study 5차

✍ EKS Autoscaling 실습환경 배포
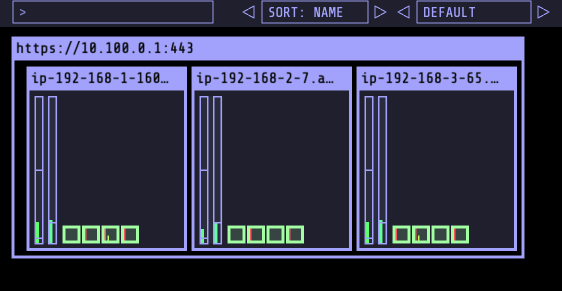
EKS Node Viewer 설치 : 노드 할당 가능 용량과 요청 request 리소스 표시, 실제 파드 리소스 사용량 X - 링크
# go 설치
yum install -y go
# EKS Node Viewer 설치 : 현재 ec2 spec에서는 설치에 다소 시간이 소요됨 = 2분 이상
go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest
# bin 확인 및 사용
tree ~/go/bin
cd ~/go/bin
./eks-node-viewer
3 nodes (875m/5790m) 15.1% cpu ██████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ $0.156/hour | $113.880/month
20 pods (0 pending 20 running 20 bound)
ip-192-168-3-196.ap-northeast-2.compute.internal cpu ████████░░░░░░░░░░░░░░░░░░░░░░░░░░░ 22% (7 pods) t3.medium/$0.0520 On-Demand
ip-192-168-1-91.ap-northeast-2.compute.internal cpu ████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 12% (6 pods) t3.medium/$0.0520 On-Demand
ip-192-168-2-185.ap-northeast-2.compute.internal cpu ████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 12% (7 pods) t3.medium/$0.0520 On-Demand
Press any key to quit
명령 샘플
# Standard usage
./eks-node-viewer
# Display both CPU and Memory Usage
./eks-node-viewer --resources cpu,memory
# Karenter nodes only
./eks-node-viewer --node-selector "karpenter.sh/provisioner-name"
# Display extra labels, i.e. AZ
./eks-node-viewer --extra-labels topology.kubernetes.io/zone
# Specify a particular AWS profile and region
AWS_PROFILE=myprofile AWS_REGION=us-west-2
기본 옵션
# select only Karpenter managed nodes
node-selector=karpenter.sh/provisioner-name
# display both CPU and memory
resources=cpu,memory(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# cd ~/go/bin
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# ./eks-node-viewer

✍ HPA - Horizontal Pod Autoscaler
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# cat php-apache.yaml | yh
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
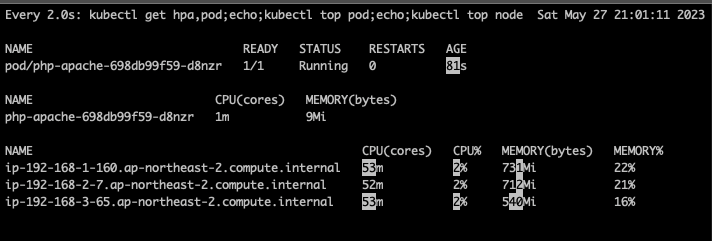
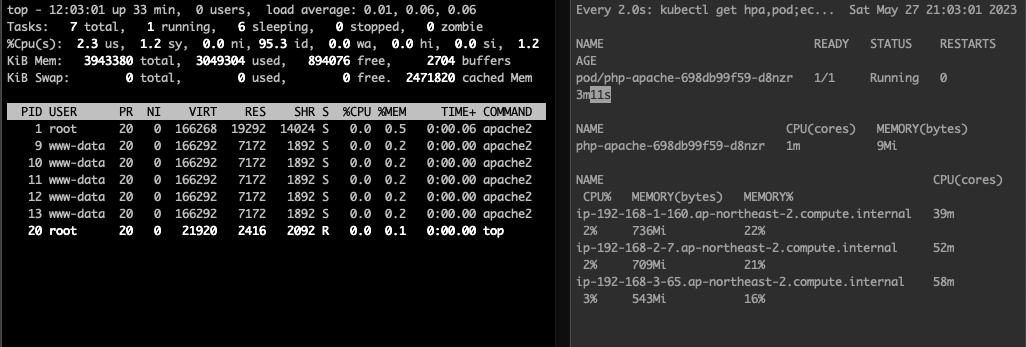
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl describe hpa
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: php-apache
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 27 May 2023 21:10:19 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#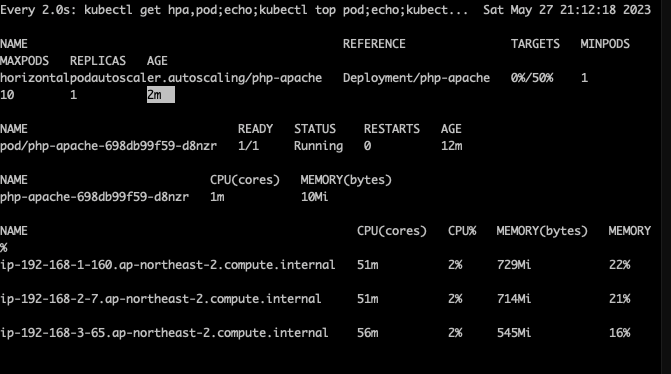
HPA 생성 및 부하 발생 후 오토 스케일링 테스트 : 증가 시 기본 대기 시간(30초), 감소 시 기본 대기 시간(5분) → 조정 가능
# HPA 설정 확인
kubectl krew install neat
kubectl get hpa php-apache -o yaml
kubectl get hpa php-apache -o yaml | kubectl neat | yh
spec:
minReplicas: 1 # [4] 또는 최소 1개까지 줄어들 수도 있습니다
maxReplicas: 10 # [3] 포드를 최대 5개까지 늘립니다
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache # [1] php-apache 의 자원 사용량에서
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # [2] CPU 활용률이 50% 이상인 경우
# 반복 접속 1 (파드1 IP로 접속) >> 증가 확인 후 중지
while true;do curl -s $PODIP; sleep 0.5; done
# 반복 접속 2 (서비스명 도메인으로 접속) >> 증가 확인(몇개까지 증가되는가? 그 이유는?) 후 중지 >> 중지 5분 후 파드 갯수 감소 확인
# Run this in a separate terminal
# so that the load generation continues and you can carry on with the rest of the steps
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl get hpa php-apache -o yaml | kubectl neat | yh
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#반복 접속 1 (파드1 IP로 접속) >> 증가 확인 후 중지
while true;do curl -s $PODIP; sleep 0.5; done
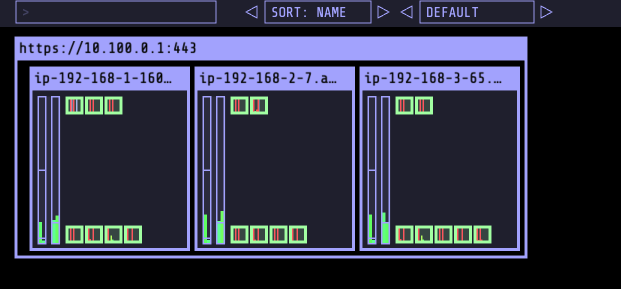
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# while true;do curl -s $PODIP; sleep 0.5; done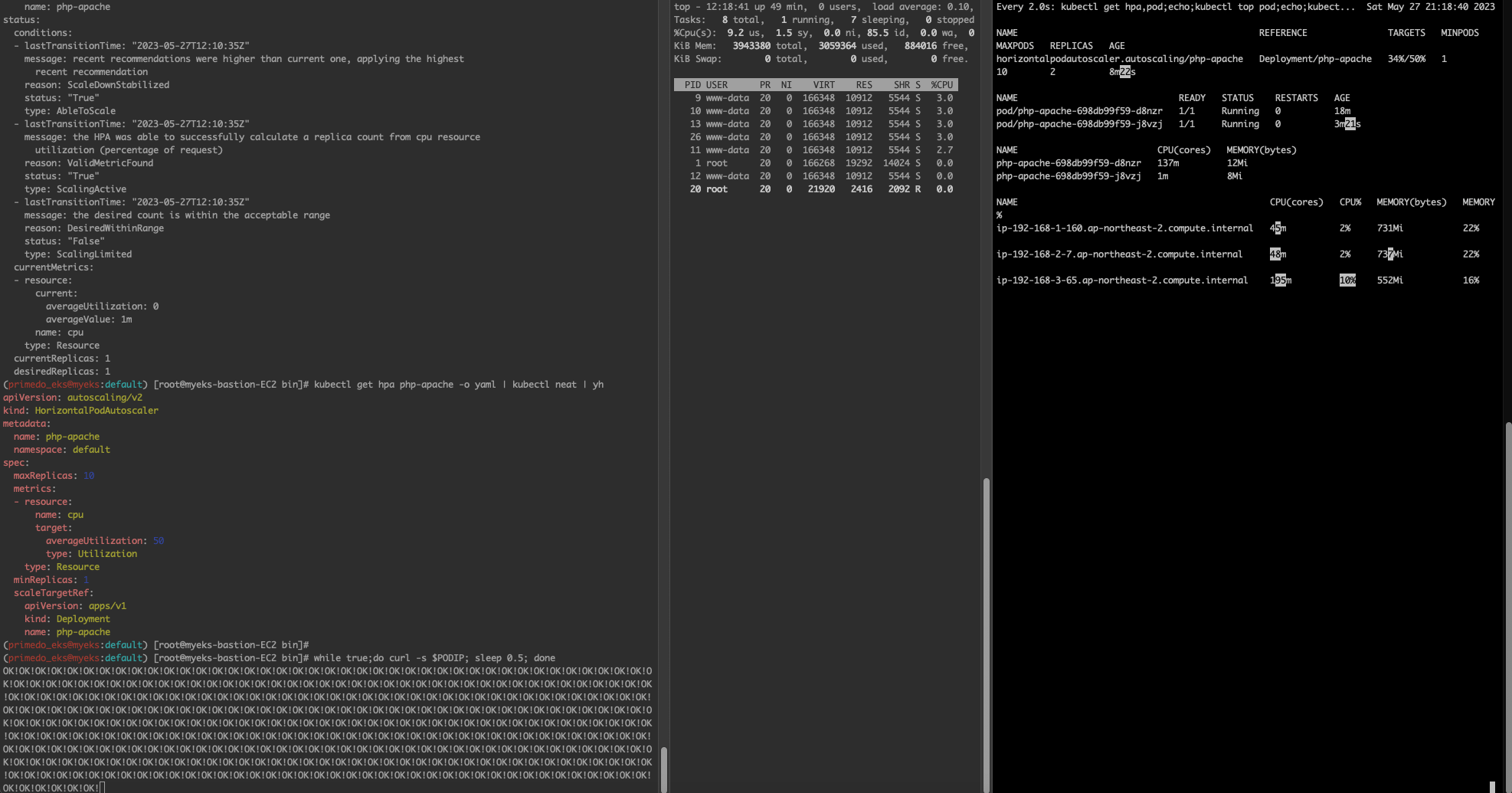
전체 총합 50%여서 더 이상 증가하지는 않는다.
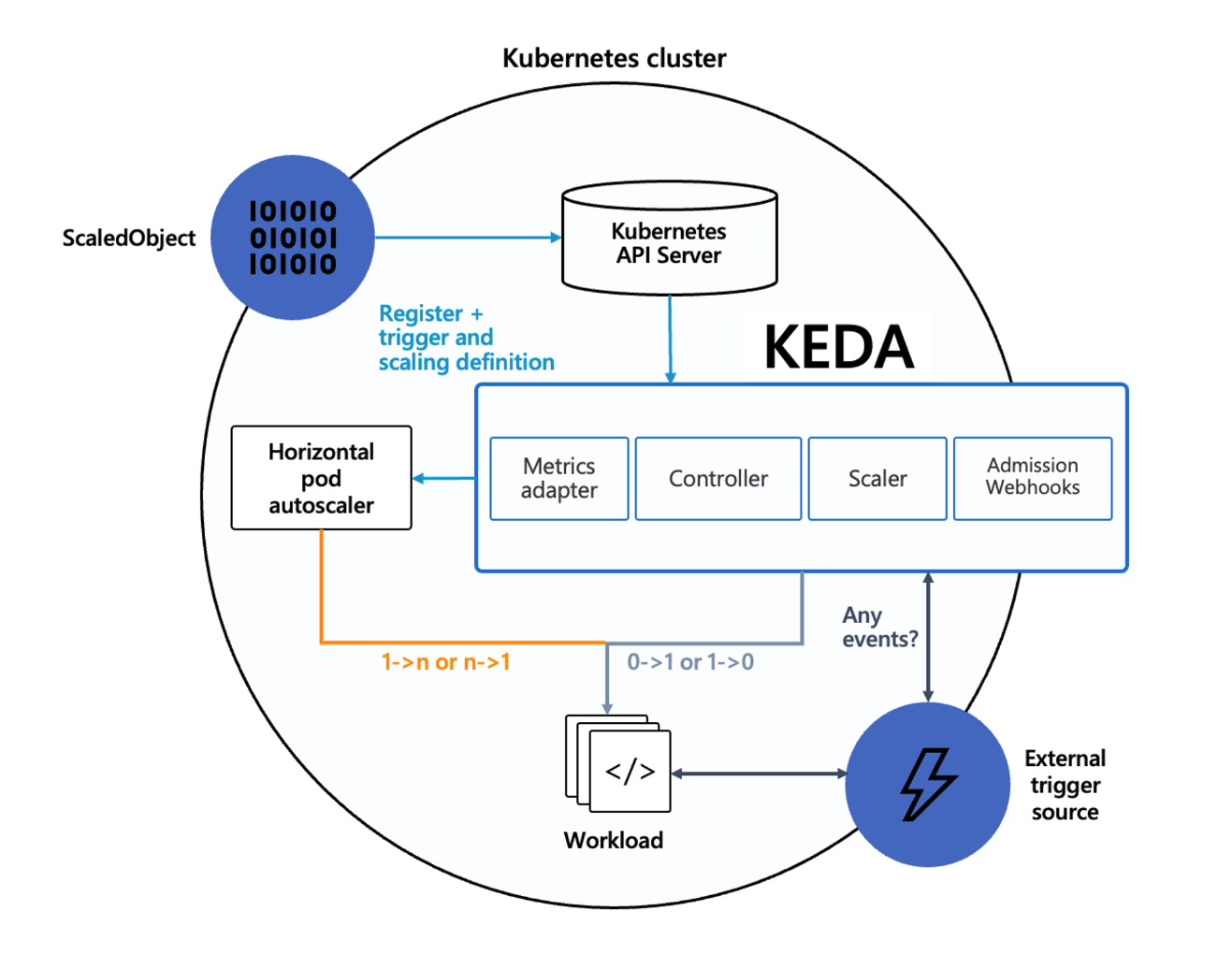
✍ KEDA - Kubernetes based Event Driven Autoscaler
기존의 HPA(Horizontal Pod Autoscaler)는 리소스(CPU, Memory) 메트릭을 기반으로 스케일 여부를 결정하게 됩니다.
반면에 KEDA는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다.
예를 들어 airflow는 metadb를 통해 현재 실행 중이거나 대기 중인 task가 얼마나 존재하는지 알 수 있습니다.
이러한 이벤트를 활용하여 worker의 scale을 결정한다면 queue에 task가 많이 추가되는 시점에 더 빠르게 확장할 수 있습니다.
KEDA Scalers : kafka trigger for an Apache Kafka topic
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.svc:9092 # Comma separated list of Kafka brokers “hostname:port” to connect to for bootstrap.
consumerGroup: my-group # Name of the consumer group used for checking the offset on the topic and processing the related lag.
topic: test-topic # Name of the topic on which processing the offset lag. (Optional, see note below)
lagThreshold: '5' # Average target value to trigger scaling actions. (Default: 5, Optional)
offsetResetPolicy: latest # The offset reset policy for the consumer. (Values: latest, earliest, Default: latest, Optional)
allowIdleConsumers: false # When set to true, the number of replicas can exceed the number of partitions on a topic, allowing for idle consumers. (Default: false, Optional)
scaleToZeroOnInvalidOffset: false
version: 1.0.0 # Version of your Kafka brokers. See samara version (Default: 1.0.0, Optional)# KEDA 설치
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
kubectl create namespace keda
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --version 2.10.2 --namespace keda -f keda-values.yaml
# KEDA 설치 확인
kubectl get-all -n keda
kubectl get all -n keda
kubectl get crd | grep keda
# keda 네임스페이스에 디플로이먼트 생성
kubectl apply -f php-apache.yaml -n keda
kubectl get pod -n keda
# ScaledObject 정책 생성 : cron
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2
pollingInterval: 30
cooldownPeriod: 300
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
kubectl apply -f keda-cron.yaml -n keda
# 그라파나 대시보드 추가
# 모니터링
watch -d 'kubectl get ScaledObject,hpa,pod -n keda'
kubectl get ScaledObject -w
# 확인
kubectl get ScaledObject,hpa,pod -n keda
kubectl get hpa -o jsonpath={.items[0].spec} -n keda | jq
...
"metrics": [
{
"external": {
"metric": {
"name": "s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx",
"selector": {
"matchLabels": {
"scaledobject.keda.sh/name": "php-apache-cron-scaled"
}
}
},
"target": {
"averageValue": "1",
"type": "AverageValue"
}
},
"type": "External"
}
# KEDA 및 deployment 등 삭제
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl get crd | grep keda
clustertriggerauthentications.keda.sh 2023-05-27T12:28:36Z
scaledjobs.keda.sh 2023-05-27T12:28:36Z
scaledobjects.keda.sh 2023-05-27T12:28:36Z
triggerauthentications.keda.sh 2023-05-27T12:28:36Z
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#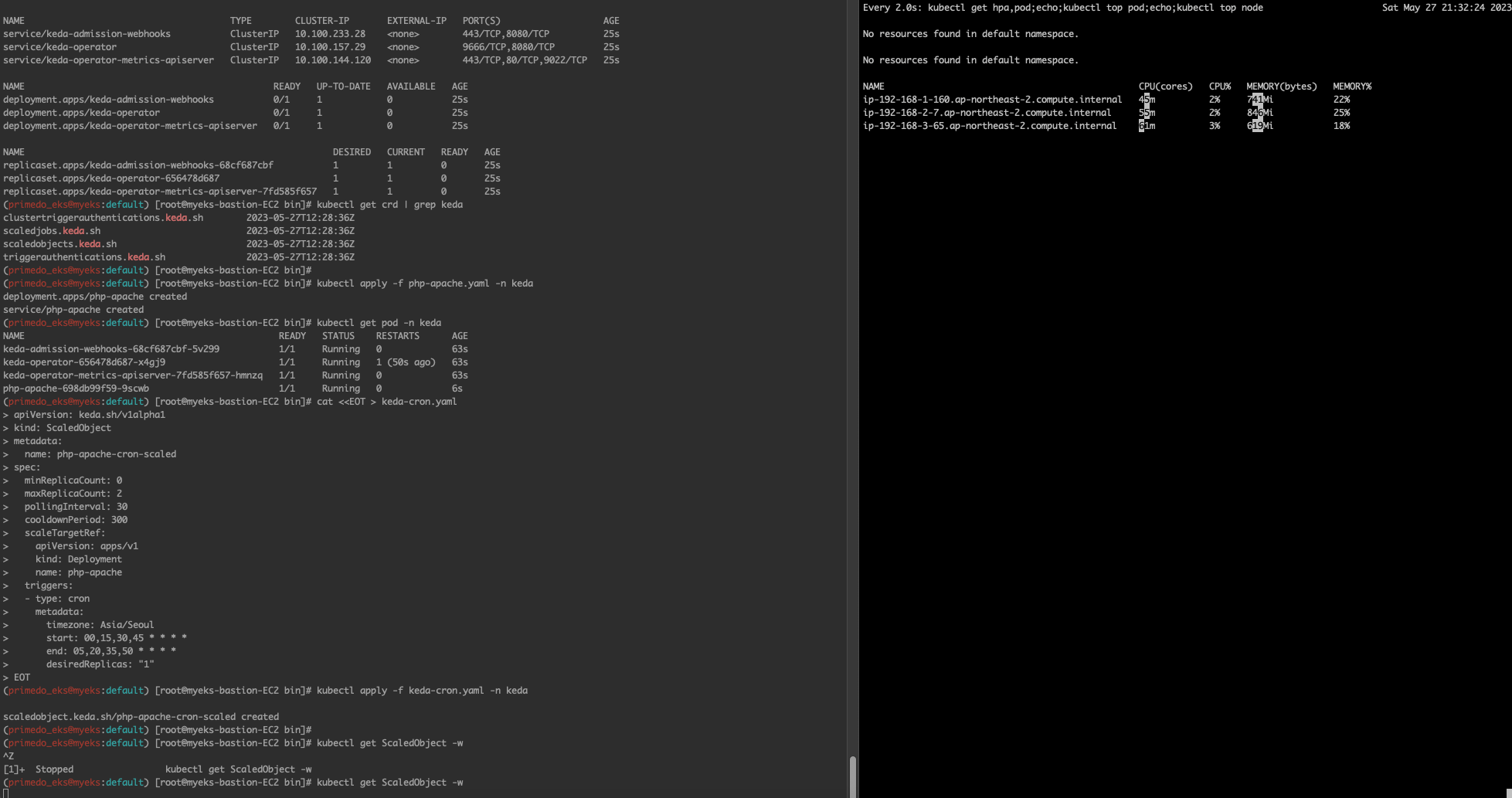
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl get ScaledObject,hpa,pod -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True True Unknown 3m3s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 1 3m3s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-68cf687cbf-5v299 1/1 Running 0 4m30s
pod/keda-operator-656478d687-x4gj9 1/1 Running 1 (4m17s ago) 4m30s
pod/keda-operator-metrics-apiserver-7fd585f657-hmnzq 1/1 Running 0 4m30s
pod/php-apache-698db99f59-9scwb 1/1 Running 0 3m33s
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl get hpa -o jsonpath={.items[0].spec} -n keda | jq
{
"maxReplicas": 2,
"metrics": [
{
"external": {
"metric": {
"name": "s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx",
"selector": {
"matchLabels": {
"scaledobject.keda.sh/name": "php-apache-cron-scaled"
}
}
},
"target": {
"averageValue": "1",
"type": "AverageValue"
}
},
"type": "External"
}
],
"minReplicas": 1,
"scaleTargetRef": {
"apiVersion": "apps/v1",
"kind": "Deployment",
"name": "php-apache"
}
}
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]## KEDA 및 deployment 등 삭제
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda✍ VPA - Vertical Pod Autoscaler
# 코드 다운로드
it clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
tree hack
# 배포 과정에서 에러 발생 : 방안1 openssl 버전 1.1.1 up, 방안2 브랜치08에서 작업
ERROR: Failed to create CA certificate for self-signing. If the error is "unknown option -addext", update your openssl version or deploy VPA from the vpa-release-0.8 branch.
# 프로메테우스 임시 파일 시스템 사용으로 재시작 시 저장 메트릭과 대시보드 정보가 다 삭제되어서 스터디 시간 실습 시나리오는 비추천
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack --reuse-values --set prometheusOperator.verticalPodAutoscaler.enabled=true -n monitoring
# openssl 버전 확인
openssl version
OpenSSL 1.0.2k-fips 26 Jan 2017
# openssl 1.1.1 이상 버전 확인
yum install openssl11 -y
openssl11 version
OpenSSL 1.1.1g FIPS 21 Apr 2020
# 스크립트파일내에 openssl11 수정
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# Deploy the Vertical Pod Autoscaler to your cluster with the following command.
watch -d kubectl get pod -n kube-system
cat hack/vpa-up.sh
./hack/vpa-up.sh
kubectl get crd | grep autoscaling(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]# ./hack/vpa-up.sh
customresourcedefinition.apiextensions.k8s.io/verticalpodautoscalercheckpoints.autoscaling.k8s.io created
customresourcedefinition.apiextensions.k8s.io/verticalpodautoscalers.autoscaling.k8s.io created
clusterrole.rbac.authorization.k8s.io/system:metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:vpa-actor created
clusterrole.rbac.authorization.k8s.io/system:vpa-checkpoint-actor created
clusterrole.rbac.authorization.k8s.io/system:evictioner created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-actor created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-checkpoint-actor created
clusterrole.rbac.authorization.k8s.io/system:vpa-target-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-target-reader-binding created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-evictioner-binding created
serviceaccount/vpa-admission-controller created
serviceaccount/vpa-recommender created
serviceaccount/vpa-updater created
clusterrole.rbac.authorization.k8s.io/system:vpa-admission-controller created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-admission-controller created
clusterrole.rbac.authorization.k8s.io/system:vpa-status-reader created
clusterrolebinding.rbac.authorization.k8s.io/system:vpa-status-reader-binding created
deployment.apps/vpa-updater created
deployment.apps/vpa-recommender created
Generating certs for the VPA Admission Controller in /tmp/vpa-certs.
Generating RSA private key, 2048 bit long modulus (2 primes)
...........................................................................................+++++
........................+++++
e is 65537 (0x010001)
Can't load /root/.rnd into RNG
140639356966720:error:2406F079:random number generator:RAND_load_file:Cannot open file:crypto/rand/randfile.c:98:Filename=/root/.rnd
Generating RSA private key, 2048 bit long modulus (2 primes)
..+++++
.............................................................................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = vpa-webhook.kube-system.svc
Getting CA Private Key
Uploading certs to the cluster.
secret/vpa-tls-certs created
Deleting /tmp/vpa-certs.
deployment.apps/vpa-admission-controller created
service/vpa-webhook created
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]# kubectl get crd | grep autoscaling
verticalpodautoscalercheckpoints.autoscaling.k8s.io 2023-05-27T12:47:29Z
verticalpodautoscalers.autoscaling.k8s.io 2023-05-27T12:47:29Z
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]#tag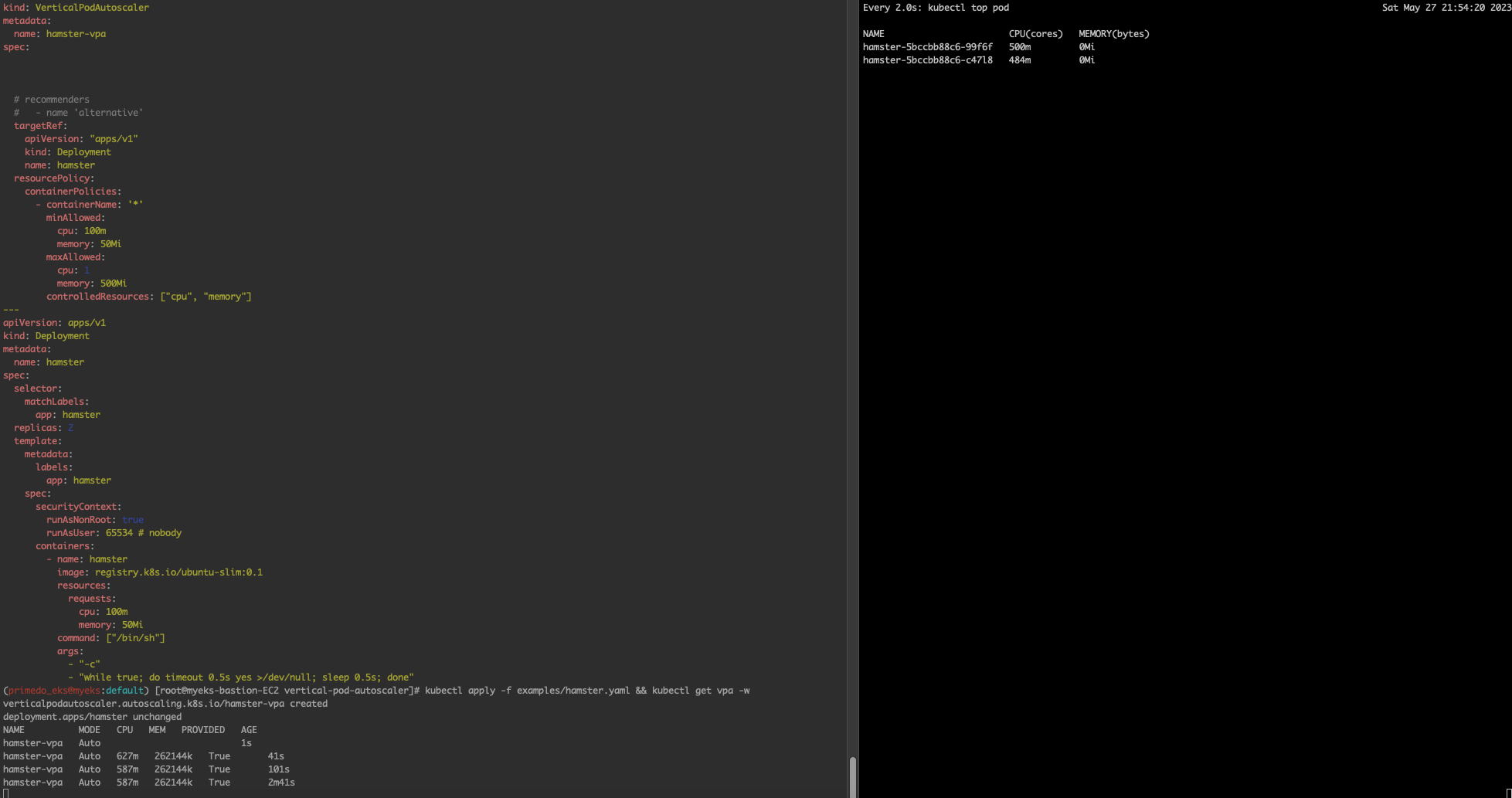
파드 리소스 Requestes 확인
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# kubectl describe pod | grep Requests: -A2
Requests:
cpu: 627m
memory: 262144k
--
Requests:
cpu: 587m
memory: 262144k
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]# kubectl get events --sort-by=".metadata.creationTimestamp" | grep VPA
4m48s Normal EvictedByVPA pod/hamster-5bccbb88c6-vzwxb Pod was evicted by VPA Updater to apply resource recommendation.
3m48s Normal EvictedByVPA pod/hamster-5bccbb88c6-wrkkc Pod was evicted by VPA Updater to apply resource recommendation.
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]#✍ CA - Cluster Autoscaler
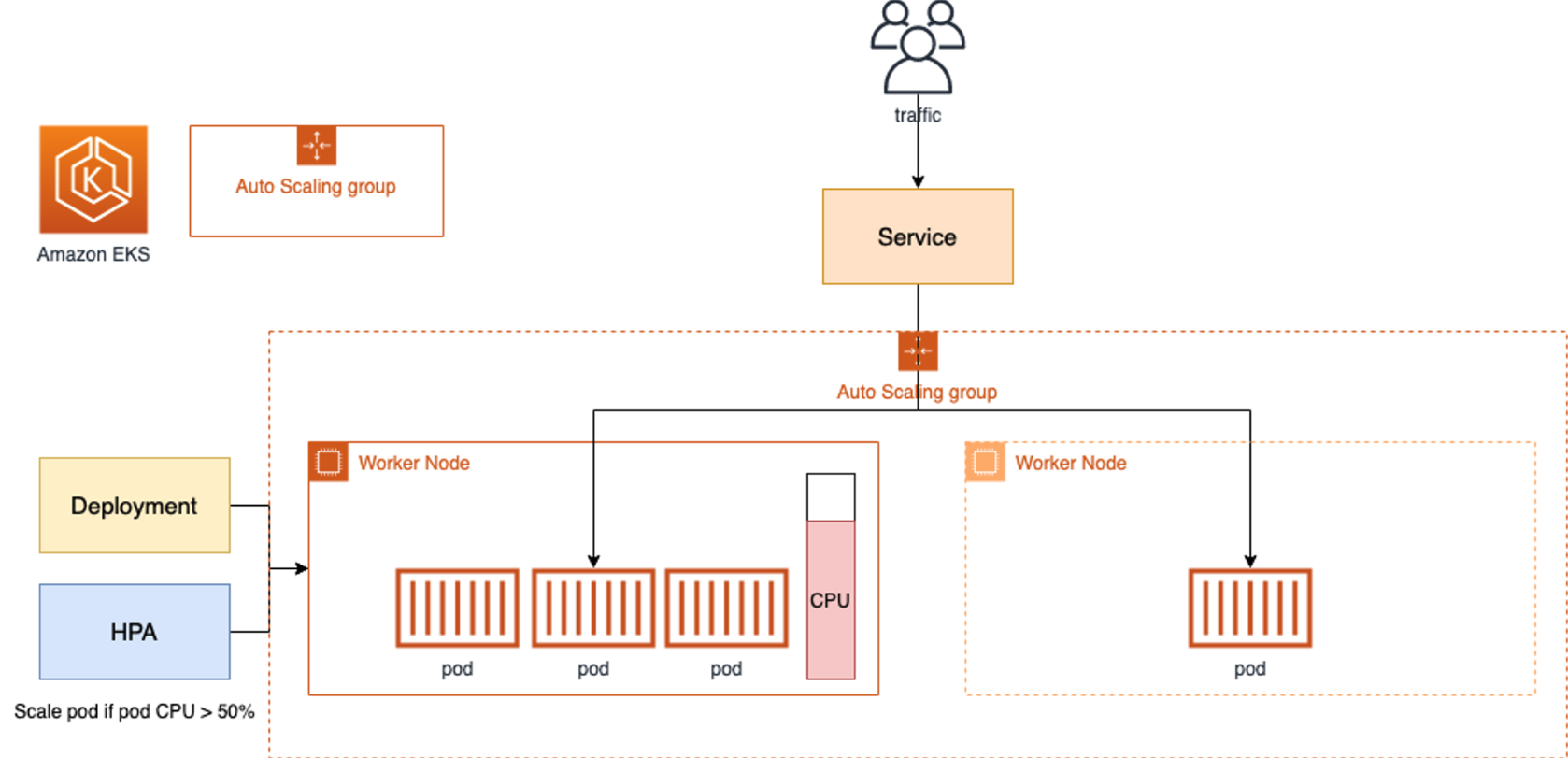
- Cluster Autoscale 동작을 하기 위한 cluster-autoscaler 파드(디플로이먼트)를 배치합니다.
- Cluster Autoscaler(CA)는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다.
- 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용합니다.
설정 전 확인
# EKS 노드에 이미 아래 tag가 들어가 있음
# k8s.io/cluster-autoscaler/enabled : true
# k8s.io/cluster-autoscaler/myeks : owned
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...# 현재 autoscaling(ASG) 정보 확인
# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='클러스터이름']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-44c41109-daa3-134c-df0e-0f28c823cb47 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
# MaxSize 6개로 수정
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 확인
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-c2c41e26-6213-a429-9a58-02374389d5c3 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
# 배포 : Deploy the Cluster Autoscaler (CA)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
# 확인
kubectl get pod -n kube-system | grep cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]# kubectl get pod -n kube-system | grep cluster-autoscaler
cluster-autoscaler-74785c8d45-pxsb4 1/1 Running 0 17s
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]# kubectl describe deployments.apps -n kube-system cluster-autoscaler
Name: cluster-autoscaler
Namespace: kube-system
CreationTimestamp: Sat, 27 May 2023 22:08:03 +0900
Labels: app=cluster-autoscaler
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=cluster-autoscaler
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=cluster-autoscaler
Annotations: prometheus.io/port: 8085
prometheus.io/scrape: true
Service Account: cluster-autoscaler
Containers:
cluster-autoscaler:
Image: registry.k8s.io/autoscaling/cluster-autoscaler:v1.26.2
Port: <none>
Host Port: <none>
Command:
./cluster-autoscaler
--v=4
--stderrthreshold=info
--cloud-provider=aws
--skip-nodes-with-local-storage=false
--expander=least-waste
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
Limits:
cpu: 100m
memory: 600Mi
Requests:
cpu: 100m
memory: 600Mi
Environment: <none>
Mounts:
/etc/ssl/certs/ca-certificates.crt from ssl-certs (ro)
Volumes:
ssl-certs:
Type: HostPath (bare host directory volume)
Path: /etc/ssl/certs/ca-bundle.crt
HostPathType:
Priority Class Name: system-cluster-critical
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: cluster-autoscaler-74785c8d45 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 27s deployment-controller Scaled up replica set cluster-autoscaler-74785c8d45 to 1
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 vertical-pod-autoscaler]#
SCALE A CLUSTER WITH Cluster Autoscaler(CA)
# 모니터링
kubectl get nodes -w
while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
# Deploy a Sample App
# We will deploy an sample nginx application as a ReplicaSet of 1 Pod
cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
# Scale our ReplicaSet
# Let’s scale out the replicaset to 15
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# 확인
kubectl get pods -l app=nginx -o wide --watch
kubectl -n kube-system logs -f deployment/cluster-autoscaler
# 노드 자동 증가 확인
kubectl get nodes
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
./eks-node-viewer
42 pods (0 pending 42 running 42 bound)
ip-192-168-3-196.ap-northeast-2.compute.internal cpu ███████████████████████████████████ 100% (10 pods) t3.medium/$0.0520 On-Demand
ip-192-168-1-91.ap-northeast-2.compute.internal cpu ███████████████████████████████░░░░ 89% (9 pods) t3.medium/$0.0520 On-Demand
ip-192-168-2-185.ap-northeast-2.compute.internal cpu █████████████████████████████████░░ 95% (11 pods) t3.medium/$0.0520 On-Demand
ip-192-168-2-87.ap-northeast-2.compute.internal cpu █████████████████████████████░░░░░░ 84% (6 pods) t3.medium/$0.0520 On-Demand
ip-192-168-3-15.ap-northeast-2.compute.internal cpu █████████████████████████████░░░░░░ 84% (6 pods) t3.medium/$0.0520 On-Demand
# 디플로이먼트 삭제
kubectl delete -f nginx.yaml && date
# 노드 갯수 축소 : 기본은 10분 후 scale down 됨, 물론 아래 flag 로 시간 수정 가능 >> 그러니 디플로이먼트 삭제 후 10분 기다리고 나서 보자!
# By default, cluster autoscaler will wait 10 minutes between scale down operations,
# you can adjust this using the --scale-down-delay-after-add, --scale-down-delay-after-delete,
# and --scale-down-delay-after-failure flag.
# E.g. --scale-down-delay-after-add=5m to decrease the scale down delay to 5 minutes after a node has been added.
# 터미널1
watch -d kubectl get node(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# aws autoscaling describe-auto-scaling-groups \
> --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
> --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-1ac42e7b-de3e-d0aa-0646-be445dbd923a | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# ./eks-node-viewer
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-1ac42e7b-de3e-d0aa-0646-be445dbd923a | 3 | 6 | 5 |
+------------------------------------------------+----+----+----+
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]#
# 디플로이먼트 삭제
kubectl delete -f nginx.yaml && date
# 노드 갯수 축소 : 기본은 10분 후 scale down 됨, 물론 아래 flag 로 시간 수정 가능 >> 그러니 디플로이먼트 삭제 후 10분 기다리고 나서 보자!
# By default, cluster autoscaler will wait 10 minutes between scale down operations,
# you can adjust this using the --scale-down-delay-after-add, --scale-down-delay-after-delete,
# and --scale-down-delay-after-failure flag.
# E.g. --scale-down-delay-after-add=5m to decrease the scale down delay to 5 minutes after a node has been added.
# 터미널1
watch -d kubectl get node
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 3
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 bin]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-1ac42e7b-de3e-d0aa-0646-be445dbd923a | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+- CA 문제점 : 하나의 자원에 대해 두군데 (AWS ASG vs AWS EKS)에서 각자의 방식으로 관리 ⇒ 관리 정보가 서로 동기화되지 않아 다양한 문제 발생
-
CA 문제점 : ASG에만 의존하고 노드 생성/삭제 등에 직접 관여 안함
-
EKS에서 노드를 삭제 해도 인스턴스는 삭제 안됨
-
노드 축소 될 때 특정 노드가 축소 되도록 하기 매우 어려움 : pod이 적은 노드 먼저 축소, 이미 드레인 된 노드 먼저 축소
-
특정 노드를 삭제 하면서 동시에 노드 개수를 줄이기 어려움 : 줄일때 삭제 정책 옵션이 다양하지 않음
- 정책 미지원 시 삭제 방식(예시) : 100대 중 미삭제 EC2 보호 설정 후 삭제 될 ec2의 파드를 이주 후 scaling 조절로 삭제 후 원복
-
특정 노드를 삭제하면서 동시에 노드 개수를 줄이기 어려움
-
폴링 방식이기에 너무 자주 확장 여유를 확인 하면 API 제한에 도달할 수 있음
-
스케일링 속도가 매우 느림
-
Cluster Autoscaler 는 쿠버네티스 클러스터 자체의 오토 스케일링을 의미하며, 수요에 따라 워커 노드를 자동으로 추가하는 기능
-
언뜻 보기에 클러스터 전체나 각 노드의 부하 평균이 높아졌을 때 확장으로 보인다 → 함정! 🚧
-
Pending 상태의 파드가 생기는 타이밍에 처음으로 Cluster Autoscaler 이 동작한다
- 즉, Request 와 Limits 를 적절하게 설정하지 않은 상태에서는 실제 노드의 부하 평균이 낮은 상황에서도 스케일 아웃이 되거나,
부하 평균이 높은 상황임에도 스케일 아웃이 되지 않는다!
- 즉, Request 와 Limits 를 적절하게 설정하지 않은 상태에서는 실제 노드의 부하 평균이 낮은 상황에서도 스케일 아웃이 되거나,
-
기본적으로 리소스에 의한 스케줄링은 Requests(최소)를 기준으로 이루어진다. 다시 말해 Requests 를 초과하여 할당한 경우에는 최소 리소스 요청만으로 리소스가 꽉 차 버려서 신규 노드를 추가해야만 한다. 이때 실제 컨테이너 프로세스가 사용하는 리소스 사용량은 고려되지 않는다.
-
반대로 Request 를 낮게 설정한 상태에서 Limit 차이가 나는 상황을 생각해보자. 각 컨테이너는 Limits 로 할당된 리소스를 최대로 사용한다. 그래서 실제 리소스 사용량이 높아졌더라도 Requests 합계로 보면 아직 스케줄링이 가능하기 때문에 클러스터가 스케일 아웃하지 않는 상황이 발생한다.
-
여기서는 CPU 리소스 할당을 예로 설명했지만 메모리의 경우도 마찬가지다.
-
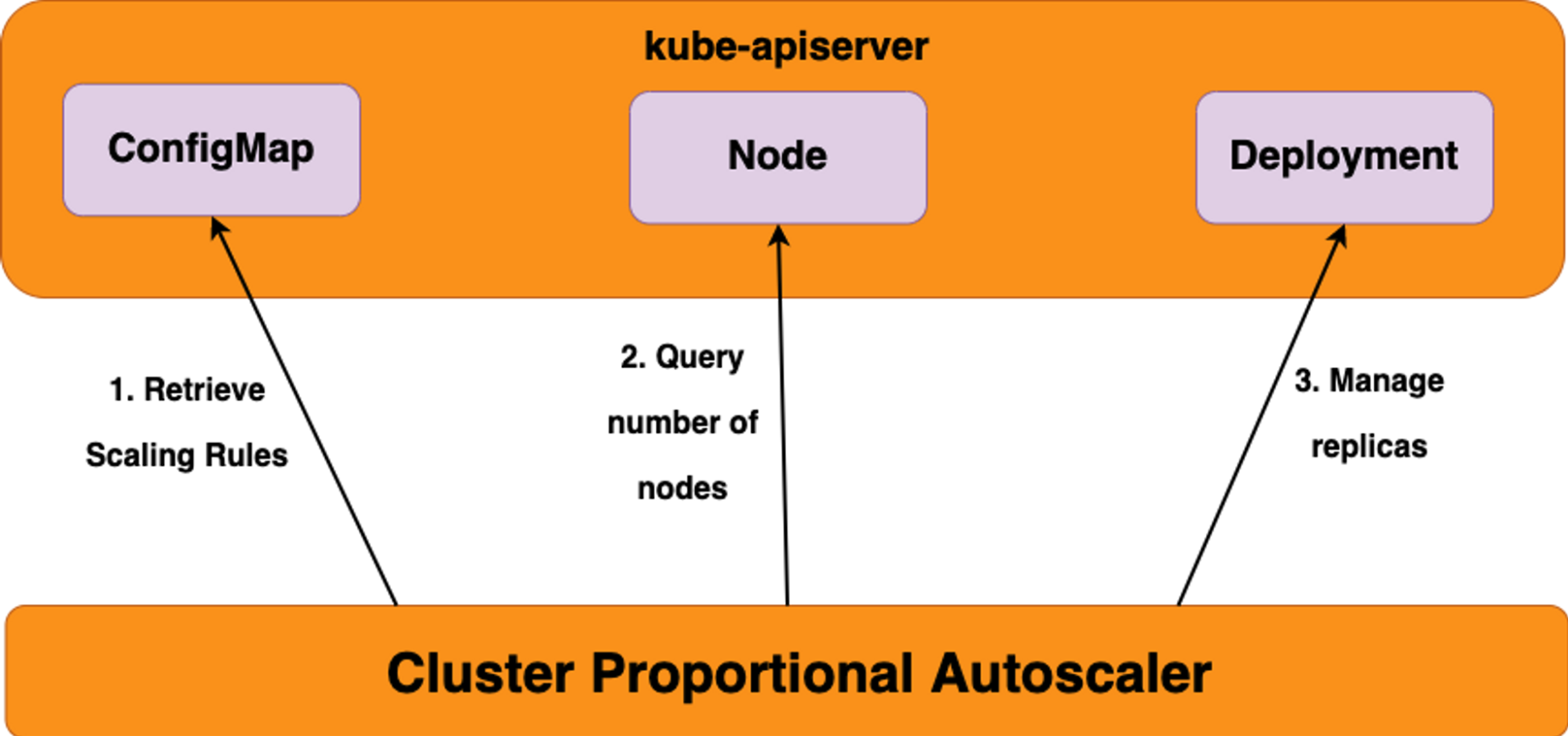
✍ CPA - Cluster Proportional Autoscaler
노드 수 증가에 비례하여 성능 처리가 필요한 애플리케이션(컨테이너/파드)를 수평으로 자동 확장
ex. coredns - Github Workshop
https://github.com/kubernetes-sigs/cluster-proportional-autoscaler
#
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml
# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
# 모니터링
watch -d kubectl get pod
# helm 업그레이드
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5개로 증가
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
# 노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-1ac42e7b-de3e-d0aa-0646-be445dbd923a | 5 | 5 | 5 |
+------------------------------------------------+----+----+----+
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#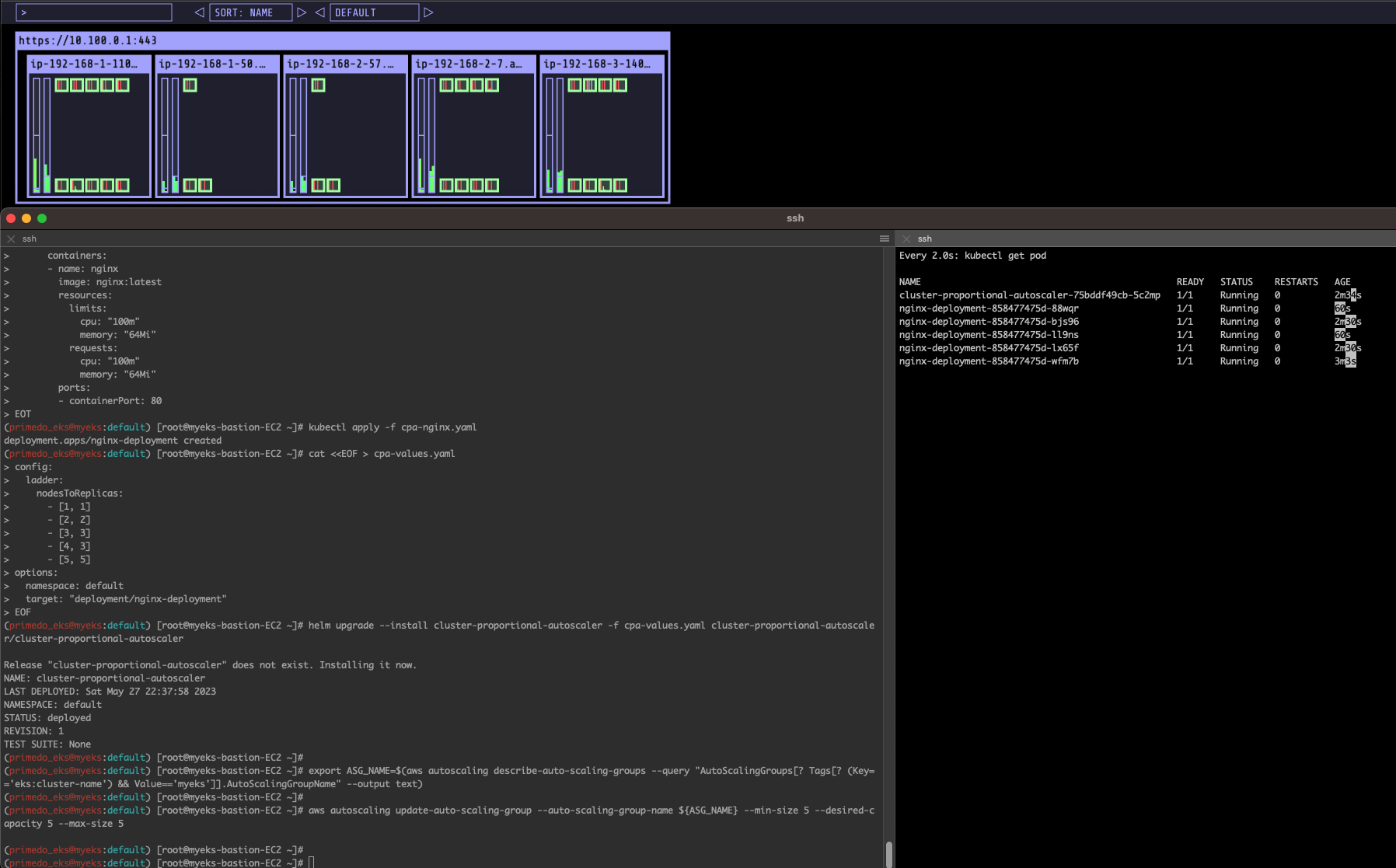
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-1ac42e7b-de3e-d0aa-0646-be445dbd923a | 4 | 4 | 4 |
+------------------------------------------------+----+----+----+
(primedo_eks@myeks:default) [root@myeks-bastion-EC2 ~]#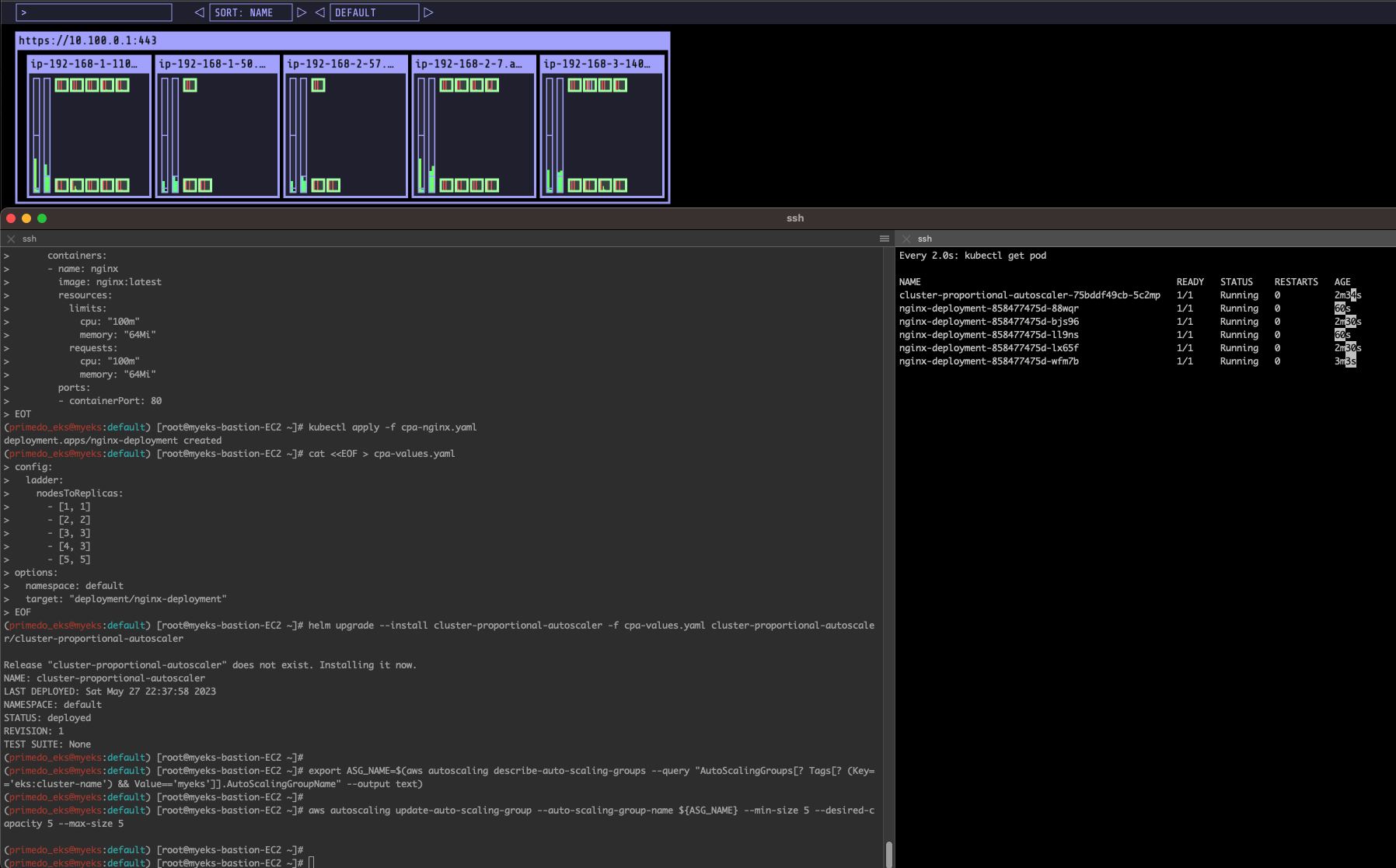
✍ Karpenter : K8S Native AutoScaler & Fargate
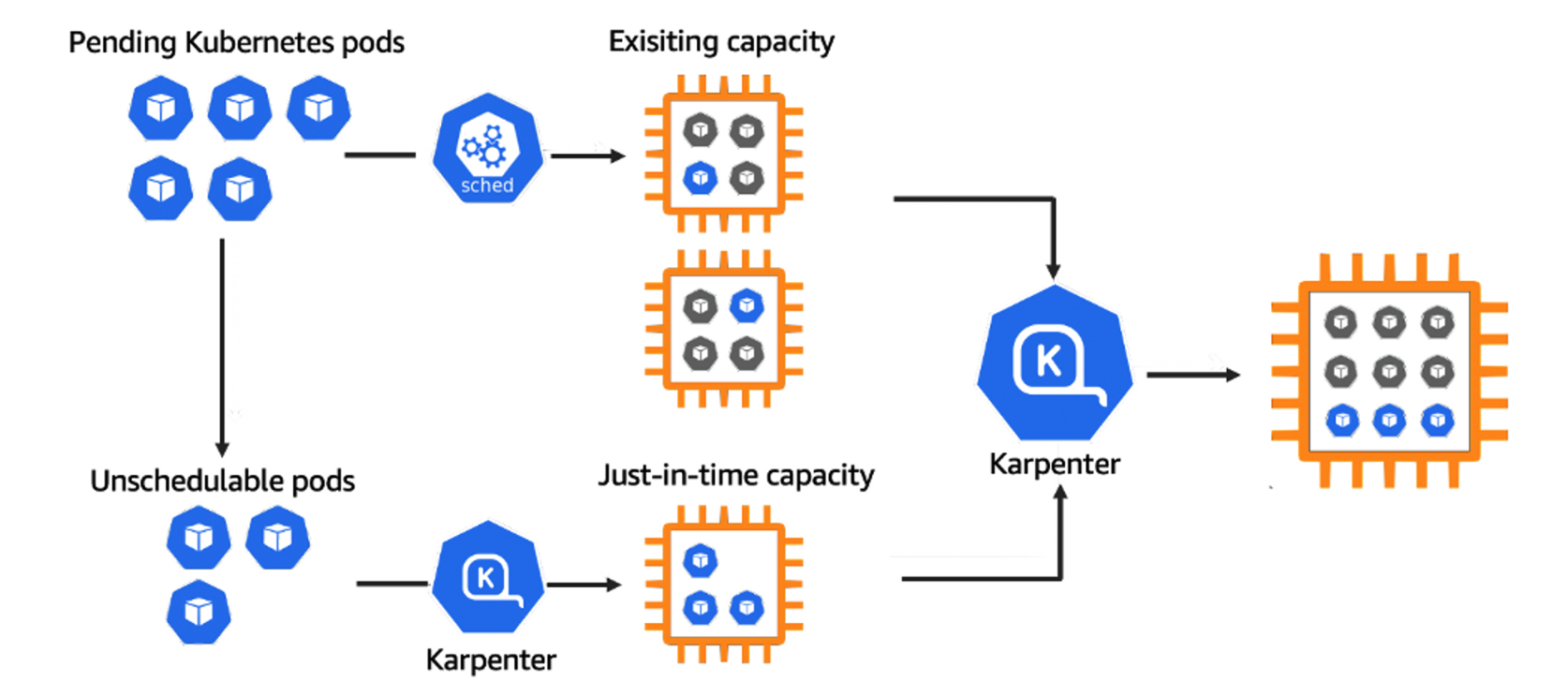
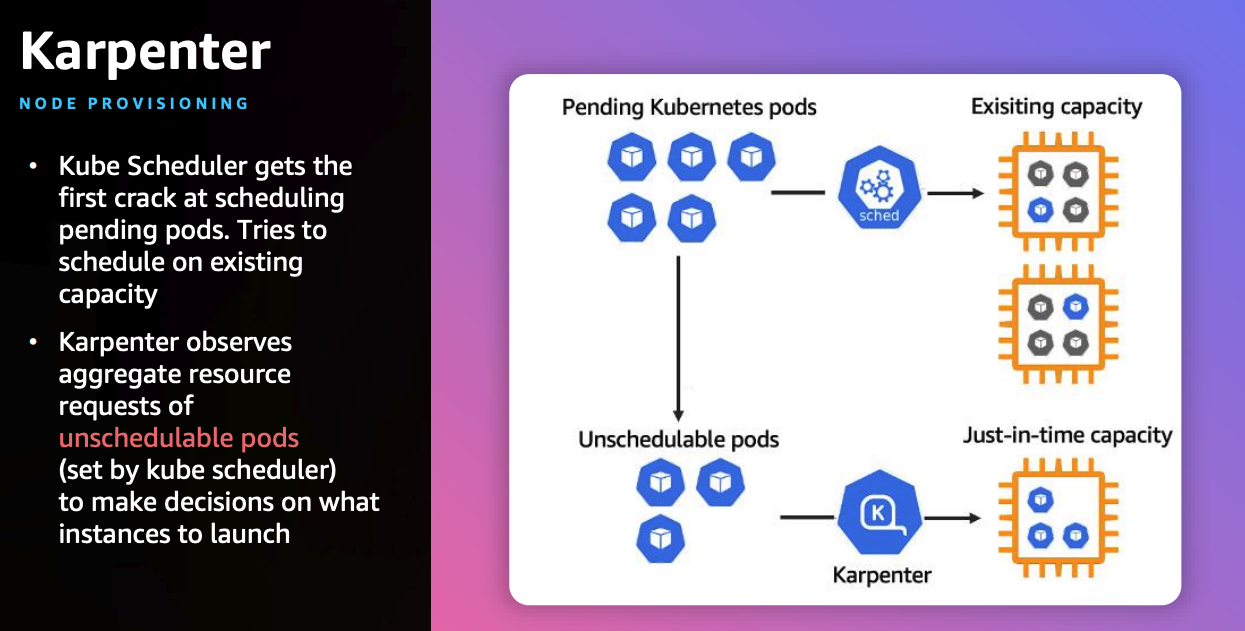
- 작동 방식
- 모니터링 → (스케줄링 안된 Pod 발견) → 스펙 평가 → 생성 ⇒ Provisioning
- 모니터링 → (비어있는 노드 발견) → 제거 ⇒ Deprovisioning
- Provisioner CRD : 시작 템플릿이 필요 없습니다! ← 시작 템플릿의 대부분의 설정 부분을 대신함
- 필수 : 보안그룹, 서브넷
- 리소스 찾는 방식 : 태그 기반 자동, 리소스 ID 직접 명시
- 인스턴스 타입은 가드레일 방식으로 선언 가능! : 스팟(우선) vs 온디멘드, 다양한 인스턴스 type 가능
- Pod에 적합한 인스턴스 중 가장 저렴한 인스턴스로 증설 됩니다
- PV를 위해 단일 서브넷에 노드 그룹을 만들 필요가 없습니다 → 자동으로 PV가 존재하는 서브넷에 노드를 만듭니다
- 사용 안하는 노드를 자동으로 정리, 일정 기간이 지나면 노드를 자동으로 만료 시킬 수 있음
- ttlSecondsAfterEmpty : 노드에 데몬셋을 제외한 모든 Pod이 존재하지 않을 경우 해당 값 이후에 자동으로 정리됨
- ttlSecondsUntilExpired : 설정한 기간이 지난 노드는 자동으로 cordon, drain 처리가 되어 노드를 정리함
- 이때 노드가 주기적으로 정리되면 자연스럽게 기존에 여유가 있는 노드에 재배치 되기 때문에 좀 더 효율적으로 리소스 사용 가능 + 최신 AMI 사용 환경에 도움
- 노드가 제때 drain 되지 않는다면 비효율적으로 운영 될 수 있습니다
- 노드를 줄여도 다른 노드에 충분한 여유가 있다면 자동으로 정리해줌!
- 큰 노드 하나가 작은 노드 여러개 보다 비용이 저렴하다면 자동으로 합쳐줌! → 기존에 확장 속도가 느려서 보수적으로 운영 하던 부분을 해소
- 오버 프로비저닝 필요 : 카펜터를 쓰더라도 EC2가 뜨고 데몬셋이 모두 설치되는데 최소 1~2분이 소요 → 깡통 증설용 Pod를 만들어서 여유 공간을 강제로 확보!
- 오버 프로비저닝 Pod x KEDA : 대규모 증설이 예상 되는 경우 미리 준비
실습환경 배포
배포 전 사전 확인 & eks-node-viewer 설치
# IP 주소 확인 : 172.30.0.0/16 VPC 대역에서 172.30.1.0/24 대역을 사용 중
ip -br -c addr
# EKS Node Viewer 설치 : 현재 ec2 spec에서는 설치에 다소 시간이 소요됨 = 2분 이상
go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest
# [터미널1] bin 확인 및 사용
tree ~/go/bin
cd ~/go/bin
./eks-node-viewer -h
./eks-node-viewer # EKS 배포 완료 후 실행 하자# 환경변수 정보 확인
export | egrep 'ACCOUNT|AWS_|CLUSTER' | egrep -v 'SECRET|KEY'
# 환경변수 설정
export KARPENTER_VERSION=v0.27.5
export TEMPOUT=$(mktemp)
echo $KARPENTER_VERSION $CLUSTER_NAME $AWS_DEFAULT_REGION $AWS_ACCOUNT_ID $TEMPOUT
# CloudFormation 스택으로 IAM Policy, Role, EC2 Instance Profile 생성 : 3분 정도 소요
curl -fsSL https://karpenter.sh/"${KARPENTER_VERSION}"/getting-started/getting-started-with-karpenter/cloudformation.yaml > $TEMPOUT \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
# 클러스터 생성 : myeks2 EKS 클러스터 생성 19분 정도 소요
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "1.24"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: karpenter
namespace: karpenter
roleName: ${CLUSTER_NAME}-karpenter
attachPolicyARNs:
- arn:aws:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}
roleOnly: true
iamIdentityMappings:
- arn: "arn:aws:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
iam:
withAddonPolicies:
externalDNS: true
## Optionally run on fargate
# fargateProfiles:
# - name: karpenter
# selectors:
# - namespace: karpenter
EOF
# eks 배포 확인
eksctl get cluster
eksctl get nodegroup --cluster $CLUSTER_NAME
eksctl get iamidentitymapping --cluster $CLUSTER_NAME
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
eksctl get addon --cluster $CLUSTER_NAME
# [터미널1] eks-node-viewer
cd ~/go/bin && ./eks-node-viewer
# k8s 확인
kubectl cluster-info
kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
kubectl get pod -n kube-system -owide
kubectl describe cm -n kube-system aws-auth
...
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::911283464785:role/KarpenterNodeRole-myeks2
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::911283464785:role/eksctl-myeks2-nodegroup-myeks2-ng-NodeInstanceRole-1KDXF4FLKKX1B
username: system:node:{{EC2PrivateDNSName}}
...
# 카펜터 설치를 위한 환경 변수 설정 및 확인
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
echo $CLUSTER_ENDPOINT $KARPENTER_IAM_ROLE_ARN
# EC2 Spot Fleet 사용을 위한 service-linked-role 생성 확인 : 만들어있는것을 확인하는 거라 아래 에러 출력이 정상!
# If the role has already been successfully created, you will see:
# An error occurred (InvalidInput) when calling the CreateServiceLinkedRole operation: Service role name AWSServiceRoleForEC2Spot has been taken in this account, please try a different suffix.
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
# docker logout : Logout of docker to perform an unauthenticated pull against the public ECR
docker logout public.ecr.aws
# karpenter 설치
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} --namespace karpenter --create-namespace \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \
--set settings.aws.clusterName=${CLUSTER_NAME} \
--set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME} \
--set settings.aws.interruptionQueueName=${CLUSTER_NAME} \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
# 확인
kubectl get-all -n karpenter
kubectl get all -n karpenter
kubectl get cm -n karpenter karpenter-global-settings -o jsonpath={.data} | jq
kubectl get crd | grep karpenter옵션 : ExternalDNS, kube-ops-view
# ExternalDNS
MyDomain=<자신의 도메인>
echo "export MyDomain=<자신의 도메인>" >> /etc/profile
MyDomain=gasida.link
echo "export MyDomain=gasida.link" >> /etc/profile
MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text)
echo $MyDomain, $MyDnzHostedZoneId
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml
MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst < externaldns.yaml | kubectl apply -f -
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
kubectl patch svc -n kube-system kube-ops-view -p '{"spec":{"type":"LoadBalancer"}}'
kubectl annotate service kube-ops-view -n kube-system "external-dns.alpha.kubernetes.io/hostname=kubeopsview.$MyDomain"
echo -e "Kube Ops View URL = http://kubeopsview.$MyDomain:8080/#scale=1.5"(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# eksctl get cluster
NAME REGION EKSCTL CREATED
myeks2 ap-northeast-2 True
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# eksctl get nodegroup --cluster $CLUSTER_NAME
CLUSTER NODEGROUP STATUS CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID ASG NAME TYPE
myeks2 myeks2-ng ACTIVE 2023-05-27T08:59:44Z 1 10 2 m5.large AL2_x86_64 eks-myeks2-ng-a6c42e37-ab0f-e865-b17d-f2fca2533e98 managed
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# eksctl get iamidentitymapping --cluster $CLUSTER_NAME
ARN USERNAME GROUPS ACCOUNT
arn:aws:iam::070271542073:role/KarpenterNodeRole-myeks2 system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::070271542073:role/eksctl-myeks2-nodegroup-myeks2-ng-NodeInstanceRole-VGV2T0F9XJC1 system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# eksctl get iamserviceaccount --cluster $CLUSTER_NAME
NAMESPACE NAME ROLE ARN
karpenter karpenter arn:aws:iam::070271542073:role/myeks2-karpenter
kube-system aws-node arn:aws:iam::070271542073:role/eksctl-myeks2-addon-iamserviceaccount-kube-s-Role1-UWTQUJYZDBME
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE CAPACITYTYPE ZONE
ip-192-168-3-74.ap-northeast-2.compute.internal Ready <none> 5m59s v1.24.13-eks-0a21954 m5.large ON_DEMAND ap-northeast-2d
ip-192-168-52-210.ap-northeast-2.compute.internal Ready <none> 5m58s v1.24.13-eks-0a21954 m5.large ON_DEMAND ap-northeast-2a
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get pod -n kube-system -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aws-node-2gpp4 1/1 Running 0 6m23s 192.168.3.74 ip-192-168-3-74.ap-northeast-2.compute.internal <none> <none>
aws-node-5b8kp 1/1 Running 0 6m22s 192.168.52.210 ip-192-168-52-210.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-2db6j 1/1 Running 0 13m 192.168.16.105 ip-192-168-3-74.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-qmfdk 1/1 Running 0 13m 192.168.17.183 ip-192-168-3-74.ap-northeast-2.compute.internal <none> <none>
kube-proxy-72vg8 1/1 Running 0 6m23s 192.168.3.74 ip-192-168-3-74.ap-northeast-2.compute.internal <none> <none>
kube-proxy-mdbd8 1/1 Running 0 6m22s 192.168.52.210 ip-192-168-52-210.ap-northeast-2.compute.internal <none> <none>
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# echo $CLUSTER_ENDPOINT $KARPENTER_IAM_ROLE_ARN
https://D48F893BA948C023CBBF5C75446C8BDA.gr7.ap-northeast-2.eks.amazonaws.com arn:aws:iam::070271542073:role/myeks2-karpenter
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get-all -n karpenter
^[[ONAME NAMESPACE AGE
configmap/config-logging karpenter 23s
configmap/karpenter-global-settings karpenter 23s
configmap/kube-root-ca.crt karpenter 23s
endpoints/karpenter karpenter 23s
pod/karpenter-6c6bdb7766-cnbz6 karpenter 23s
pod/karpenter-6c6bdb7766-zhrpm karpenter 23s
secret/karpenter-cert karpenter 23s
secret/sh.helm.release.v1.karpenter.v1 karpenter 23s
serviceaccount/default karpenter 23s
serviceaccount/karpenter karpenter 23s
service/karpenter karpenter 23s
deployment.apps/karpenter karpenter 23s
replicaset.apps/karpenter-6c6bdb7766 karpenter 23s
lease.coordination.k8s.io/karpenter-leader-election karpenter 15s
endpointslice.discovery.k8s.io/karpenter-m44td karpenter 23s
poddisruptionbudget.policy/karpenter karpenter 23s
rolebinding.rbac.authorization.k8s.io/karpenter karpenter 23s
role.rbac.authorization.k8s.io/karpenter karpenter 23s
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get all -n karpenter
NAME READY STATUS RESTARTS AGE
pod/karpenter-6c6bdb7766-cnbz6 1/1 Running 0 58s
pod/karpenter-6c6bdb7766-zhrpm 1/1 Running 0 58s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/karpenter ClusterIP 10.100.3.255 <none> 8080/TCP,443/TCP 58s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/karpenter 2/2 2 2 58s
NAME DESIRED CURRENT READY AGE
replicaset.apps/karpenter-6c6bdb7766 2 2 2 58s
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get crd | grep karpenter
awsnodetemplates.karpenter.k8s.aws 2023-05-27T09:10:41Z
provisioners.karpenter.sh 2023-05-27T09:10:41Z
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get pod -n kube-system -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aws-node-gfwgx 1/1 Running 0 13m 192.168.59.7 ip-192-168-59-7.ap-northeast-2.compute.internal <none> <none>
aws-node-rjvn4 1/1 Running 0 13m 192.168.8.171 ip-192-168-8-171.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-k7h6g 1/1 Running 0 20m 192.168.42.139 ip-192-168-59-7.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-lr597 1/1 Running 0 20m 192.168.63.81 ip-192-168-59-7.ap-northeast-2.compute.internal <none> <none>
kube-proxy-lgm67 1/1 Running 0 13m 192.168.8.171 ip-192-168-8-171.ap-northeast-2.compute.internal <none> <none>
kube-proxy-pqdd4 1/1 Running 0 13m 192.168.59.7 ip-192-168-59-7.ap-northeast-2.compute.internal <none> <none>
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl describe cm -n kube-system aws-auth
Name: aws-auth
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::070271542073:role/KarpenterNodeRole-myeks2
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::070271542073:role/eksctl-myeks2-nodegroup-myeks2-ng-NodeInstanceRole-O1PPK4JZ8XRM
username: system:node:{{EC2PrivateDNSName}}
mapUsers:
----
[]
BinaryData
====
Events: <none>
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get crd | grep karpenter
awsnodetemplates.karpenter.k8s.aws 2023-05-27T15:03:59Z
provisioners.karpenter.sh 2023-05-27T15:03:59Z
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get awsnodetemplates,provisioners
NAME AGE
awsnodetemplate.karpenter.k8s.aws/default 12s
NAME AGE
provisioner.karpenter.sh/default 12s
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
First Use
# pause 파드 1개에 CPU 1개 최소 보장 할당
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
EOF
kubectl scale deployment inflate --replicas 5
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
# 스팟 인스턴스 확인!
aws ec2 describe-spot-instance-requests --filters "Name=state,Values=active" --output table
kubectl get node -l karpenter.sh/capacity-type=spot -o jsonpath='{.items[0].metadata.labels}' | jq
kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type,node.kubernetes.io/instance-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE CAPACITY-TYPE INSTANCE-TYPE
ip-192-168-165-220.ap-northeast-2.compute.internal Ready <none> 2m37s v1.24.13-eks-0a21954 spot c5a.2xlarge
ip-192-168-57-91.ap-northeast-2.compute.internal Ready <none> 13m v1.24.13-eks-0a21954 ON_DEMAND m5.large
ip-192-168-75-253.ap-northeast-2.compute.internal Ready <none> 13m v1.24.13-eks-0a21954 ON_DEMAND m5.largeprimedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# cat <<EOF | kubectl apply -f -
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: inflate
> spec:
> replicas: 0
> selector:
> matchLabels:
> app: inflate
> template:
> metadata:
> labels:
> app: inflate
> spec:
> terminationGracePeriodSeconds: 0
> containers:
> - name: inflate
> image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
> resources:
> requests:
> cpu: 1
> EOF
deployment.apps/inflate created
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl scale deployment inflate --replicas 5
deployment.apps/inflate scaled
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# aws ec2 describe-spot-instance-requests --filters "Name=state,Values=active" --output table
------------------------------------------------------------------------------------------------------
| DescribeSpotInstanceRequests |
+----------------------------------------------------------------------------------------------------+
|| SpotInstanceRequests ||
|+--------------------------------------------------+-----------------------------------------------+|
|| CreateTime | 2023-05-27T15:17:27+00:00 ||
|| InstanceId | i-08b05ec8d94540a06 ||
|| InstanceInterruptionBehavior | terminate ||
|| LaunchedAvailabilityZone | ap-northeast-2c ||
|| ProductDescription | Linux/UNIX ||
|| SpotInstanceRequestId | sir-21iyk7xq ||
|| SpotPrice | 0.454000 ||
|| State | active ||
|| Type | one-time ||
|+--------------------------------------------------+-----------------------------------------------+|
||| LaunchSpecification |||
||+------------------------------------+-----------------------------------------------------------+||
||| ImageId | ami-0fa3b31d56b9a36b2 |||
||| InstanceType | c4.2xlarge |||
||+------------------------------------+-----------------------------------------------------------+||
|||| BlockDeviceMappings ||||
|||+------------------------------------------------+---------------------------------------------+|||
|||| DeviceName | /dev/xvda ||||
|||+------------------------------------------------+---------------------------------------------+|||
||||| Ebs |||||
||||+--------------------------------------------------------------------+-----------------------+||||
||||| DeleteOnTermination | True |||||
||||| Encrypted | True |||||
||||| VolumeSize | 20 |||||
||||| VolumeType | gp3 |||||
||||+--------------------------------------------------------------------+-----------------------+||||
|||| IamInstanceProfile ||||
|||+-------+--------------------------------------------------------------------------------------+|||
|||| Arn | arn:aws:iam::070271542073:instance-profile/KarpenterNodeInstanceProfile-myeks2 ||||
|||| Name | KarpenterNodeInstanceProfile-myeks2 ||||
|||+-------+--------------------------------------------------------------------------------------+|||
|||| Monitoring ||||
|||+---------------------------------------------------+------------------------------------------+|||
|||| Enabled | False ||||
|||+---------------------------------------------------+------------------------------------------+|||
|||| NetworkInterfaces ||||
|||+-----------------------------------------+----------------------------------------------------+|||
|||| DeleteOnTermination | True ||||
|||| DeviceIndex | 0 ||||
|||| SubnetId | subnet-007f5b3776173dabc ||||
|||+-----------------------------------------+----------------------------------------------------+|||
|||| Placement ||||
|||+-----------------------------------------------+----------------------------------------------+|||
|||| AvailabilityZone | ap-northeast-2c ||||
|||| Tenancy | default ||||
|||+-----------------------------------------------+----------------------------------------------+|||
|||| SecurityGroups ||||
|||+-----------------------+----------------------------------------------------------------------+|||
|||| GroupId | GroupName ||||
|||+-----------------------+----------------------------------------------------------------------+|||
|||| sg-04b80c789e3210955 | eksctl-myeks2-cluster-ClusterSharedNodeSecurityGroup-1JHHW9S6W53C4 ||||
|||| sg-03e66325fb472bd0b | eksctl-myeks2-cluster-ControlPlaneSecurityGroup-11JXODRY5KAC ||||
|||+-----------------------+----------------------------------------------------------------------+|||
||| Status |||
||+--------------------------+---------------------------------------------------------------------+||
||| Code | fulfilled |||
||| Message | Your Spot request is fulfilled. |||
||| UpdateTime | 2023-05-27T15:24:33+00:00 |||
||+--------------------------+---------------------------------------------------------------------+||
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node -l karpenter.sh/capacity-type=spot -o jsonpath='{.items[0].metadata.labels}' | jq
{
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "c4.2xlarge",
"beta.kubernetes.io/os": "linux",
"failure-domain.beta.kubernetes.io/region": "ap-northeast-2",
"failure-domain.beta.kubernetes.io/zone": "ap-northeast-2c",
"k8s.io/cloud-provider-aws": "35a3405a9b5c02025fe6ff647a94190b",
"karpenter.k8s.aws/instance-ami-id": "ami-0fa3b31d56b9a36b2",
"karpenter.k8s.aws/instance-category": "c",
"karpenter.k8s.aws/instance-cpu": "8",
"karpenter.k8s.aws/instance-encryption-in-transit-supported": "false",
"karpenter.k8s.aws/instance-family": "c4",
"karpenter.k8s.aws/instance-generation": "4",
"karpenter.k8s.aws/instance-hypervisor": "xen",
"karpenter.k8s.aws/instance-memory": "15360",
"karpenter.k8s.aws/instance-network-bandwidth": "2500",
"karpenter.k8s.aws/instance-pods": "58",
"karpenter.k8s.aws/instance-size": "2xlarge",
"karpenter.sh/capacity-type": "spot",
"karpenter.sh/initialized": "true",
"karpenter.sh/provisioner-name": "default",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "ip-192-168-123-105.ap-northeast-2.compute.internal",
"kubernetes.io/os": "linux",
"node.kubernetes.io/instance-type": "c4.2xlarge",
"topology.kubernetes.io/region": "ap-northeast-2",
"topology.kubernetes.io/zone": "ap-northeast-2c"
}
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node -l karpenter.sh/capacity-type=spot -o jsonpath='{.items[0].metadata.labels}' | jq
{
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "c4.2xlarge",
"beta.kubernetes.io/os": "linux",
"failure-domain.beta.kubernetes.io/region": "ap-northeast-2",
"failure-domain.beta.kubernetes.io/zone": "ap-northeast-2c",
"k8s.io/cloud-provider-aws": "35a3405a9b5c02025fe6ff647a94190b",
"karpenter.k8s.aws/instance-ami-id": "ami-0fa3b31d56b9a36b2",
"karpenter.k8s.aws/instance-category": "c",
"karpenter.k8s.aws/instance-cpu": "8",
"karpenter.k8s.aws/instance-encryption-in-transit-supported": "false",
"karpenter.k8s.aws/instance-family": "c4",
"karpenter.k8s.aws/instance-generation": "4",
"karpenter.k8s.aws/instance-hypervisor": "xen",
"karpenter.k8s.aws/instance-memory": "15360",
"karpenter.k8s.aws/instance-network-bandwidth": "2500",
"karpenter.k8s.aws/instance-pods": "58",
"karpenter.k8s.aws/instance-size": "2xlarge",
"karpenter.sh/capacity-type": "spot",
"karpenter.sh/initialized": "true",
"karpenter.sh/provisioner-name": "default",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "ip-192-168-123-105.ap-northeast-2.compute.internal",
"kubernetes.io/os": "linux",
"node.kubernetes.io/instance-type": "c4.2xlarge",
"topology.kubernetes.io/region": "ap-northeast-2",
"topology.kubernetes.io/zone": "ap-northeast-2c"
}
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
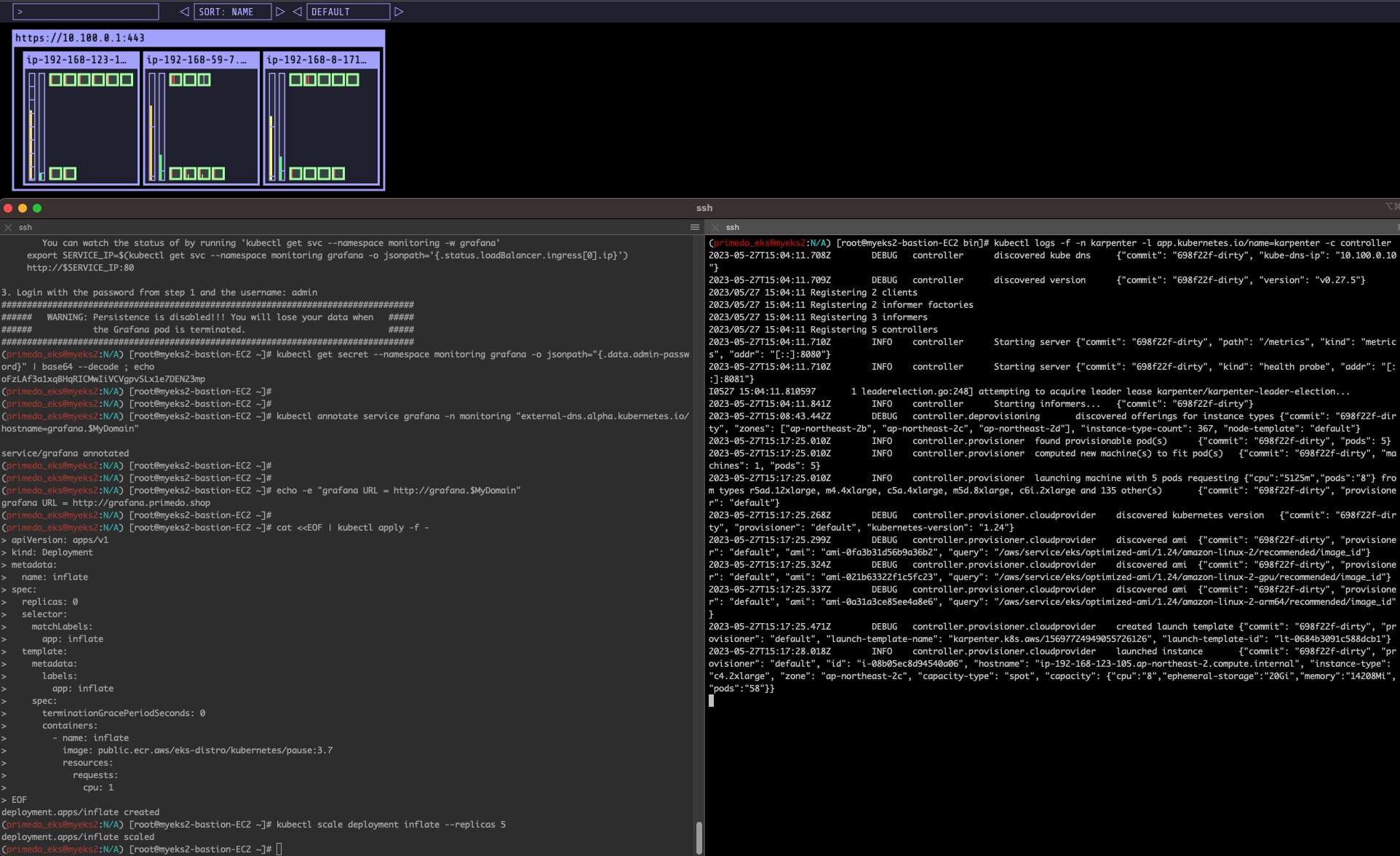
Scale down deployment : ttlSecondsAfterEmpty 30초
# Now, delete the deployment. After 30 seconds (ttlSecondsAfterEmpty), Karpenter should terminate the now empty nodes.
kubectl delete deployment inflate
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller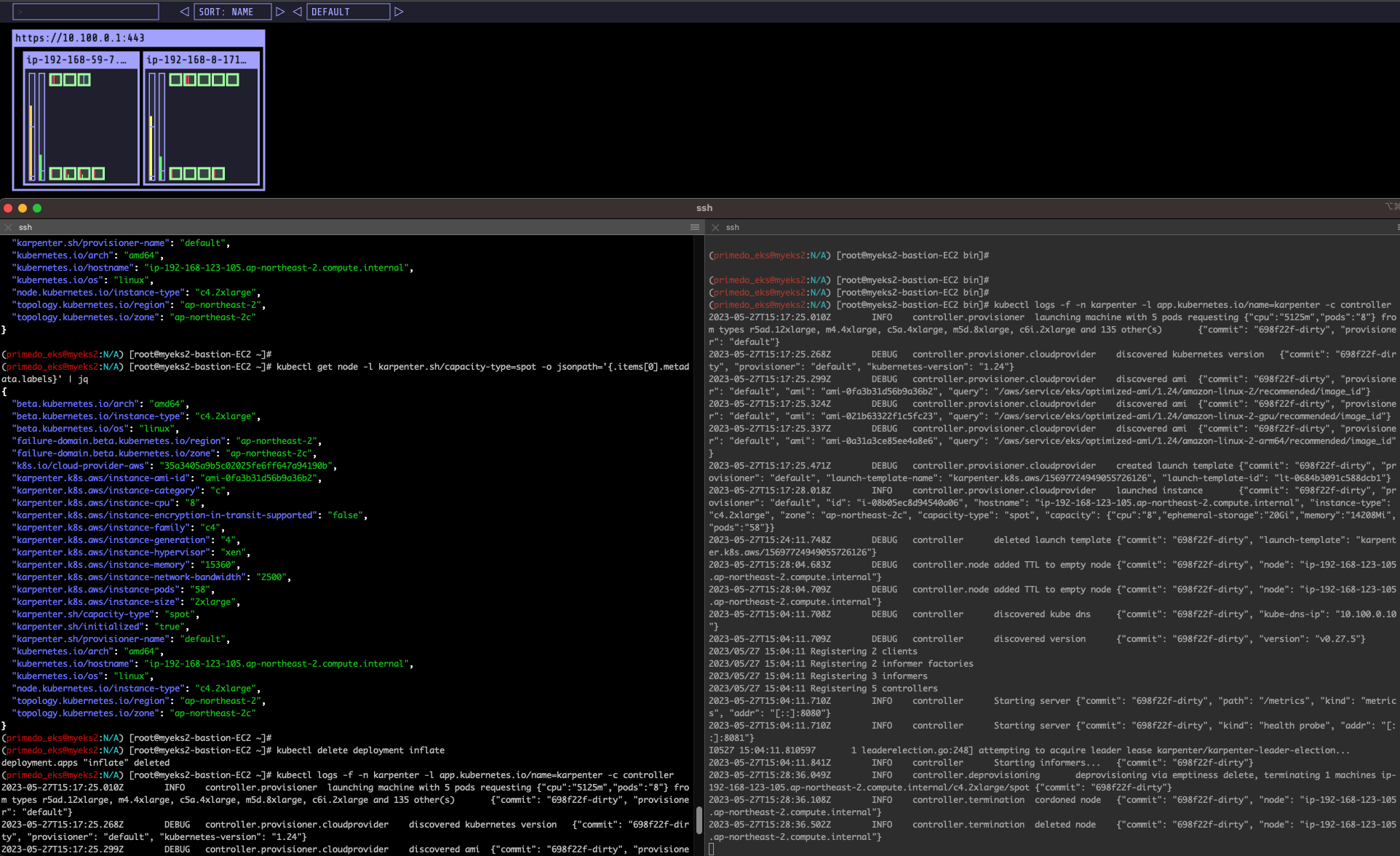
Consolidation
- Docs 링크 Work
https://aws.amazon.com/ko/blogs/containers/optimizing-your-kubernetes-compute-costs-with-karpenter-consolidation/
#
kubectl delete provisioners default
cat <<EOF | kubectl apply -f -
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
consolidation:
enabled: true
labels:
type: karpenter
limits:
resources:
cpu: 1000
memory: 1000Gi
providerRef:
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- on-demand
- key: node.kubernetes.io/instance-type
operator: In
values:
- c5.large
- m5.large
- m5.xlarge
EOF
#
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
EOF
kubectl scale deployment inflate --replicas 12
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
# 인스턴스 확인
# This changes the total memory request for this deployment to around 12Gi,
# which when adjusted to account for the roughly 600Mi reserved for the kubelet on each node means that this will fit on 2 instances of type m5.large:
kubectl get node -l type=karpenter
kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
# Next, scale the number of replicas back down to 5:
kubectl scale deployment inflate --replicas 5
# The output will show Karpenter identifying specific nodes to cordon, drain and then terminate:
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-17T07:02:00.768Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-14-81.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "d7e22b1-dirty"}
2023-05-17T07:02:00.803Z INFO controller.termination cordoned node {"commit": "d7e22b1-dirty", "node": "ip-192-168-14-81.ap-northeast-2.compute.internal"}
2023-05-17T07:02:01.320Z INFO controller.termination deleted node {"commit": "d7e22b1-dirty", "node": "ip-192-168-14-81.ap-northeast-2.compute.internal"}
2023-05-17T07:02:39.283Z DEBUG controller deleted launch template {"commit": "d7e22b1-dirty", "launch-template": "karpenter.k8s.aws/9547068762493117560"}
# Next, scale the number of replicas back down to 1
kubectl scale deployment inflate --replicas 1
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-17T07:05:08.877Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-145-253.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "d7e22b1-dirty"}
2023-05-17T07:05:08.914Z INFO controller.termination cordoned node {"commit": "d7e22b1-dirty", "node": "ip-192-168-145-253.ap-northeast-2.compute.internal"}
2023-05-17T07:05:09.316Z INFO controller.termination deleted node {"commit": "d7e22b1-dirty", "node": "ip-192-168-145-253.ap-northeast-2.compute.internal"}
2023-05-17T07:05:25.923Z INFO controller.deprovisioning deprovisioning via consolidation replace, terminating 1 machines ip-192-168-48-2.ap-northeast-2.compute.internal/m5.xlarge/on-demand and replacing with on-demand machine from types m5.large, c5.large {"commit": "d7e22b1-dirty"}
2023-05-17T07:05:25.940Z INFO controller.deprovisioning launching machine with 1 pods requesting {"cpu":"1125m","pods":"4"} from types m5.large, c5.large {"commit": "d7e22b1-dirty", "provisioner": "default"}
2023-05-17T07:05:26.341Z DEBUG controller.deprovisioning.cloudprovider created launch template {"commit": "d7e22b1-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/9547068762493117560", "launch-template-id": "lt-036151ea9df7d309f"}
2023-05-17T07:05:28.182Z INFO controller.deprovisioning.cloudprovider launched instance {"commit": "d7e22b1-dirty", "provisioner": "default", "id": "i-0eb3c8ff63724dc95", "hostname": "ip-192-168-144-98.ap-northeast-2.compute.internal", "instance-type": "c5.large", "zone": "ap-northeast-2b", "capacity-type": "on-demand", "capacity": {"cpu":"2","ephemeral-storage":"20Gi","memory":"3788Mi","pods":"29"}}
2023-05-17T07:06:12.307Z INFO controller.termination cordoned node {"commit": "d7e22b1-dirty", "node": "ip-192-168-48-2.ap-northeast-2.compute.internal"}
2023-05-17T07:06:12.856Z INFO controller.termination deleted node {"commit": "d7e22b1-dirty", "node": "ip-192-168-48-2.ap-northeast-2.compute.internal"}
# 인스턴스 확인
kubectl get node -l type=karpenter
kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
# 삭제
kubectl delete deployment inflate(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl scale deployment inflate --replicas 12
deployment.apps/inflate scaled
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-27T15:04:11.708Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-27T15:04:11.709Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/27 15:04:11 Registering 2 clients
2023/05/27 15:04:11 Registering 2 informer factories
2023/05/27 15:04:11 Registering 3 informers
2023/05/27 15:04:11 Registering 5 controllers
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0527 15:04:11.810597 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-27T15:04:11.841Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-27T15:32:12.792Z INFO controller.provisioner computed new machine(s) to fit pod(s) {"commit": "698f22f-dirty", "machines": 4, "pods": 12}
2023-05-27T15:32:12.792Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-27T15:32:12.798Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-27T15:32:12.804Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-27T15:32:12.811Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-27T15:32:13.346Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/17993375577863570658", "launch-template-id": "lt-0013d6ee0f7fe0333"}
2023-05-27T15:32:15.384Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-072f955243615ceaa", "hostname": "ip-192-168-120-202.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-033a0e70eb4c7ed64", "hostname": "ip-192-168-56-239.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0052af14d48b1037b", "hostname": "ip-192-168-62-255.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0e9ac86ae3bb91ce4", "hostname": "ip-192-168-104-59.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
^Z
[2]+ Stopped kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#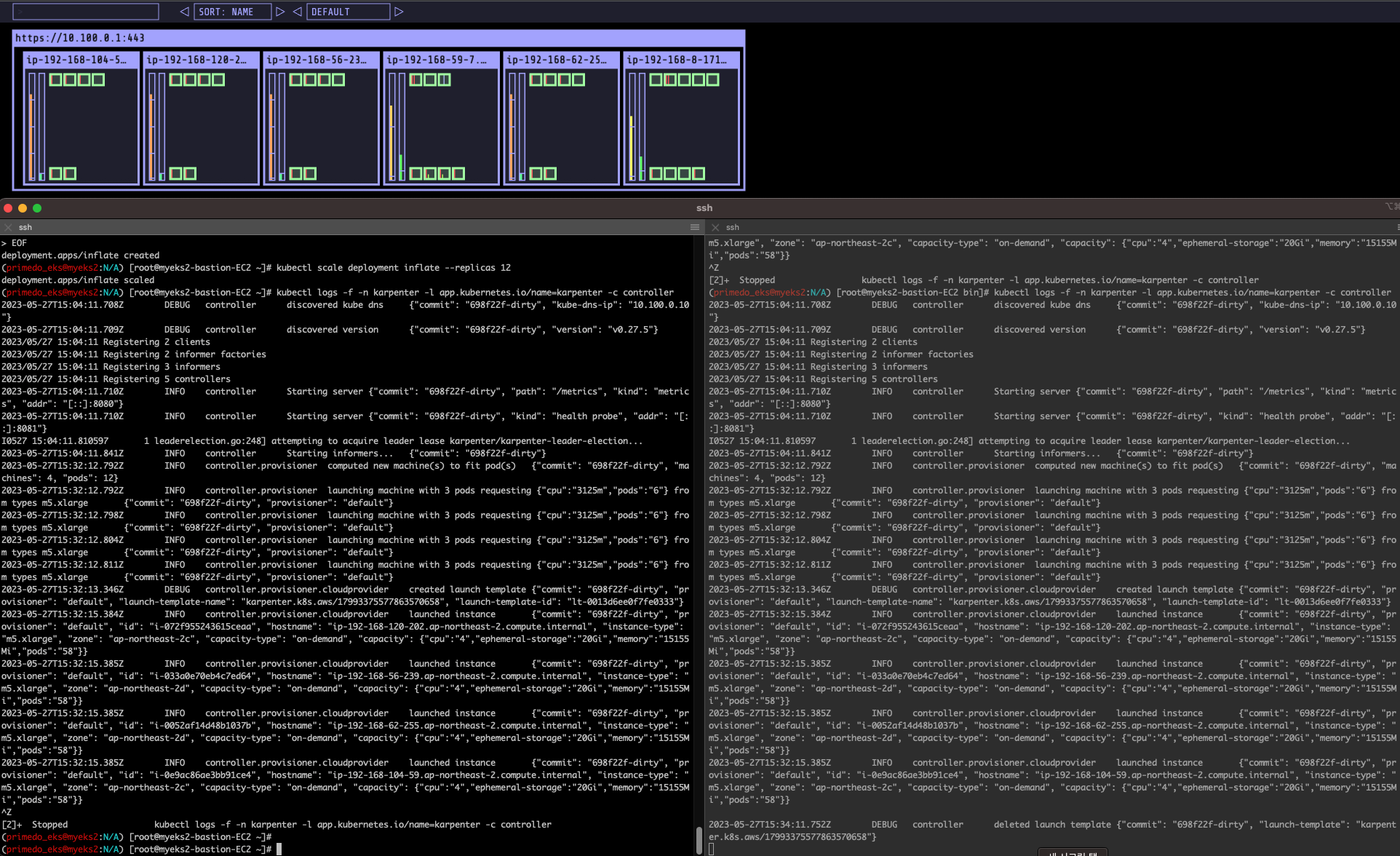
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node -l type=karpenter
NAME STATUS ROLES AGE VERSION
ip-192-168-104-59.ap-northeast-2.compute.internal Ready <none> 2m22s v1.24.13-eks-0a21954
ip-192-168-120-202.ap-northeast-2.compute.internal Ready <none> 2m22s v1.24.13-eks-0a21954
ip-192-168-56-239.ap-northeast-2.compute.internal Ready <none> 2m22s v1.24.13-eks-0a21954
ip-192-168-62-255.ap-northeast-2.compute.internal Ready <none> 2m22s v1.24.13-eks-0a21954
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE CAPACITY-TYPE
ip-192-168-104-59.ap-northeast-2.compute.internal Ready <none> 2m30s v1.24.13-eks-0a21954 on-demand
ip-192-168-120-202.ap-northeast-2.compute.internal Ready <none> 2m30s v1.24.13-eks-0a21954 on-demand
ip-192-168-56-239.ap-northeast-2.compute.internal Ready <none> 2m30s v1.24.13-eks-0a21954 on-demand
ip-192-168-59-7.ap-northeast-2.compute.internal Ready <none> 57m v1.24.13-eks-0a21954 ON_DEMAND
ip-192-168-62-255.ap-northeast-2.compute.internal Ready <none> 2m30s v1.24.13-eks-0a21954 on-demand
ip-192-168-8-171.ap-northeast-2.compute.internal Ready <none> 57m v1.24.13-eks-0a21954 ON_DEMAND
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ZONE
ip-192-168-104-59.ap-northeast-2.compute.internal Ready <none> 2m36s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
ip-192-168-120-202.ap-northeast-2.compute.internal Ready <none> 2m36s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
ip-192-168-56-239.ap-northeast-2.compute.internal Ready <none> 2m36s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2d
ip-192-168-59-7.ap-northeast-2.compute.internal Ready <none> 57m v1.24.13-eks-0a21954 m5.large ap-northeast-2d
ip-192-168-62-255.ap-northeast-2.compute.internal Ready <none> 2m36s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2d
ip-192-168-8-171.ap-northeast-2.compute.internal Ready <none> 57m v1.24.13-eks-0a21954 m5.large ap-northeast-2c
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#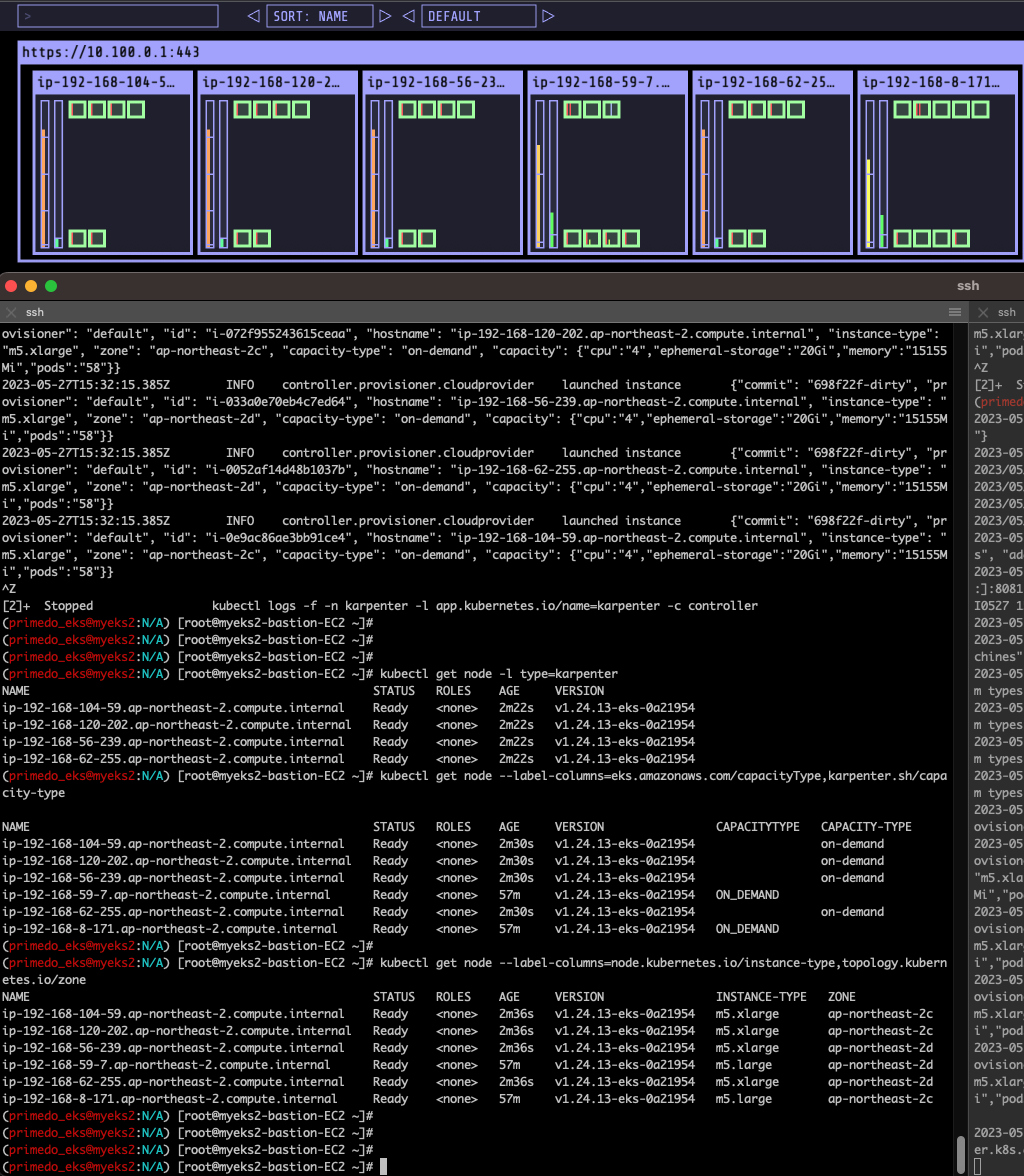
#Next, scale the number of replicas back down to 5:
kubectl scale deployment inflate --replicas 5
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl scale deployment inflate --replicas 5
deployment.apps/inflate scaled
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
#The output will show Karpenter identifying specific nodes to cordon, drain and then terminate:
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
t(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 bin]# kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-27T15:04:11.708Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-27T15:04:11.709Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/27 15:04:11 Registering 2 clients
2023/05/27 15:04:11 Registering 2 informer factories
2023/05/27 15:04:11 Registering 3 informers
2023/05/27 15:04:11 Registering 5 controllers
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0527 15:04:11.810597 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-27T15:04:11.841Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-033a0e70eb4c7ed64", "hostname": "ip-192-168-56-239.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0052af14d48b1037b", "hostname": "ip-192-168-62-255.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0e9ac86ae3bb91ce4", "hostname": "ip-192-168-104-59.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:34:11.752Z DEBUG controller deleted launch template {"commit": "698f22f-dirty", "launch-template": "karpenter.k8s.aws/17993375577863570658"}
2023-05-27T15:37:15.110Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-104-59.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-27T15:37:15.151Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-104-59.ap-northeast-2.compute.internal"}
2023-05-27T15:37:15.529Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-104-59.ap-northeast-2.compute.internal"}
2023-05-27T15:37:32.185Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-120-202.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-27T15:37:32.243Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-120-202.ap-northeast-2.compute.internal"}
2023-05-27T15:37:32.742Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-120-202.ap-northeast-2.compute.internal"}#Next, scale the number of replicas back down to 1
kubectl scale deployment inflate --replicas 1
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 bin]# kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-27T15:04:11.708Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-27T15:04:11.709Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/27 15:04:11 Registering 2 clients
2023/05/27 15:04:11 Registering 2 informer factories
2023/05/27 15:04:11 Registering 3 informers
2023/05/27 15:04:11 Registering 5 controllers
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-27T15:04:11.710Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0527 15:04:11.810597 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-27T15:04:11.841Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-033a0e70eb4c7ed64", "hostname": "ip-192-168-56-239.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0052af14d48b1037b", "hostname": "ip-192-168-62-255.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2d", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:32:15.385Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0e9ac86ae3bb91ce4", "hostname": "ip-192-168-104-59.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-27T15:34:11.752Z DEBUG controller deleted launch template {"commit": "698f22f-dirty", "launch-template": "karpenter.k8s.aws/17993375577863570658"}
2023-05-27T15:37:15.110Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-104-59.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-27T15:37:15.151Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-104-59.ap-northeast-2.compute.internal"}
2023-05-27T15:37:15.529Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-104-59.ap-northeast-2.compute.internal"}
2023-05-27T15:37:32.185Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-120-202.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-27T15:37:32.243Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-120-202.ap-northeast-2.compute.internal"}
2023-05-27T15:37:32.742Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-120-202.ap-northeast-2.compute.internal"}
2023-05-27T15:41:10.292Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-56-239.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-27T15:41:10.342Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-56-239.ap-northeast-2.compute.internal"}
2023-05-27T15:41:10.665Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-56-239.ap-northeast-2.compute.internal"}
2023-05-27T15:41:27.427Z INFO controller.deprovisioning deprovisioning via consolidation replace, terminating 1 machines ip-192-168-62-255.ap-northeast-2.compute.internal/m5.xlarge/on-demand and replacing with on-demand machine from types c5.large, m5.large {"commit": "698f22f-dirty"}
2023-05-27T15:41:27.447Z INFO controller.deprovisioning launching machine with 1 pods requesting {"cpu":"1125m","pods":"4"} from types c5.large, m5.large {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-27T15:41:27.811Z DEBUG controller.deprovisioning.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/17993375577863570658", "launch-template-id": "lt-025ae9b7a4df27bdb"}
2023-05-27T15:41:29.946Z INFO controller.deprovisioning.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-08fc50774cba01dfc", "hostname": "ip-192-168-75-185.ap-northeast-2.compute.internal", "instance-type": "c5.large", "zone": "ap-northeast-2b", "capacity-type": "on-demand", "capacity": {"cpu":"2","ephemeral-storage":"20Gi","memory":"3788Mi","pods":"29"}}
2023-05-27T15:42:14.165Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-62-255.ap-northeast-2.compute.internal"}
2023-05-27T15:42:14.706Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-62-255.ap-northeast-2.compute.internal"}
2023-05-27T15:44:11.755Z DEBUG controller deleted launch template {"commit": "698f22f-dirty", "launch-template": "karpenter.k8s.aws/17993375577863570658"}
# 인스턴스 확인
kubectl get node -l type=karpenter
kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
# 삭제
kubectl delete deployment inflate(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node -l type=karpenter
NAME STATUS ROLES AGE VERSION
ip-192-168-75-185.ap-northeast-2.compute.internal Ready <none> 4m37s v1.24.13-eks-0a21954
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE CAPACITY-TYPE
ip-192-168-59-7.ap-northeast-2.compute.internal Ready <none> 69m v1.24.13-eks-0a21954 ON_DEMAND
ip-192-168-75-185.ap-northeast-2.compute.internal Ready <none> 4m51s v1.24.13-eks-0a21954 on-demand
ip-192-168-8-171.ap-northeast-2.compute.internal Ready <none> 69m v1.24.13-eks-0a21954 ON_DEMAND
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ZONE
ip-192-168-59-7.ap-northeast-2.compute.internal Ready <none> 69m v1.24.13-eks-0a21954 m5.large ap-northeast-2d
ip-192-168-75-185.ap-northeast-2.compute.internal Ready <none> 4m52s v1.24.13-eks-0a21954 c5.large ap-northeast-2b
ip-192-168-8-171.ap-northeast-2.compute.internal Ready <none> 69m v1.24.13-eks-0a21954 m5.large ap-northeast-2c
(primedo_eks@myeks2:N/A) [root@myeks2-bastion-EC2 ~]#