1. MongoDB에 대한 설명
🥐 MongoDB란?
- MongoDB는 C++로 작성된 오픈소스
문서지향적Cross-platform 데이터베이스 - 뛰어난 확장성과 성능을 제공하며, 현존하는 NoSQL 데이터베이스 중 인지도 1위
🥐 MongDB가 만들어진 계기
- 10gen 의 플렛폼은 하드웨어와 소프트웨어 인프라의 관리와 확장성을 자동으로 처리하고, 그에 따라 개발자들은 애플리케이션 개발에 집중하게 하려는 목적으로 설계
- 오픈소스 이지만 여전히 MongoDB 의 핵심 개발자들은 MongoDB의 설립자이거나 직원이고, 프로젝트의 로드맵은 사용자 커뮤니티의 필요에 의해서, 그리고 관계형 데이터베이스 와 키-값(key-value) 분산 저장 시스템에서 장점만을 통합하는 데이터베이스 설계라는 주요 목표로 개발되어가고 있다.
🥐 MongoDB가 인기 있는 이유
- 몽고DB의 도큐먼트 모델은 다양한 유형의 데이터와 워크로드를 반영하고, 단일 API로 복잡한 워크로드를 쉽게 구성할 수 있다. 몽고DB가 개발자에게 인기를 얻는 건 자연스럽게 생산성을 높일 수 있기 때문이다.
MongoDB 카힐 부사장의 인터뷰
- 그는 개발자의 생산성을 저해하는 원인을
관계형 데이터베이스(RDB)라고 지목했다. 경직된 아키텍처, 비싼 비용, 부족한 확장성 등을 RDB의 문제점으로 꼽았다.
그는 “
RDB를 쓰면 수많은 시스템이 연결돼야 서비스를 제공할 수 있어 복잡성과 비용 모두 증가한다”며 “다양한 기술과 인터페이스를 각기 다른 방식으로 관리해야 하므로 혁신이 느려진다”고 말했다. 카힐 부사장은 “도큐먼트가 많이 조인된다면 기존보다 2배 빨라지고, 선별적인 소수의 조인이라면 5~10배 빨라지며, 사람이 실시간으로 분석하면서 미리 인덱스 없이 쿼리를 던질 때 100배 빨라진다”며 “새 쿼리 엔진과, 실시간 인앱 분석 쿼리 지원 강화로 몽고DB의 데이터 저장 방식도 애널리틱스 쿼리의 경우 별도 컬럼스토어로 할 수 있는 ‘컬럼스토어 인덱스’를 추가했다”고 밝혔다.
스택 오버플로우를 보면 가장 원하는 데이터베이스 기술에 3년 연속 1위를 했으며, 기술 순위 5위 안에 드는데 그 중 3위까지가 RDBMS라고 한다. NoSQL에서 강세라는 것..
빠른 속도와 확장성
- NoSQL의 분류
| 종류 | 예시 |
|---|---|
| 키-값 스토어 | Redis, Dynamo |
| 컬럼 지향 스토어 | HBase, Cassandra |
| 도큐먼트 지향 스토어 | MongoDB |
| 그래프 데이터베이스 | Neo4J |
- 빠른 속도와 확장성을 적절하게 충족
- 개인적인 궁금증.. MongoDB보다 인기가 많은 Redis 왜일까?
- 먼저, 레디스는 사용자가 많아 자료가 많다. 커뮤니티가 큰 오픈소스를 사용해야 적용 및 대응이 쉽다.
두번째로 인메모리데이블은 제약사항이 많은 반면에 레디스는 다양한 데이터구조 사용가능, 스냅샷으로 복구시 활용가능한 점등이 확장성을 고려해봤을때도 여전히 좋다고 한다.
그렇다면 그게 뭔데?
🔗 https://brunch.co.kr/@skykamja24/575
Redis는 REmote DIctionary Server의 약어로 Key와 Value를 가진 오픈소스 NoSQL 데이터베이스이다. 시스템메모리를 사용하는 키-값 데이터 스토어로 문서형 데아터베이스보다 빠르고 가볍게 동작한다고 한다. 레디스와 백엔드 프레임워크의 궁합이 좋으며, 보통 aws와 많이 쓰는 것 같다. 운영 중인 웹 서버에서 키-값 형태의 데이터 타입을 처리해야 하고 I/O가 빈번히 발생해 다른 저장 방식을 사용하면 효율이 떨어지는 경우의 사용
친숙함과 이용의 편리성
- 웹 개발자라면 사용 한 번 쯤 해봤을
JavaScript를 활용하기에 친숙함 - MongoDB는 관계형 DBMS에서 테이블을 이용해 정보를 저장하는 방식과 달리 웹 서버와 통신할 때 자주 쓰이는
JSON과 유사한 형태로 저장하는 방식 채용 - 밑에서도 설명하지만 테이블 구조와는 다르게 어떤 값을 가질지, 크기는 얼마나 될지 미리 정하지 않고 데이터를 저장할 수 있다.
쉽고 빠른 컴퓨팅 환경 구성
- 복제와 샤딩 기능을 제공하고 있다.
이러한 기능은 어디에 쓰일까?
이를테면, 무료 송금 어플리케이션 개발시 계좌정보 저장하는데 송금시스템이 통째로 멈추면 안되니, 애플리케이션은 안전성이 중요하기 때문에 데이터 불러올 때 실패하지 않으려면 복제가 필요하다.
- 샤딩 : 정보를 분산해서 여러 대의 서버 데이터베이스에 저장하는 것
🥐 NoSQL(Not Only SQL) 이란
- 기존의 RDBMS의 한계를 극복하기위해 만들어진 새로운 형태의 데이터저장소 관계형 DB가 아니므로, RDMS처럼 고정된 스키마 및 JOIN이 존재하지 않는다.
🥐 Document 데이터베이스(NoSQL)
비 관계형 데이터베이스 : 개발자가 시스템 구성시 관심을 갖는 이유
- MongoDB는 웹 어플리케이션과 인터넷 기반을 위해 설계된 데이터베이스 관리 시스템
- 데이터 모델과 지속성 전략을 높은 읽기/쓰기 효율과 자동 장애조치(failover)를 통한 확장의 용이성을 염두에 두고 만들어졌다.
확장성: 애플리케이션에서 필요한 데이터베이스 노드가 하나이거나 혹은 그 이상이거나 관계없이 좋은 성능- 단 하나의 데이터베이스 서버만 필요하는 경우에도 사용할 이유가 있을까?
- 직관적인 데이터 모델 : 정보를 행(row) 대신 도큐먼트(document)에 저장
- 도큐먼트 기반의 데이터 모델은 풍부하고 계층적인 구조의 데이터를 표현 할 수 있다.
- 한 상품의 정보는 아마도 여러개의 테이블에 나뉘어 저장될 것
- 한 상품에 대한 레코드를 얻기 위해서는 조인 연산으로 많이 있는 복잡한 SQL 쿼리 이용해야 하지만,
도큐먼트 모델에서는 대부분의 상품 정보를 하나의 도큐먼트로 표현할 수 있다. - 프로그래밍 언어에서 정의한 객체가 그대로 저장되므로 객체 매퍼(mapper) 의 복잡성이 사라지게 된다.
도큐먼트(document)
{
_id: 10,
username: 'geum',
password: 1234,
email: 'prs212@naver.com',
hobby : 'read book'
}- 데이터 구조는 한 개이상의 key-value pair 구성
- 사용자에 대한 정보를 몇개의 필드(field) 로 저장
- Document 는 동적의 schema 구조를 가지고 있어서, 같은
Collection안에 있는 Document
끼리 다른 schema 를 가질 수 있다. 즉, 서로 다른 데이터 (즉 다른 key) 들을 가지고 있을 수 있다.
1.Collection: MongoDB 도큐먼트 그룹으로 도큐먼트들이 Collection 내부에 위치하며, table과 비슷한 개념이나, 스키마를 따로 가지고 있지 않다. - 이런 형태의 장점은? RDBMS의 경우, 각각의 사용자에 대해 여러 개의 취미를 저장하고자 한다면
조인을 하기 위해 이메일 주소와 사용자 테이블을 각각 만들어야 할 것 - MongoDB 배열로 만들어 문제 해결 가능 ⇒
유연성: 스키마 맞춰야 하는 걱정없이 구조화된 도큐먼트를 데이터 베이스에 저장할 수 있다
{
_id: 10,
username: 'geum',
password: 1234,
email: ['prs212@naver.com',
'sdg212@gmail.com'],
hobby : 'read book'
}- 프로그래밍 언어에서 정의한 객체가 그대로 저장되므로 객체 매퍼(mapper) 의 복잡성이 사라지게 된다.
Json(JavaScript Object Notation) : 도큐먼트 형태구조
- 사람이 읽고 쓰기 쉽고, 기계가 파싱하고 생성하기 쉬
- JavaScript 의 Array 문법으로 데이터 구조를 기술하는 방법으로 XML 이 가지는 유연성과 구조적 데이터 표현 기능을 확보하면서, XML 이 가짂 오버헤드를 줄이는 방법으로 사용됨
RDBMS와 MongoDB 비교
| RDBMS | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Tuple/Row | Document |
| Column | Key/Field |
| Table Join | Embedded Documents |
| Primary Key | Primary Key(_id) |
| Database Server & Client | |
| mysqld | mongod |
| mysql | mongo |
🥐 핵심 기능
도큐먼트 데이터 모델
- 도큐먼트는 본질적으로 속성의 이름 과 값으로 이루어진 쌍의 집합
- MongoDB 는 도큐먼트의 모음인
컬렉션(collection)에 도큐먼트로 저장하는 반면, MySQL 이나 다른 RDBMS 에서는 데이터를 테이블의행으로 저장- 객체의 데이터를 여러 개의 테이블로 나누어 표현하는 기법인 정규화사용 시 비용이 들어가게 되는데 그 말은 즉, 데이터를 모으는 작업에 많은 비용이 들어간다는 의미이다.
- 도큐먼트 지향적인 데이터 모델에서는 객체를 자연스럽게 모아 놓은 형태로 표현함으로써 객체 전체적으로 작업이 가능하며, 도큐먼트를 컬렉션으로 모아 놓는데, 어떤 종류의
스키마도 필요하지 않는다.
스키마가 없는 모델의 장점
- 데이터베이스가 아닌 애플리케이션이 데이터 구조를 정한다는 것
- 데이터 구조가 빈번히 변경되는 개발 프로젝트 초기 단계 개발시간 단축
- 스키마가 없는 데이터 모델을 통해
가변적인속성을 갖는 데이터를 표현 가능도큐먼트로 데이터 모델링을 하게 되면 조인이 필요 없고, 새로운 속성은 한 도큐먼트에 동적으로 추가- 애플리케이션이 개발을 할 때 추후에 필요할 데이터 필드가 무엇인지에 대해서 고민이나 걱정이 상대적으로 부담이 덜 될 수 있다는 점
애드 훅 쿼리
애드혹 쿼리(ad-hoc-query)는 사용자가 직접 쿼리 명령 및 함수를 사용하여 직접 입력하는 방식으로 데이터를 추출하는 쿼리를 의미- MongoDB의 설계 목표 중 하나는 관계형 데이터베이스상에서 매우 필수적인 쿼리 언어 성능을 대부분 유지 하는 것
- MongoDB 는 문서를 저장하고 조회 목적에 맞는 조회 방법을 제공하며, 값, 범위(lt 등) 조회, 정규식 검색 등을 지원하고 자바스크립트의 함수를 사용할 수도 있다.’
인덱스
- MongoDB 도 인덱스를 지원하며 인덱스는
B-Tree 인덱스로 구현되어 있다. - 대부분의 데이터베이스는 각 도큐먼트 또는 각 행의 기준을 위한
고유의 식별자로서 프라이머리 키(Primary Key) 를 부여하며, 기본 키는 자동적으로 인덱스되며 고유한 값을 유지 하기 위해서 유니크 키 를 사용하게 된다. - MongoDB는 여러개의 세컨더리 인덱스를 허용함으로 여러 조회 조건을 빠르게 처리 할 수 있도록 합니다.
🥐 언제 써야 할까?
- 스키마가 자주 바뀌는 환경
- 분산 컴퓨팅 환경
2. MongoDB 설치
🥐 설치 관련
설치 사이트 : 버전 안정화된 6.0.9 추천
🔗 https://www.mongodb.com/try/download/community-kubernetes-operator
- 윈도우에서 몽고 데몬이 서비스 형태로 동작해야 함
- Complete > Install MongoDB a Service [Run sevice as Network Service user] 로 설치
shell 설치

3. MongoDB 사용
🥐 기본 사용법
TIP
- 만약 설치가 안된다면
환경변수에 등록할 것[ZIP파일 시 등록해야 할 수 있으니 msi로 하자]
cmd
- 관리자 권한으로 실행
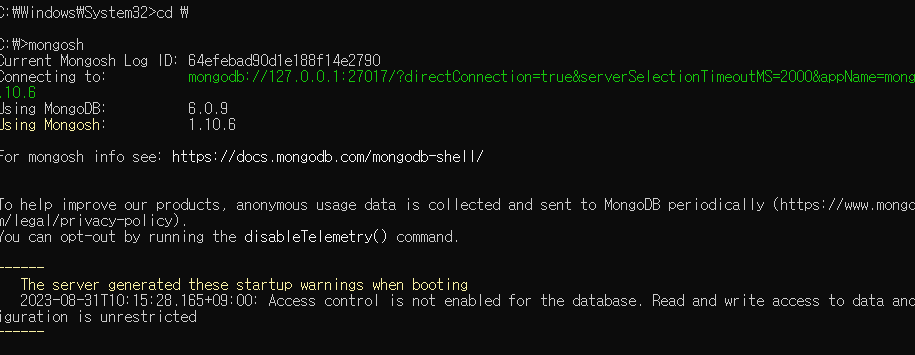
- 서버가 떠 있다는 뜻 서버 포트:27017
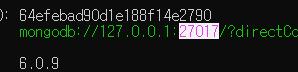
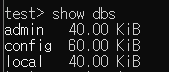
- DB 목록 조회하기
- 현재 설치된 데이터베이스의 목록을 알고 싶을 때 사용
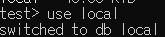
- DB 선택하기
- use DB_이름
- 사용 중인 DB 이름보기
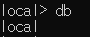
DB 생성하기
- 몽고 DB는 새로운 DB 생성 명령이 없음
- 몽골 DB는 있으면 사용하고 없으면 생성하는 형태
- mydb라는 이름의 db를 만들고 싶다면
use명령이용
- 이 시점에서는 새로운 db 생성하지 않음
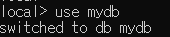
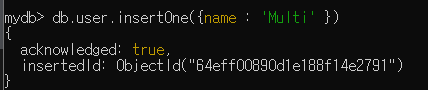
- 새로운 DB는 실제 데이터가 새로운 DB 생성시 함께 만들어짐- 실제 데이터 만들기 예제
- 마치 자바처럼 {}안에 객체를 넣기
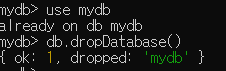
DB 지우기
use명령으로 삭제하고 싶은 DB 선택
🥐 컬렉션과 문서
- RDBMS의 테이블을 컬렉션이라고 함
- RDBMS의 레코드에 해당하는 한 건의 데이터를 문서(document)라고 함
- 즉,
컬렉션이란 스키마 없이 자유롭게 작성된 여러 개의 문서를 보관하는 저장소
새로운 컬렉션 만들기고 목록보고 삭제해보기
- 새로운 컬렉션 만들기 : 컬렉션 설정 옵션을 지정하고 싶다면
{}안에 작성

- 현재 사용 중인 db의 모든 컬렉션을 보려면

- 컬렉션 삭제 하기
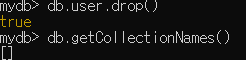
- 만약 네임에
띄어쓰기가 있다면 db[”컬렉션이름”]으로 해줘야함
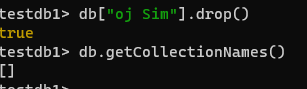
mongotest 컬렉션 만들고 그 안에 객체를 넣어줌 ⇒ 그 후 컬렉션 삭제\
- 명령어
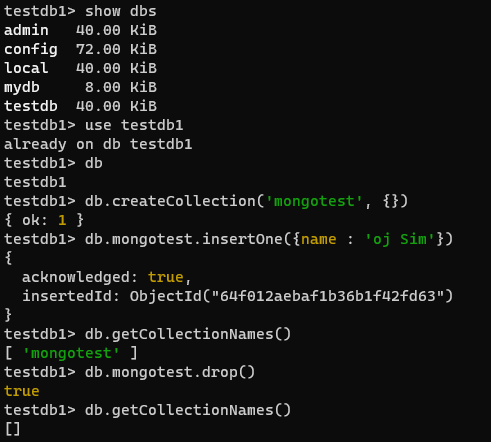
- 구조[도큐먼트 - 컬렉션 - 데이터베이스]
🥐 _id 필드와 ObjectId 타입
- 모든 몽고DB 문서는 _id라는 특별핚 이름의 필드field를 가지는데, 이 필드는 문서가 DB에 저장
될 때 자동으로 만들어 짐
- ObjectId의 문자열 부분은 유닉스 시간 표기(4바이트) + 랜덤값(5바이트) + 카운트(3바이트)로 이루어 짐
🥐 컬렉션의 CRUD 메서드
- findOndAndUpdate
- 나머지는 insertOne, insertMany, findOne, find, updateOne, updateMany, deleteOne, deleteMany
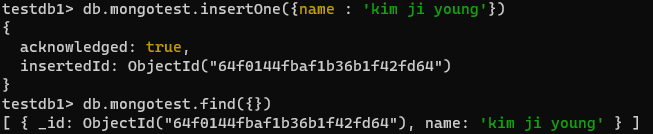
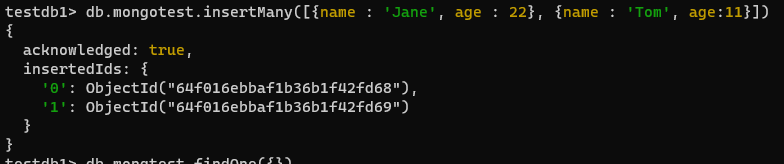
🥐 문서 생성 메서드 사용하기
- create 메서드로 생성하지 않아도 몽고 db는 스키마가 없기 때문에
이름.insertOne형태 명령시 컬렉션 자동 생

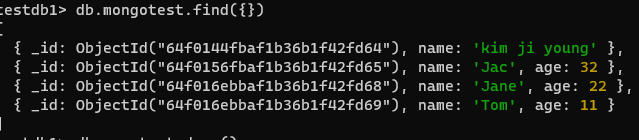
🥐 문서 검색 메서드 사용하기
🥐 몽고 DB에서 연산자
연산자란?
- 몽고DB에서는
$gt처럼 달러 기호를 접두사로 사용하는 키워드
| 연산자 이름 | 의미 |
|---|---|
| $eq | 필드_값 == 값 |
| $ne | 필드_값 ≠ 값 |
| $gt | 필드_값 > 값 |
| $gte | 필드_값 ≥ 값 |
| $lt | 필드_값 < 값 |
| $lte | 필드_값 ≤ 값 |
- 일치하는 값을 가지는 문서를 찾거나, 또는 반대로 여러 값 중에서 하나도 일치하지 않는 값을 가지는 문서를 찾아야 할 때
$in 과 $nin연산
| 연산자 이름 | 의미 |
|---|---|
| $in | 하나라도 매치되면 해당 문서 반환 |
| $nin | 하나도 매치되지 않는 문서 반환 |
논리 연산자
- $and, $not, $or, $nor
$regex 정규식 연산자
- 와일드 카드 느낌

필드 데이트 연산자
| 연산자 이름 | 용도 |
|---|---|
| $set | 특정 필드값 변경시 사용 |
| $inc | 문서 숫자 타입 필드값 증가 시 사용 |
| $dec | 문서 숫자 타입 필드값 감소 시 사용 |
| ⇒ 최신 버전에서 사용 못한다고 함 |
🥐 연습문제
연습문제 1 find문제
- 데이터입력
주의해야 할 점 : insertMany를 할 때 전부
[]로 묶어주기
db.mongotest.insertMany([
{ item: "journal", status: "A", size: { h: 14, w: 21, uom: "cm" }, instock: [{ warehouse: "A", qty: 5 }] },
{ item: "notebook", status: "A", size: { h: 8.5, w: 11, uom: "in" }, instock: [{ warehouse: "C", qty: 5 }] },
{ item: "paper", status: "D", size: { h: 8.5, w: 11, uom: "in" }, instock: [{ warehouse: "A", qty: 60 }] },
{ item: "planner", status: "D", size: { h: 22.85, w: 30, uom: "cm" }, instock: [{ warehouse: "A", qty: 40 }] },
{ item: "postcard", status: "A", size: { h: 10, w: 15.25, uom: "cm" }, instock: [{ warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 }] },
{ item: "hat", status: "B", size: { h: 12, w: 12, uom: "cm" }, instock: [{ warehouse: "C", qty: 20 }] },
{ item: "shovel", status: "B", size: { h: 80, w: 12, uom: "cm" }, instock: [{ warehouse: "C", qty: 100 }] },
{ item: "broom", status: "C", size: { h: 80, w: 8, uom: "cm" }, instock: [{ warehouse: "A", qty: 5 }, { warehouse: "C", qty: 5 }] }
]);- 문제1. 창고에서 물품을 정리해야 한다. 측정된 물품의 단위가 in인 물품을 cm로 바꾸려고 한다.
단위가 in인 물품의 목록을 찾아보자.
- 첫 번 째 방법 :
.연산자로 오브젝트 안에 들어있는 값 불어오기 위한 접근 가능
db.inventory.find({"size.uom":"in"})- 두 번째 방법
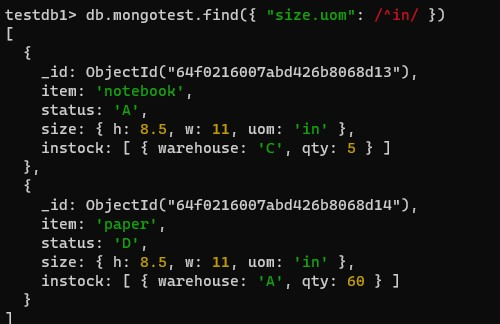
참고
필드이름.0 : 배열의 인덱스 첫 번째 요소를 찾을 수 있음
- 문제2. 창고에 C급, D급인 물품을 찾아서 절반정도의 물량을 창고에서 버리려고 한다. 창고에 C급,D급인 물품을 모두 찾아보자.
db.mongotest.find({status: {$in: ["C", "D"]}})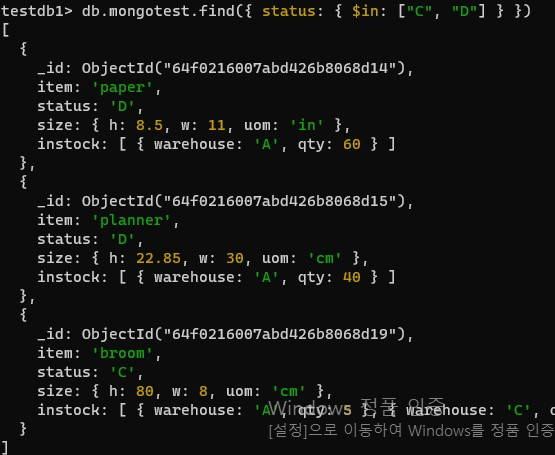
- 문제3. B창고에 길고 가느다란 공간이 비어서 그 빈 공간을 채우기 위해 폭(w)이 15cm보다 작고 높이(h)가 50cm이상, 100cm이하인 물품을 찾아서 채워넣으려고 한다.
db.mongotest.find({"size.w": {$lt: 15}, "size.h": {$gte:50, $lte:100}})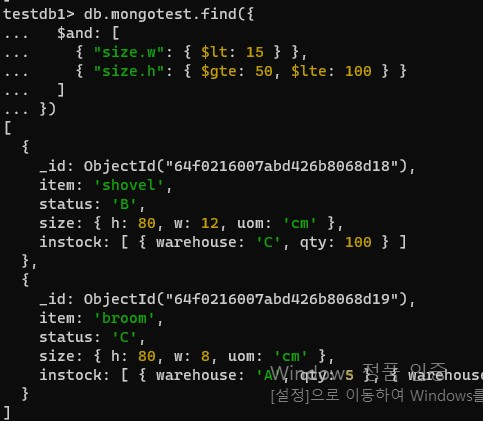
연습문제 CRUD 2
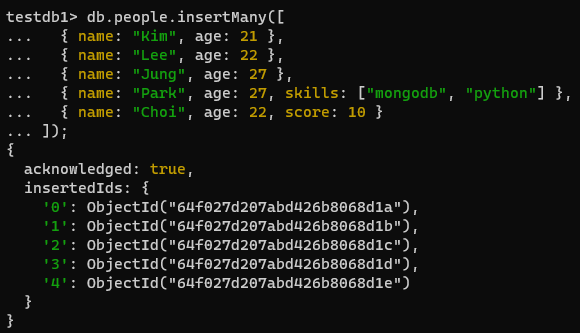
- testdb1 , people 컬렉션을 생성하여 아래 기본 데이터를 입력해주세요.
db.people.insertMany([
{ name: "Kim", age: 21 },
{ name: "Lee", age: 22 },
{ name: "Jung", age: 27 },
{ name: "Park", age: 27, skills: ["mongodb", "python"] },
{ name: "Choi", age: 22, score: 10 }
]);
- 입력된 모든 사원들의 document를 검색하세요
db.people.find({})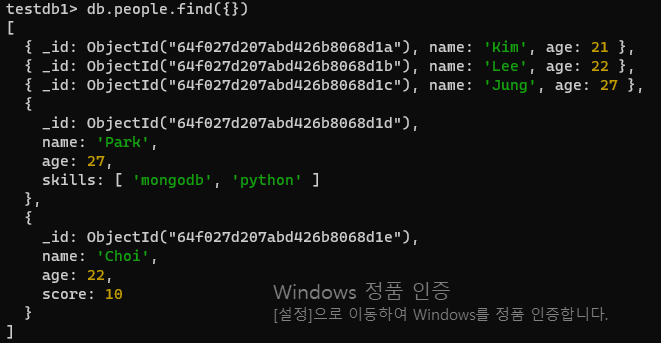
- name 이 'Jung' 정보를 삭제하세요
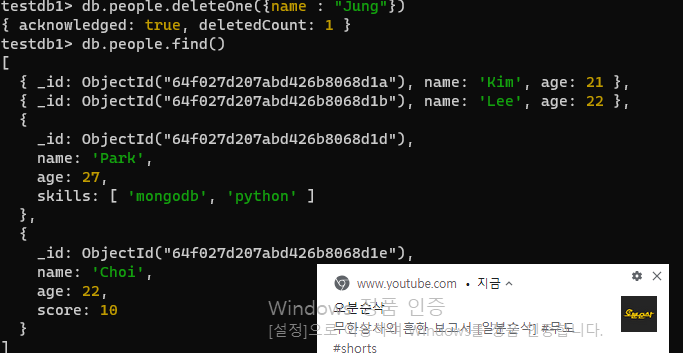
db.people.deleteOne({name : "Jung"})- 사원 중 이름이 Lee 인 document를 이름 : Lim , age : 25 변경하세요
db.people.updateOne({name : "Lee"}, {$set : {name :"Lim", age: 25}});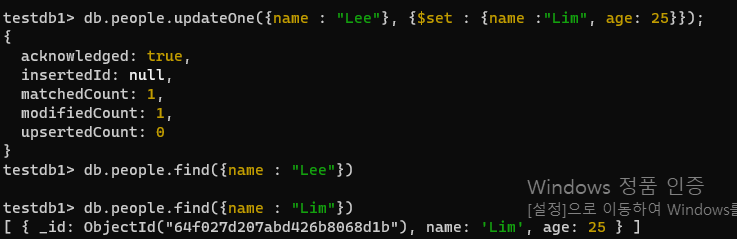
- 이름이 Kim인 문서의 나이를 20을 변경하세요 - update
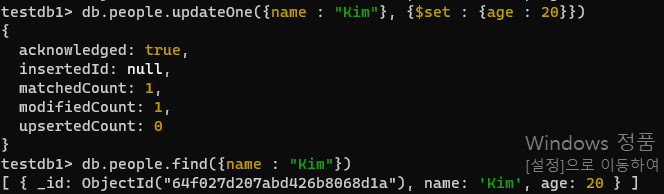
db.people.updateOne({name : "Kim"}, {$set : {age : 20}})- 이름이 Park 인 문서에서 기술필드(skills)를 제거합니다. -일부 필드 제거
- 아래사진은 7번 후에 한 것으로 choi의 스코어가 8임
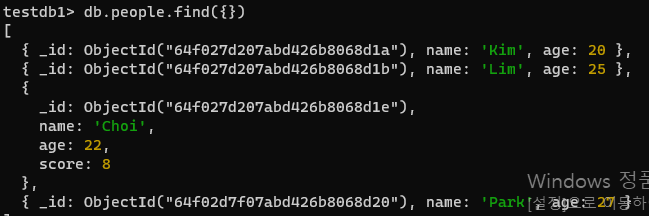
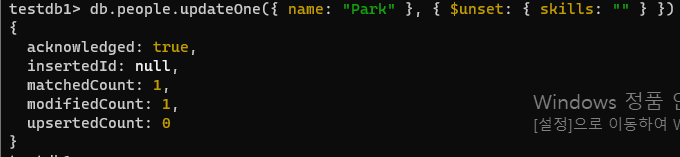
db.people.updateOne({ name: "Park" }, { $unset: { skills: "" } })- 이름이 Choi 인 문서에서 점수(score)필드를 2만큼 줄입니다.
- 찾아보니 최근에는 dec가 문법적으로 안된다고 하여 inc 사용
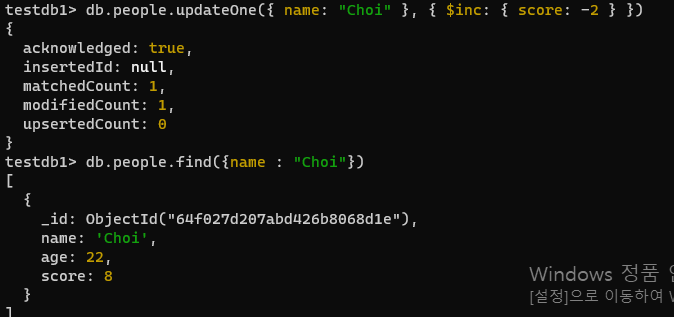
연습문제 3
- testdb1에 score컬렉션 생성 및 데이터 넣기
db.people.updateOne({ name: "Choi" }, { $inc: { score: -2 } })db.score.insertMany([({name:"Kim junsung",kor:90,eng:71,mat:88}),
({name:"Lee jiyeon",kor:80,eng:87,mat:78}),
({name:"Park heji",kor:60,eng:80,mat:58}),
({name:"Kim yura",kor:89,eng:83,mat:75}),
({name:"Choi jinsu",kor:54,eng:91,mat:68}),
({name:"Lee jisun",kor:95,eng:88,mat:98})]);
- score전체 출력 해보세요
db.score.find({})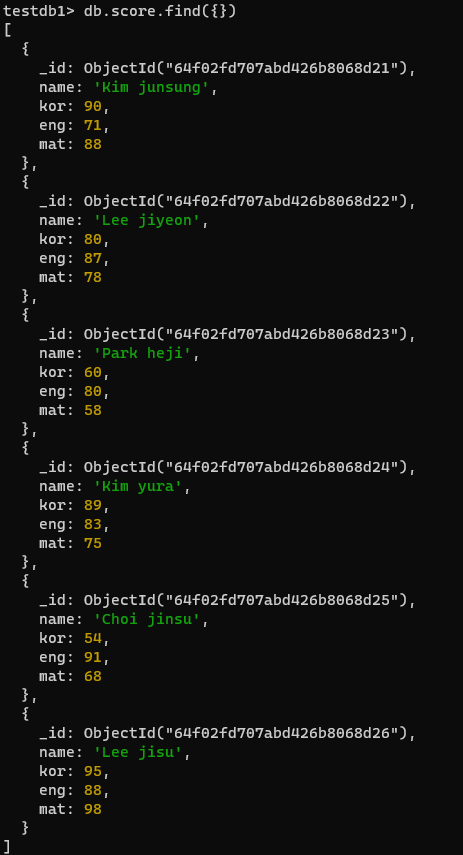
- 이름과 수학 점수만 출력
참고
쿼리가 어떤 도큐먼트를 불러올지를정하는 파라미터라면,프로젝션은 각각의 도큐먼트를 어떤 필드를 노출할지 결정해주는 파라미터 => 원하는 필드만 가지고 옴 true(1), false(0) 둘다 있다면 에러남
단, _id는 제외

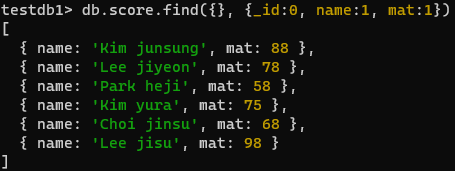
db.score.find({}, {_id:0, name:1, mat:1})- 수학 점수 중 70점 이상만 출력 이상 - gte
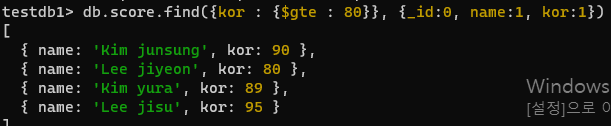
db.score.find({mat : {$gte : 70}})- 이름과 국어를 출력하되, 국어 점수가 80점 이상 문서만 출력
find()메서드에서 조건을 지정할 때는 두 번째 인자로 전달되는 프로젝션 객체에만 필드를 포함하거나 제외시킬 수 있다.
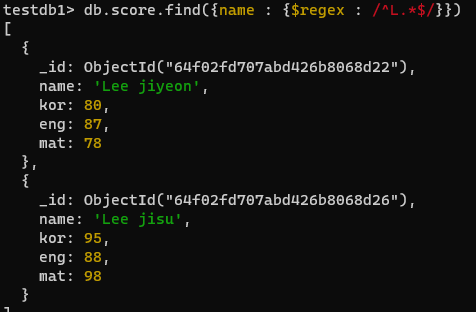
db.score.find({kor : {$gte : 80}}, {_id:0, name:1, kor:1})- 이름이 'L' 로 시작되는 문서 출력
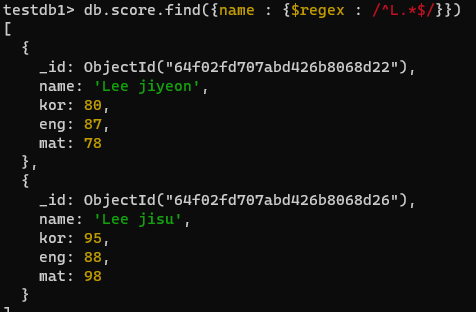
^: 문자열의 시작을 나타냄L: 문자 "L"을 나타냄.*: 임의의 문자가 0번 이상 반복되는 것을 나냄$: 문자열의 끝을 나타냄
db.score.find({name : {$regex : /^L.*$/}})4. 맛있는 MonogoDB에 있는 예제
🥐 Capped 컬렉션과 뷰
Capped란
- 이 컬렉션의 경우 일반 컬렉션이랑 다르게 정해진 크기를 초과하면, 자동으로 가장 오래된 데이터 삭제
- 로그 데이터나, 일정 시간 동안만 보관하는 통계 데이터를 보관할 때 유용

뷰
- 데이터 베이스 안에 쓸 수는 없고 읽을수 있는 뷰 생성 가능
- 뷰는 미리 설정한 내용에 의해 뷰를 불러올 때마다 실제로 데이터를 저장한 컬렉션으로부터 데이터를 모아서 데이터를 출력하게 된다.
예를 들어 회원에 대한 컬렉션과 회원의 포인트에 대한 컬렉션이 각 각 따로 있다.
내 애플리케이션의 많은 부분이 회원정보와 포인트에 대한 정보에 동시에 접근하게 되면, 코드를 간결하게 유지하고 가독성을 높이기 위해 회원정보와 포인트를 한 번에 불러올 수 있는 뷰를 만들어 활용 가능
- 뷰를 생성하더라도 물리적인 데이터베이스 내부에는 회원정보와 포인트 정보가 합쳐지지 않은 채로 존재한다.
- 하나의 컬렉션인 것처럼 가공해서 출력
- 뷰는 실제 데이터를 저장해서 불러오지 않기 때문에 사용할 수 있는 명령어의 제약이 있다.
집계 파이프라인문법 이용
🥐 MongoDB 관리 툴 소개
- URL에 접속시 명령이 수행되는 시간, 메모리 사용률, CPU 사용률, 수행된 명령의 수를 얻을 수 있음

흠.. 하지만 책과 달리 나오지는 않는다.
- 찾아보니
db.getFreeMonitoringStatus()된다고 해서 해보니 된다.
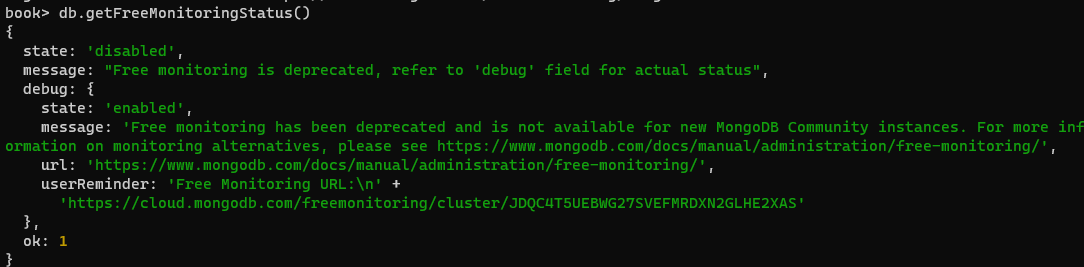
3. 이 기능을 이용하면 원격으로 데이터 베이스의상태를 알 수 있다고 한다.
🥐 데이터 베이스 상태 조회
🥐 컬렉션 상태 조회
p.42
🥐 원자성의 이해
mongoDB는 CRUD 작업에대해 원자성을 확보하고 있다. 즉, 데이터베이스에는 작업이 완료된 상태가 되거나 완료되기 전 상태만 존재하지 그 중간 상태는 존재하지 않는다는 것이다.
insertOne함수의 경우 따로 어떤 작업을 하지 않아도 원자성을 가지고 있다.- `insertMany' 명령의 경우 각각 하나의 도큐먼트에는 원자성이 적용되지만, 입력하는 모든 도큐먼트에 대해 원자성이 적용되지 않는다.
예를 들어 ATM 기기에 1만원을 넣고 2만원을 빼려고 했는데 1만원 넣기는 성공했는데 2만원 빼기는 실패 시 이 작업 전체는 원자성을갖추지 못하게 된다. => 이런 것을 해결하기 위해 나온 것 '트랜잭션'
🥐 게시판에 글쓰기
-
board 데이터베이스 작업
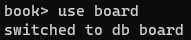
-
자유게시판이랑 비밀게시판을 생성한다.
freeboard_result = db.board.insertOne({name : "자유게시판"})
freeboard_id = freeboard_result.insertedId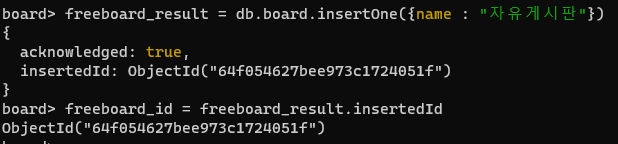
- 자유게시판에 아무 글이나 3개 작성하자. 특히 그중에서 글 하나에는 댓글 하나가 달린 상태로 생성
db.articla.insertMany([{board_id: freeboard_id, title : 'hello', content: 'hi, hello1', author : 'Karoid'},{board_id : freeboard_id, title:'hi', content:'ji, hello2', author:'Jeong'},{board_id: freeboard_id, title : 'hel', content: 'hi, hello3', author : 'Kim',comments: [{author : 'Karoid', content : 'hello Hong'}]},])
🥐 커서(cursor)
- 쿼리 결과에 대한 포인터로 find 명령어는 결과로 도큐먼트를 직접 반환하지 않고 커서를 반환한다. 더 나은 성능을 위해서이다.
- 포인터를 이용한다면 해당 도큐먼트의 위치 정보만을 반환하여 작업을 효과적으로 만들 수 있다.
- 커서를 이용하면 데이터 전부 불러올 도큐먼트만 선별적으로 조회
- 커서는 일시적으로 결과를 읽어내려고 존재하기 때문에 시간 제한 10분을 넘기면 비활성 상태로 전환
회고
몽고디비 문법 익숙해지는데는 시간이 걸릴 것 같다... 사람들이 몽고디비 몽고디비해서 뭘까 했는데.. 가장 좋은 이유가 가변적인것에 확장적이라는 점, 스키마가 없다는 점인 것 같다. SQL도 다 잊어버린 것 같은데... 할 거 너무 많다... CS도 해야하고 프로젝트 다가오니 프로젝트에 내야 할 것도 많고 CS 스터디 공부도 해야하는데 많이 하는데 머리 속이 정리가 안된 느낌...
이번주에 해야 할 것 : 점핏 2부 강의 듣기, 자소서 내기, 노션에 포트폴리오 틀 잡기, 금요일에 멘토링 신청한 거 질문에 대한 답변 적기, SQL 깃허브 리포지토리 따로 파서 정리하기
블로그에 올릴 글 : CS 스터디에서 한 부분 보충, 점핏 2부, 8월 회고록 ... 등등
가능하다면... 독서 저번주에 못한 4장 마저 하자.. 취업전까지 주니어가 읽어야 하는 테스트 부분까지는 읽기
화이팅..
