못 알고 있었다.
본 대회는 자율 주행용 적용 가능성이 아니었다.
카메라 왜곡을 신경쓰고 현업에서 사용 가능한 Domain Adaptation 알고리즘을 개발하는 것
대회 처음에는 방향성을 잘 잡다가 Crop과 Slide Prediction에서 추론 속도 신경쓰다가 변경된 UDA 구조에 대해서 자세한 설명이나 성능 비교를 올리지 못했다.
많이 아쉬웠다..
마무리
정말 어렵지만 재밌는 주제를 가진 대회였다.
잠을 줄이고 논문 찾아보고 구현하고 학습하는 것 때문에 바쁘다는 생각을 하긴 했지만 이 느낌이 싫지는 않았다.
하나 아쉬운 점은 시간이 좀 걸릴 거 같아 급하다는 생각으로 논문을 겉으로만 훌훌 읽어버리고 제대로 보지 않아서 중요한 디테일한 부분들을 놓쳤던 거 같다.
Pseudo Label을 만들 때는 Augmentation을 적용하지 않아야 하는데 적용 하고 입력으로 넣어서 성능 하락으로 이어진 거 같다...(다음에는 시간이 걸리더라도 확실하게 이해하고 구현해야겠다.)
다른 사람들의 방법론을 보면 나와 다른 방법으로 좋은 성능을 낸다는 점과 배울 점이 정말 많은 것 같다.
Test Time Augmentation 기법은 성능 올리기 좋은 방법인 거 같고 기회가 된다면 다음 대회에서도 사용해보고 싶다.
특히 모델에만 집중하고 학습 방법론(Contrastive Learning, Continual Learning, Domain Adaptation 등)은 생각하지 못하던 나에게 새로운 눈을 뜨게 해준 것 같다.
앞으로는 모델만 찾아보는게 아니라 여러 논문도 찾아봐야겠다.
