- 자연어 처리 전반적인 과정 실습
예제 문서 만들기
정답 데이터 만들기
텍스트 데이터 수치형태 변경
DTM
문제와 정답 만들기
데이터셋 나누기
머신러닝 모델 로딩
학습
예측
평가
트리 알고리즘 분석
라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'예제 문서
corpus = ["코로나 거리두기와 코로나 상생지원금 문의입니다.",
"지하철 운행시간과 지하철 요금 문의입니다.",
"지하철 승강장 문의입니다.",
"코로나 선별진료소 문의입니다.",
"버스 운행시간 문의입니다.",
"버스 터미널 위치 안내입니다.",
"코로나 거리두기 안내입니다.",
"택시 승강장 문의입니다."
]df = pd.DataFrame(corpus)
df.columns = ['문서']
df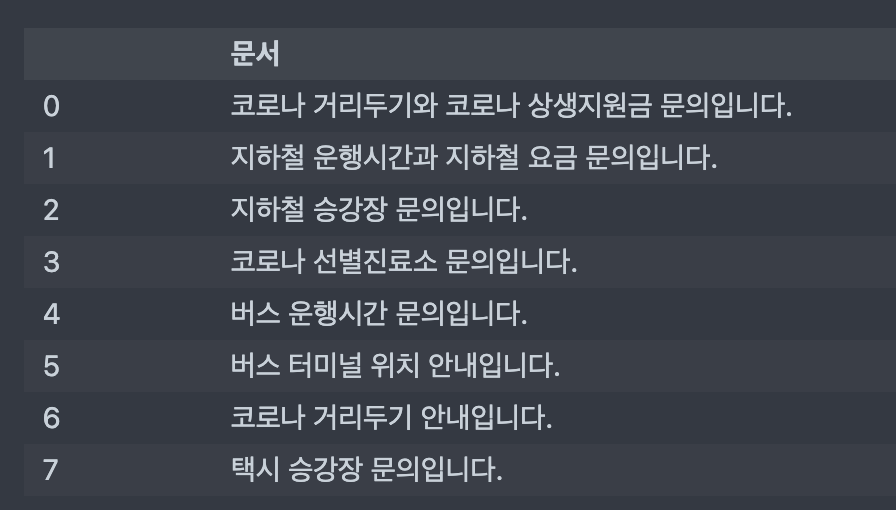
정답 데이터 만들기
- 코로나가 들어가면 '보건' 그 외는 '교통'으로 레이블링
df.loc[df['문서'].str.contains("코로나"), '분류'] = '보건'
df.loc[~df['문서'].str.contains("코로나"), '분류'] = '교통'
df
df['분류'].value_counts()
>>>>
교통 5
보건 3
Name: 분류, dtype: int64텍스트 데이터 수치 형태로 변경
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfvect.fit_transform(df['문서'])DTM
df_dtm = pd.DataFrame(dtm.toarray(), columns=tfidfvect.get_feature_names_out())
df_dtm
문제와 정답
X = df_dtm
y = df['분류']데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
>>>>
((6, 16), (2, 16), (6,), (2,))
y_train.value_counts()
>>>>
교통 4
보건 2
Name: 분류, dtype: int64
y_test.value_counts()
>>>>
교통 1
보건 1
Name: 분류, dtype: int64머신러닝 모델 로드
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)학습(훈련)
model.fit(X_train, y_train)예측
y_predict = model.predict(X_test)
y_predict
>>>>
array(['교통', '보건'], dtype=object)평가
- Accuracy 측정
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
>>>>
1.0
# crosstab 으로 confusion matrix
pd.crosstab(y_test, y_predict)
트리 알고리즘 분석
- 의사결정나무 시각화
from sklearn.tree import export_text
print(export_text(model, feature_names=X.columns.tolist()))
>>>>
|--- 코로나 <= 0.24
| |--- class: 교통
|--- 코로나 > 0.24
| |--- class: 보건
# plot_tree 시각화
from sklearn.tree import plot_tree
tree = plot_tree(model, filled=True,
feature_names = X.columns.tolist())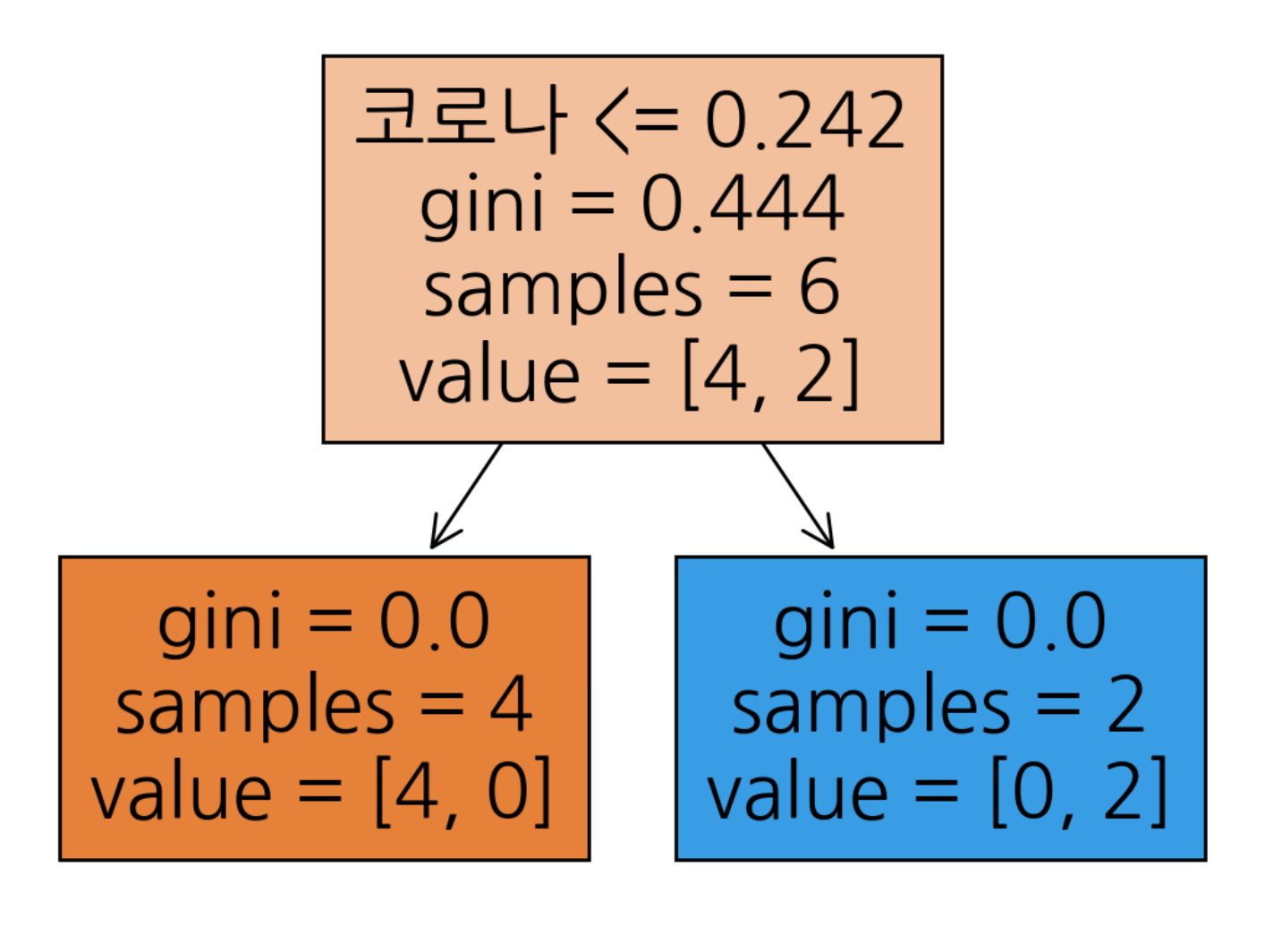

Ⓓ🅰️🅣🄰 ♡♥︎