1. 개요
아키텍처 설계 인터뷰에 참여할 기회가 있었습니다. 제한시간 30분 내에 주어진 요구사항과 비기능 요구사항, 그리고 다양한 고려 사항을 바탕으로 글로벌 실시간 채팅 플랫폼을 설계하는 과제를 수행해야 했습니다.
하지만 당일에는 채팅 시스템에 대한 이해도가 부족해 충분한 답변을 작성하지 못했고, 아쉬움이 많이 남았습니다.
비록 시험은 끝났지만, 이번 기회를 통해 부족했던 부분을 학습하고, 실제로 아키텍처를 설계해보며 채팅 시스템에대한 이해를 얻고 싶다는 생각이 들었습니다.
이전에 작성했던 코인 거래소 주문 매칭 엔진처럼 이번에도 개략적 설계안을 먼저 작성하고, 이후 직접 구현해보는 과정을 포스팅으로 남기려 합니다. 감사합니다.🙂
2. 시스템 요구사항
시스템의 사용자, 사용 사례, 비기능 요구사항등을 정리합니다.
- 사용자
- 일반 사용자 : 글로벌 채팅 플랫폼을 사용하는 일반 개인 사용자 다양한 국가에 거주, 모바일 또는 웹 클라이언트 사용
- 시스템 운영자 : 시스템 상태를 모니터링하고 문제 발생 시 대응하는 관리 역할, 장애 복구, 트래픽 관리, 데이터 보존 정책 운영
-
사용 사례
2-1. 사용자 등록 및 로그인
- 사용자는 시스템에 가입하고 로그인합니다.
- 전 세계 어디서든 로그인 시 낮은 지연시간을 보장해야 합니다.2-2. 친구 추가
- 사용자는 다른 사용자를 검색을 통해 친구추가 할수있습니다.2-3. 1:1 채팅
- 친구와의 개인 채팅 기능 제공
- 실시간 메시지 전송 및 수신 (지연시간 100ms 이하)2-4. 그룹 채팅
- 최대 1,000명이 참여 가능한 그룹 채팅 기능 제공
- 실시간으로 메시지가 전송되고 수신됩니다.2-5. 메시지 이력 조회
- 사용자는 과거 메시지를 조회할 수 있습니다.
- 메시지는 최소 6개월간 저장됩니다.2-6. 메시지 전송
- 사용자가 메시지를 입력하면 상대방에게 실시간으로 전달됩니다.
- 메시지는 영구 저장소에 저장되어야 하며, 6개월 후 자동 삭제됩니다.2-7. 메시지 전송 시 푸시 알림
- 메시지 수신자가 오프라인 상태일 경우, 푸시 알림을 전송합니다.
- 푸시 알림은 모바일 OS의 푸시 서비스를 통해 전달됩니다.2-8. 장애 자동 복구
- 시스템에서 장애가 발생했을 경우 자동으로 복구가 이루어져야 합니다.
- 고가용성(99.99%)을 유지해야 하므로 무중단 서비스를 제공해야 합니다.2-9. 메시지 저장 및 삭제 정책 적용
- 메시지는 저장 후 일정 기간이 지나면 자동 삭제되어야 합니다.2-10. 운영자 시스템 모니터링
- 실시간 트래픽 상태, 메시지 처리량, 장애 상태 등을 확인할 수 있는 모니터링 기능이 필요합니다. -
비기능 요구사항
비기능 요구사항은 시스템이 원활하게 운영되기 위해 필요한 성능, 확장성, 안정성, 보안성 등의 요소를 정의합니다.
- TPS 1,000,000 건의 메시지 처리가 가능해야합니다.
- 전세계 사용자를 지원, 지연시간은 100ms 이내를 유지해야합니다.
- 고가용성 99.99% 를 보장합니다.
- 장애 발생 시 자동 복구가 가능해야합니다.
- 데이터 저장은 6개월간 유지되고, 이후 삭제 됩니다.
- 메시지 이력의 검색 성능을 최적화하기 위한 인덱싱 및 파티셔닝 전략이 필요합니다.
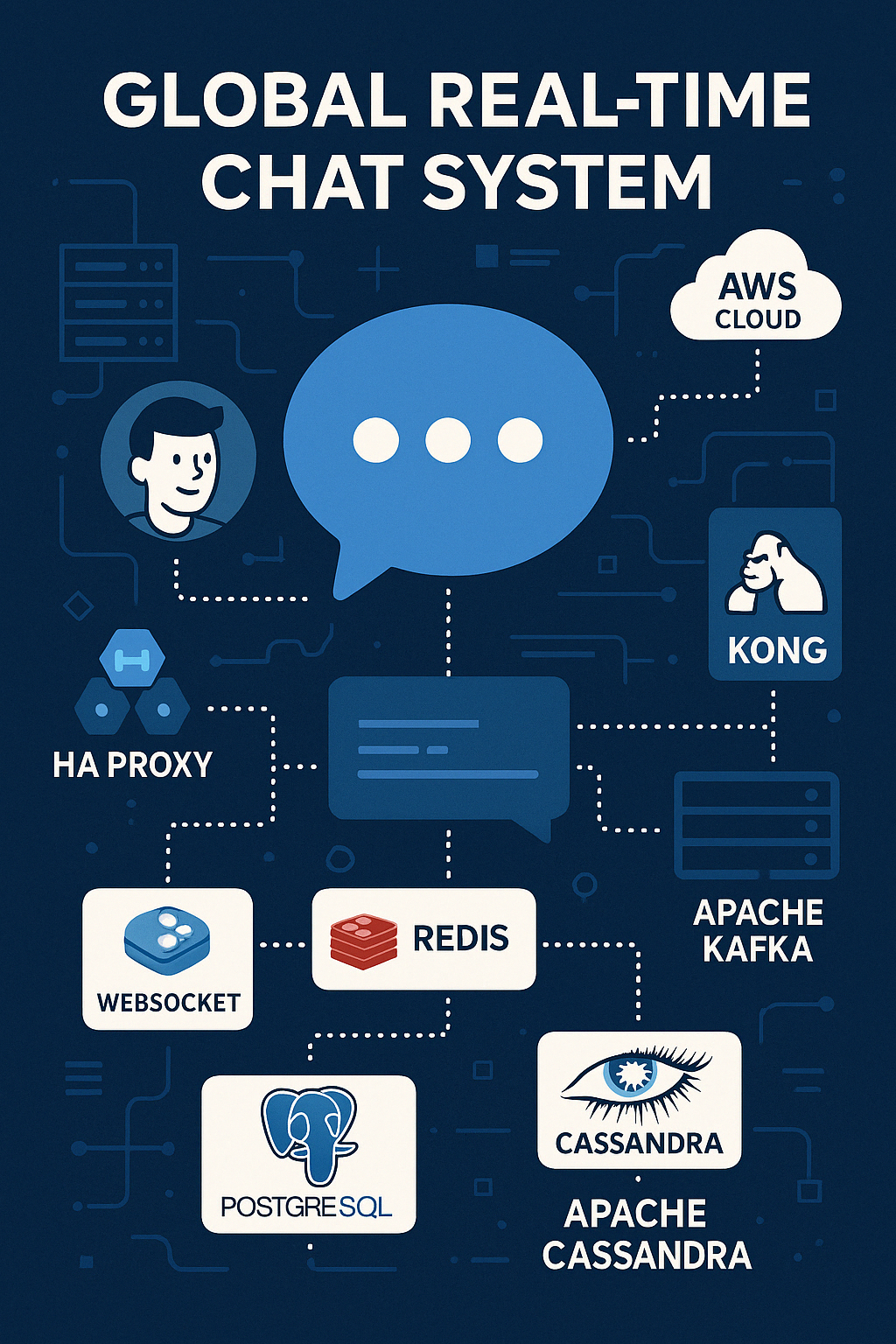
3. 사용할 기술 스택
시스템 구현에 사용할 기술 스택, 선택 이유를 정리합니다.
프로그래밍 언어 / 프레임워크: TypeScript + NestJS
- 실제 서비스가 아니기에 빠른 구현 및 테스트를 위해 사용합니다. 실제 서비스에는 각 서비스에 맞는 언어를 고려해서 사용합니다.
- WebSocket 및 REST API를 동시에 지원하며, 모듈화 구조와 의존성 주입(DI) 기반 설계가 가능해 확장성과 유지보수에 유리합니다.
실시간 통신: WebSocket
- 기본적으로
@nestjs/websockets + socket.io를 사용하여 구현합니다. - TPS 1,000,000 이상의 고성능 환경이 요구되므로,
uWebSockets.js기반 커스텀 어댑터 도입도 리서치 및 검토 예정입니다.
데이터베이스: PostgreSQL + Apache Cassandra
-
PostgreSQL- 사용자, 친구, 그룹, 인증/권한 등 관계형 데이터 저장에 사용합니다.
- 트랜잭션(ACID) 보장, NestJS와의 연동 시 TypeORM 또는 Prisma를 활용할 수 있습니다.
-
Apache Cassandra- 1:1 / 그룹 메시지 저장, 읽음 상태 관리, 메시지 이력 조회 등에 사용됩니다.
- TPS 1,000,000 수준의 고속 쓰기, 분산 저장, TTL 기반 자동 만료 기능 제공
캐시 계층 / 실시간 상태 관리: Redis
- 실시간 유저 상태 관리, 세션 저장, 빠른 데이터 접근 및
Pub/Sub기반 메시지 브로드캐스트 등에 사용됩니다.
메시지 브로커: Apache Kafka
- 메시지 수신, 저장 등의 흐름을 비동기로 분리하여 확장성과 내결함성을 높입니다.
- 대규모 트래픽 대응 및 컨슈머 지연 추적이 용이합니다.
로드밸런서: AWS NLB + ALB
- NLB(Network Load Balancer)와 ALB(Application Load Balancer) 를 함께 사용하여
WebSocket 기반 지속 연결과 HTTP 기반 API 요청을 모두 효율적으로 처리합니다. - WebSocket 기반 지속 연결을 효율적으로 분산 처리하기 위해 사용합니다.
- 높은 커넥션 유지성과 성능 제공
API 게이트웨이: Kong Gateway 또는 Apache APISIX
- REST API 호출 시 JWT 인증, 속도 제한(Rate Limiting), 라우팅, 요청/응답 가공 등의 기능을 제공합니다.
- 많은 기업이 사용하고 검증된 Kong (무거움), 가볍고 고성능인 Apache APISIX 고려
통신 방식: gRPC / REST
- 마이크로서비스 간 통신은 gRPC 또는 REST를 통해 이루어집니다.
- gRPC는 고성능 바이너리 통신 기반으로 내부 서비스 간 빠른 요청/응답 처리에 적합합니다.
- REST는 외부 연동 및 범용적인 API 통신에 유리합니다.
인증 방식: JWT + Redis
- 사용자 인증 및 로그인에 사용되며, 발급된 토큰을 통해 API 및 WebSocket 요청 시 사용자 식별이 가능합니다.
- 메모리 기반으로 세션을 관리하며 확장성 있는 인증 시스템을 구성할 수 있습니다.
멀티 리전 글로벌 인프라
- CDN:
AWS Cloud - 글로벌 로드밸런서:
AWS Global Accelerator - 전 세계 사용자에 대해 가장 가까운 리전 엔드포인트로 라우팅합니다.
- 장애 발생 시 자동으로 다른 리전으로 failover 가능합니다.
- DB 전략:
Cassandra: 멀티리전 분산 저장 구조를 기본 지원PostgreSQL: 읽기 전용 지역별 리전 복제 구성
모니터링: Prometheus + Grafana
- Kafka, Redis, PostgreSQL, NestJS 애플리케이션의 메트릭 수집 및 시각화에 사용됩니다.
4. 애플리케이션 아키텍처
애플리케이션의 구성도 입니다.
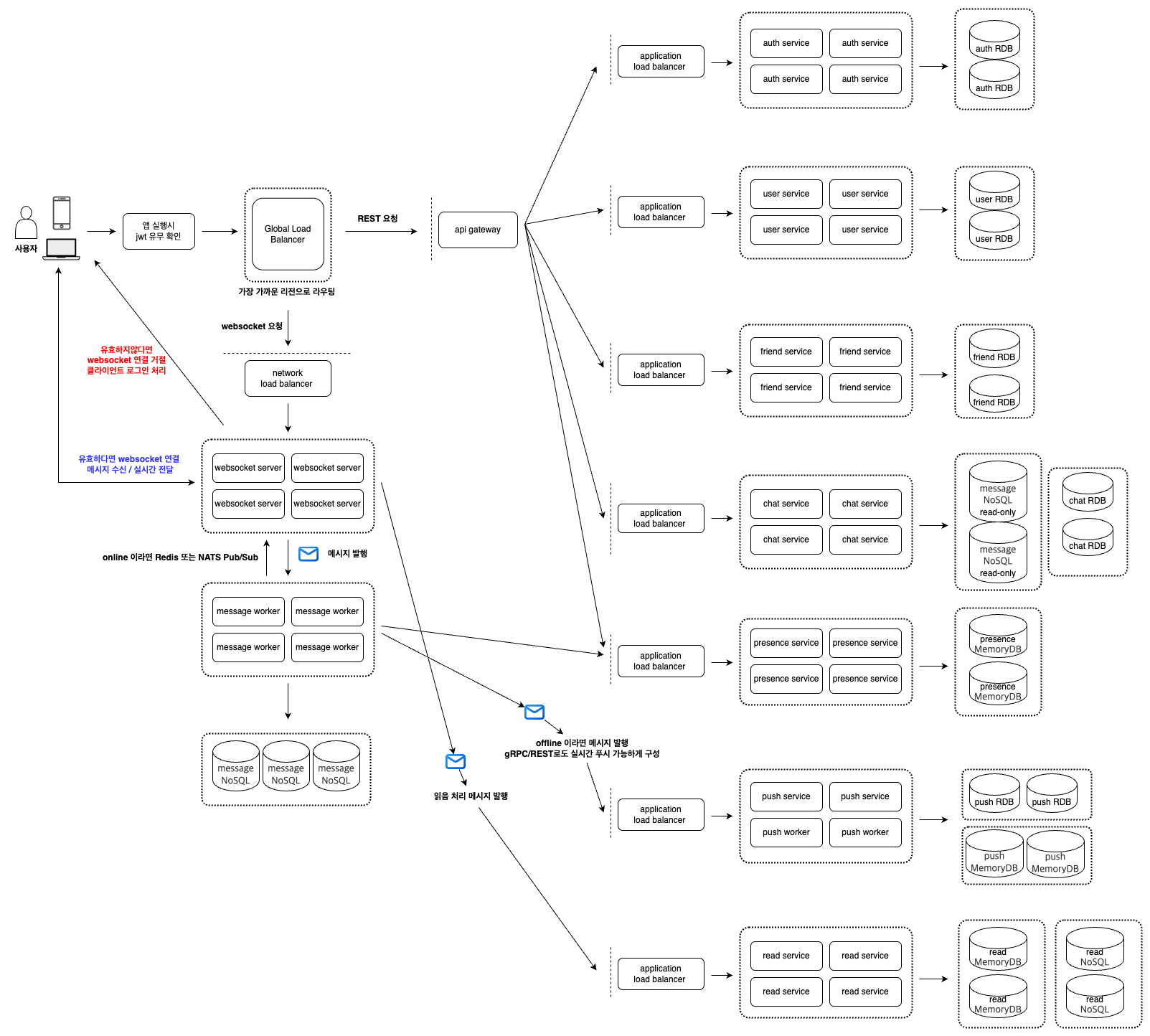
- 본 시스템은 글로벌 환경을 고려해 마이크로서비스 아키텍처로 설계되었습니다.
단일 애플리케이션 구조가 반드시 나쁘다고 보진 않지만, 전 세계 수많은 사용자와 높은 트래픽을 안정적으로 처리하기 위해 서비스 분리가 용이하고 확장성이 뛰어난 마이크로서비스 방식을 선택했습니다. - 마이크로서비스 아키텍처는 다양한 장점이 있지만, 제가 가장 장점으로 생각한 부분은 이미 많은 빅테크 기업들에 의해 검증된 안정성과 유연성입니다. 대규모 시스템에서 충분히 효과적이라는 점이 실제 사례로 입증되었습니다.
- 물론 마이크로서비스 아키텍처가 모든 문제를 해결해주는 실버불릿은 아닙니다. 서비스 간 복잡도 증가, 데이터 정합성 관리, 배포 및 모니터링 체계 등 새로운 도전 과제가 뒤따릅니다.
하지만 이러한 문제들에 대해서도 이미 검증된 다양한 패턴과 해법이 존재하며, 적절한 설계와 도구를 통해 충분히 안정적인 운영이 가능합니다. - 시스템은 기능 단위로 다음과 같은 서비스로 구성됩니다 auth, user, friend, chat, presence, push, websocket, message worker, read
- 각 서비스는 완전히 독립적으로 배포 및 운영이 가능하며, 서비스 단위로 수평 확장이 가능해 트래픽 증가에 유연하게 대응할 수 있습니다.
- 각 서비스는 마이크로서비스 아키텍처의 모범 사례에 따라 자체 데이터베이스를 보유하며, 서비스 간 데이터베이스 공유는 없습니다.
- 각 서비스가 자체 데이터베이스를 소유하므로, 서비스 간 복합 작업에서 전통적인 분산 트랜잭션(ACID)을 적용하기 어렵습니다.
이를 해결하기 위해 본 시스템에서는 이벤트 기반의 saga 패턴을 활용하여 서비스 간 트랜잭션을 관리합니다. 롤백이 필요한 경우에는 보상 트랜잭션을 통해 상태를 복원합니다. - 데이터 저장소는 서비스의 특성에 따라 RDBMS, NoSQL, In-memory 등 다양한 스토리지를 목적에 맞게 선택합니다.
- 데이터베이스 역시 각자의 특성에 따라 수평 확장이 가능하도록 설계되어 있으며, 대규모 트래픽에도 대응할 수 있도록 구성됩니다.
- 필요에 따라 각 서비스는 서비스에 적합한 언어와 기술 스택으로 구현이 가능합니다.
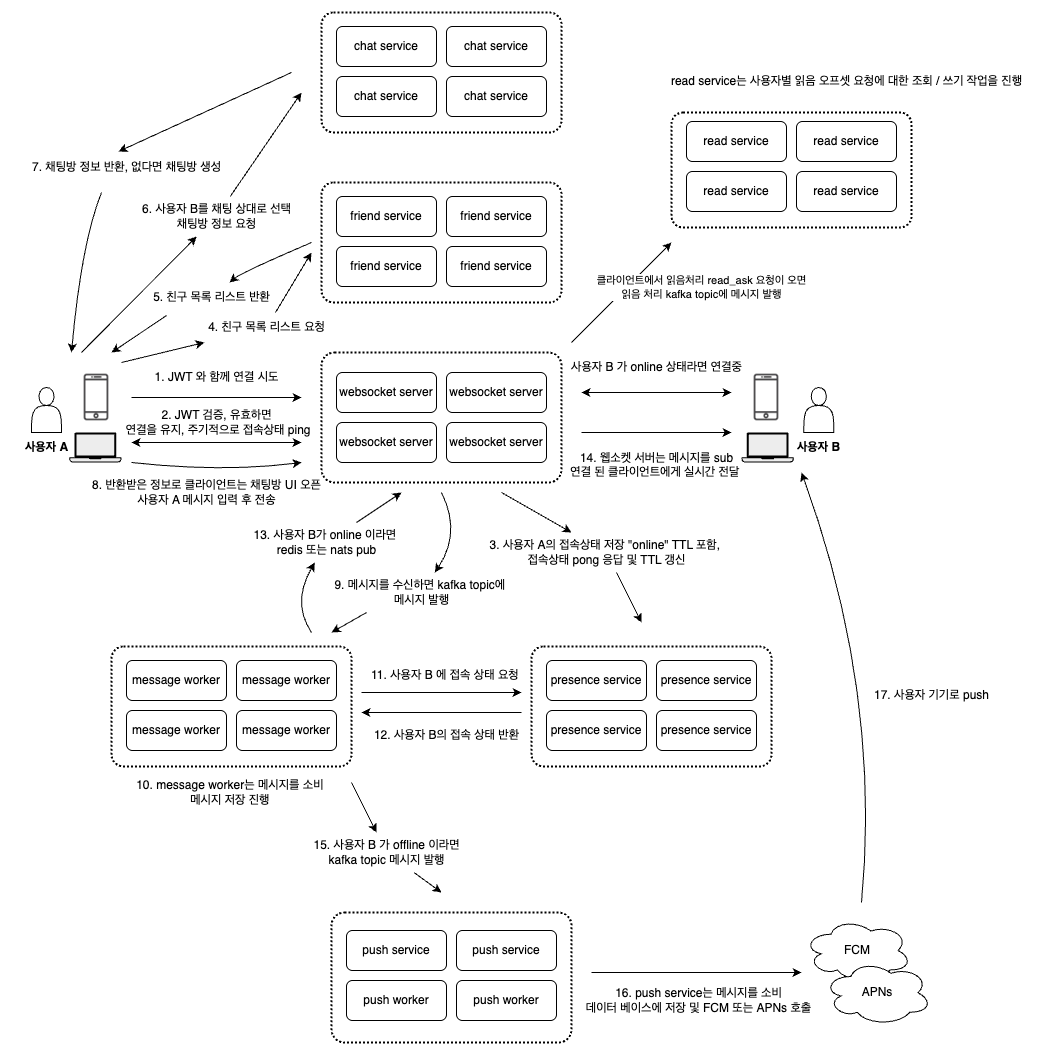
5. 애플리케이션 플로우
애플리케이션의 플로우 입니다.
큰 틀의 플로우를 정리합니다. 로그인부터 채팅방 진입 -> 메시지 전송 플로우 입니다.
서비스가 방대하기에 실제 테스트 구현은 채팅 메시지만 구현해볼 예정입니다.🙂
- 사용자가 앱에 로그인하면, auth 서비스로 로그인 요청을 보냅니다.
- auth 서비스는 사용자의 자격을 검증한 뒤, jwt 토큰을 발급합니다.
- 이후 클라이언트는 이 토큰을 authorization 헤더에 포함하여 user 서비스에 사용자 정보 요청을 보냅니다.
- user 서비스는 jwt 유효성을 검증하고, 사용자 정보를 반환합니다.
- 클라이언트는 friend 서비스에 친구 목록을 요청합니다.
- friend 서비스는 jwt를 검증한 뒤, 해당 사용자의 친구 목록을 응답합니다.
- 클라이언트는 chat 서비스에 채팅방 목록을 요청합니다.
- chat 서비스는 jwt를 검증하고, 사용자의 채팅방 목록을 반환합니다.
- 사용자가 채팅방에 진입하면, 클라이언트는 websocket 서비스에 연결을 시도합니다.
- websocket 서비스는 jwt를 직접 검증하여, 사용자의 신원을 확인한 뒤 연결을 승인합니다.
- 사용자가 메시지를 입력하면, 해당 메시지는 websocket 통해 websocket 서버에 전달됩니다.
- websocket 서버는 메시지를 받으면 kafka를 통해 message worker에 메시지를 발행합니다.
- message worker는 kafka 메시지를 소비하고, 메시지를 NoSQL에 저장합니다.
- 이후 redis에 저장된 presence 정보를 기반으로 수신자의 온라인 상태를 확인합니다.
- 수신자가 온라인 상태일 경우, message worker가 redis pub/sub을 통해 websocket 서버로 메시지를 전파합니다.
- websocket 서버는 해당 수신자와 연결된 소켓을 통해 실시간으로 메시지를 전달합니다.
- 수신자가 오프라인 상태일 경우, message worker는 kafka에 push 메시지를 발행합니다.
- push 서비스는 kafka 메시지를 소비하고, 수신자의 기기로 FCM 또는 APNs를 통해 푸시 알림을 전송합니다.
6. 채팅 플로우
애플리케이션의 채팅 플로우 입니다.
채팅 플로우는 1:1과 그룹 채팅 모두에 공통 적용되며, 그룹 채팅은 수신자 수(N명) 확장 및 presence 최적화만 추가된 확장 모델입니다.
채팅 플로우에 대한 설명은 플로우차트 함께 정리되어 있기에, 별도의 단계 설명 없이 설계 과정에서 고민했던 주요 포인트와 해결 전략 중심으로 정리합니다.
-
더미 채팅방
채팅방 정보를 요청했을 때, 해당 방이 없다면 즉시 생성하는 방식은 프론트엔드와 백엔드 모두에서 구현이 단순하고, 전체 플로우 상 자연스럽게 동작합니다. 다만 이 방식은 메시지가 없는 상태로 방만 생성되는"더미 채팅방"이 누적될 수 있는 문제가 있습니다. 이는 데이터 정합성이나 리소스 낭비 측면에서 리스크가 될 수 있기 때문에, DBA가 있다면 함께 논의하여 초기 설계에 반영하는 것이 바람직합니다.
해결책으로 첫 번째 메시지가 저장되는 시점에 채팅방을 생성하는 방식도 고려했으나, 이 경우 프론트와 백엔드 모두에서의 구현 복잡성, 메시지 전송 실패 시의 예외 처리 난이도 등을 고려해서 채택하지 않기로 했습니다.
최종적으로는메시지가 하나도 없고, 참여자 전원이 오프라인이며, 일정 시간(예: 1시간) 이상 아무 활동이 없는 채팅방을 주기적으로 정리하는 클린업 프로세스를 추가해서 더미 방이 쌓이는 문제를 해결하기로 결정했습니다. -
메시지의 중복 처리 및 전파 성공 및 실패
메시지 전송 과정에서 다양한 원인으로 인해 중복 메시지가 발생할 수 있습니다. 사용자의 네트워크가 끊겼다 다시 연결되는 경우 클라이언트는 동일한 메시지를 재전송할 수 있으며, kafka와 같은 메시지 브로커에서도 중복 소비가 발생할 수 있습니다. 이러한 상황이 제대로 처리되지 않으면, 동일한 메시지가 여러 번 저장되거나 사용자에게 중복 전파되어 사용자 경험에 혼란을 주고, 데이터 정합성에도 문제가 생길 수 있습니다.
이 문제를 해결하기 위해 메시지 처리 전 과정을멱등성을 보장하게 설계합니다. 우선, 클라이언트는 메시지를 전송할 때마다 고유한client_message_id를 생성해 함께 전송합니다. 이 id는 메시지의 논리적 고유성을 나타내며, 재전송이 발생해도 동일한 메시지로 인식되게 합니다.
websocket server는 메시지를 단순히 kafka로 라우팅만 하고, 중복 여부 판단과 실제 저장은 message worker에서 처리합니다.
message worker는room_id + client_message_id를 기준으로 db에서 메시지의 중복 여부를 확인하고, 신규 메시지인 경우에만 저장한 후, redis 또는 NATS pub/sub 을 통해 실시간 전파합니다.
또한 메시지에는delivery_status필드를 두고, 전파 성공 여부를pending → delivered 또는 failed로 상태 관리합니다. 만약 websocket 연결이 끊어졌거나 푸시 실패가 발생하면,kafka의 재시도 토픽을 통해 해당 메시지를 지연 재처리할 수 있도록 설계합니다. -
읽음 처리 모델 설계
실시간 채팅 시스템에서는 사용자의 읽음 여부를 정확하게 추적하는 기능이 매우 중요합니다.
1:1 또는 그룹 채팅 모두에서 사용자가 어디까지 메시지를 읽었는지에 따라 사용자 경험(UX)과 프론트엔드 동작에 직접적인 영향을 미치기 때문입니다. 하지만 다음과 같은 문제들이 존재합니다.
- 메시지가 수신되었더라도, 수신자가 실제로 해당 메시지를 읽었는지 여부를 서버는 즉시 알 수 없습니다.
- 읽음 여부를 바로 데이터베이스에 기록할 경우, 대규모 트래픽이 발생하면 DB 부하가 집중되어 성능 저하가 발생할 수 있습니다.
- 읽음 정보가 부정확할 경우, 사용자에게 읽지 않은 메시지 알림이 잘못 표시되는 UX 문제가 발생할 수 있습니다.이러한 문제를 해결하기 위해, 우리는
사용자별 읽음 오프셋(read offset)개념을 도입합니다.
각 사용자가 각 채팅방에서 마지막으로 읽은 메시지의 ID 또는 시점을 별도로 기록하는 방식입니다.websocket 서버는 클라이언트에게 메시지를 전파하지만, 클라이언트는 메시지를 수신했다고 해서 바로 읽음 처리를 하지 않습니다.
실제 사용자가 해당 메시지를 화면에 표시하고 확인한 순간에만 읽음 처리를 진행합니다.
이 방식은 메시지가 수신되었더라도 사용자가 실제로 읽지 않은 경우를 정확히 구분할 수 있어, 읽지 않은 메시지 알림이 잘못 표시되는 문제를 효과적으로 방지할 수 있습니다.사용자가 채팅방을 열어 메시지가 화면에 노출되는 순간, 프론트엔드는 websocket을 통해
읽음 상태(read_ack)메시지를 서버로 전송합니다. 서버는 이를 수신하고, 사용자의 last_read_message_id를 저장합니다.시스템에서 읽음 오프셋의 조회 및 기록은 매우 빈번하게 발생합니다. 또한 본 시스템은 글로벌 사용자를 고려한 고성능 설계를 목표로 하고 있기 때문에, 성능과 확장성을 확보하기 위해 redis + cassandra 조합을 사용합니다.
- read service는 읽음 상태를 1차적으로 redis에 저장하여 초고속 처리를 보장합니다.
- 이후 비동기 처리로 주기적으로 redis의 데이터를 cassandra에 반영하여 영구 저장합니다.
- 읽음 오프셋 조회 시에는 메모리 기반 초고속 읽기 성능을 제공하는 redis에서 처리합니다.
- 오래된 redis 데이터는 TTL 설정을 통해 주기적으로 자동 삭제하여 리소스를 관리합니다.
- 또한, 클라이언트가 읽음 갱신(read_ack)을 보낼 때마다 redis를 즉시 업데이트하여,
조회시에 항상 최신의 읽음 정보를 유지하도록 설계합니다.
-
멀티 디바이스 동시 접속 동기화
실시간 채팅 시스템에서는 하나의 사용자가 모바일, 웹, 태블릿 등 여러 디바이스에서 동시에 채팅에 접속하는 경우가 빈번하게 발생합니다.
이때, 모든 디바이스 간 상태가 일관되지 않으면 사용자 경험(UX)에 심각한 문제가 발생할 수 있습니다.발생할 수 있는 문제점
- 모바일에서는 메시지를 읽었지만, 웹에서는 읽음 표시가 반영되지 않는 문제
- 모바일에서는 메시지 전송 성공(ack)이 되었지만, 웹에서는 실패로 남아있는 문제
- 채팅방 입장/퇴장, 읽음 처리 등 채팅방 UI 상태가 디바이스마다 불일치하는 문제이러한 동기화 실패는 사용자 혼란을 초래하고, 채팅 시스템의 신뢰성과 일관성을 저하시킬 수 있습니다.
이러한 문제를 해결하기 위해,user_id 단위 presence 그룹을 redis로 통합 관리하고, websocket 서버는 메모리 기반으로 세션을 관리하며, redis Pub/Sub 이벤트를 통해 모든 디바이스에 실시간으로 상태를 일관성 있게 전파하는 구조를 설계합니다.presence 통합 관리
- 동일한 user_id로 접속한 모든 디바이스(웹, 모바일 등)를 하나의 presence 그룹으로 관리합니다.
- 사용자의 presence(접속 상태)는 redis에 통합 저장합니다.
- 예시: user:online:{user_id} 키를 사용하여 접속 여부 및 소켓 수를 기록합니다.
- 여러 소켓 연결이 동시에 존재할 수 있으며, 접속 수(socket count) 관리도 함께 수행합니다.websocket 서버 메모리 기반 세션 관리
- 각 websocket 서버는 자체 메모리에 다음과 같은 구조로 세션을 관리합니다.
- 예시: Map<user_id, Set<socket_id>>
- 서버는 메모리에서 user_id별 소켓 목록을 조회하여, 빠르게 다중 소켓에 메시지를 전파할 수 있습니다.redis pub/sub을 통한 서버 간 이벤트 동기화
- 모든 websocket 서버는 redis pub/sub 채널을 구독합니다.
- message worker 또는 다른 서비스는 redis pub 채널에 이벤트를 publish합니다.
- websocket 서버는 수신한 메시지의 user_id를 확인한 뒤
- 메모리에 등록된 소켓들을 찾아 해당 소켓을 통해 각 디바이스로 메시지 또는 읽음 상태를 실시간으로 전파합니다.
-
그룹 채팅 확장 시 고려사항과 문제점 및 해결방안
5-1. 수신 대상이 N명으로 확장
- 1:1 채팅에서는 단일 수신자만 처리하면 되지만, 그룹 채팅에서는 수백~수천 명에게 동시에 메시지를 전파해야 합니다.
- 단순 반복 처리 시, 서버 부하와 네트워크 병목이 심각해질 수 있습니다.
5-1. 해결방안
- presence를 조회하여 현재 온라인 상태인 사용자만 선별하여 실시간 전파합니다.
- 오프라인 사용자는 kafka를 통해 push service로 전환하여, 모바일 푸시 알림으로 전파합니다.5-2. presence 조회 트래픽 증가
- 수신 대상이 많을 경우, 각 사용자의 온라인/오프라인 상태를 개별 redis 조회하면 redis 부하가 급격히 증가할 수 있습니다.
- 예를 들어 1,000명 그룹이면 1,000번 조회가 발생할 수 있습니다.
5-2. 해결방안
- redis MGET 명령어를 사용하여, 여러 user_id의 presence 상태를 한 번에 일괄 조회(batch get) 처리합니다.
- 일괄 조회 후, 온라인인 사용자만 필터링하여 전파합니다.5-3. 메시지 전파 최적화가 필요합니다.
- 모든 websocket 서버가 Pub/Sub 메시지를 수신하지만, 실제 연결된 소켓이 없는 서버도 같은 메시지를 수신/처리하게 되어 오버헤드가 발생할 수 있습니다.
5-3. 해결방안
- websocket 서버는 메시지를 수신한 뒤, 자신의 서버 메모리상에 연결된 소켓(user_id) 이 있는 경우에만 해당 소켓에 전송합니다.
- 소켓이 없는 경우는 메시지를 무시하여 서버 리소스를 절약합니다.5-4. 읽음 상태 관리 복잡성 증가
- 1:1 채팅은 간단한 읽음 여부 관리로 충분했지만, 그룹 채팅은 사용자별로 읽은 메시지 ID를 모두 관리해야 하므로 데이터 양과 복잡성이 기하급수적으로 늘어납니다.
5-4. 해결방안
- 사용자별 last_read_message_id를 관리합니다.
- 읽음 오프셋 데이터는 1차로 redis에 저장하여 고속 응답성을 보장하고, 이후 비동기적으로 cassandra에 영구 저장합니다.
- redis에는 TTL을 적용하여, 오래된 읽음 데이터는 자동 정리되도록 설계합니다.
7. 데이터베이스 설계
데이터베이스를 설계합니다.
RDBMS (PostgreSQL) 영역, NoSQL (Cassandra) 영역, In-memory (Redis) 영역을 구분해서 진행합니다.
서비스에 필요한 최소한의 설계로 진행합니다.
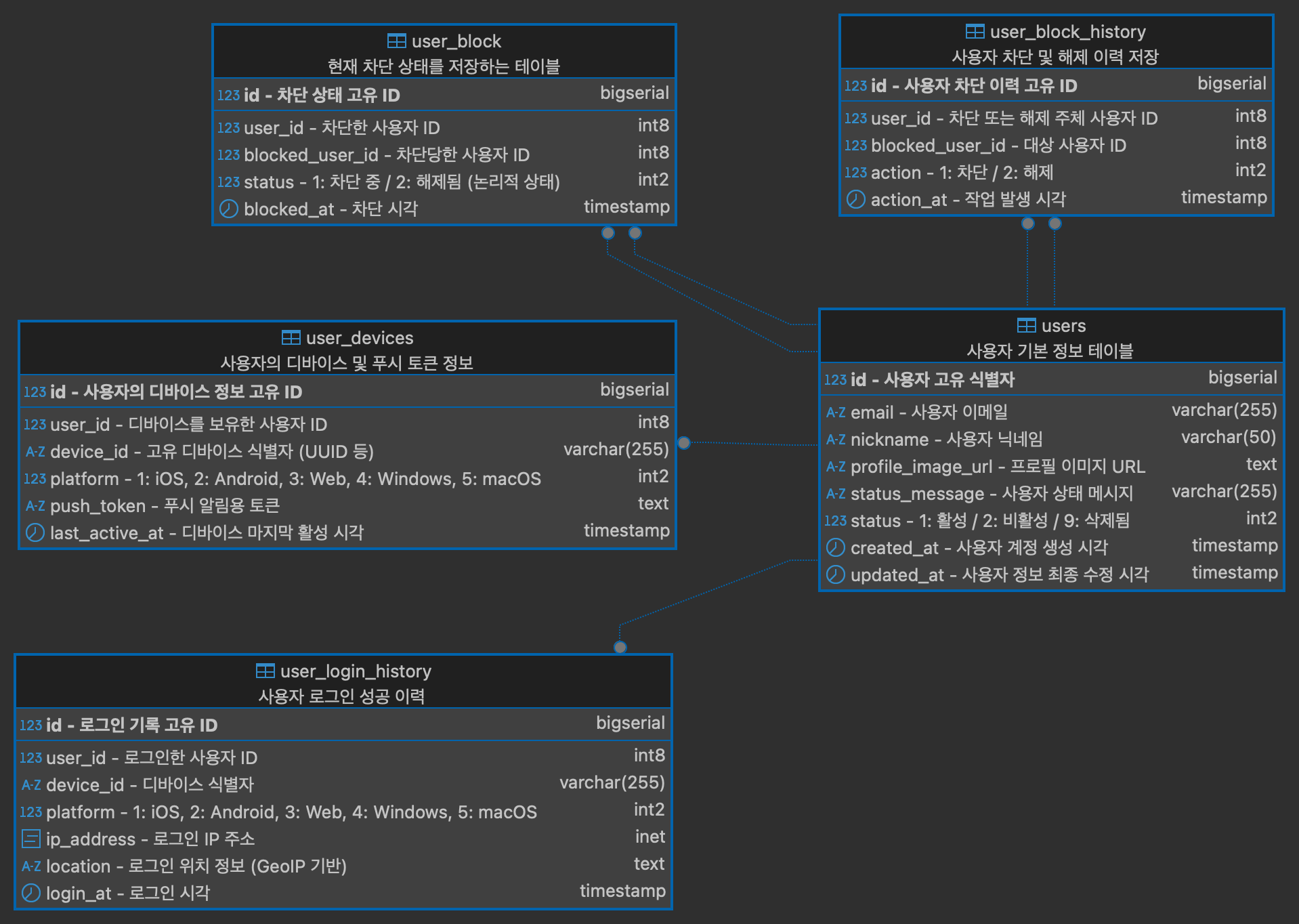
7-1. user_db - RDBMS (PostgreSQL)
1. 사용자 기본 정보 테이블을 중심으로, 사용자의 디바이스 및 푸시 토큰을 관리하는 테이블, 로그인 성공 이력을 저장하는 테이블, 현재 차단 상태를 기록하는 테이블, 그리고 차단 및 해제 이력을 저장하는 테이블로 구성하였습니다.
2. 향후 알림 설정, 관심사 태그 등 사용자 개인화 기능을 위한 테이블도 확장 가능하도록 고려했습니다.
3. user_db는 사용자 프로필, 디바이스 정보, 로그인 이력, 차단 정보 등 사용자 엔티티 확장을 담당하며, auth_db와 역할을 명확히 분리하여 설계되었습니다.
4. 인증 및 로그인 처리는 별도의 auth_db에서 수행되며, 이는 마이크로서비스 아키텍처의 책임 분리 원칙을 따르기 위함입니다.
5. 데이터 삭제는 물리적 삭제 대신 status 컬럼을 활용한 논리 삭제 방식을 채택하였습니다.
6. 논리 삭제를 도입한 이유는 데이터 복구, 감사 로그 유지 등 향후 운용 및 확장에 유리하기 때문입니다.
7. status 값은 문자열 대신 숫자형 정수로 구성하여 저장 효율성과 검색 성능을 높였습니다.
8. 사용자 차단 기능은 현재 상태를 user_block 테이블에서 관리하고, 차단/해제의 모든 이력은 user_block_history에 기록하여 정확한 행위 추적이 가능하도록 했습니다.
9. 푸시 알림 처리를 위해, user_devices 테이블에서 디바이스 단위의 푸시 토큰을 관리합니다.
10. 로그인 성공 시 user_login_history 테이블에 접속 플랫폼, IP, 위치 등의 정보를 저장하며, 이는 보안 분석이나 이상 로그인 탐지 등의 운영 및 보안 측면에서 활용될 수 있습니다.

7-2. auth_db - RDBMS (PostgreSQL)
1. auth_db는 로그인, 인증, 계정 연동 등 인증 관련 책임을 전담하는 서비스의 데이터베이스로 설계되었습니다.
2. 구성된 테이블은 각각 인증 계정 정보, 로그인 시도 이력, Refresh Token을 관리합니다.
3. auth_accounts는 provider + identifier 조합의 유일성 제약을 통해, 사용자가 일반 로그인 또는 소셜 로그인을 통해도 식별 가능하도록 설계되었습니다.
4. 비밀번호는 user_db가 아닌 auth_db 내 password_hash 컬럼에 저장되며, 보안 책임을 인증 서비스 내로 명확히 분리 하였습니다. 이를 통해 인증 방식 확장에도 유연하게 대응할 수 있습니다.
5. Refresh Token 관리는 별도의 refresh_tokens 테이블로 분리하여, 다중 디바이스 및 토큰 갱신 로직을 보다 명확히 관리하고 보안성을 강화했습니다.
6. 로그인 성공 여부 및 시도 이력은 auth_logs 테이블에 저장되며, 사용자 식별자, 시도 시간, IP, User-Agent 등 보안 모니터링 및 이상 탐지를 위한 핵심 데이터를 제공합니다.
7. auth_logs.user_id는 nullable로 설정되어, 로그인 실패 또는 비회원 시도 역시 모두 기록되어 인증 내역의 추적이 가능합니다.
8. provider는 문자열이 아닌 숫자형 값으로 관리되어 저장 효율성과 검색 성능을 고려했습니다.
9. 향후 확장 가능한 테이블로는 이메일 인증 토큰, 비밀번호 재설정 로그, 2FA(이중 인증) 코드 저장 테이블 등이 있습니다.
10. auth_db는 user_db와 물리적으로 분리된 독립 데이터베이스로, 테이블 간 외래키 관계 없이 user_id 필드로만 연결됩니다.
11. auth_db와 user_db는 직접적인 FK는 없지만 논리적으로 연결되어 있으므로, 서비스 간 API 호출을 통해 user_id의 존재 및 상태를 실시간 검증하고, 사용자 상태 변경(예: 정지, 탈퇴 등)은 Kafka 등의 메시지 브로커를 통해 이벤트로 발행하여 비동기 동기화 전략을 적용합니다.
데이터 삭제는 물리 삭제 대신 status 컬럼 기반의 논리적 삭제 방식을 채택하여 복구 및 감사 로깅에 유리하도록 설계했습니다.
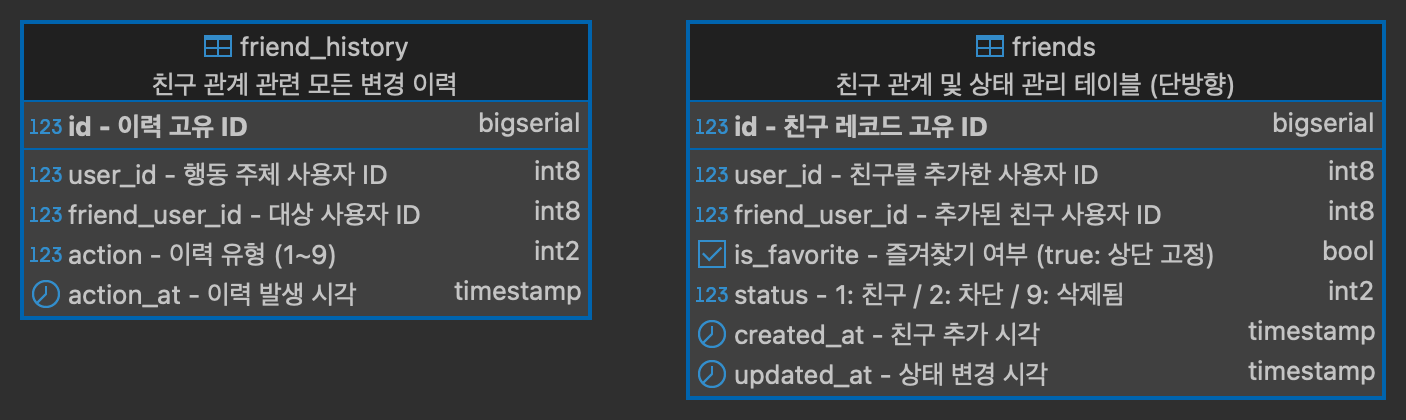
7-3. friend_db - RDBMS (PostgreSQL)
1. 역할 분리 원칙에 따라 friend_db는 친구 관계 및 관련 이력을 전담 관리하는 데이터베이스입니다. 사용자 정보는 별도의 서비스에서 관리하며, user_id를 통해 논리적으로만 연결됩니다. 데이터베이스 간 직접적인 외래키 관계는 설정하지 않습니다.
2. friends 테이블의 친구 관계는 1건으로 양방향 표현이 아닌, 단방향(한 쪽이 friend로 추가한 상태) 으로 저장합니다. 관계의 유연성과 관리 효율을 위해 단방향 모델을 채택했으며, 필요 시 쿼리로 쌍방 여부를 확인합니다.
또한 친구 요청/승인 없이 즉시 추가하는 구조로 설계했습니다. 따라서 복잡한 상태 전이 없이 status 값만으로 친구 추가 / 친구 삭제 / 친구 차단 상태를 구분합니다.
3. 차단 정책은 is_blocked = true로 처리되며, 물리 삭제 없이 논리적 상태로 유지합니다. 삭제 또한 논리적으로 구분하며, 복구 가능성과 이력 추적을 염두에 둡니다. 모든 상태 변경은 friend_history 테이블에 기록하여 변경 로그 및 감사 기록으로 활용됩니다.
4. 즐겨찾기를 고려한 is_favorite 필드를 통해 자주 대화하는 친구를 표시할 수 있습니다. 이는 사용자 편의성 및 UX 개선을 위한 필수 기능으로, 클라이언트에서 상단 고정에 활용됩니다.
5. 정렬 기준은 is_favorite = true인 친구가 먼저 표시되며, 그 외 친구는 nickname 또는 name 기준 가나다/ABC 순으로 정렬합니다.
별도의 sort_order 필드는 도입하지 않고 클라이언트 정렬 기준만으로 충분하다고 판단했습니다.
6. 변경 이력 관리의 경우 모든 친구 상태 변화는 friend_history에 저장됩니다. 이는 추후 추천 친구, 숨김 처리, 임시 차단 등 기능 확장을 위한 기반이 됩니다.
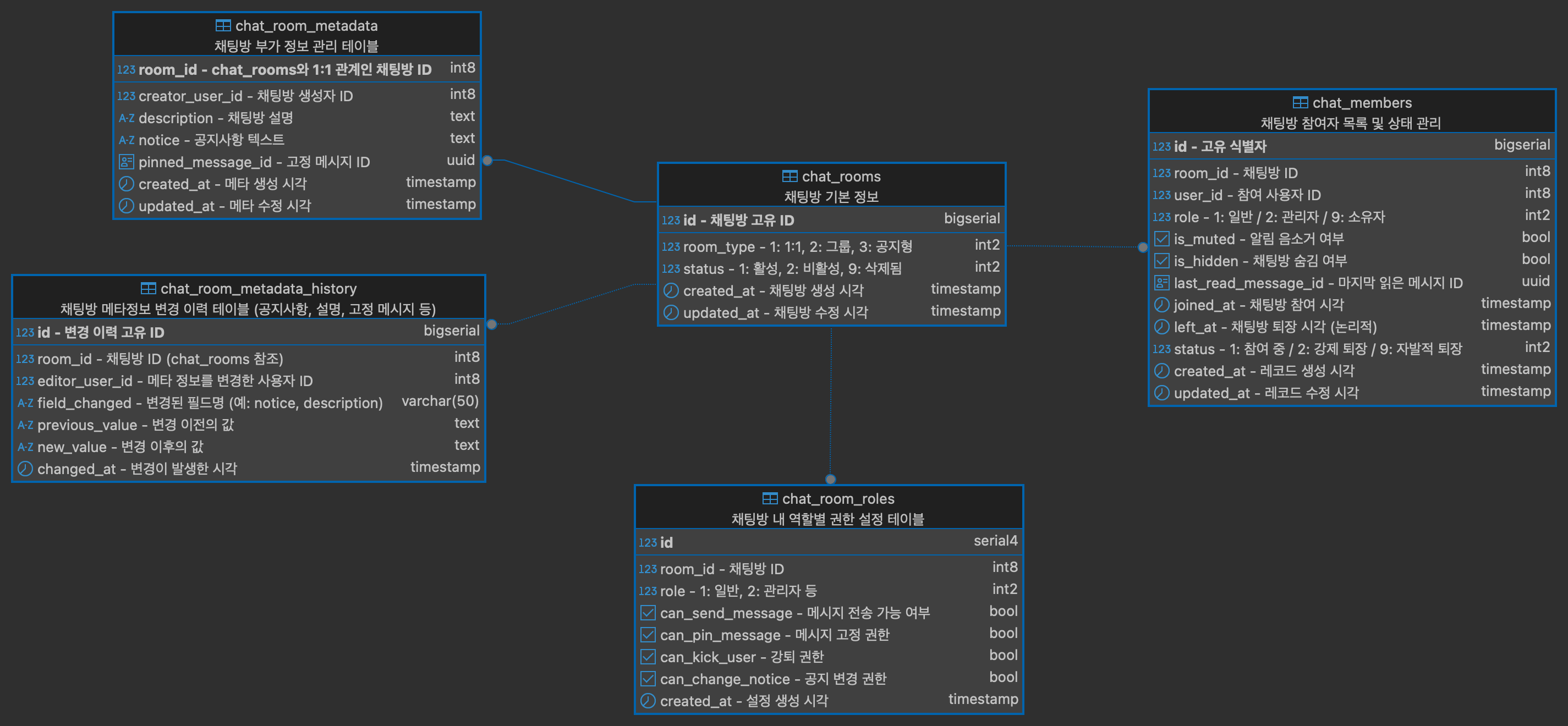
7-4. chat_db - RDBMS (PostgreSQL)
1. 역할 분리 원칙에 따라 chat_db는 채팅방 구조 및 참여자 상태, 권한 설정 등을 전담 관리하는 데이터베이스입니다. chat_rooms는 채팅방의 필수 정보를 담고, chat_room_metadata는 설명, 공지사항, 고정 메시지 등 부가 정보를 분리하여 관리합니다. 이로써 핵심 정보에 빠르게 접근할 수 있고, 메타 정보의 구조적 확장도 유연하게 설계됩니다.
2. chat_members는 채팅방 내 사용자 상태를 포괄적으로 관리합니다. 역할(role), 읽음 위치, 음소거/숨김 여부, 참여/퇴장 이력까지 포함하여, 실시간 참여 상태뿐 아니라 복귀 시점을 유연하게 처리할 수 있도록 논리 삭제(퇴장) 방식으로 구성했습니다.
3. 읽음 오프셋은 redis에 우선 저장하여 빠른 조회를 가능하게 하고, cassandra에 영속적으로 기록합니다. 이와 별도로 chat_members의 last_read_message_id도 주기적으로 업데이트하여 채팅방 리스트에서 빠른 UX 제공이 가능하도록 했습니다. 다만, 실시간성이 덜 중요하다고 가정하고 설계했으므로, 해당 필드 업데이트는 배치 또는 비동기로 처리하여 DB 부하를 분산시킵니다.
4. 채팅방 내 권한 관리는 chat_room_roles에서 정의됩니다. 역할별로 메시지 전송, 고정, 강퇴, 공지 변경 권한을 세분화해 저장하고, room_id + role 복합 유니크 인덱스를 두어 중복 정의를 방지합니다. 다양한 역할 정책 적용에 유연하게 대응할 수 있는 구조입니다.
5. 채팅방 유형 구분을 위해 room_type 필드를 두었으며, 1:1, 그룹, 공지형 등 다양한 확장 가능성을 고려했습니다. 이후에도 오픈채팅, 채널, 공지방 등 유형이 추가될 때 무리 없이 적용 가능한 구조입니다.
6. 사용자 정보는 외부의 user_db에서 관리하며, FK는 사용하지 않고 user_id만 논리적으로 참조합니다. 이는 마이크로서비스 간 결합도를 낮추기 위한 전략이며, 실제 사용자 상태 확인은 api 호출 또는 kafka 이벤트 방식으로 처리됩니다.
7. 모든 테이블은 물리 삭제 대신 status 또는 left_at을 활용한 논리 삭제 방식을 채택하여 이력 보존, 감사 추적, 데이터 복구가 가능한 안정적인 운영이 가능하도록 구성했습니다.
8. chat_room_metadata의 pinned_message_id 와 chat_members의 last_read_message_id는 메시지 저장소인 cassandra의 message id를 참조하므로, 해당 필드는 UUID 타입으로 설정하였습니다. 이로 인해 메시지와의 연결성을 유지합니다.
9. 공지사항 변경 등 주요 메타데이터 변경 이력을 관리하기 위해, chat_room_metadata_history 테이블을 구성하여 변경 추적 및 감사에 용이하게 했습니다.
10. 테이블 간 관계는 같은 DB 내에서만 외래키로 설정하며, 외부 DB 간(user_db 등) 관계는 설정하지 않았습니다. 이는 마이크로서비스의 독립성을 지키기 위한 전략으로, 필요 시 서비스 간 통신이나 이벤트로 연결합니다.
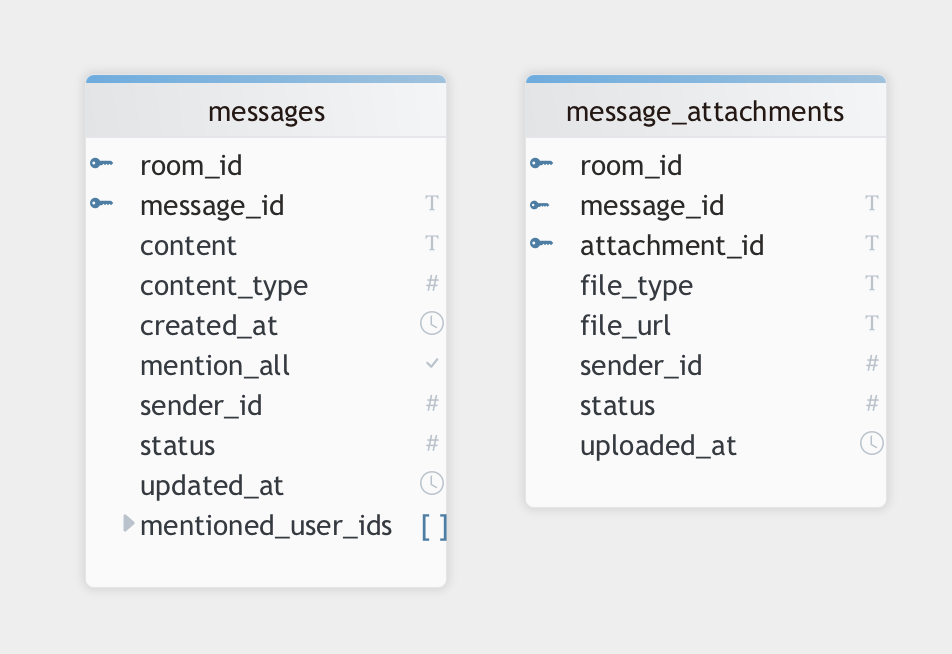
7-5. message_db - NoSQL (Cassandra)
1. 역할 분리 원칙에 따라 message_db는 실제 메시지 본문과 첨부파일 저장을 전담합니다. 채팅방 구조(chat_db), 사용자 정보(user_db), 읽음 오프셋(read_db)과는 분리되어 있으며, 메시징 처리에 집중한 스키마를 구성합니다.
2. room_id를 파티션 키로 사용하여 채팅방 단위로 데이터를 분산 저장합니다. 이는 cassandra의 분산 아키텍처 특성에 맞춰 노드 간 부하 분산 및 확장성을 보장합니다.
3. message_id는 TIMEUUID 타입을 사용하여 메시지 생성 시각 순으로 정렬이 가능하고, 클러스터링 키로 활용되어 최신 메시지 조회 성능을 높입니다.
4. 멘션 기능은 별도 테이블로 분리하지 않고, mentioned_user_ids 리스트 컬럼을 통해 특정 사용자 멘션 (@user), mention_all boolean 필드를 통해 전체 멘션 (@all) 여부를 함께 구성하여, 구조 간결성과 조회 효율을 동시에 확보했습니다.
향후 데이터 분리가 필요한 경우 추후 message_mentions 테이블로 확장 가능합니다.
5. 첨부파일은 본문 메시지로부터 분리하여 message_attachments 테이블에 저장합니다. 1:N 구조를 고려한 설계로, 대용량 첨부 처리, 파일별 상태 관리, 저장 공간 최적화 등을 고려 했습니다.
본문 메시지에 리스트 컬럼으로 포함하지 않고 분리한 이유는 첨부파일 수(50~100개 이상)가 많아질 경우, 읽기/쓰기 성능 저하를 피하기 위함입니다.
6. message_attachments 테이블에는 sender_id(업로더 ID)를 함께 저장합니다. 이는 비정규화 구조이지만, 메시지 없이 첨부파일만 조회할 경우에도 사용자 정보가 필요하기 때문에 포함했습니다.
7. 메시지와 첨부파일 모두 status, created_at, updated_at 컬럼을 포함하여 논리 삭제, 버전 추적, 운영상 감사를 위한 기반 데이터를 제공합니다.
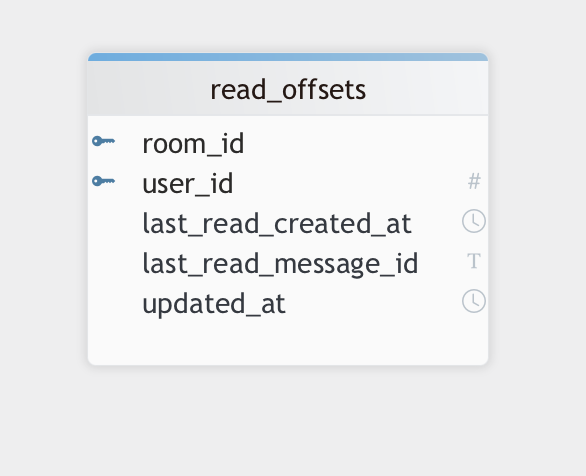
7-6. read_db - NoSQL (Cassandra) + In-memory (Redis)
1. 역할 분리 원칙에 따라 read_db는 사용자별 채팅방의 읽음 오프셋 관리를 전담 합니다.
실시간 메시지 소비 여부를 추적하는 책임을 이 마이크로서비스에 집중하여, 메시지 저장 또는 채팅방 구조와의 분리를 유지합니다.
2. redis + cassandra의 이중 저장 전략으로 성능과 영속성을 확보합니다.
redis는 초고속 읽기 성능을 위한 캐시로 사용하며, TTL(예: 7일)을 적용해 오래된 데이터는 자동으로 정리됩니다.
cassandra는 영구 저장소로 사용되어, 재접속 시에도 안정적인 복원이 가능합니다.
3. redis는 read:{room_id}:{user_id} 형식의 키 구조를 통해 빠르고 직관적인 조회가 가능합니다.
명확한 키 네이밍을 통해 특정 사용자나 채팅방 기준의 대량 조회도 손쉽게 확장할 수 있습니다.
4. cassandra는 파티션 키를 room_id, 클러스터링 키를 user_id로 설정해 채팅방 단위의 데이터 분산과 사용자 단위 정렬을 고려했습니다.
이 설계를 통해 확장성과 성능을 확보함과 동시에, 특정 방에서 사용자별 데이터를 효율적으로 조회할 수 있습니다.
5. 읽음 오프셋은 message_id(TIMEUUID)와 created_at을 함께 저장합니다.
cassandra의 시간 기반 정렬 특성을 활용하는 동시에, 클라이언트에는 사람이 인식 가능한 타임스탬프도 함께 제공합니다.
6. 데이터 업데이트는 최신 상태만 유지하는 upsert 방식으로 처리합니다.
사용자 행동이 자주 발생하는 읽음 처리 특성상, append 방식보다 파티션 크기감소, 조회의 간단성, 성능적인 이점 등을 고려했습니다.
7. 전체 처리 흐름은 kafka 기반 이벤트 드리븐 구조를 채택했습니다.
websocket 서버는 읽음 ack를 Kafka에 발행하고, read-service가 이를 소비해 redis와 cassandra를 갱신함으로써 책임이 명확히 분리됩니다.
고속 처리를 위한 '읽음 오프셋' - In-memory (Redis)
Key: read:{room_id}:{user_id}
Value: {
"last_read_message_id": "TIMEUUID",
"last_read_created_at": "timestamp"
}
TTL: 7일 등 (비활성 사용자 데이터 자동 정리)7-7. presence - In-memory (Redis)
7-7-1. 사용자 접속 정보
Key: presence:{user_id}
Type: SET
Value: {socket_id1, socket_id2, ...}
SADD presence:{user_id} socket_a
SADD presence:{user_id} socket_b- 해당 사용자가 현재 어떤 소켓들로 접속 중인지를 저장합니다.
- 한 명의 사용자가 여러 기기(브라우저, 앱 등)에서 동시에 접속 가능하도록 socket_id들을 저장합니다.
- 이 SET이 비어있으면 사용자는 오프라인으로 간주합니다
7-7-2. 소켓 생존 확인 (TTL 기반 유지)
Key: presence:socket:{socket_id}
Type: STRING
Value: "user_id"
TTL: 약 60초 (주기적 갱신 필요)
SET presence:socket:socket_a {user_id} EX 60
EXPIRE presence:socket:socket_a 60 // 주기적 갱신- 각 소켓의 실시간 생존 상태를 확인하기 위한 TTL 기반 키입니다.
- 클라이언트에서 주기적으로 ping 이벤트를 보내면 TTL이 갱신되어 만료되지 않도록 유지됩니다.
TTL이 만료되면 해당 socket_id는 죽은 것으로 간주하고, presence:{user_id} SET에서 자동으로 제거됩니다. - 제거 처리는 consumer나 별도 정리 로직이 담당합니다.
7-7-3. 사용자 상태 캐시
Key: presence:status:{user_id}
Type: STRING
Value: "online" / "offline"
SET presence:status:101 "online" EX 30- 그룹 채팅, 친구 목록, 알림 전송 등 대량 사용자 상태 조회에 최적화된 캐시 구조로, MGET 방식으로 수천 명의 상태를 빠르게 확인할 수 있습니다.
- TTL 기반으로 실시간성을 유지하며, websocket 서버가 주기적으로 상태를 갱신하고 만료 시 자동 정리됩니다.
- 실시간 SET 구조보다 응답 속도와 확장성 면에서 유리하여 필수적인 전략입니다.
7-7-4. 접속 로그 기록용 (선택적)
Key: presence:log:{user_id}
Type: LIST
Value: ["CONNECTED:timestamp", "DISCONNECTED:timestamp", ...]
LPUSH presence:log:{user_id} "CONNECTED:2024-05-26T14:33:00"- 접속/종료 로그를 임시 저장할 수 있습니다.
- 디버깅, 통계, 최종 접속 시간 확인 등의 보조 정보를 저장합니다.
1.역할 분리 원칙에 따라 presence는 실시간 사용자 접속 상태 관리를 전담합니다.
온라인/오프라인 상태 추적에 집중함으로써, 다른 마이크로서비스와의 책임을 명확히 구분했습니다.
2. 멀티 디바이스 환경을 고려하여 사용자별로 여러 소켓 연결을 동시에 관리할 수 있도록 설계했습니다.
각 연결은 고유한 socket_id로 구분되며, Redis의 SET 구조를 통해 효율적이고 중복 없는 추적이 가능합니다.
3. TTL 기반 생존 확인 방식을 도입하여 각 소켓 연결의 실시간 유효성을 보장합니다.
주기적인 ping으로 TTL을 연장하고, 만료된 연결은 consumer나 정리 로직이 자동으로 제거하여 불필요 리소스를 최소화합니다.
4. 접속 여부 판단과 상태 캐싱을 분리함으로써 실시간성과 대규모 조회 성능을 동시에 확보하려고 합니다.
presence:{user_id}는 실시간 상태 기준이며, presence:status:{user_id}는 친구 목록, 그룹 채팅 등 대량 상태 조회에 최적화된 캐시로 활용됩니다.
5. 접속/종료 이벤트는 선택적으로 LIST로 기록하여, 디버깅, 최종 접속 시간 확인, 통계 분석 등 부가 기능 확장에 대비할 수 있도록 했습니다.
로그 보존 및 활용 전략에 따라 유연하게 운영할 수 있는 구조입니다.
사용자별 방별 안 읽은 알림 목록 - In-memory (Redis)
Key: push:unread:{user_id}:{room_id}
Type: LIST
Value: [notification_id1, notification_id2, ..., notification_idN]
LPUSH push:unread:101:room-abc 9001
LPUSH push:unread:101:room-abc 9002
사용자별 방별 안 읽은 수 - In-memory (Redis)
Key: push:unread_count:{user_id}
Type: HASH
Field: {room_id}
Value: {unread_count}
HINCRBY push:unread_count:101 room-abc 1
HINCRBY push:unread_count:101 room-def 17-8. push_db - RDBMS (PostgreSQL) + In-memory (Redis)
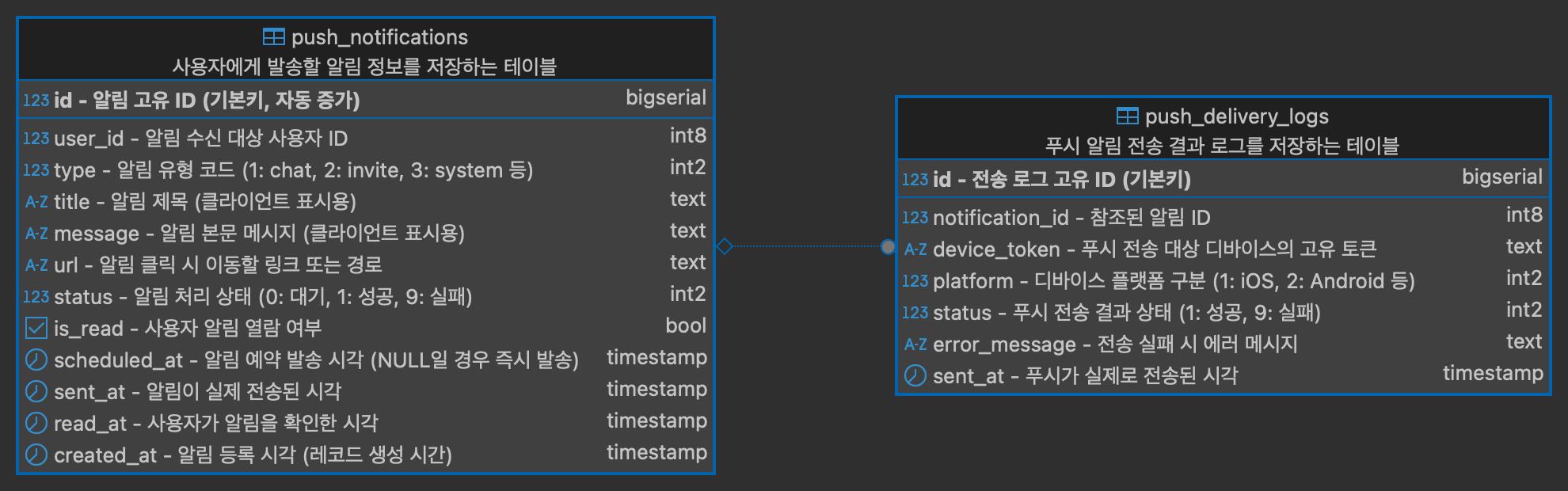
1. 역할 분리 원칙에 따라 Push 시스템은 사용자 알림 생성, 전송, 열람 추적을 전담합니다.
kafka 기반 비동기 메시징과 postgreSQL, redis를 조합하여 알림 전달과 후속 상태 관리까지 책임집니다.
2. 사용자 알림 데이터(push_notifications)와 전송 이력(push_delivery_logs)을 분리하여
비즈니스 이벤트와 실제 디바이스 전송 결과를 명확히 구분했습니다.
멀티 디바이스 환경에서 각 디바이스의 성공/실패 여부를 별도로 기록하여 장애 복구 및 통계 수집에 유리합니다.
3. 예약 발송(scheduled_at) 및 상태 추적(status, sent_at, read_at) 필드를 통해 전체 수명주기 관리를 지원합니다.
즉시 발송뿐 아니라 예약 기반 서비스(예: 일정 알림)에도 유연하게 대응할 수 있도록 설계했습니다.
4. 읽지 않은 알림은 Redis 구조(push:unread:{user_id}:{room_id}, push:unread_count:{user_id})를 활용하여 빠른 조회 성능을 보장합니다.
대규모 사용자 채팅방이나 친구 목록에서 알림 배지 표시를 빠르게 처리하며, MGET/HGET을 통해 효율적인 일괄 조회가 가능합니다.
5. 디바이스 토큰은 User Service와의 통신을 통해 전송 시점에 확보하며, 알림 본문 테이블에는 저장하지 않습니다.
전송 로그(push_delivery_logs)에만 전송된 토큰 및 플랫폼 정보를 기록하여 데이터 중복과 보안 이슈를 방지합니다.
6. redis는 postgreSQL과 병행하여 읽음 상태를 실시간 캐싱하며,
알림 열람 시에는 캐시에서 키를 제거하고 DB 상태를 동기화합니다.
TTL 정책을 통해 캐시가 지속적으로 쌓이지 않도록 자동 정리 기능도 함께 고려되었습니다.
8. API 스펙 정의
------------------> DB설계가 드디어 끝! 🙂
6월부턴 시간내기가 더 힘들것같지만 꾸준히.
작성중입니다. 🍩👨🏻💻
