
background
Transformer는 Sequential Data에 대한 예측 및 분류를 하기 위한 모델이다.
RNN도 Sequential Data를 예측하는 대표적 모델로 소개되고 있다.
하지만 순차적으로 입력 데이터를 처리하는 RNN의 특성 상 언어 데이터를 다룬다고 할 때 중간 중간 말이 빠지거나 순서가 밀리는 경우 이를 제대로 처리하기 어려워진다.
Transformer는 sequential 데이터를 병렬적으로 처리하여 위의 상황에도 맥락을 컴퓨터가 더 잘 이해할 수 있도록 만든다.
Architecture & Principle of Operation
-
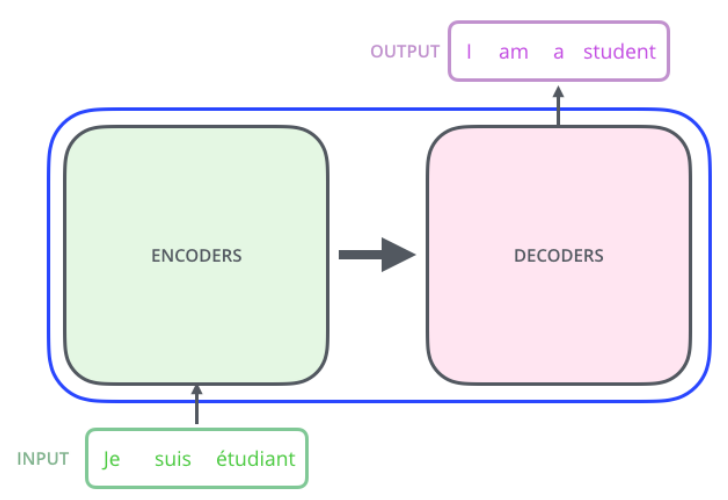
파란색 선 내부가 바로 transformer이다. transformer는 encoder 여러 개와 decoder 여러 개로 구성된다.
-
'Attention Is All You Need' 논문의 모델은 encoder 6개, decoder 6개로 정의하고 있다.
-
input이 주어졌을 때 영어로 번역하는 task를 수행한 결과를 출력한다.
-
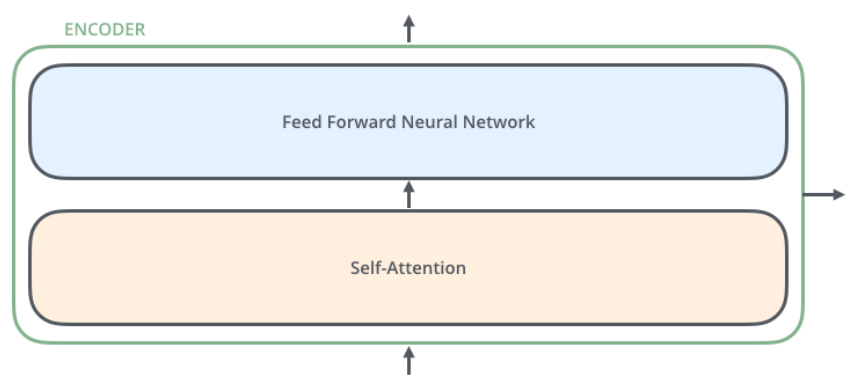
인코더 하나를 자세히 보면 두 가지 구조로 구분된다. input은 먼저 self attention layer를 거친 후 feed forward nn을 지나게 된다.
-
self attention
- input sequence 내의 단어들 간의 유사도를 계산한다.
- 문장 내에 n개의 단어가 있을 때 n개의 모든 단어 간 관계를 계산해야 하기 때문에 각 단어가 모두 서로 dependent하다.
-
feed forward neural network
- 일반적으로 알고있는 MLP network라고 볼 수 있다.
- 각 단어가 네트워크를 거칠 때 서로의 관계가 의미없기 때문에 independent하다. 그렇기 때문에 병렬적으로 처리할 수 있다.
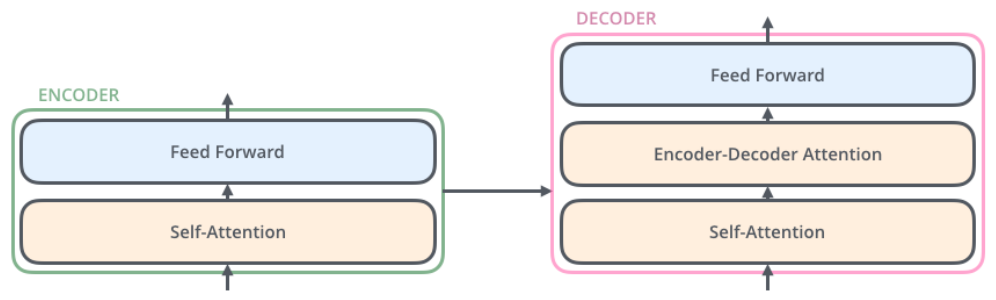
- 디코더는 인코더가 갖고 있던 두 구조를 모두 가지는데 그 사이에 encoder-decoder attention layer가 추가된 구조이다. encoder-decoder attention layer는 문장 내에 유사한 관계가 있는 부분에 디코더가 집중하도록 돕는 역할을 한다.
-
self-attention 연산 방법에 대해 자세히 설명하고자 한다.
-
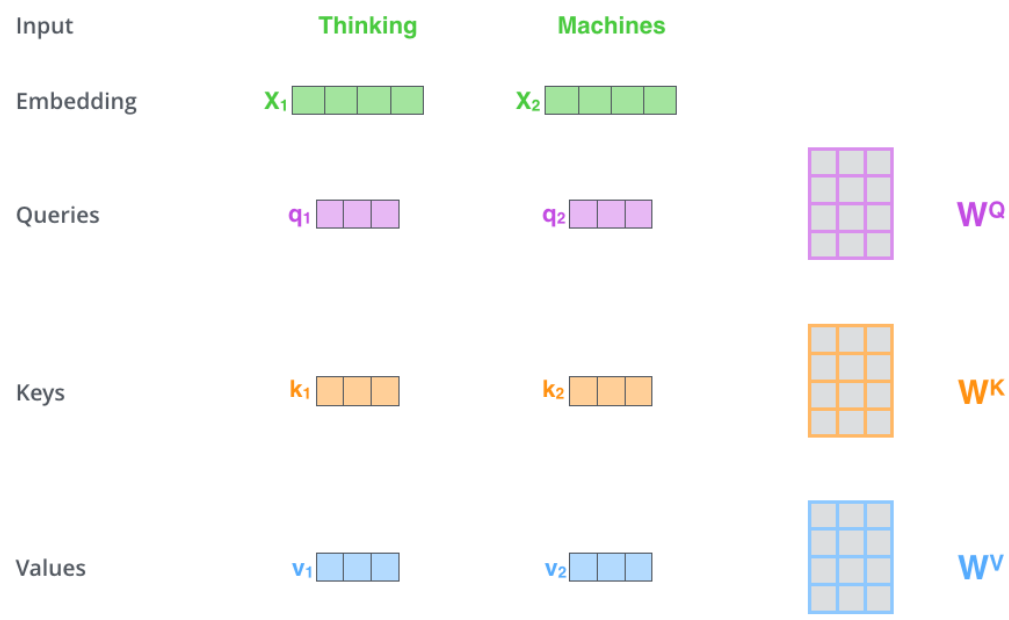
첫번째로, input에 대한 embedding vector x에 Wq, Wk, Wv 가중치 행렬을 각각 곱한 결과가 바로 q, k, v 벡터가 된다.
- 초기 q, k, v 벡터는 모두 같은 값을 가진 벡터로 통일한다.
-
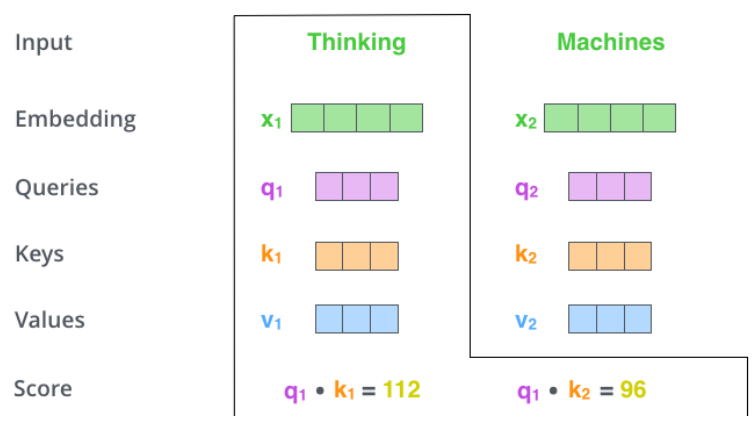
두 번째로, q, k를 내적하여 self-attention score를 계산한다.
-
주목해야 할 점
-
왜 q, k를 내적하는가?
둘 사이의 연관성을 계산해준다.
-
thinking이라는 단어의 q1에 대해서 모든 k1, k2, ..., kn까지 내적을 해줘야 한다. (모든 단어 사이의 관계를 확인하는 것이 최종 목적이기 때문)
-
-
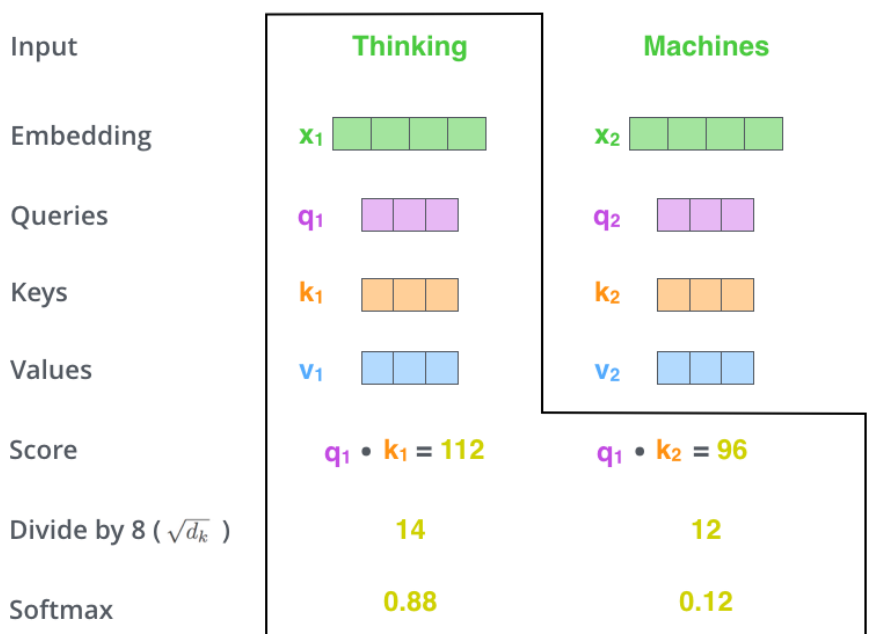
세 번째로, self-attention score를 의 루트 값으로 나누어 준다. 는 k 벡터의 차원이다.
-
네 번째로, 그렇게 나누어준 값에 softmax 함수를 적용한다. softmax 함수는 0~1 사이의 값으로 score를 정규화하는 역할을 한다.
- softmax score는 각 단어가 해당 위치에서 얼마나 잘 표현되고 있는지를 수치화해서 보여준다. 일반적으로는 위에서와 마찬가지로 실제 그 단어의 위치에서의 score가 가장 높겠지만 대명사 등 모호한 표현을 사용하게 되는 경우 다른 위치에서의 softmax score가 더 크게 나오기 때문에 해석에 용이해진다.
-
다섯 번째로, 각 v벡터에 softmax scrore를 곱해준다.
-
여섯 번째로, 업데이트된 v 벡터들을 더해서 feed forward nn으로 보낸다.
위 단계들을 보다 보면 드는 의문점이 있다.
순차적 데이터를 처리하는 것임에도 단어의 순서가 바꼈을 때 연산 결과에 있어서 영향이 없다는 것이다.
즉 순차적 정보를 반영하지 못한다는 이야기가 된다. 하지만 일반적으로 사람이 말을 할 때 끝까지 들어봐야 한다는 말처럼 어순은 언어에 있어서 아주 중요하다.
순차적 정보를 처리하기 위해 나온 개념이 바로 positional encoding이다.
-
positional encoding
각 단어의 임베딩 벡터 x에 단어의 위치 정보를 더해준다는 개념이다.
예를 들어,
I am a student.
라는 문장이 있을 때 I에 대한 임베딩 벡터 x = [1.5, 3, 2, 1] 라고 한다면,
위치 정보인 [1, 0, 0, 0]을
더해줌으로써 최종적으로 [2.5, 3, 2, 1]이라는 벡터 x를 사용하게 된다.다만 실제로 위에서처럼 위치 정보를 one hot으로 단순하게 표현하는 것은 아니다.
실제로는 위치 정보 역시 함수를 사용해 계산한다.
입력 문장에서의 임베딩 벡터의 위치 , 임베딩 백터 내의 차원의 인덱스 을 인풋으로 i가 짝수면 함수를 사용하고 홀수이면 함수를 사용한다.
