Definition and Objective
CNN이란 Convolution Neural Network의 약자로, 합성곱 연산을 수행하는 모델을 의미한다.
이미지 데이터를 학습하는 데에 사용하는 것으로 익히 알려져 있다.
MLP로 이미지 데이터를 학습할 수도 있을 것이다.
하지만 이미지는 픽셀 값 뿐만 아니라 공간적 요소도 중요한 정보이기 때문에 공간적 정보까지 잃지 않고 학습시킬 수 있는 CNN이 일반적으로 더 좋은 성능을 보인다.
❓어떻게 공간적 정보를 유지할 수 있을까?
Convolution
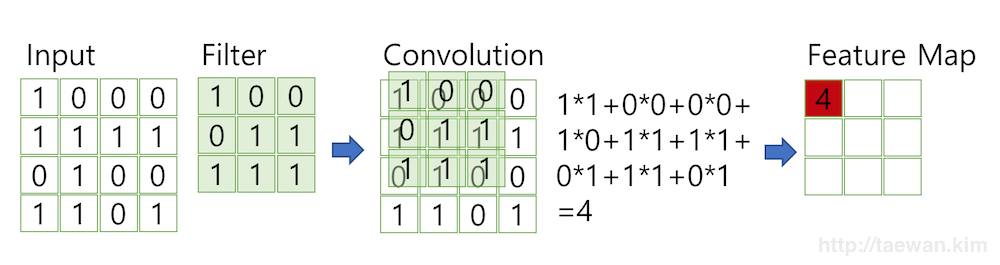
Input image에 대해 Filter가 일정 step size만큼씩 이동하면서 element wise 곱 연산을 수행하여 feature map을 뽑아낸다.
이렇게 하면 input의 픽셀 값 정보와 함께 공간 정보도 저장할 수 있게 된다.
feature map의 크기에 대한 공식은 아래와 같다.
size of output(feature map)
size of input image
padding size
kernel(=filter) size
stride(step size of kernel)
Padding은 convolution 층이 깊어짐에 따라 output이 점차 작아지면서 동반되는 정보 소실 문제를 막기 위해 input의 크기를 키워주기 위해 존재한다.
예를 들어서 위 Input에 동서남북 방향으로 한 겹씩 0으로 더 둘러쌓여 있다고 한다면 feature map의 크기는
로 기존에 padding이 없을 때보다 1이 더 커질 것이다.
History
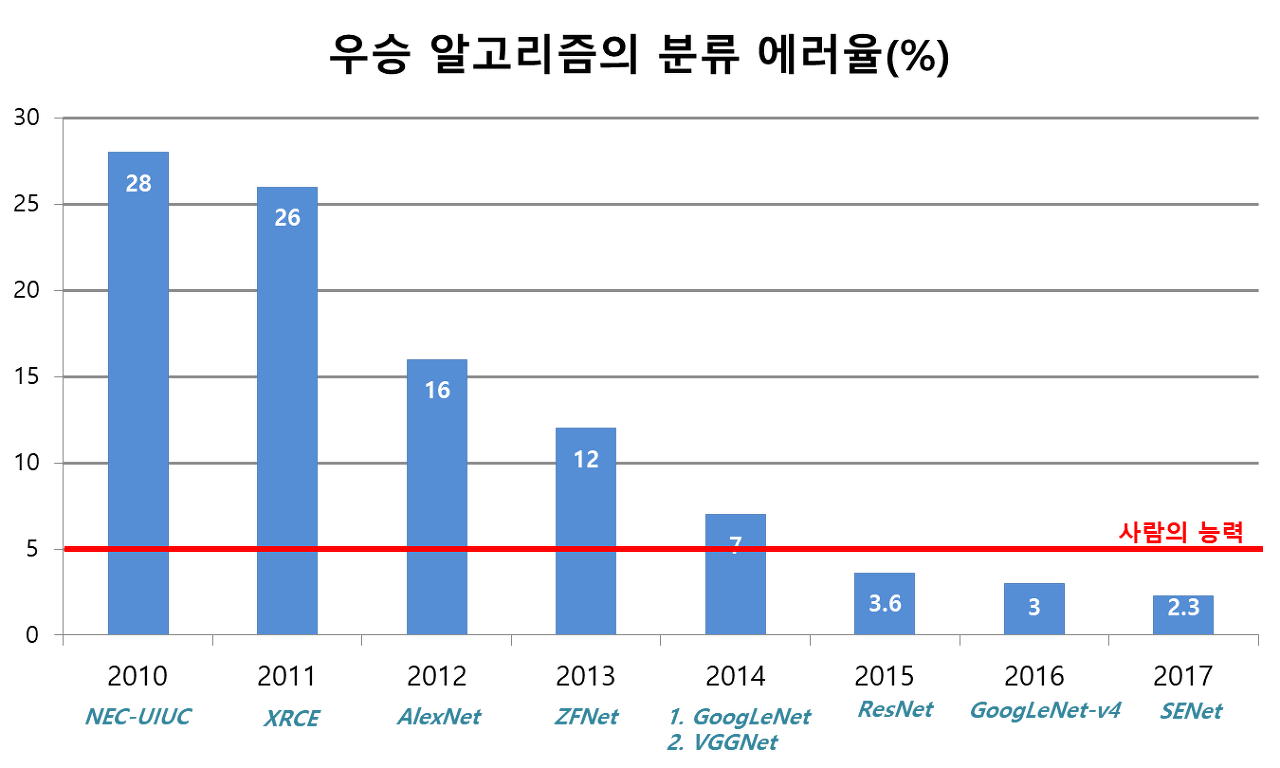
ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회는 이미지를 1000개의 클래스로
분류하는 것이 과제인 경진대회로, 이 대회에서 우승한 모델들은 Computer Vision 분야에서 큰 의미를 갖게 되었다.
시간이 지날 수록 더 높은 성능을 가지면서 더 적은 연산을 수행하는 모델들이 나오게 되었다.
-
2012, AlexNet
- 11x11, 5x5, 3x3, 총 3가지의 kernel size를 사용하였음
- 파라미터 개수 60M
-
2014, VGGNet
- 3x3 kernel size만 사용함으로써 같은 입력과 출력 사이즈 대비 더 적은 파라미터로 계산할 수 있음을 보임
- 파라미터 개수 140M
-
2014, GoogleNet
- 1x1 convolution을 이용하여 channel reduction을 함으로써 파라미터 개수를 줄임
- 파라미터 개수 4M -> Alexnet의
-
2015, ResNet
-
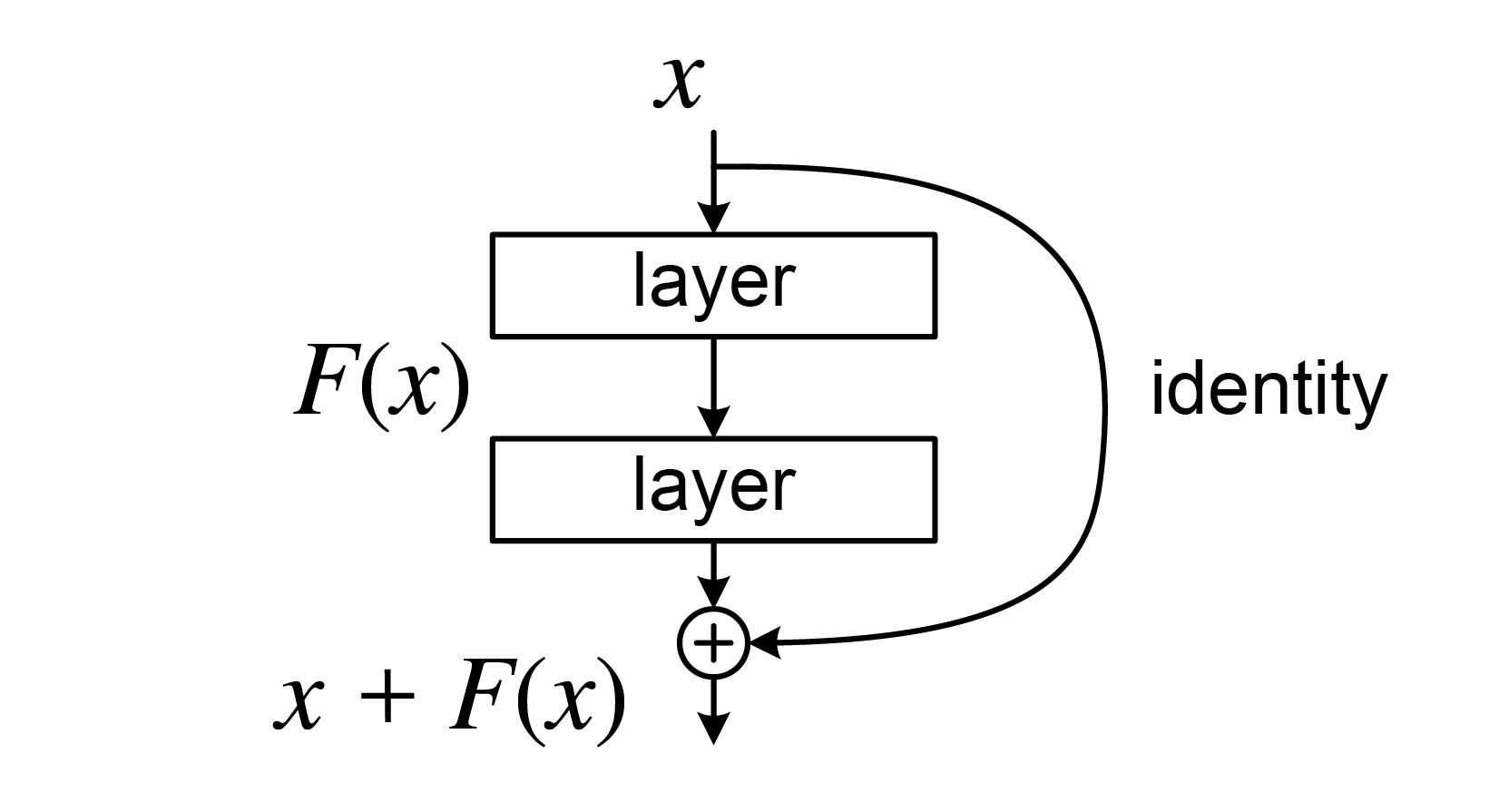
Identity Map
네트워크의 깊이가 깊어지고 파라미터의 개수가 증가하면 gradient vanishing 문제가 발생할 수 있다.
반복되는 back propagation으로 인해 gradient 값을 계속 곱해주다 보면 gradient 값은 점차 0으로 수렴하게 되고 파라미터는 업데이트가 거의 이루어지지 않기 때문이다.
Identity map은 네트워크로 받은 output을 덧셈으로 전달해줌으로써 gradient vanishing 문제를 완화한다.
-
-
2017, DenseNet
-
Concatenation
출력을 모든 레이어에 concatenate하여 정보의 소실을 최소화한다.
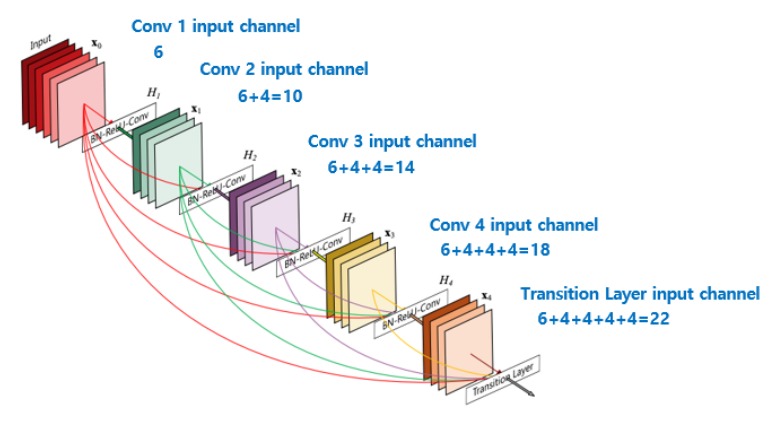
이 역시 resnet에서의 identity map과 유사한 것은 vanishing gradient 문제를 완화한다는 점이다.
다만 이러한 연산의 경우 channel의 수가 층이 깊어질수록 기하급수적으로 늘어나기 때문에
1x1 conv 연산도 함께 반복적으로 수행한다.
-
적용 분야
-
Semantic Segmentation
이미지 하나가 아니라 픽셀마다 레이블을 분류하는 문제이다.
최근에는 Fully Convolutional Network(FCN)을 주로 사용하는 추세이다.
기존 CNN의 경우 출력층에서 dense layer를 적용하지만 FCN은 Convolutional layer를 사용한다.
공간적 정보를 출력층까지 유지할 수 있기 때문이다.하지만 convolution 자체가 인풋의 정보를 요약하는 것이기 때문에 이미지 전체 크기 대비 큰 부분을 차지하는 경우 사실상 무의미한 정보를 굳이 분류하기도 한다. 또 작은 부분을 차지하는 객체의 경우, 정보가 소실되어 출력층에서 그 객체를 아예 인지할 수 없는 문제가 존재한다.
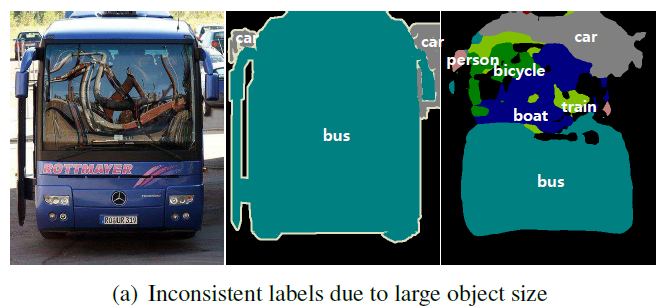

-
Deconvolution
위 문제를 해결하기 위해 나온 개념으로 단어 자체를 보면 역 합성곱 연산을 의미한다.
그렇지만 실제로 수학적으로 역 연산을 행하는 것은 아니다.input에 pooling을 추가함으로써 기존 input보다 더 큰 output(feature map)을 얻을 수 있도록 만드는 연산을 의미한다.
pytorch 내 코드로 구현을 할 때에는 torch.nn.ConvTranspose 모듈을 이용해 구현할 수 있다.
-
-
Object Detection
Semantic Segmentation과 동일하게 이미지 내의 객체를 인식하기 위한 것이지만 조금 차이가 있다.
Object Detection은 픽셀 전부를 분류한다기 보다는 객체를 bounding box로 탐지하는 것이 목적이다.
