넘쳐나는 컨텐츠와 상품들 사이에서 유저의 취향을 반영한 제품을 추천해주는 시스템도 발전하고 있다.
추천 시스템은 유저 개개인에게 적합한 상품을 추천해주기 위해서 유저 정보, 상품 정보, 유저와 상품의 상호작용 정보를 활용한다.
개인의 취향을 반영해 좋아할만한 제품을 추천해주기도 하겠지만
일반적으로 익숙하게 받아들이고 신뢰가 가는 것은 '인기순'이기도 하다.
유튜브에서는 주로 좋아요 수가 많은 댓글을 상위에 노출하고 인기급상승동영상 순위에 드는 동영상들은 많은 사람들의 알고리즘에 노출되기도 한다.
커뮤니티 사이트에 올라오는 수많은 게시글 중에서도 조회수와 좋아요 수가 많은 게시글일수록 상위에 노출시킨다.
인기도 기반 추천
-
정의
가장 인기 있는 상품을 추천
-
척도
조회수, 평점, 좋아요 수, 댓글 수 등
어떤 스코어가 필요할까?
-
score formula
뉴스는 매일매일 업데이트되고 그날 그날의 소식이 중요하기 때문에 최신성이라는 속성이 가장 중요하다.
이를 반영한 공식은 아래와 같다.
조회수
(업로드 이후) 경과 시간from datetime import date, datetime, timedelta news_df = pd.DataFrame.from_dict({'뉴스': ['코로나 백신 접종', '월드컵 4강 진출', '세월호 참사', '촛불집회 발발', '셀트리온 치료제 출시'], '조회수': [500, 5000, 10000, 2000, 600], '업로드 날짜': ['2021-03-01', '2002-06-21', '2014-04-15', '2016-12-23', '2021-02-25']}) def score_formula(df, pageviews: str, upload_time: str, k: int, time_unit:str): ''' df: 데이터 프레임 pageviews: + 요소가 되는 컬럼명(ex. 조회수) upload_time: 게시물 게시 시점 컬럼명(ex. 업로드 시간) k: 추천받을 뉴스 개수 time_unit: 지정할 시간 단위(일: day, 시: hour, 분: minute) ''' current_time = datetime.now() time_elapsed = current_time - pd.to_datetime(df[upload_time]) if time_unit == 'day': time_elapsed = time_elapsed.dt.days elif time_unit == 'hour': time_elapsed = time_elapsed / pd.Timedelta(hours = 1) elif time_unit == 'minute': time_elapsed = time_elapsed / pd.Timedelta(minutes = 1) else: raise ValueError("time_unit can be chosen among ['day','hour','minute']") df['score'] = df[pageviews] - time_elapsed return df.sort_values(by='score', ascending = False)[:k] score_formula(news_df, '조회수', '업로드 날짜', 5, 'hour')
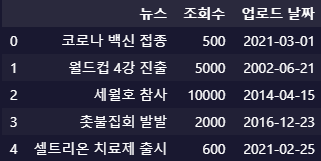
위의 news_df를 정렬한 결과
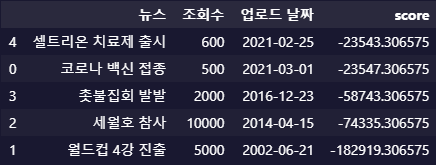
순서대로 추천해주는 결과가 나온다.
- hackers news formula
시간이 오래 지남에 따라 더 빠르게 점수를 낮게 하기 위한 아이디어로 나온 공식이다.
조회수
경과 시간
중력 상수(=1.8)
def hackers_news_formula(
df, pageviews:str, upload_time: str, k:int, time_unit: str):
current_time = datetime.now()
age = current_time - pd.to_datetime(df[upload_time])
if time_unit == 'day':
age = age.dt.days
elif time_unit == 'hour':
age = age / pd.Timedelta(hours = 1)
elif time_unit == 'minute':
age = age / pd.Timedelta(minutes = 1)
else:
raise ValueError("time_unit can be chosen among ['day','hour','minute']")
df['hacker_news_score'] = (df[pageviews]-1) / (age+2)**1.8
return df.sort_values(by = 'hacker_news_score', ascending = False)[:k]
hackers_news_formula(news_df, '조회수', '업로드 날짜', 5, 'minute')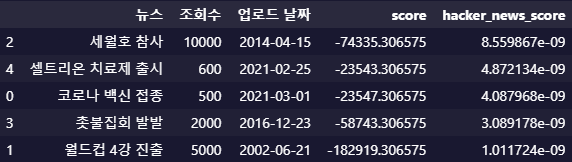
- reddit formula
reddit은 미국의 거대 커뮤니티 사이트이다.
커뮤니티 사이트에서는 게시글 추천에 있어서 인기도와 최신성이 모두 아주 중요하다.
ups: 좋아요 수
downs: 싫어요 수
seconds: 게시 시간(절대 시간을 의미함. 게시된 기간 x)
sign: 양수면 1, 음수면 -1, 0이면 0을 반환하는 함수
첫 번째 term의 경우 popularity를 의미한다.
로그가 씌워져 있는 이유는 게시글을 게시하고 난 이후 인기글이 된다고 했을 때 좋아요 수가 기하급수적으로 올라가기 때문에 변동이 아주 큰 인기도를 보정하기 위함이다.
두번째 term은 글이 포스팅된 절대 시간을 의미한다.
이때 절대 시간은 현재의 절대 시간에서 2005-12-08 07:46:43(unix timestamp로는 1134028003)을 뺀 값으로 정의하고 있다.
df = pd.DataFrame.from_dict({'게시글': [1,2,3],
'좋아요': [1000, 30000, 50],
'싫어요': [10, 30, 1],
'업로드 날짜': ['2023-11-20', '2023-11-24', '2023-11-27']})
def sign(x):
if x>0:
return 1
elif x<0:
return -1
else:
return 0
def reddit_formula(df, ups:str, downs:str, upload_time: str):
popularity = df[ups] - df[downs]
seconds = (pd.to_datetime(df[upload_time]) - datetime.utcfromtimestamp(1134028003)) / pd.Timedelta(seconds=1)
df['reddit_score'] = np.log10(popularity) + (popularity.apply(sign)*seconds) / 45000
return df.sort_values(by = 'reddit_score', ascending = False)
reddit_formula(df, '좋아요', '싫어요', '업로드 날짜')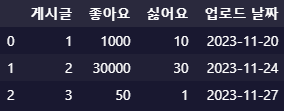
위를 reddit score 기반으로 정렬하면
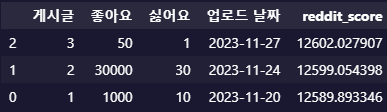
reddit score도 최신성이 잘 반영되는 것을 볼 수 있다.
