📌 6일차 배운 내용 목차
| 번호 | 주제 | 내용 |
|---|---|---|
| 1 | CSS | - 선택자 (전체, 태그, 아이디, 클래스, 계층) - 계층 선택자: 자식, 자손, 인접형태, 형제 |
| 2 | Selenium을 이용한 크롤링 | - |
✏️1. CSS( cascading Style Sheets)
✔️CSS란?
- HTML문서의 스타일을 꾸밀 때 사용하는 스타일 시트 언어
- why 사용? 유지보수 편의성 + 재사용성
font 속성
| 속성 | 설명 |
|---|---|
font-family | 글꼴 (예: 나눔고딕, 굴림, 돋움 등) |
font-size | 글자 크기 (px, em, rem 단위 사용) |
font-weight | 글자 두께 (bold, 100 ~ 900) |
font-style | 글자 스타일 (italic 등) |
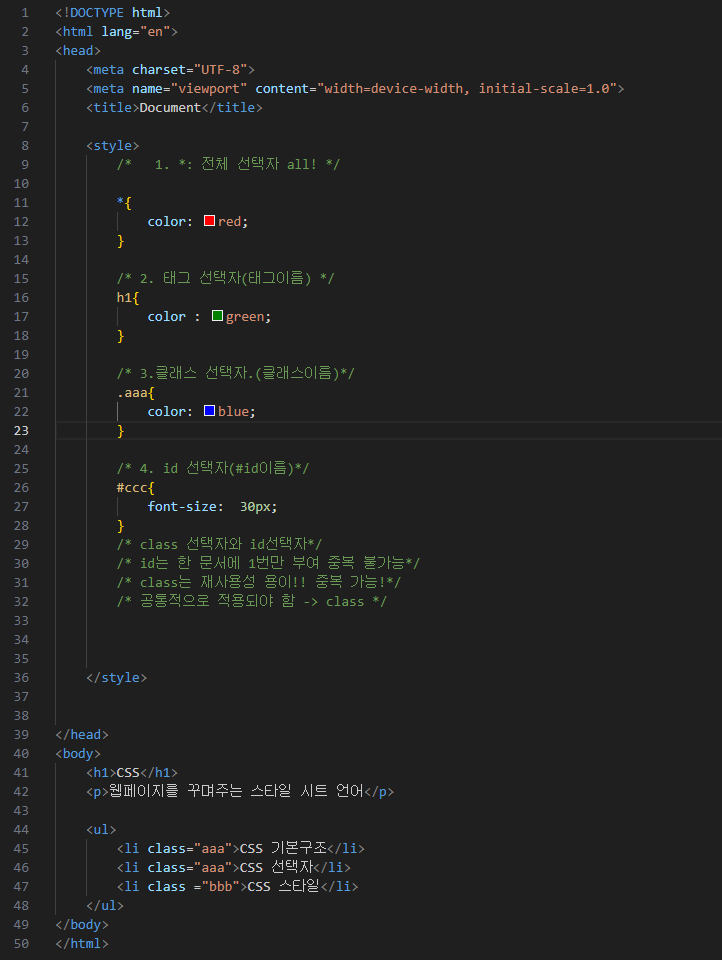
선택자
| 선택자 종류 | 설명 |
|---|---|
| 전체 선택자 | *로 표시되며, 웹 문서 내 모든 요소 선택 |
| 타입 선택자 | 요소 이름으로 사용하여 요소 선택 (예: div, p, h1 등) |
| 아이디 선택자 | # 기호로 표시되며 특정한 요소 선택 - body 태그 내 하나만 존재 - 한 페이지 내 한 번만 사용 - 상단메뉴, 하단정보 등 특정 요소 스타일 지정 |
| 클래스 선택자 | . 마침표 기호로 표시되며 특정한 요소 선택 - 여러 개의 태그에 동시에 적용 가능 - 재사용 가능 - 반복적으로 사용되는 스타일 정의에 적합 |
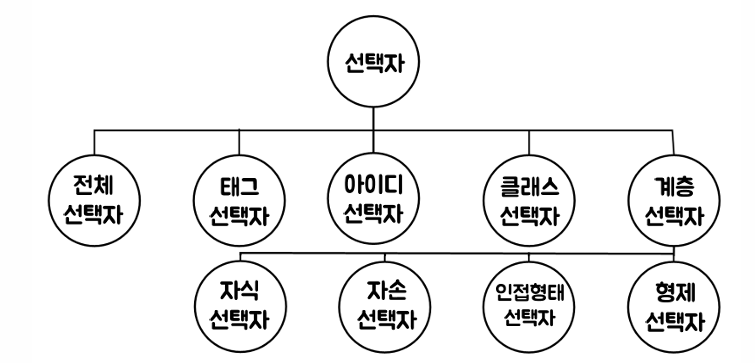
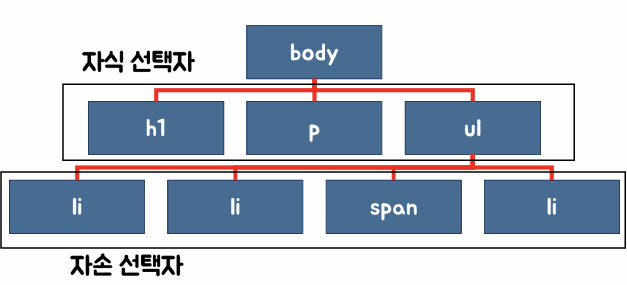
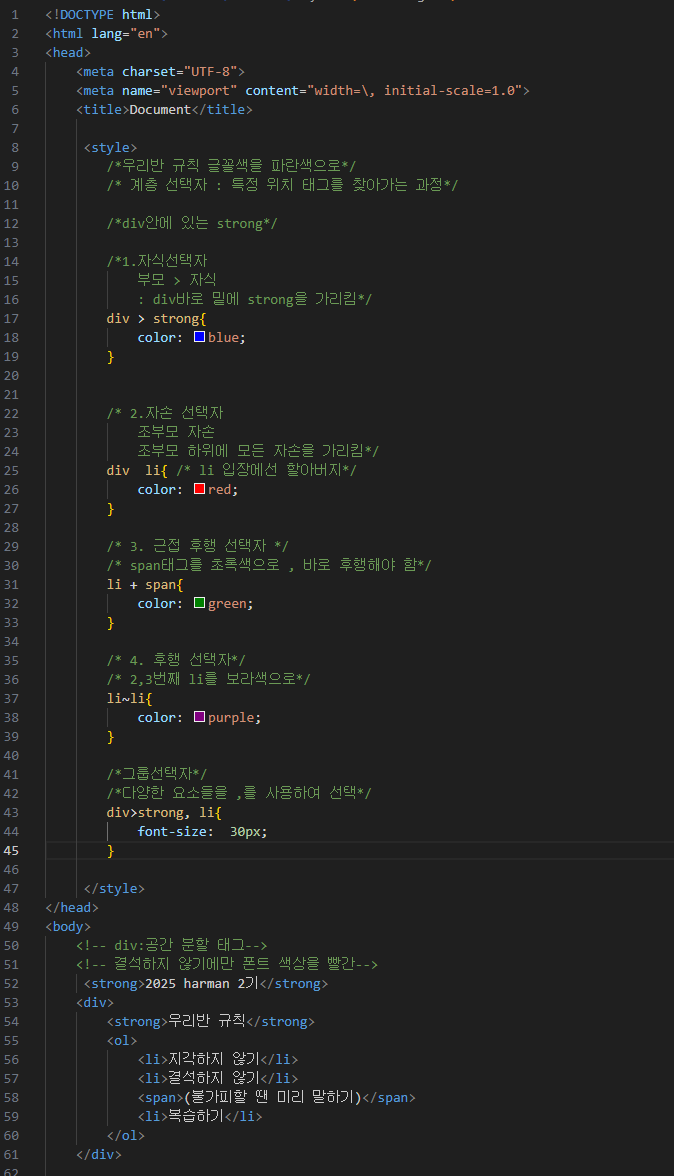
| 계층 선택자 | 특정 위치의 요소를 계층적 구조로 선택 (예: 자식, 자손, 형제, 인접 등) |
| 그룹 선택자 | 여러 요소를 쉼표( , )로 구분하여 한 번에 선택 |
계층

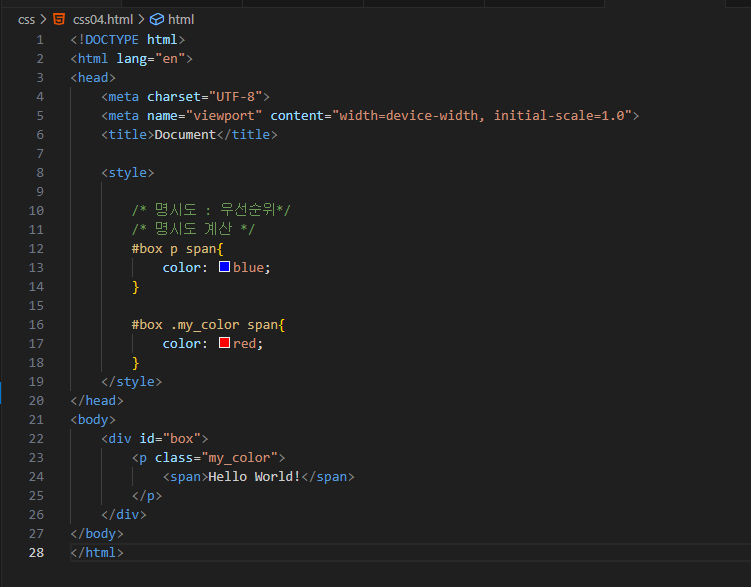
명시도 계산
| 가중치 | 스타일 적용 | 예시 |
|---|---|---|
| 0 | 전체 선택자 | * { color: red; } |
| 1 | 타입 선택자 | p { color: red; } |
| 10 | 클래스 선택자 | .txt { color: red; } |
| 100 | 아이디 선택자 | #main { color: red; } |
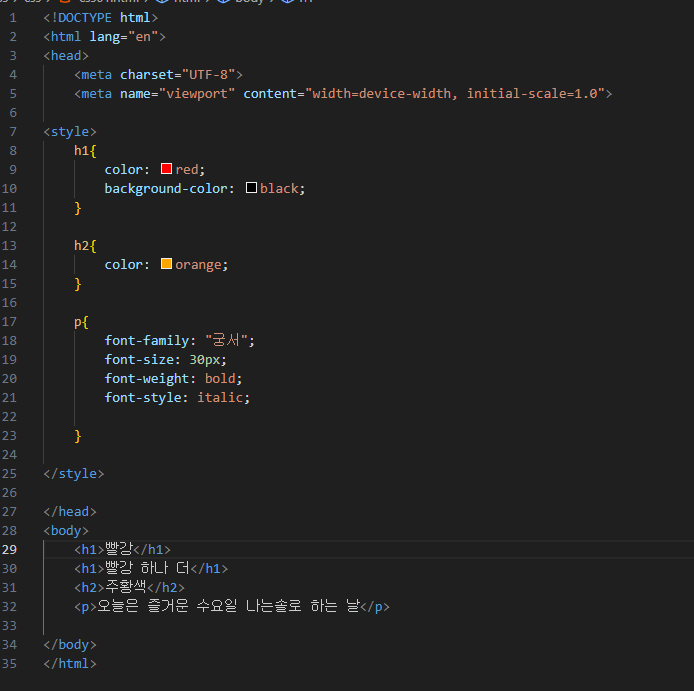
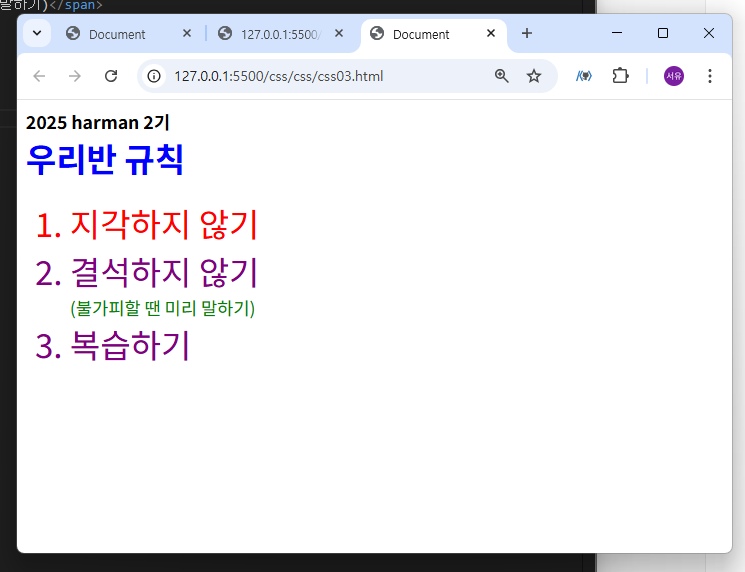
연습
1)
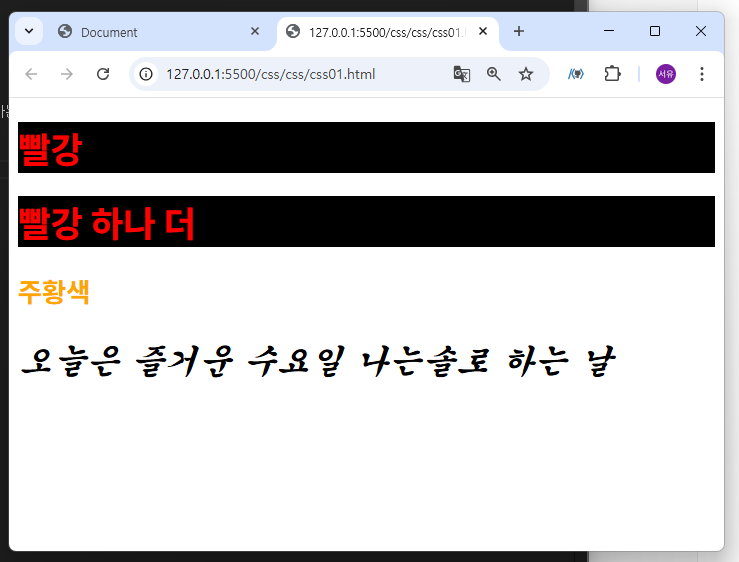
2)
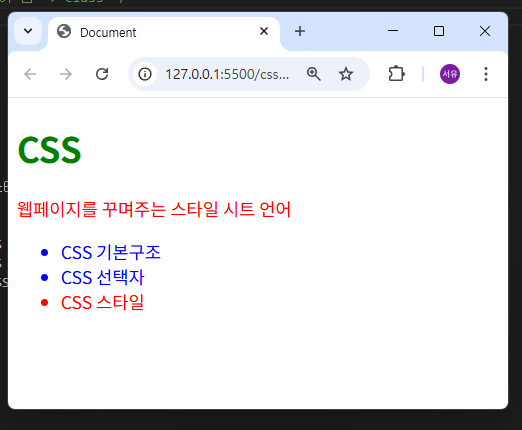
3)
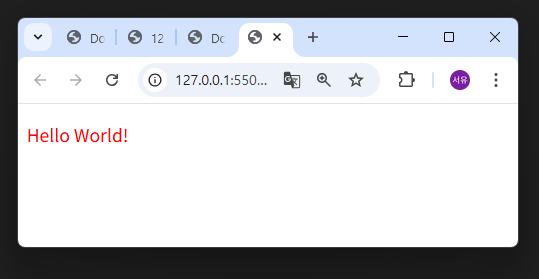
4)
✏️2. Selenium
✔️ Selenium이란?
- 웹 브라우저를 자동으로 제어할 수 있는 오픈소스 라이브러리!
- 크롤링뿐만 아니라 웹 앱 테스트, 자동화 업무에 사용!
동적 vs 정적 웹페이지
정적 : HTML이 고정되어 있어 requests와 BeautifuSoup으로 쉽게 크롤링 가능
동적 : JavaScript로 로드되는 콘텐츠가 있어 Selenium으로 제어해야함
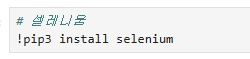
셀레니움 사용시 기본적으로 들고가는 라이브러리

연습
1) 화곡역 맛집 찾기
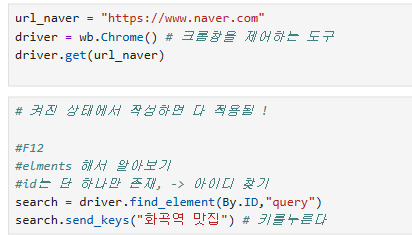
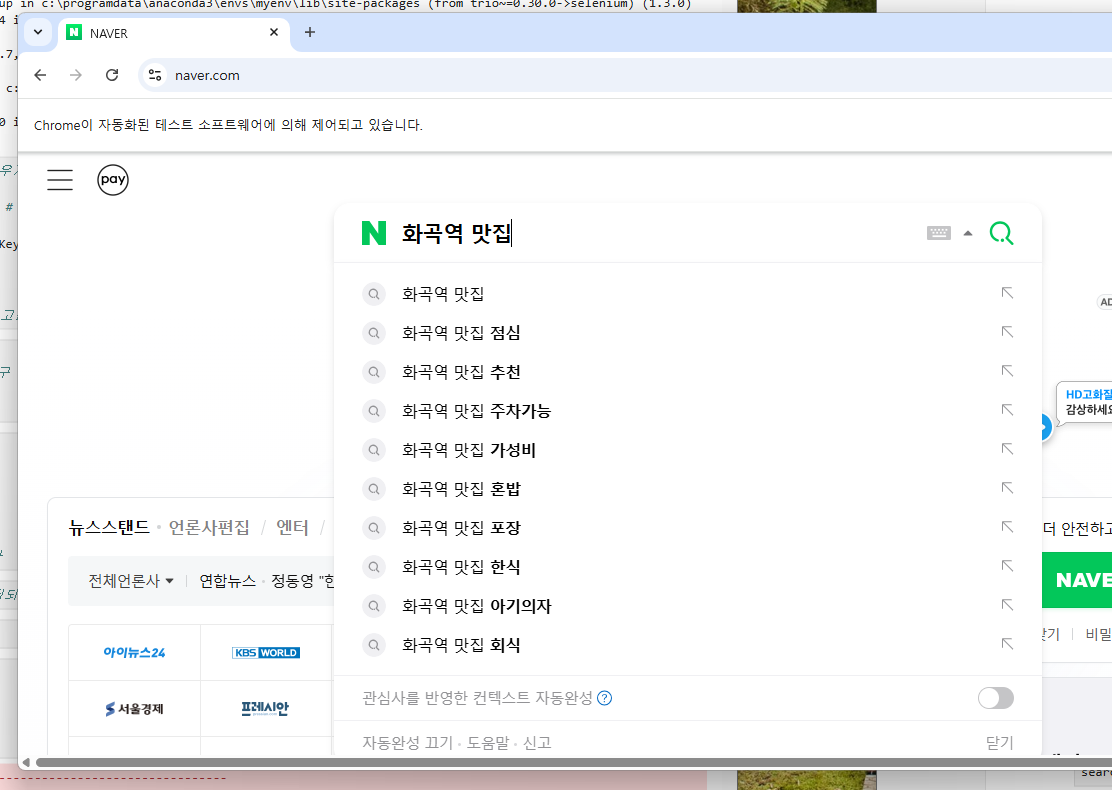

2) 이미지 검색 후 관련 폴더에 다운로드
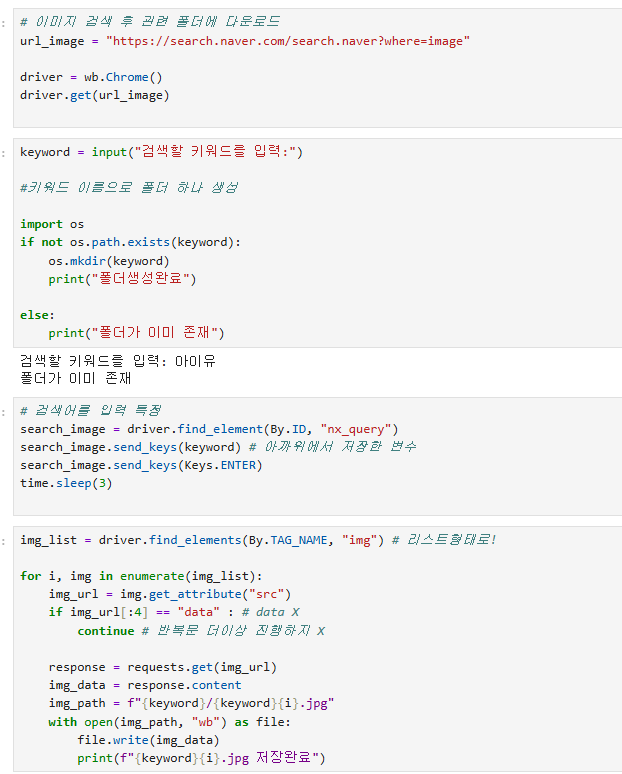
3) 이미지 저장 코드 정리!!
#1. selentium 관련 라이브러리 import (3개)
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 2. time 라이브러리 import
import time
# 3. os 라이브러리 import, request 라이브러리 import
import os
import requests
# 4. 네이버 이미지 검색 url이용해 ""
url = "https://search.naver.com/search.naver?where=image"
# 5. 사용자로부터 검색할 키워드 입력 받아 keyword 저장
keyword_user = input("검색할 키워드를 입력하세요:")
# 6. 폴더 만들자(단,폴더가 없다면)
if not os.path.exists(keyword_user):
os.mkdir(keyword_user)
print(f"{keyword_user}폴더생성완료")
else:
print(f"{keyword_user}이미존재")
# 7. wb 활용해서 Chrome 켜고
driver = wb.Chrome()
driver.get(url)
# 8. 사용자가 입력한 keyword 던져서 이미지 검색!
search_user = driver.find_element(By.ID, "nx_query")
search_user.send_keys(keyword_user)
search_user.send_keys(Keys.ENTER)
time.sleep(3) # 이미지 로딩시간
# 9. 나온 이미지 들을 find_elements를 통해 list로 저장
search_user_list = driver.find_elements(By.TAG_NAME, "img")
# 10. for문을 돌면서 이미지 주소를 가져오고
# 11. 해당 이미지 주소가 data로 시작이 안된다면
# 12. requests 통해 요청
# 13. 응답된 결과를 response를 통해 byte 형태로 받자(content)
# 14. with ~ open(경로, "wb")를 통해 key폴더에 이미지를 저장하자
response = requests.get(url)
img_data = response.content
for i, img in enumerate(search_user_list):
url = img.get_attribute("src")
if url[:4] == "data" : # data X
continue # 반복문 더이상 진행하지 X
response = requests.get(url)
img_data = response.content
img_path = f"{keyword_user}/{keyword_user}{i}.jpg"
with open(img_path, "wb") as file:
file.write(img_data)
print(f"{keyword_user}{i}.jpg 저장완료")
# 15. driver.close()
driver.close()-> 결과 : 차은우 폴더를 만들어서 차은우의 사진들을 저장해봄 ㅎㅎ