
왜 이런 걸 배우는 걸까? 컴퓨터 속을 들여다보자!
우리는 평소에 컴퓨터를 쓰면서 '앱'이나 '게임'을 실행하곤 하죠. 이걸로 충분할 것 같지만, 사실 그 아래에는 우리가 보지 못하는 깊은 세계가 존재해요. 전원이 켜질 때부터, 우리가 키보드를 누르고, 프로그램이 반응하기까지 — 수많은 복잡한 일들이 동시에 벌어지거든요.
1장에서는 다음과 같은 걸 배워볼 거예요:
- 프로그램이랑 프로세스는 뭐가 다를까?
- 커널은 왜 필요할까? 그냥 프로그램이 직접 다 하면 안 될까?
- 시스템 콜(system call)은 왜 중요한 걸까?
- strace, sar 같은 도구로 그 속을 엿볼 수 있다고?
- 라이브러리는 컴퓨터랑 어떻게 대화하지? 정적 링크, 동적 링크는 또 뭐야?
1. 프로그램과 프로세스: 파일에서 '살아있는 존재'가 되는 순간
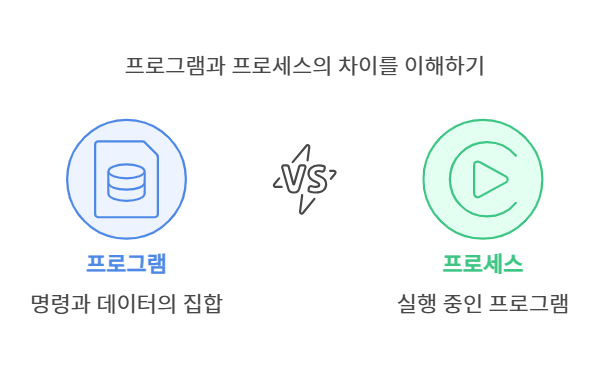
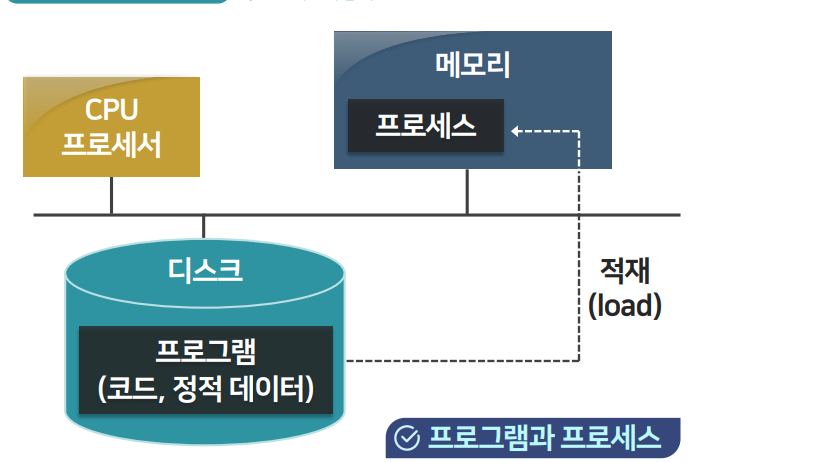
먼저, "프로그램"과 "프로세스"라는 말이 헷갈릴 수 있어요. 둘은 비슷해 보이지만 엄연히 다릅니다.
- 프로그램은 그냥 코드 덩어리예요. 실행되기 전 상태, 즉
.py파일이나.exe파일 같은 걸 말해요. 게임 CD나 USB 안의 설치파일을 생각해보세요. - 프로세스는 그 프로그램이 실제로 실행되었을 때의 상태입니다. 마치 게임을 설치하고 실제로 플레이 중인 느낌이죠.
즉, 프로그램은 멈춰있는 코드이고, 프로세스는 움직이고 있는 살아있는 코드예요. 파이썬이든 고(Go)든, 중요한 건 실행됐느냐 안됐느냐입니다.
2. 커널이 뭐길래 이렇게 중요한가요?
1) 그냥 프로그램이 하드웨어에 직접 명령 내리면 안 되나요?
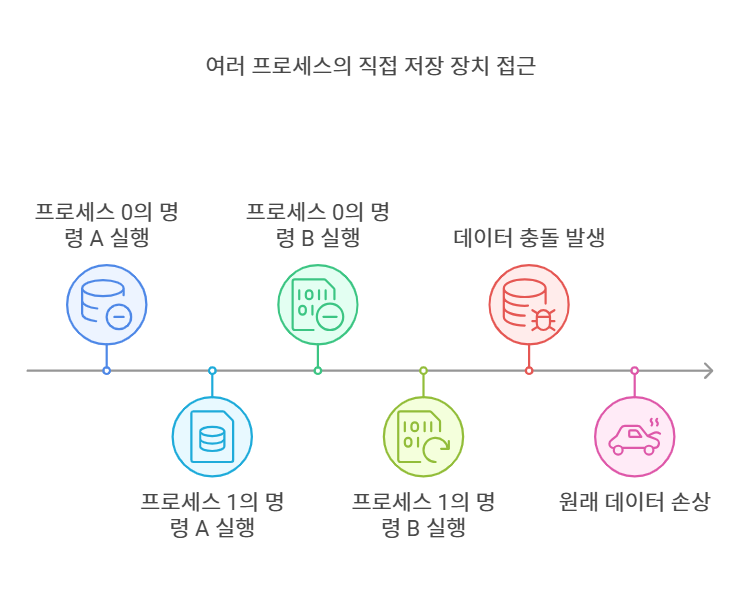
예를 들어, 내가 만든 앱이 하드디스크에 무언가 저장하고 싶어요. 동시에 친구가 만든 앱도 저장하려고 해요. 만약 둘 다 하드디스크에 직접 접근하면 어떻게 될까요?
- 내가 쓰려던 위치에 친구 데이터가 덮어쓰기 될 수 있어요.
- 심한 경우, 파일이 손상되거나 시스템 전체가 고장 날 수도 있죠.
이걸 동시성 문제라고 해요. 그래서 '누가 먼저 쓸까?', '어떻게 정리해서 쓸까?' 같은 조정이 필요한 거예요.
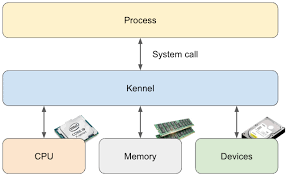
2) 그 조정을 누가 해줄까? 바로 커널입니다!
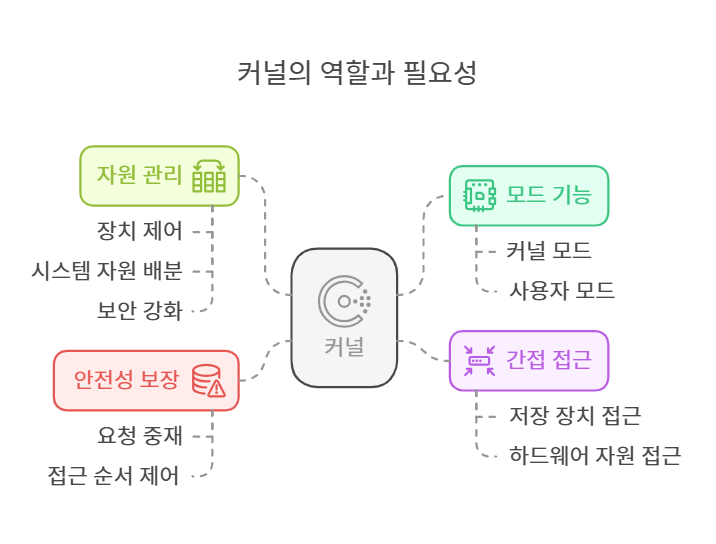
커널(Kernel)은 운영체제의 핵심이에요. 우리가 만든 앱이 직접 하드웨어랑 이야기 못 하게 하고, 대신 커널이 모든 요청을 받아서 조정해줍니다.
- "이 프로세스는 지금 디스크에 쓸 차례"
- "이건 나중에 쓰게 하자"
이렇게 해서 서로 충돌이 없게 만들어줘요. 마치 도서관 사서처럼, 책을 대여하려는 사람들을 질서 있게 관리해주는 역할을 합니다.
3) CPU는 두 얼굴을 가지고 있어요: 사용자 모드 vs 커널 모드
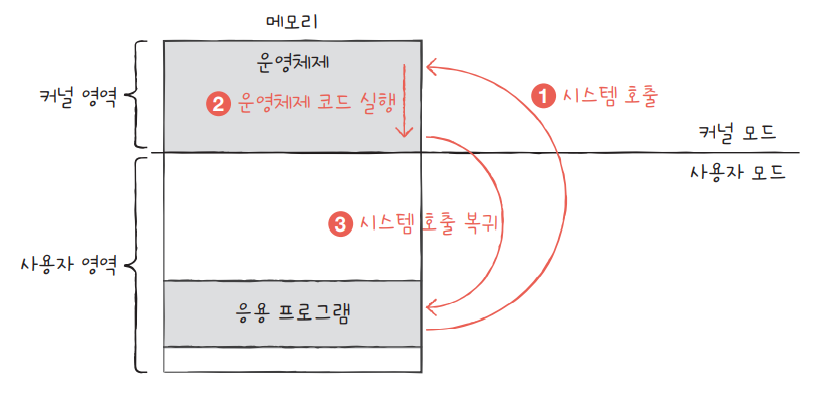
- 사용자 모드(User Mode): 우리가 만든 앱이 돌아가는 상태. 직접 하드웨어를 건드릴 수 없어요.
- 커널 모드(Kernel Mode): 운영체제의 뇌인 커널이 활동하는 상태. 하드웨어에 직접 접근 가능해요.
앱이 하드디스크에 저장하려면, "커널님! 도와주세요!" 하고 요청해야 하고, 이때 CPU는 커널 모드로 전환됩니다.
4) 🧠 리눅스 커널 구조, 어렵지 않게 이해해보자!
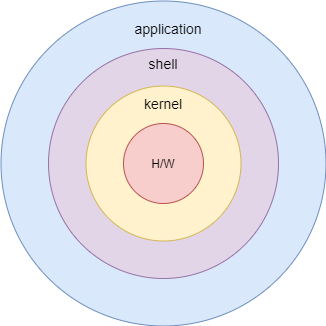
쉘은 사용자의 응용프로그램과 커널 사이에 위치해있으며 응용프로그램의 명령어와 커널이 대화를 하도록 만들어줍니다. 그래서 명령어 해석기라는 부릅니다.
운영체제(OS)는 우리가 스마트폰이나 컴퓨터에서 무언가를 할 수 있게 해주는 '기본 틀'이에요. 그 중에서도 커널(Kernel)은 OS의 심장 같은 존재죠. 하드웨어와 소프트웨어 사이에서 일어나는 모든 것을 조정하는 역할을 해요.
그런데 커널에도 '구조'가 있어요. 즉, 커널이 어떻게 생겼는지, 어떤 방식으로 구성돼 있는지에 따라 종류가 나뉘어요.
💡 단일형 커널(monolithic kernel)이란?
“할 수 있는 건 전부 내가 직접 처리할게!”
이게 바로 단일형 커널의 마인드예요.
📌 특징
1. 모든 기능을 하나의 커널 안에서 처리해요.
- 예: 파일 시스템, 네트워크, 장치 제어, 메모리 관리 등 전부!
- 속도가 빠르고 → 내부 통신이 적어서 효율적이에요.
- 설계가 단순해서 빠르게 개발 가능해요.
⚠️ 단점도 있어요
- 한 커널에 모든 걸 넣다 보니, 커널이 점점 비대해지고 커져요.
- 하나의 버그가 전체 시스템을 불안정하게 만들 수 있어요.
🖥️ 단일형 커널을 사용하는 OS 예시
- 리눅스(Linux)
- 대부분의 UNIX 계열
- MS-DOS, Windows 95/98/ME
- Mac OS 8.6 이하
🤔 그런데, 요즘은 '순수한 단일형'은 거의 없어요!
요즘 리눅스 커널이나 다른 운영체제들은 단일형 커널의 틀을 유지하면서도, 일부 기능을 외부에서 추가하거나 빼는 방식을 쓰고 있어요. 즉, “필요할 때만 불러와서 쓰는” 모듈 방식을 도입한 거예요.
예를 들면?
- Linux의
DKMS - FreeBSD의
kld - NetBSD의
module
이런 방식은 마이크로커널처럼 모듈형 구조의 장점을 흡수한 거예요. 그래서 요즘 커널들은 ‘혼합형 커널(hybrid kernel)’이라는 표현도 쓰이곤 해요.
🚨 그럼 마이크로커널은 뭐예요?
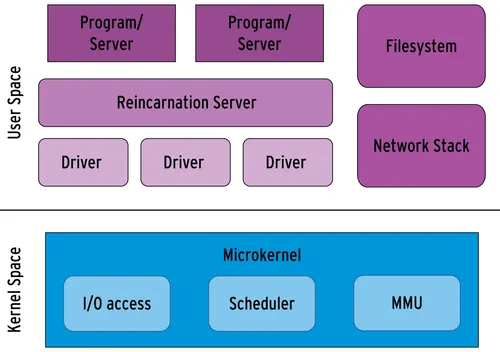
단일형 커널과 반대되는 개념이에요.
“최소한만 하고, 나머지는 바깥에서 처리할게!”
- 핵심 기능만 커널에 남기고,
- 나머지는 사용자 모드에서 처리하는 구조예요.
- 안정성은 좋지만, 속도나 통신 비용이 늘어날 수 있어요.
리눅스 커널 구조를 뜯어볼까?
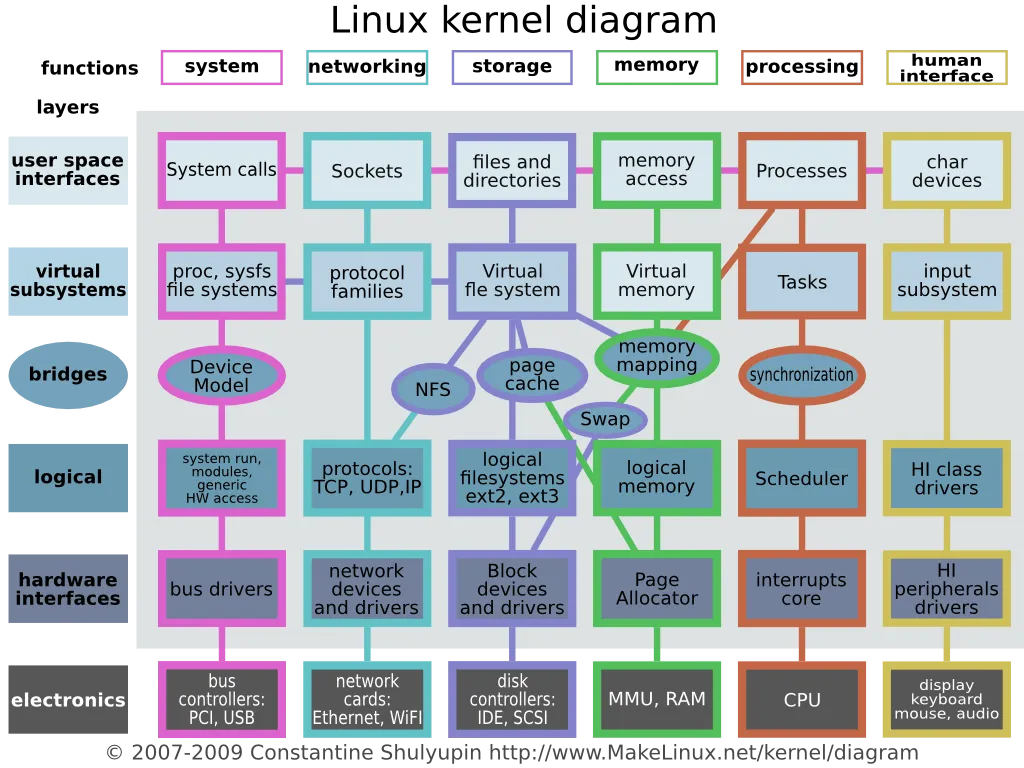
🧭 전체 구조 요약:
- 위에서 아래로: 사용자 공간 → 가상 서브시스템 → 논리 계층 → 하드웨어 드라이버 → 실제 하드웨어
- 왼쪽에서 오른쪽으로: 기능 영역(시스템콜/네트워크/파일/메모리/프로세스/장치) 구분
| 색상 | 기능 영역 | 대표 역할 |
|---|---|---|
| 🟣 Magenta | 시스템 인터페이스 | 사용자 요청 처리, 장치와 소통 |
| 🟦 Cyan | 네트워크 | 데이터 통신 |
| 🔵 Dark Blue | 파일 시스템 | 파일 저장과 읽기 |
| 🟩 Green | 메모리 관리 | RAM과 Swap 관리 |
| 🟧 Orange | 프로세스 관리 | 프로세스와 스케줄링 |
| 🟨 Yellow | 장치 I/O | 사용자 주변기기 관리 |
🧑💻 1단계: 사용자 공간 (User Space Interfaces) — 가장 위층
가장 위에 있는 건 우리가 직접 호출하는 것들.
예: read(), write(), fork(), open() 같은 함수들.
- System calls (🟣): 프로그램이 커널에게 요청할 수 있는 입구
- Sockets (🟦): 네트워크 통신을 위한 입구
- Files and directories (🔵): 파일 시스템에 접근하는 입구
- Memory access (🟩): 메모리 접근에 대한 인터페이스
- Processes (🟧): 프로세스를 다루는 인터페이스
- Char devices (🟨): 키보드, 마우스 같은 장치 인터페이스
⏬ 즉, 이들은 전부 "나 사용자 프로그램인데 시스템 자원 좀 쓸게요"라고 문을 두드리는 부분
🧩 2단계: 가상 서브시스템 (Virtual Subsystems)
여기서부터는 커널이 내부에서 일관되게 시스템을 다루는 중간 계층이야. 각 기능을 '가상화'해서 내부 처리를 표준화해요.
- 예:
proc이나sysfs처럼 파일처럼 보이지만 실제로는 메모리 상 구조를 보여주는 구조들 Virtual file system은 다양한 파일 시스템(ext4, NFS 등)을 하나의 방식으로 다룸Protocol families는 다양한 네트워크 프로토콜을 묶어서 관리함
📌 이 계층은 사용자 요청을 받아 내부에서 '적절한 방식으로 정리'하는 단계라고 보면 됩니다.
⚙️ 3단계: 논리 계층 (Logical)
이제 실제로 처리되는 로직들이 모여 있어요. 이 레벨부터 커널의 진짜 작업이 시작됩니다.
- 예:
TCP/IP,ext3,Swap,Page allocator,Scheduler,Interrupts core등
- 이들은 전부 CPU, 디스크, 메모리 같은 자원과 관련된 핵심 알고리즘들이야
- 여기서부터는 성능 최적화, 메모리 할당, 우선순위 조정 등 복잡한 일들이 이뤄져
💡 이 레벨이 시스템 성능과 안정성을 좌우하는 중추야.
🔌 4단계: 하드웨어 인터페이스 (Drivers)
이제 로직을 실제 하드웨어와 연결시켜줘야 하니까, 각 기능별 드라이버들이 등장합니다.
- 예:
network devices and drivers(이더넷 카드)block devices and drivers(하드디스크, SSD)scheduler,synchronization,input subsystem등
이들은 커널이 CPU, 메모리, 입출력 장치에 정확히 명령을 내릴 수 있게 해주는 연결고리
🧱 5단계: 실제 하드웨어 (Electronics)
그림 맨 아래에 있는 이 블록들이 우리가 만질 수 있는 진짜 장치들이에요!
| 영역 | 장치 예시 |
|---|---|
| 🟣 bus controllers | PCI, USB |
| 🟦 network cards | Ethernet, Wi-Fi |
| 🔵 disk controllers | IDE, SCSI |
| 🟩 MMU, RAM | 메모리 제어 |
| 🟧 CPU | 연산 장치 |
| 🟨 display, keyboard 등 | 사용자 입출력 장치 |
🎯 예시 흐름으로 이해해보기
예: 내가 Python으로 print("hello") 했을 때
1. write()라는 시스템 콜 호출 → 🟣
2. 문자 출력이니 char device(🟨) 경로로 들어감
3. 내부적으로 출력 장치 드라이버 탐색
4. 드라이버가 장치 컨트롤러 호출 → 디스플레이로 전송
5. 사용자 화면에 출력 완료!
✨ 예: 웹 요청을 보내기 위해 requests.get() 사용
1. 소켓 호출 → 🟦 Sockets → 프로토콜 패밀리 → TCP/IP 처리
2. 네트워크 드라이버 → NIC(Network Interface Card)
3. 이더넷/Wi-Fi 통해 패킷 전송됨
✨ 정리
이 구조도를 보면, 리눅스 커널이 얼마나 잘 정리된 층 구조로 이루어져 있는지를 알 수 있어요.
- 세로 방향(계층): 사용자 → 가상 서브시스템 → 논리 처리 → 드라이버 → 실제 장치
- 가로 방향(기능): 시스템 호출 / 네트워크 / 파일 시스템 / 메모리 / 프로세스 / 장치
각 블록은 커널의 기능 모듈이고, 이들이 서로 연결되어 사용자 프로그램과 하드웨어 사이에서 다리 역할을 하고 있어요.
각 영역이 협업해서 하나의 시스템을 만들고 있고,
위에서 아래로는 흐름(요청 → 처리 → 하드웨어),
옆으로는 기능별 역할 분업이 이뤄지고 있다고 보면 돼요!
📌 요약
| 구분 | 단일형 커널 (Monolithic) | 마이크로커널 (Microkernel) |
|---|---|---|
| 처리 방식 | 대부분의 기능을 커널 내부에서 | 핵심 기능만 커널에서, 나머진 바깥에서 |
| 장점 | 빠르고 설계 단순함 | 안정적이고 유연함 |
| 단점 | 커질수록 불안정해질 수 있음 | 성능이 느려질 수 있음 |
| 예시 | Linux, UNIX | 일부 최신 OS, 실시간 OS 등 |
3. 시스템 콜이 뭐예요? 커널에게 말 거는 방법이에요
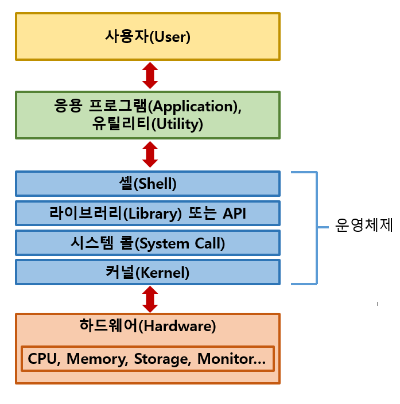
우리가 만든 프로그램은 커널에게 직접 말을 걸 수 없어요. 대신 시스템 콜(system call)이라는 인터페이스를 통해 요청을 보냅니다.
예를 들어,
- 파일을 열고 싶으면
open() - 데이터를 쓰고 싶으면
write() - 새 프로세스를 만들고 싶으면
fork()
이런 함수들이 다 시스템 콜이에요. 물론 우리가 부르는 건 함수처럼 보이지만, 그 안에는 복잡한 CPU 작업이 숨어 있죠.
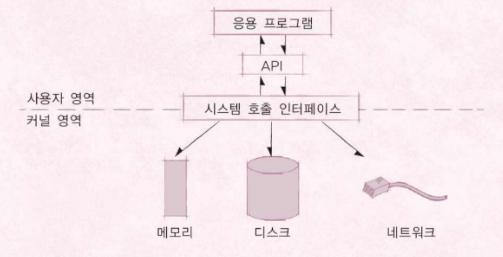
1) 시스템 콜의 작동 순서
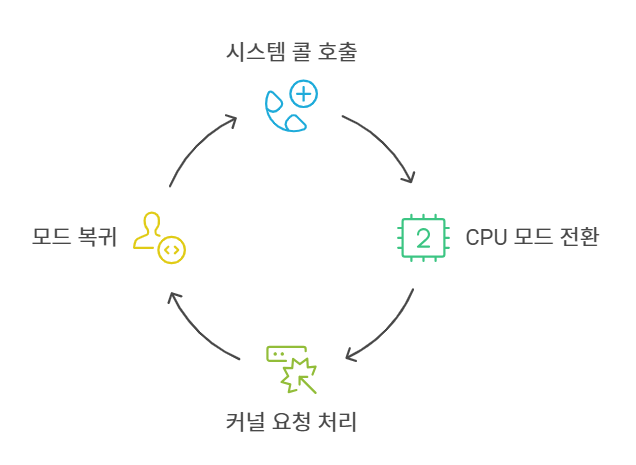
- 앱이
getpid()같은 시스템 콜을 호출해요 - CPU가 "예외(Exception)!"을 발생시키고 커널 모드로 바뀌어요
- 커널이 요청을 처리하고 결과를 돌려줘요
- 다시 사용자 모드로 돌아가 앱이 실행을 이어가요
2) strace: 시스템 콜을 몰래 훔쳐보는 도구
strace -T ./hello
이 명령어를 실행하면,
- 어떤 시스템 콜이 호출됐는지
- 각각 얼마나 시간이 걸렸는지
까지 보여줘요. 진짜 신기해요. write()가 0.000007초 걸렸다는 식으로요.
3) sar: CPU가 어디에 시간 쓰는지 보여주는 도구
sar -P 0 1 1이 명령어는 CPU 0번 코어가,
- 얼마나 사용자 모드에 있었는지 (%user)
- 얼마나 커널 모드에서 시스템 콜 처리했는지 (%system)
를 알려줘요. 직접 실험도 해볼 수 있어요:
- 무한 루프 돌리면
%user가 올라가요 getppid()만 계속 호출하면%system이 올라가요
이런 차이를 눈으로 보면서 배우면 이해가 훨씬 쉬워요!
4) 시스템 콜의 더 깊은 이야기: 내부 구조와 보안까지
앞서 시스템 콜이 "사용자 프로그램이 커널에게 요청을 전달하는 창구"라고 설명드렸죠?
그런데 그 창구는 단순히 문 하나 열고 들어가는 게 아니라, 꽤 복잡한 경로와 규칙을 따릅니다.
이제 그 구조를 조금 더 깊이 들여다보겠습니다.
1. 시스템 콜은 어떻게 우리에게 제공될까? — API 인터페이스 이야기
우리는 C 언어나 Python에서 그냥 read(), write(), getpid() 같은 함수들을 당연하게 호출하잖아요? 하지만 사실 이 함수들은 커널로 가는 직접 문이 아닙니다. 우리가 문 손잡이를 잡으면, 실제 문을 열고 요청을 전달하는 사람은 따로 있어요.
그 사람이 바로 표준 C 라이브러리(glibc) 같은 시스템 라이브러리입니다.
- 이 라이브러리는 우리가 호출한 함수 이름을 보고 내부적으로 시스템 콜 번호를 설정하고, CPU에게 “커널 모드로 들어가자”는 신호를 보냅니다.
- 그래서 우리는 마치 그냥 함수 하나 쓰듯이, 복잡한 시스템 콜을 간단한 API 형태로 쓸 수 있게 되는 거죠.
❗ 이때 중요한 건, 사용자 프로세스는 직접 커널 모드로 갈 수 없다는 점입니다. 꼭 시스템 콜을 통해서만 요청할 수 있어요. 마치 공항에서 출국장 안으로 들어가려면 반드시 보안 검색대를 통과해야 하듯이요.
2. 예외(exception)와 모드 전환: 커널 진입의 문지기
시스템 콜을 호출하면 CPU는 내부적으로 예외(exception)라는 이벤트를 발생시킵니다. 이 예외는 우리가 흔히 말하는 오류와는 조금 달라요.
- 이 예외는 "지금은 커널 모드로 들어가야 할 때야!"라는 신호 같은 거예요.
- 예외가 발생하면 CPU는 사용자 모드에서 커널 모드로 전환되고, 커널이 준비한 시스템 콜 처리 루틴을 실행합니다.
이 과정에서는 다음과 같은 일들이 일어납니다:
- 요청이 유효한지 검사: 예를 들어, 메모리 범위를 벗어난 접근이 아닌지 확인
- 올바른 처리가 가능한지 검토: 허가되지 않은 시스템 콜은 거절하기도 해요
또 한 가지 중요한 점은, 이 모드 전환 과정 자체가 비용이 든다는 것이에요. CPU 입장에서는 사용자 → 커널 모드 전환, 다시 복귀하는 과정에서 시간과 리소스를 쓰게 되거든요. 그래서 최근에는 이런 오버헤드를 줄이기 위한 다양한 최적화 기술들도 연구되고 있습니다.
3. 커널 개발자라면 꼭 알아야 할 시스템 콜
시스템 콜은 단순히 사용자와 커널 사이를 이어주는 통로일 뿐 아니라, 커널 개발자나 시스템 엔지니어 입장에서는 디버깅과 보안의 핵심 포인트이기도 해요.
- 예를 들어, 새로운 장치 드라이버를 만들거나, 커널 모듈을 개발할 때는 시스템 콜이 어떻게 처리되는지 정확히 알아야 합니다.
strace같은 도구로 시스템 콜 흐름을 분석하면, 프로그램이 어디서 병목이 생기는지, 잘못된 요청이 어떤 시스템 콜로 연결됐는지 추적할 수 있어요.
- 프로세스/스레드 관련: fork(), exec(), exit()
- 파일 I/O 관련: open(), read(), write()
- 소켓 관련: socket(), bind(), connect()
- 장치 관련: ioctl(), mknod()
- 프로세스 간 통신(IPC): pipe(), shmget(), mmap()
보안을 위한 시스템 콜 필터링: seccomp
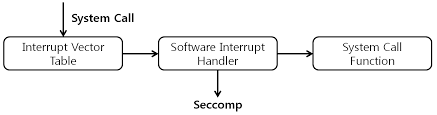
리눅스에서는 seccomp(secure computing) 같은 보안 기능을 통해 특정 시스템 콜만 허용하고 나머지는 차단할 수 있어요. 예를 들어, 어떤 프로그램이 open()은 써도 되지만 fork()는 절대 못 쓰게 제한할 수도 있죠.
이렇게 하면, 악성 코드가 시스템 콜을 통해 시스템을 공격하는 걸 미리 막을 수 있어요. 실제로 컨테이너 보안에서도 많이 쓰이는 방식이랍니다.
요약하자면
| 구분 | 핵심 내용 |
|---|---|
| API 인터페이스 | glibc 등이 시스템 콜을 감싸고, 우리는 편하게 함수처럼 사용 |
| 직접 호출 불가 | 사용자 모드 → 커널 모드는 예외 발생을 통해서만 가능 |
| 모드 전환 비용 | 시스템 콜은 오버헤드가 있으며 최적화 연구가 계속됨 |
| 커널 개발/보안 | 디버깅, 성능 분석, 보안 필터링에서 시스템 콜은 핵심 포인트 |
시스템 콜은 단지 요청을 전달하는 메커니즘이 아니라, 사용자와 커널을 잇는 보안 게이트이자 최적화의 포인트입니다.
이걸 이해하면 커널과 시스템의 깊은 내부가 눈에 들어오기 시작해요. 마치 병원 수술실의 흐름을 이해하는 의사처럼요.
4. 라이브러리: 우리가 부르는 함수들이 어떻게 작동하냐면요
printf(), malloc(), getppid() 같은 함수들은 전부 라이브러리에 들어 있어요. 특히 C 언어의 경우는 glibc라는 유명한 라이브러리가 있어요.
1) 시스템 콜을 감싸는 래퍼(wrapper) 함수
getppid() 같은 함수는 내부적으로 시스템 콜을 호출하지만, 우리는 그냥 함수처럼 쓰면 돼요. 그 안에서
- 레지스터에 매개변수 담고
syscall명령어 날리고- 결과 받아오고
이런 복잡한 걸 glibc가 대신 해줘요. 그래서 이식성도 좋아지고, 코드도 간단해지는 거죠.
2) 정적 링크 vs 공유 라이브러리: 어떤 방식으로 프로그램이 구성될까?
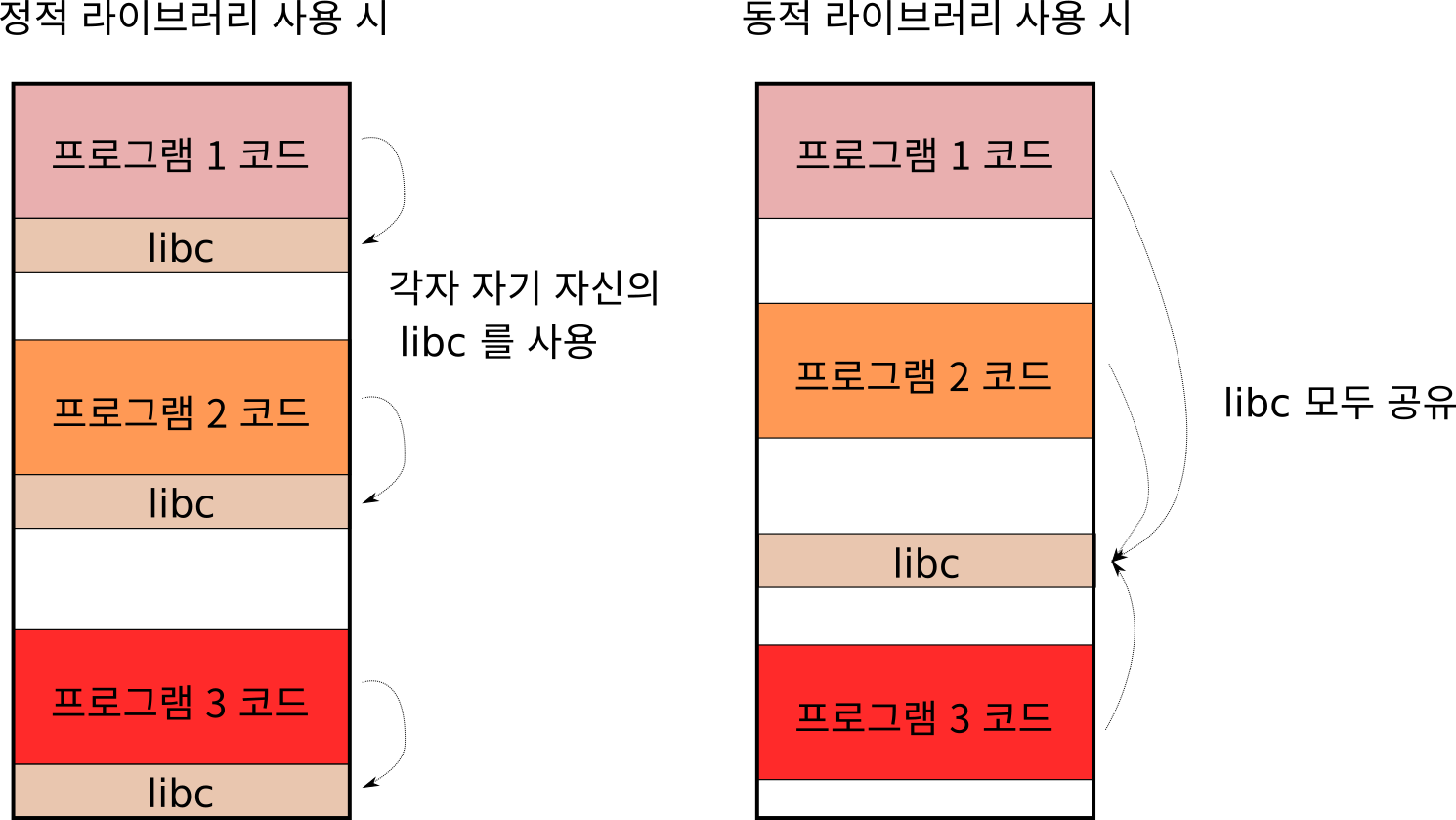
정적 링크
- 라이브러리 코드가 통째로 프로그램에 포함돼요
- 실행파일 하나만 옮기면 바로 실행 가능!
- 하지만 파일 크기가 커져요
- 대표 언어: Go
공유 라이브러리 (동적 링크)
- 실행할 때 라이브러리를 따로 불러와요
- 메모리와 디스크를 아낄 수 있어요
- 다른 앱이 같은 라이브러리를 함께 써요
- 대표 언어: C, Python
왜 Go는 정적 링크를 선호할까?
- 파일 하나만 복사하면 어디서든 실행됨 (배포 편리)
- 버전 충돌 없음 (DLL 지옥 방지)
- 하드웨어가 좋아져서 파일 크기 걱정도 적음
5. PLT와 GOT: 공유 라이브러리 주소를 찾아가는 길
공유 라이브러리를 사용하는 프로그램은, 처음 실행할 땐 함수 주소를 몰라요. 그래서 다음 도구들을 써요:
- PLT (Procedure Linkage Table): 일단 함수 호출이 들어오면 여길 거쳐요. 문지기 같은 존재죠.
- GOT (Global Offset Table): 실제 함수의 위치를 담아두는 테이블이에요.
처음 호출엔 GOT를 갱신하고, 이후엔 곧장 함수 주소로 점프! 그래서 한 번만 설정해두면 빠르게 실행돼요.
1) 📦 정적 링크 vs 🔗 동적 링크 – 프로그램은 어떻게 라이브러리를 불러올까요?
우리가 컴퓨터에서 프로그램을 실행할 때, 프로그램은 자주 쓰는 기능들을 ‘라이브러리’에서 빌려 씁니다. 그런데 이 라이브러리를 프로그램에 어떻게 연결하느냐에 따라 정적 링크와 동적 링크라는 두 가지 방식으로 나뉘어요.
🔗 과거에는 왜 동적 링크를 많이 썼을까요?
옛날에는 메모리와 저장공간이 부족했기 때문에, 자원을 최대한 효율적으로 써야 했습니다. 그래서 많은 운영체제들이 다음과 같은 이유로 동적 링크를 선호했어요.
-
자원 절약
여러 프로그램이 동일한 라이브러리를 쓴다고 해도, 한 번만 메모리에 올리면 다 함께 쓸 수 있으니까 훨씬 효율적이었죠. -
필요할 때만 불러오기
실행 중에도 필요한 순간에만 라이브러리를 로딩하면 되니, 처음부터 모든 걸 올릴 필요가 없었어요.
하지만 이렇게 좋은 방식에도 치명적인 단점이 하나 있어요.
프로그램이 "그 환경(OS)"에 의존하게 된다는 점입니다.
즉, A 컴퓨터에서는 잘 실행되던 프로그램이, B 컴퓨터에서는 동적 링크된 라이브러리의 버전이 달라서 에러가 나는 일이 생기기도 해요. 이걸 흔히 "DLL 지옥"이라고 부르기도 해요.
📦 그런데 왜 요즘은 정적 링크가 다시 뜨고 있죠?
Go 언어는 아예 정적 링크 방식을 채택했습니다. 그 이유는 명확해요.
요즘은 예전과 달리:
- 메모리나 저장 장치가 훨씬 크고 싸졌고
- 파일만 옮기면 다른 컴퓨터에서도 잘 돌아가야 하니까요.
실제로 정적 링크는 프로그램 실행 시 필요한 모든 라이브러리를 미리 실행 파일 안에 포함시켜 둡니다. 그래서 프로그램 하나만 들고 가면 그 자리에서도 실행이 가능해요.
추가로 좋은 점은:
- 공유 라이브러리를 찾느라 시간이 들지 않아서 실행 속도가 빠르고
- 다른 프로그램과 충돌도 일어나지 않아요.
💡 그러면 동적 링크에서는 라이브러리를 어떻게 찾아올까요?
사실 공유 라이브러리를 연결하는 데는 아주 정교한 구조가 사용돼요. 바로 PLT와 GOT라는 구조인데요,
함수를 호출하면(PLT를 호출하면) GOT로 점프하는데 GOT에는 함수의 실제 주소가 쓰여있다.
첫 번째 호출이라면 GOT는 함수의 주소를 가지고 있지 않고 ‘어떤 과정’을 거쳐 주소를 알아낸다.
두 번째 호출 부터는 첫 번째 호출 때 알아낸 주소로 바로 점프한다. “
🧩 PLT (Procedure Linkage Table)
프로그램이 라이브러리 함수를 호출할 때, 제일 처음 도착하는 위치입니다.
여기서 함수가 어디 있는지를 직접 알려주는 건 아니고요, "이 함수 어디 있어요?" 하고 묻는 전화교환대 역할을 한다고 생각하시면 돼요.
🗃️ GOT (Global Offset Table)
PLT는 GOT를 참고합니다.
GOT는 진짜 함수 주소를 가지고 있는 테이블이에요.
한 번만 찾으면 그다음부터는 바로바로 연결할 수 있어요.
예를 들어 printf() 같은 함수를 부를 때 실제로는 printf@plt로 먼저 들어가고, 이게 다시 GOT를 참고해서 진짜 주소로 점프하는 거예요.
📌 실제 작동 흐름 요약
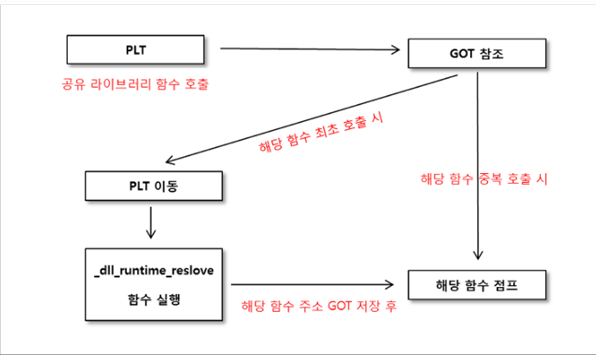
- 프로그램이
puts()함수를 호출해요. puts@plt에 먼저 도착해요.puts@plt는 GOT를 봅니다.- 만약 GOT에 실제 주소가 아직 없다면?
→got.plt로 가서 함수 주소를 찾고 저장합니다.
- 만약 GOT에 실제 주소가 아직 없다면?
- 다음 호출부터는 GOT에 저장된 진짜 주소를 바로 씁니다!
이런 과정을 통해, 공유 라이브러리를 효율적으로 연결하고 호출할 수 있게 되는 거예요.
✅ 요약
| 구분 | 정적 링크 📦 | 동적 링크 🔗 |
|---|---|---|
| 방식 | 실행 파일 안에 라이브러리 포함 | 실행 중에 라이브러리를 메모리에 연결 |
| 장점 | 이식성 높음, 충돌 없음, 실행 빠름 | 메모리 절약, 업데이트 용이 |
| 단점 | 파일 크기 큼, 메모리 더 사용 | 환경 의존, 버전 충돌 가능 |
| 예시 언어 | Go, 일부 C/C++ | Python, Java, 대부분의 리눅스 시스템 |
공유 라이브러리 방식은 여전히 많은 시스템에서 사용되고 있지만,
언제 어떤 방식이 적절할지 상황에 따라 선택하는 눈이 중요합니다.
좋습니다! 각 항목에 대해 의미와 맥락을 좀 더 명확히 전달할 수 있도록, 배경 설명과 함께 부가 설명을 붙여드릴게요. 학습자나 발표 대상자가 더 쉽게 이해할 수 있도록 친절한 말투로 풀어드렸습니다.
6. 논의 사항
1) strace라는 명령어는 커널까지 다루는데 운영 환경에서 써본 적이 있는가?
거의 없다는 것, 임베디드나 C언어 다루는 사람들이 사용하지 않을까?
- 보통
strace는 프로그램이 어떤 시스템 콜을 호출하고 있는지, 어디서 문제가 생기는지를 파악할 때 사용합니다. - 따라서 C언어나 시스템 프로그래밍, 커널 모듈 개발자, 또는 임베디드 개발자들이 자주 쓰는 도구입니다.
- 운영 환경에서는 성능에 민감하거나, 디버깅해야 할 때 아주 제한적으로 사용됩니다.
- 최근에는 대부분의 시스템이 안정적으로 동작하고 있고, 하드웨어 스펙도 좋아졌기 때문에 실무에서는 접할 일이 많지는 않을 수 있습니다.
📌 한줄 요약: strace는 커널의 내부 동작을 추적하는 도구로, 디버깅이나 성능 분석 시에만 한정적으로 사용되는 전문적인 도구입니다.
2) sar -P는 어디에 쓸 수 있을까?
sar는 System Activity Report의 약자로, CPU, 메모리, 디스크 I/O, 네트워크 등 시스템 자원 사용 상태를 시간대별로 보여주는 도구입니다.-P옵션은 특정 CPU 코어별 사용량을 보여줘요. 멀티코어 환경에서 CPU 0, CPU 1 각각이 얼마나 바빴는지를 확인할 수 있습니다.- 특히
sar는 운영체제에 설치된 에이전트가 주기적으로 데이터를 수집하고 기록하기 때문에, 문제가 발생했던 과거 시간대의 상태까지 추적할 수 있다는 장점이 있어요. - 다만 실제로 시스템이 완전히 멈춰버리면 로그를 볼 수 없기 때문에, 평소에 모니터링 시스템과 함께 운영하는 것이 중요합니다.
📌 한줄 요약: sar -P는 CPU의 사용 현황을 모니터링하거나 병목 원인을 분석할 때 유용하지만, 사전 설정이 없으면 실시간 대응은 어려울 수 있습니다.
3) uptime: 서버가 얼마나 오랫동안 켜져 있었는지 보여주는 명령어
uptime명령어는 단순히 "서버가 얼마나 켜져 있었는지", "현재 접속한 사용자 수", "Load Average"를 보여줍니다.- 그중
Load Average는 시스템이 처리 중인 평균 작업 수를 의미합니다. 단위는 1분, 5분, 15분 동안의 평균값 3개로 제공됩니다.
Load Average 값 해석 예시
- CPU 1개, 프로세스 1개 → LA: 1 → 적당한 상태
- CPU 1개, 프로세스 2개 → LA: 2 → 과부하 가능성
- CPU 4개, 프로세스 4개 → LA: 1 → 부하 적음
R과 D는 무엇인가요?
R(Running): CPU를 점유하고 실행 중인 프로세스D(Uninterruptible sleep): 보통 디스크 I/O 작업 중인 프로세스. 중간에 끊을 수 없습니다.
그래서
Load Average가 높더라도, R이 많다면 CPU가 바쁘다는 뜻이고
D가 많다면 디스크 병목(예: I/O 지연)이 생기고 있다는 뜻이에요.
📌 한줄 요약: uptime은 단순하지만, Load Average를 통해 시스템의 부하 상태를 빠르게 파악할 수 있는 실용적인 명령어입니다.
필요하시면 위 내용을 발표용 슬라이드 요약이나 Q&A 질문형으로도 바꿔드릴 수 있어요!
7. 부팅 과정도 알고 보면 재밌어요
컴퓨터를 켜면 제일 먼저 움직이는 건 뭐냐면... 커널이 아니에요!
1) 부트로더가 커널을 깨운다
- 전원이 켜짐 → BIOS/UEFI가 하드웨어 체크
- 부트로더(ex. GRUB)가 실행됨
- 부트로더가 커널을 메모리에 올려줌
- 커널이 첫 번째 프로세스(init)를 실행시킴
즉, 컴퓨터가 켜진 직후부터 여러 프로그램이 바통터치하듯 이어지고 있는 거예요. 이걸 그림으로 정리하면 더 쏙쏙 들어옵니다. (그림 그려주신 분 최고!)
8. 마무리: 커널을 이해하면 프로그램이 보인다
이 장에서는 정말 핵심적인 주제들을 다뤘어요:
- 프로그램과 프로세스의 차이
- 커널이 왜 필요한지
- 시스템 콜이 어떻게 작동하는지
- 도구를 활용해 시스템 내부를 엿보는 법
- 라이브러리와 링크 방식의 차이까지!
이걸 알면,
- 문제의 원인을 더 잘 찾을 수 있고
- 성능이 좋은 프로그램을 만들 수 있고
- 더 나아가 시스템에 강한 개발자가 될 수 있어요 💪
커널을 이해한다는 건 단순히 지식을 아는 게 아니에요.
우리가 만든 코드가 '어떤 세계에서 살아가는지'를 보는 눈을 가지게 되는 거죠.
출처
