Congestion vs flow control
네트워크에서의 packet양 조절 vs 리시버에서 컨트롤
다르다. 서로
외형적으로는 점점 packet이 쌓이고 딜레이가 길어지기 시작한다.
congestion 컨트롤 메카니즘은 sending rate를 줄이거나 크게 하는 방법 말고는 없다. reject해서 못 들어오게 할 수가 없다. sending rate를 어떻게 줄일것인가? 막줄이면 쉽게 해결될 것 같지만 문제는 efficiency이다. 그리고 fairness, 모든 사용자가 없어야지, 몇몇 사람만 packet을 없애면 안 된다는 것.
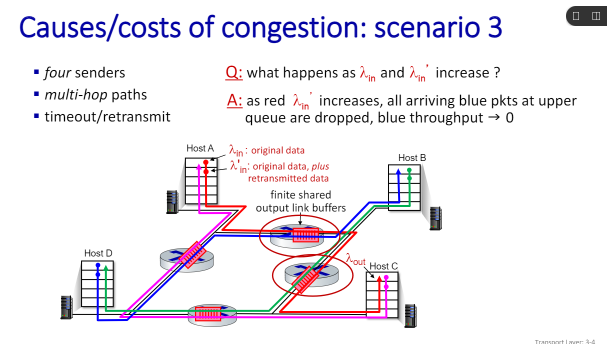
서로 router를 겹쳐서 보내는 중. 실제는 더 복잡하겠져. congestion이 일어나면 처음엔 장비가 문제인 줄 알았다. congestion이 났다고 해도 평균 패킷 처리량만큼은 처리가 돼야 하는데 컨제션이 나오니까 아예 전송이 안 되더라는 거임. 왜 그런지 이 그림을 통해 알 수 있음.
레드가 리소스를 다 사용해서 블루가 사용하지 못한다고 하자. 그런데 그 다음엔 그린이 리소스를 다 사용해서 레드가 다 로스가 됐다고 하자. 레드는 처음 라우터에선 리소스를 많이 사용했지만 그 다음엔 못 했으니 처음 사용한 리소스가 다 낭비가 되어버린 셈이다. 그래서 드랍이 되면 해당 지점까지 오면서 쓴 리소스가 다 허비된다는 것. 그래서 컨제션이 일어나면 전체 평균 패킷 전송률이 0에 접근할 수 있다는 것.
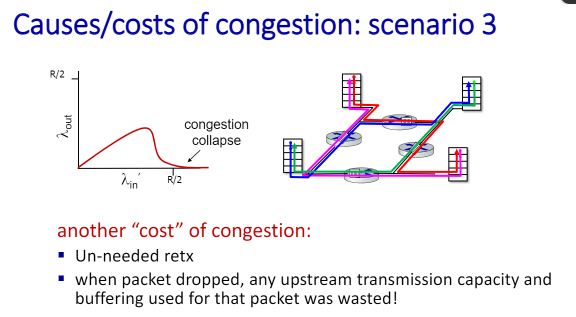
그래서 왼쪽 그래프처럼 congestion collapse가 생긴다. 컨제션으로 붕괴가 발생/ 이러면 딜레이가 엄청 길어지고 쓸데 없는 재전송이 엄청나게 발생한다. 버퍼에 패킷이 있는데 시간이 지나서 재전송이 됨. 또 패킷이 드랍되면 이전 업스트림에서 사용한 모든 리소스가 낭비가 된 셈이다.
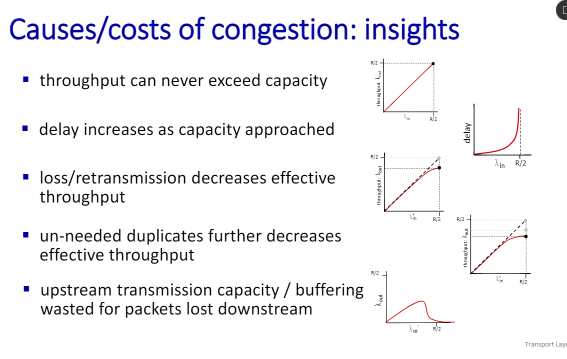
왠지 두명이서 사용하면 절반까지는 쭉 사용할 수 있을 것 같지만실제로는 어느시점부터 감소를 시작한다. 그렇게 점점 쓸데없는 게 많아지면서 더 꺾인다. 그러면서 이전 사용했던 것들이 다 쓸데없어지면서 아예 꺽여버림.
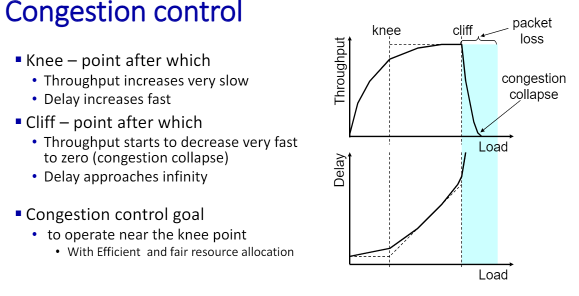
처음 그림의 KNEE 부분을 보면 꺽였다가 CLIFF에서는 THROUGHPUT이 아예 감소해버림. 그래서 컨제션 컨트롤은 knee에서 유지한다는 개념
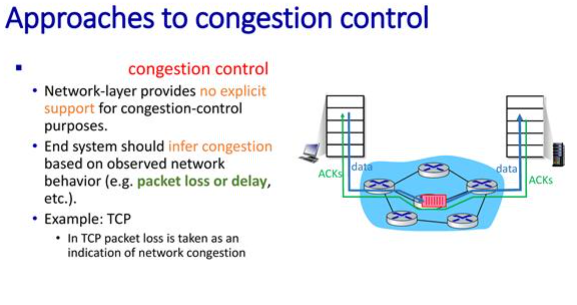
컨제션 컨트롤은 속성이 있다. 하나는 암시적이고 명백하게 알려주지 않음이다. 네트워크 사이드에서는 레이어 1~3까지만 움직인다. 실질적으로 L3에서 congestion이 났는지 알 수 없다. TCP는 end-end시스템이니 추정할 수 밖에 없다. 그래서 TCP에서는 로스가 발생하면 congestion이 발생했구나 추정하는 것.
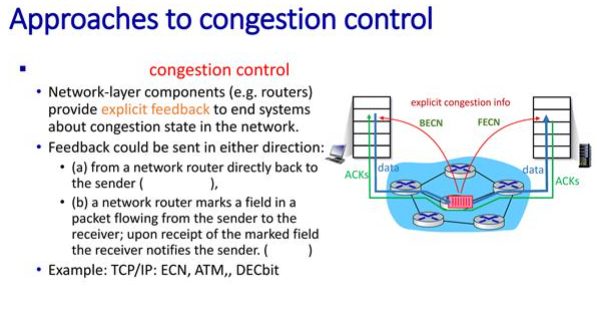
그런데 명백하게 하는 방식도 있다.
나는 지금 congestion이 아니야! 이렇게 알려주는 두가지 방식이 있다. B는 backward : 패킷이 전달되다가 경고를 sender에게 알려주는 것. 또 다른 것은 F Forward방식, receiver에게 알려주는 것. 그런데 데이터를 주는 입장인 sender가 컨제션을 알아야 함. 그러니 B가 정상적임. 그런데 B는 알려주기 위한 새로운 패킷을 만들어야 함. 또한 진행의 반대쪽으로 가야하기에 반대길도 컨제션일 상황이 높다. 그래서 원칙은 B인데 F를 많이 쓴다. 그래서 network layer이기에 IP layer에 지나가는 패킷의 header에 한 비트를 할당해서 알려준다. receiver의ip protocol이 받는다. 그러면 receiver의 TCP에게 알려준다. 그러면 TCP에서 헤더의 한 비트에 ack의 헤더에서 알려준다. 그게 ECN메커니즘이다.
TCP congestion contorl
window based <-> Rate-based
윈도우 베이스는 윈도우 사이제에 비례하게 sending이 날라간다. 컨제션이 났다는 걸 어떻게 아는가? 위에서는 "났을 때", "안 났을 때"라고 나와있는데? 그래서 timeout이 발생하면 컨제션에 의한 로스다 이렇게 판단한다. 정확히는 3dup ack이다. loss면 TCP는 전부 congestion에 의한 거라고 추정하고 판단한다. 그러면 wireless가 들어가면 transmission으로 발생하면 에러가 날 수 있다. TCP는 전송상 에러를 네트웍의 컨제션이라고 생각하니. 이렇게 추정하는 게 잘 못 추정할 수 있다. 그리고 증가 감소는 어떻게 ? 그런 것들을 해결해야 한다.

A : additive : 덧셈식
M : multiplicate : 곱셈식
underload : 사용양에 못 미침
overload : 사용가능량을 넘음
해당 선에 가깝게 해야 효율이 좋다는 것
fair는 y=x그래프이니 같은 양을 사용. 따라서 둘 다의 조건을 만족하려면 교점에 가까워야 함.
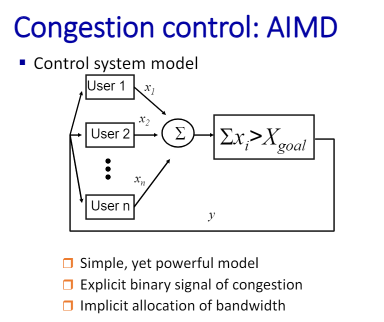
간단하고 유용한 모델
n명이 있고 각각의 트래픽 양을 xn으로 잡음. 보내는 트래픽의 양이 자신의 타겟보다, 리소스 양보다 크면 너가 congestion이다 이렇게 알려줌. 그보다 많아 작아 이것만 알려준다. 그러면 그 정보를 가지고 컨제션이다 아니다 정보를 가지고 알고리즘을 통해 xn의 양을 조절하게 된다.

컨제션 -> 감소, 없으면 -> 증가
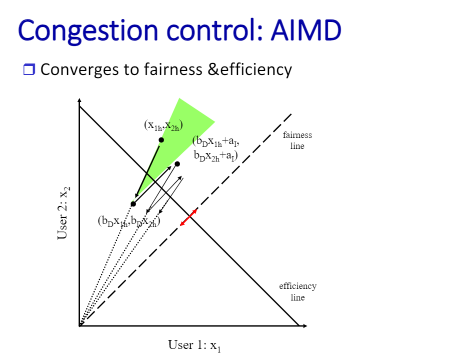
두 사람이 있을 경우 현재 상태가 x1h,x2h라고 하면 overload이니 o.x를 곱해줘야 한다. 많이 사용하는 얘가 많이 줄인다. 둘 다 0을 접근하는 직선을 따라서 감소하게 된다. 모든 점이 저 곳으로 온다.

Tahoe Reno
ack은 packet이 도착했으니까 오는 거니까 congestion에서 자유로움
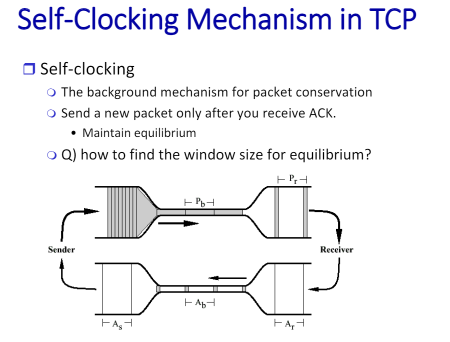
fat pipe, thin pipe한번 늦게 전송이 되면 bandwidth가 늘어나도 bottelneck에서의 시간을 유지 한다. 액이 패킷 사이즈가 작으니 아주 작은 시간으로 날라간다. 결국 상단의 bottleeneck이 모든 걸 결정한다. equilibrium에 도착할 때 이야기이고 새로운 세션이 열려서 패킷을 보내면 평형상태가 다 깨져서 컨제션이 생기게 된다. 그래서 보낼 때 잘 보내야 한다.

자신이 이용할 수 있는 bandwidth compacity를 알고 넣어야 하는데 이걸 알기 위해 아주 천천히 해야 한다. 그런데 너무 조심스럽게 하면 파일 전송에 너무 시간이 많이 걸려서 또 문제. 자신이 이용할 수 있는 bandwidth를 빨리 알아야 한다. 아주 작게 시작해서 아주 exponentially하게 증가시킨다. 그래서 available한 bandwidth가 몇인지 빠르게 알아내야.
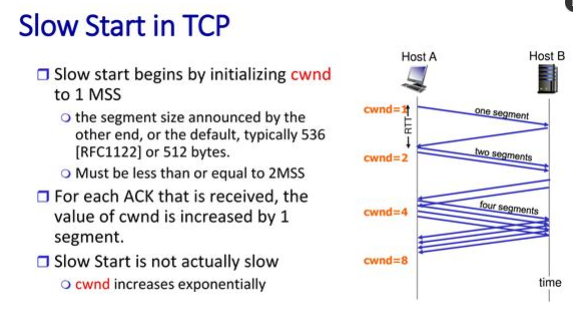
MSS(maximum segment size)를 1로 한다. mss에서 알려주는데 그걸 안 하면 default로 536으로 한다. 그런데 표준에 보면 2MSS보다는 크지 않게 하라는 말이 있다. 요즘은 또 너무 적게 시작하면 데이터 전송이 오래 걸리니까 조금 더늘리자 이런 말도 있는데 여튼 처음 얘기. 여기서 딜레이를 일단 머리에서 지워야. 하나의 세그먼트를 보내면 ack이온다. ack을 받을 때마다 cwnd를 1MSS증가 시킨다. 이렇게 하면 cwnd가 엄청나게 증가한다.


증가시키는 룰. 컨제션이 발생했을 때 즉, 타임아웃이나 3 dupack 생길 때 현재 window 사이즈를 반으로 줄이고 ssthresh에 저장한다.

실제 타오에서는 이렇게 한다.
cwnd를 일반적으로 1MSS로 하고 ssthresh는 64KB rwnd, cwnd를 둘 다 만족시켜야. 만약 new ack이 도착하면 자신이 현재 scnd가 ssthresh보다 작으면 slow start이고 아니면 congestion avoidance이다. ack이 rTT동안 1mss만큼 증가하니까 linear하게 증가한다.
그 다음 컨제션이 일어나면 타임아웃이나, 3dup가 발생하면 sstheresh를 flightsize(=cwnd)이다. 걔의 반으로 감소를 시킨다. 엄청 줄이는 것.
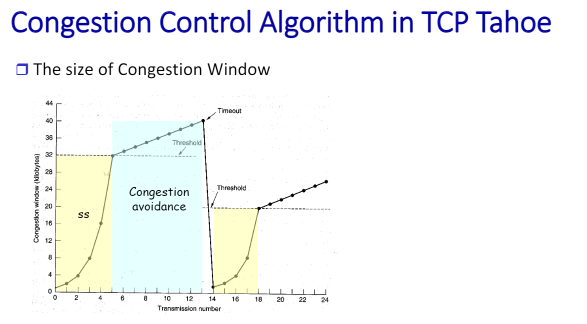
ideal하게 보면 이렇데. x축은 단위가 RTT임.
