데이터 전처리
수집한 데이터를 machine learning agorithm을 운용할 수 있는 형태로 가공하는 작업
데이터의 분할, 결측치, 범주형 데이터, 클래스 불균형 등 일반적인 데이터에서 발생 가능한 문제를 해결하는 방법론
실습 데이터 - Titanic Data
타이타닉호에 승선했던 탑승자 정보를 담고 있는 데이터
탑승자 정보를 바탕으로 탑승자의 사망 여부를 알아낼 수 있을까?
https://www.kaggle.com/c/titanic/data
결측 데이터의 처리
늘 모든 데이터가 모든 값에 대해 정보를 담고 있을 수는 없다.
이럴 때, 결측치 데이터를 처리하는 코드에 대해 알아보자
일단 데이터를 가져와서 결측치가 있는지 확인한다
import pandas as pd
df = pd.read_csv('your data directory/data_file.csv')DataFrame에 결측치가 있으면 True, 아니면 False를 반환한다
df.isna()
Data의 전체 정보를 확인하는 방법으로 결측치를 확인할 수도 있다
df.info()
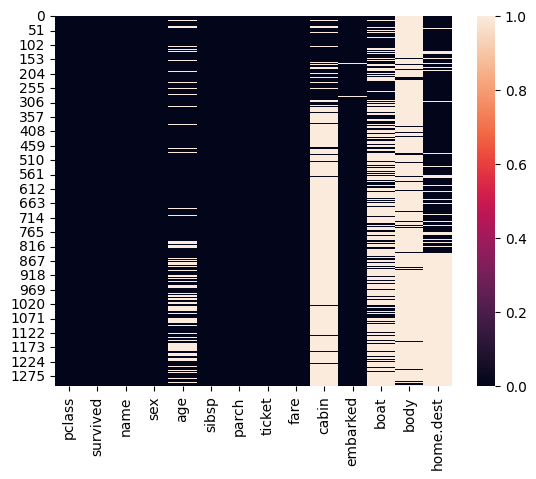
결측 데이터를 시각화 할때는 seaborn을 추천한다
import seaborn as sns sns.heatmap(df.isna())
Handling Missing Data 1. Removal
결측치가 너무많은데 유추해서 채우기도 어렵고, 의미없는 Feature 같은데?
지워버려
결측치 비율 계산
df['cabin'].isna().sum()/len(df)*100 #결측이 77%나?!
column을 삭제하는 다양한 방법
df = df.drop('cabin', axis = 1) df = df.drop(['cabin', 'ticket']) del df['cabin']
Handling Missing Data 2. Replace
결측치 값이 그렇게 많지 않거나, 충분히 유추할 수 있는 정보라면 내가 임의로 적당히 채우면 되지 않을까?
숫자네? 평균값으로 하자!
df['fare'].fillna(df['fare'].mean(), inplace=True)
카테고리 데이터네.. 일단 다른 값들을 확인해보자
df['emarked'].unique() # array(['S', 'C', nan, 'Q'], dtype=object)
제일 많은 값으로 하자!
df['emarked'].value_counts() # embarked # S 914 # C 270 # Q 123 df['embarked'].fillna(df['embarked'].mode()[0], inplace=True)
데이터의 존재 자체가 중요한 값인데?
df['boat'] = df['boat'].isna() def bool_to_binary(x): return int(x) df['boat'].apply(bool_to_binary)
범주형 변수의 처리
categorical data라고도 하며
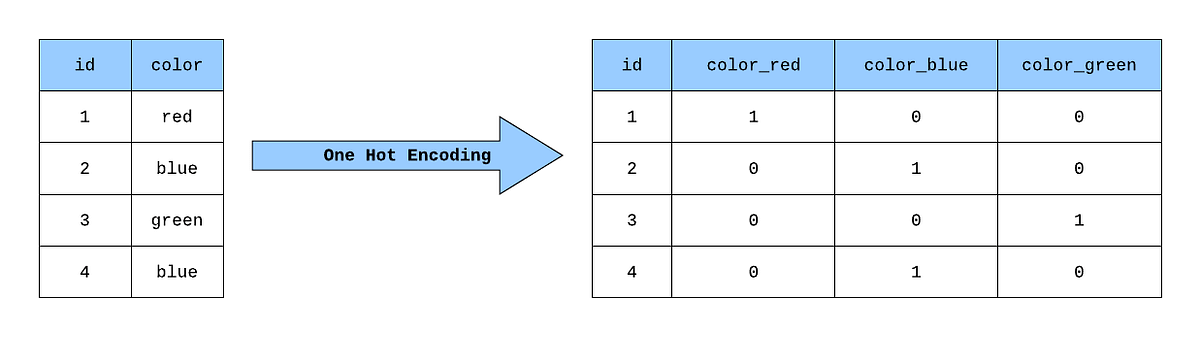
데이터가 특정 구간에 속하여 구분이 가능한 데이터 분포를 보이는 변수의 범주형 데이터라고 하는데, 보통 문자열로 구분이 되어 있어 이를 컴퓨터가 숫자 값이 아닌 카테고리형으로 이해할 수 있도록 dummy화, 혹은 one-hot 인코딩이라는 형태로 변경한다.
get_dummies
pd.get_dummies(df, columns = ['pclass', 'sex', 'embarked']one-hot-encoding
머신러닝을 할 때, 0이 많은 값은 약간 noise라고 인식될 수 있는데, 범주형 변수를 처리하면 문제가 0이 다수인 data들이 너무 많이 생긴다는 점이다.
그래서 columns를 하나라도 줄일 수 있으면 좋은데 사실 하나는 줄일 수 있다.
그러니까 분류가 A, B, C라면
A도 아니고 B도 아니면? C 잖아!
그러므로 한 개 column은 불필요 하게 들어가있다고 생각할 수 있다.
이럴 때 drop_first 옵션을 사용한다
pd.get_dummies(df, columns=['pclass', 'sex', 'embarked'], drop_first=True)시간형 데이터의 처리
test data의 생성
f1=pd.DataFrame(pd.date_range('2022-01-01', periods =400, freq='H'), columns=['datetime'])위와 같이 기간과 주기를 정해서 시간형 데이터를 만들어 볼 수 있음
아니면 이미 있는 시간 데이터에 대해
pd.to_datetime(변수명) #문자열 등을 시간형태의 데이터타입으로 변환이렇게 데이터 타입을 변환할 수도 있음
여기서 좋은 점은
- 날짜끼리의 연산이 가능함
df1.loc[10, 'datetime'] - df1.loc[7, 'datetime'] # Timedelta('0 days 03:00:00')
- 쪼갤 수도 있고 그 과정에서 요일 계산도 가능함
df1['year']=df1['datetime'].dt.year print(df1['datetime'].dt.year) print(df1['datetime'].dt.month) print(df1['datetime'].dt.day) print(df1['datetime'].dt.hour) print(df1['datetime'].dt.minute) print(df1['datetime'].dt.second) print(df1['datetime'].dt.microsecond) print(df1['datetime'].dt.dayofweek) # 0부터 월요일
Scale의 조정
사용해야 하는 데이터에 따라 스케일의 보정이 필요한 경우가 있습니다.
예를 들어,
특정 값은 해당 값의 단위가 10만인데,
어떤 feature의 값은 값의 단위가 0.001일때,
각각의 beta값이 단순히 단위로 인해 큰 차이가 나게 됩니다
이 문제를 방지하기 위해 scale 보정이 필요합니다.
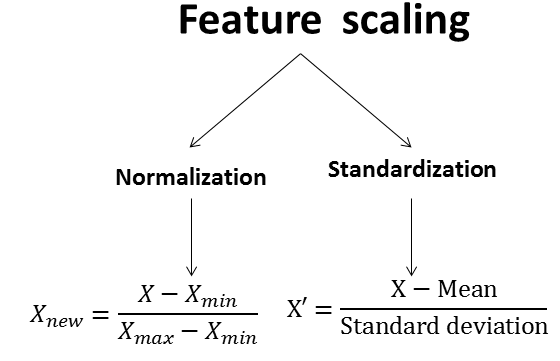
가장 일반적으로 사용하는 scale 보정 방법론에는 2가지가 있습니다
Normalization
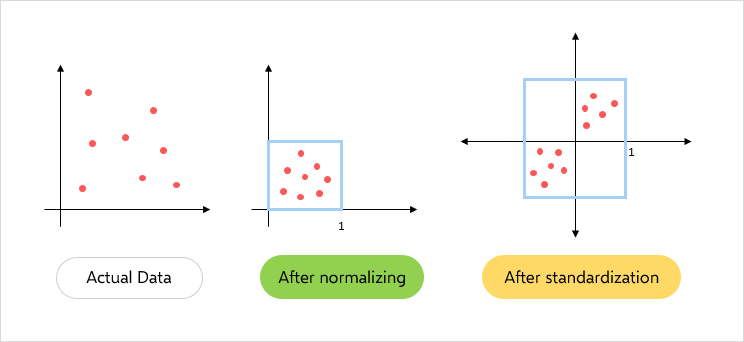
설명 변수의 범위를 0~1 사이로 조정
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(X_train) scaler.transform(X_train) scaled_X_train = pd.DataFrame(scaler.transform(X_train), columns=X_train.columns)
Standardization
설명변수의 범위를 평균0, 분산1이 되도록 조정. 정규분포를 표준정규분포화 시키는 것
데이터가 가진 분포 정보가 많이 뭉개지기 때문에 잘 사용하지 않는다
클래스 불균형 (imbalance data)
PJT를 진행하며 만날 수 있는 굉장히 빈번하게 나타나지만 해결이 어려운 문제
학습에 필요한 충분한 클래스의 샘플 수를 확보하지 못해 모델의 결과값이 샘플 수가 큰 클래스로 편향되는 문제를 발생시킴
ex) 1000개 샘플 중 10개의 오류를 모두 정상이라 판별해도 acc는 99%입니다.
타겟 데이터의 불균형 문제를 해결하기 위한 방법으로 oversampling / undersampling을 활용 할 수 있습니다.
- oversampling
타겟데이터 클래스 샘플 수를 크기가 큰 타겟데이터 클래스 샘플 수와 같은 갯수로 생성
- undersampling
타겟데이터 클래스 샘플 수를 크기가 작은 타겟데이터 클래스 샘플 수와 같게 샘플 삭제
# imblearn 설치
!pip install -U imbalanced-learn
# SMOTE import
from imblearn.over_sampling import SMOTE
# oversampling 적용
# imblearn oversampling SMOTE (Synthetic Minority Oversampling Technique)
smote = SMOTE()
over_X_train, over_y_train = smote.fit_resample(X_train, y_train)