NLP
- 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일
- 자연어? 우리가 일상 생활에서 사용하는 언어
- 기계에게 인간의 언어를 이해시키는 인공지능의 한 분야
✅ 할 수 있는 일 - 음성인식, 내용요약, 번역
- 사용자의 감성 분석
- 텍스트 분류 작업 (스팸메일 분류, 뉴스 기사 카테고리 분류)
- 질의 응답 시스템, 챗봇
머신러닝 활용한 자연어 분류 과정
- 데이터 로드
- 텍스트 데이터 전처리
- 기계가 text를 이해할 수 있도록 정제하여 신호와 소음을 구분 (불용어 stopword)
- 텍스트 데이터 벡터화 (one-hot-encoding - BOW, TF-IDF)
- 데이터 나누기
- 학습세트 / 예측세트
- 모델, 학습, 예측, 평가
정규 표현식(Regular Expression : re)
import re- [A-Za-z0-9] : 영숫자
- [A-Za-z0-9_] : 영숫자 + “_”
- [^A-Za-z0-9] : 낱말이 아닌 문자]
- [ ₩t] : 공백과 탭
- | 수직선은 여러 항목 중 선택을 하기 위해 구분 gray|grey -> gray 또는 grey 일치
- [^] : not (부정)
- ^ : 처음
토큰화(Tokenization)
: text 조각을 톸는이라고 하는 더 작은 단위로 분리하는 방법
- 패턴을 찾는데 매우 유용하며 형태소 분석 및 표제어를 위한 기본 단계로 간주
import nltk
sent = """At eight 0'clock on Thursday morning Arhur didn't feel very good."""
token = nltk.word_tokenize(sent)
token
>>>> ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']불용어 (stopword)
- 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는 데 도움이 안되는 단어
- 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업이 필요
✅ 불용어 제거 추천
언어 분류, 스팸 필터링, 캡션 생성, 자동 태그, 생성, 감정 분석 또는 텍스트 분류와 관련된 작업
✅ 불용어 유지
기계 번역, 질문 답변 문재, 텍스트 요약, 언어 모델링 중 하나인 경우 이러한 응용 프로그램의 중요한 부분이므로 유지
✅ Python에서 불용어 제거 방법
: NLTK, SpaCy, Gensim 등 라이브러리 사용
BOW : Bag of Words
: 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- 가장 간단하지만 효과적이라 널리쓰이는 방법
- 단어의 순서가 완전히 무시된다는 단점
N-gram 언어 모델
: 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법 사용
- n-gram에서의 n의 의미: 단어의 수
n-gram : 동물원에 버스를 타고 갔다.
uni-gram : ['동물원에','버스를', '타고', '갔다']
bi-gram : ['동물원에 버스를', '버스를 타고', '타고 갔다.']
DTM : Document-Term Matrix
- 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
- 쉽게 생각하면 각 문서에 대한 BOW를 하나의 행렬로 만든 것
✅ 너무 희귀한 단어를 제외하는 효과가 있는 것은 무엇을까요? min_df
✅ 너무 많이 등장하는 불용어를 제외하는 효과가 있는 것은 무엇일까요? max_df
✅ BOW를 사용하다보면 앞뒤 맥락을 고려하지 않는 단점이 있습니다. 이것을 해결하기 위한 것은 무엇일까요? ngram_range
✅ 단어를 너무 많이 사용해서 dtm 가 너무 커지는 것을 방지하기 위해 최대 단어를 제한하는 것은 무엇일까요? max_features
TF-IDF
: 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지 나타내는 통계적 수치.
문서의 핵심어 추출, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용.
✅ TF : 단어 빈도, 특정한 단어가 문서 내에 얼마나 자주 등장하는 지 나타내는 값
- 이 값이 높을수록 문서에서 중요하다고 생각할 수 있음
✅ DF : 문서 빈도, 특정 단어가 등장한 문서의 수
- 단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미
✅ TF-IDF : 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단
- 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
- TF-IDF 값이 낮으면 중요도가 낮으며, TF-IDF 값이 크면 중요도가 큰 것
- 정보검색과 텍스트 마이닝에서 이용하는 가중치
- 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
- 문서의 핵심어를 추출하거나, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 용도로 사용
➡️ 사이킷런은 TF-IDF를 자동 계산해주는 TfidfVectorizer
실습
단어 벡터화 하기
https://scikit-learn.org/stable/modules/feature_extraction.html
라이브러리 로드
import warnings
warnings.filterwarning('ignore')
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 시각화를 위한 한글폰트 설정
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'분석할 문서
corpus = ["코로나 거리두기와 코로나 상생지원금 문의입니다.",
"지하철 운행시간과 지하철 요금 문의입니다.",
"지하철 승강장 문의입니다.",
"코로나 선별진료소 문의입니다.",
"버스 운행시간 문의입니다.",
"버스 터미널 위치 안내입니다.",
"코로나 거리두기 안내입니다.",
"택시 승강장 문의입니다."
]CountVectorizer
: sklearn에서 제공하는 BOW를 만들 수 있는 방법
- 텍스트 문서 모음을 토큰 수의 행렬로 변환
- 단어들의 카운트(출현빈도)로 여러 문서들을 벡터화

from sklearn.feature_extraction.text import CountVectorizerfit, transform, fit_transform
- fit : 원시 문서에 있는 모든 토큰의 어휘 사전을 배운다.
- transform : 문서를 문서 용어 매트릭스로 변환. 숫자형태로 변경
- fit_transform : 어휘 사전을 배우고 문서 용어 매트릭스로 반환
📌주의 !!
단, fit_transform 은 학습데이터만 사용하고 예측 데이터에는 transform을 사용
fit은 학습 데이터에만 사용
cvect = CountVectorizer()
dtm = cvect.fit_transform(corpus)
dtm
>>>>
# fit_transform() 어휘 사전을 배우고 문서 용어 매트릭스를 반환합니다.
# fit 다음에 변환이 오는 것과 동일하지만 더 효율적으로 구현됩니다.
# dtm
dtm = cvect.fit_transform(corpus)
dtm
>>>>
<8x16 sparse matrix of type '<class 'numpy.int64'>'
with 27 stored elements in Compressed Sparse Row format>
vocab = cvect.get_feature_names_out()
vocab
>>>>
array(['거리두기', '거리두기와', '문의입니다', '버스', '상생지원금', '선별진료소', '승강장', '안내입니다',
'요금', '운행시간', '운행시간과', '위치', '지하철', '코로나', '택시', '터미널'],
dtype=object)
# 단어사전은 {"단어": 인덱스번호}
cvect.vocabulary_
>>>>
{'코로나': 13,
'거리두기와': 1,
'상생지원금': 4,
'문의입니다': 2,
'지하철': 12,
'운행시간과': 10,
'요금': 8,
'승강장': 6,
'선별진료소': 5,
'버스': 3,
'운행시간': 9,
'터미널': 15,
'위치': 11,
'안내입니다': 7,
'거리두기': 0,
'택시': 14}dtm 데이터프레임 만들기
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)
print(df_dtm.shape)
df_dtm
>>>>
(8, 16)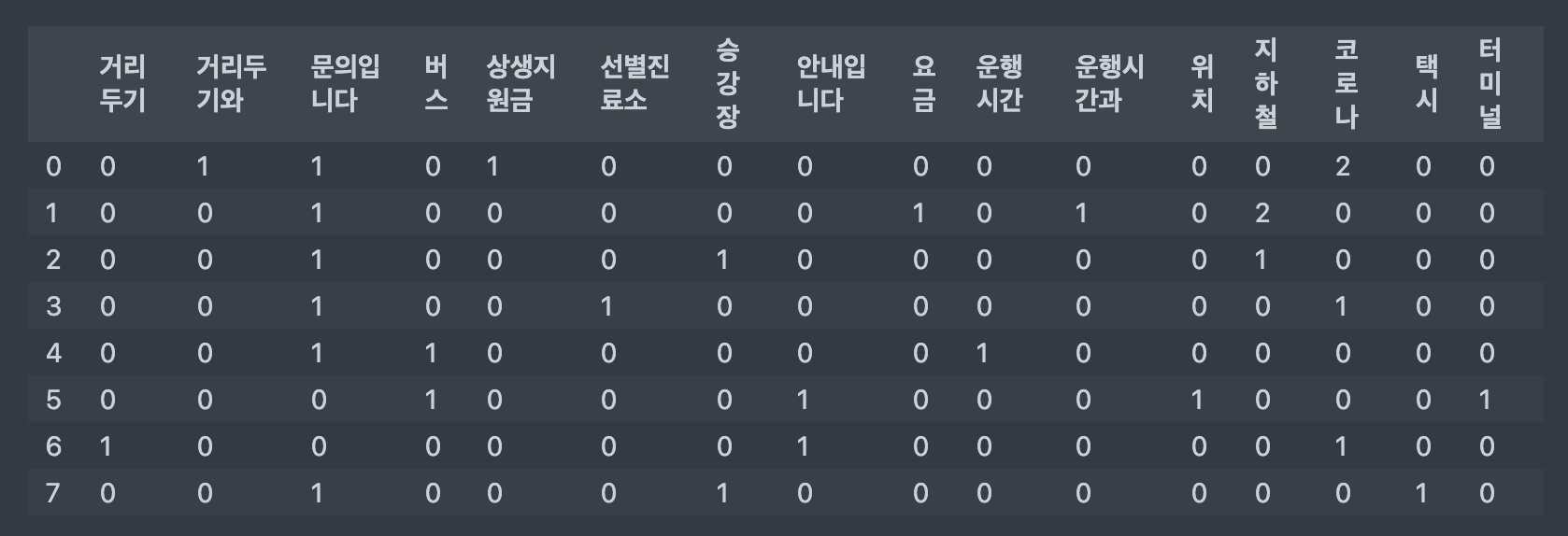
- 전체 문서에서 단어 빈도 합계
df_dtm.sum()
>>>>
거리두기 1
거리두기와 1
문의입니다 6
버스 2
상생지원금 1
선별진료소 1
승강장 2
안내입니다 2
요금 1
운행시간 1
운행시간과 1
위치 1
지하철 3
코로나 4
택시 1
터미널 1
dtype: int64N-grams
- 토큰을 몇 개 사용할 것인지 구분
- 지저한 n개의 숫자 만큼의 토큰을 묶어서 사용
- 예를 들어 (1, 1) 이라면 1개의 토큰을
- (2, 3)이라면 2~3개의 토큰을 사용
- analyzer 설정에 따라 단어단위, 캐릭터 단위로 사용
- ngram_range(min_n, max_n)
cvect = CountVectorizer(ngram_range=(1, 2))
dtm = cvect.fit_transform(corpus)
dtm
>>>>
<8x36 sparse matrix of type '<class 'numpy.int64'>'
with 48 stored elements in Compressed Sparse Row format>
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
df_dtm
- 빈도수 확인
df_dtm.sum()
>>>>
거리두기 1
거리두기 안내입니다 1
거리두기와 1
거리두기와 코로나 1
문의입니다 6
버스 2
버스 운행시간 1
버스 터미널 1
상생지원금 1
상생지원금 문의입니다 1
선별진료소 1
선별진료소 문의입니다 1
승강장 2
승강장 문의입니다 2
안내입니다 2
요금 1
요금 문의입니다 1
운행시간 1
운행시간 문의입니다 1
운행시간과 1
운행시간과 지하철 1
위치 1
위치 안내입니다 1
지하철 3
지하철 승강장 1
지하철 요금 1
지하철 운행시간과 1
코로나 4
코로나 거리두기 1
코로나 거리두기와 1
코로나 상생지원금 1
코로나 선별진료소 1
택시 1
택시 승강장 1
터미널 1
터미널 위치 1
dtype: int64문서 용어 행렬을 반환하는 함수
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
print(df_dtm.shape)
return df_dtm.style.background_gradient()display_transform_dtm(cvect, corpus)
- min_df=2 로 설정하면 2 이하의 값 제외
cvect = CountVectorizer(min_df=2)
display_transform_dtm(cvect, corpus)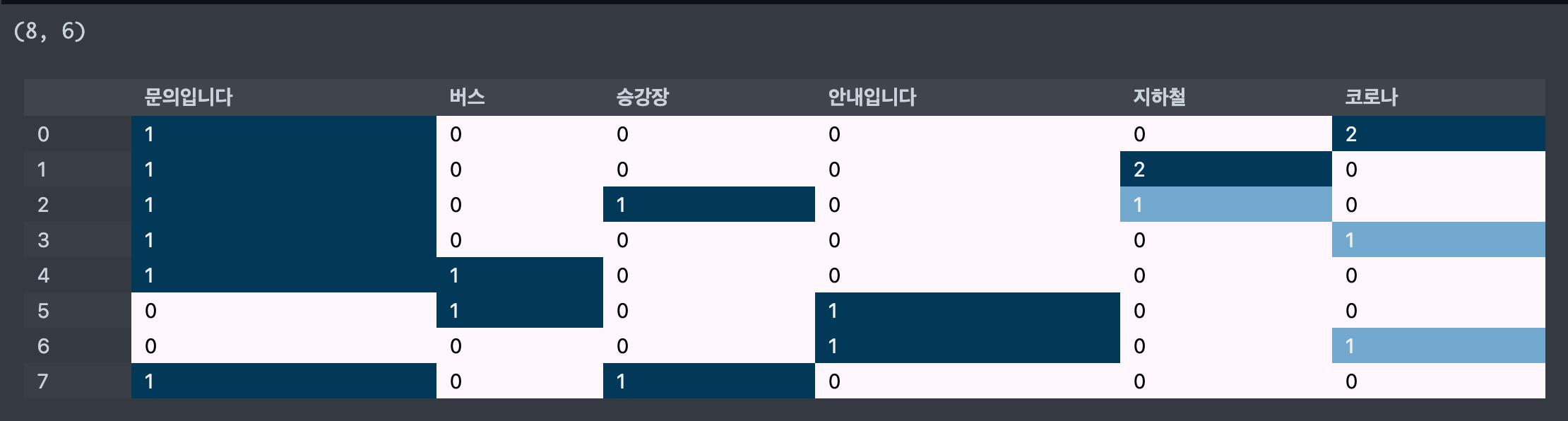
- max_df=4 로 설정하면 4 이상의 값 제외
cvect = CountVectorizer(max_df=4)
display_transform_dtm(cvect, corpus)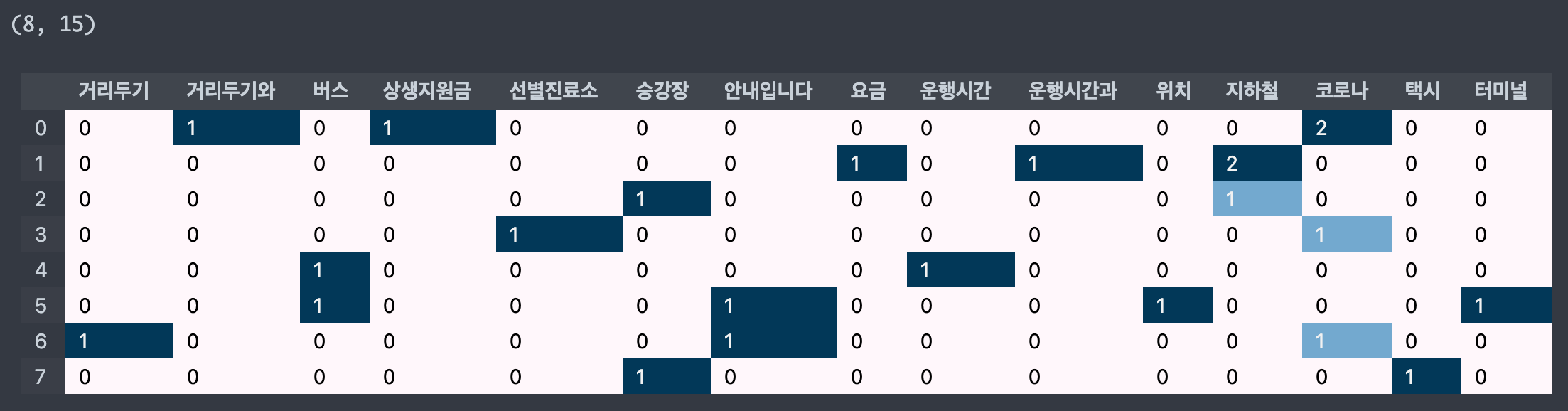
- max_features=10 로 설정하면 빈도수가 가장 높은 순으로 해당 개수만큼 단어 추출
cvect = CountVectorizer(max_feature=10)
display_transform_dtm(cvect, corpus)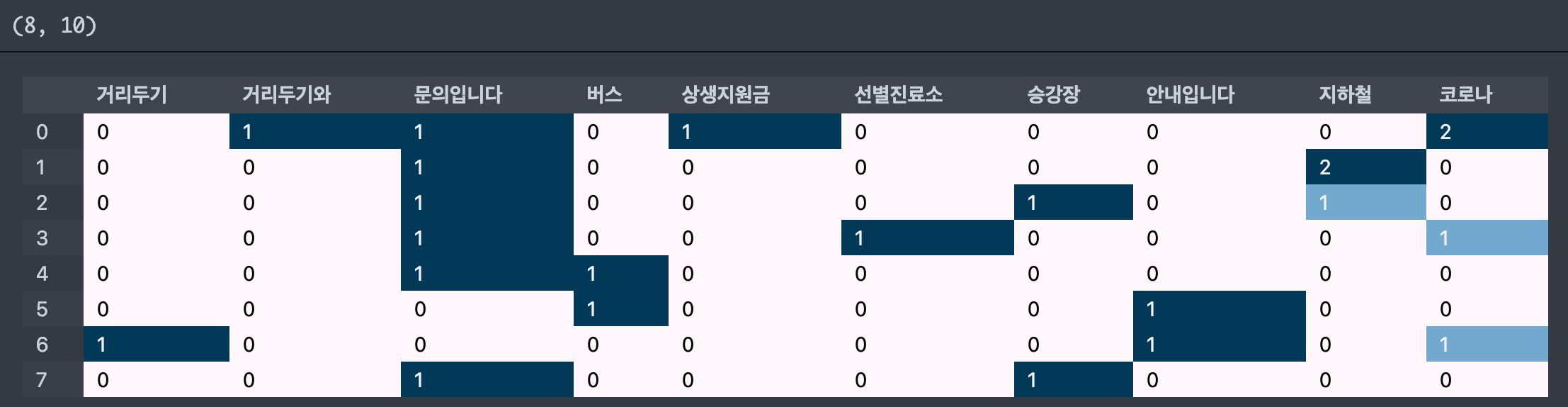
불용어
stop_word = ['코로나', '문의입니다', '터미널', '택시']
cvect = CountVectorizer(stop_words=stop_words)
display_transform_dtm(cvect, corpus)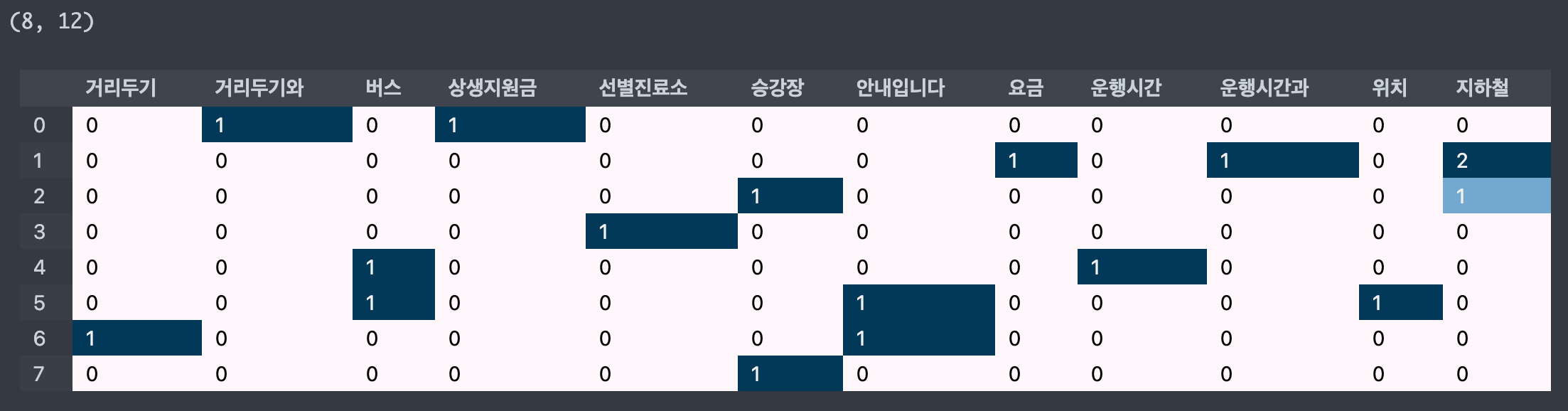
TF-IDF
- TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfVect.fit_transform(corpus)
# 문서에 토큰이 더 많이 나타날수록 가중치는 더 커짐
# 그러나 토큰이 문서에 많이 표시될수록 가중치 감소
# 얼마나 빈번하게 등장하냐에 따라 가중치 값 변환
# 전체 문서에서는 자주 등장하지 않지만, 특정 문서에서 자주 등장한다면 가중치 값 높게 나옴
# 모든 문서에서 자주 등장하는 값은 가중치 낮게 나옴
tfidfvect = TfidfVectorizer()
display_transform_dtm(tfidfvect, corpus)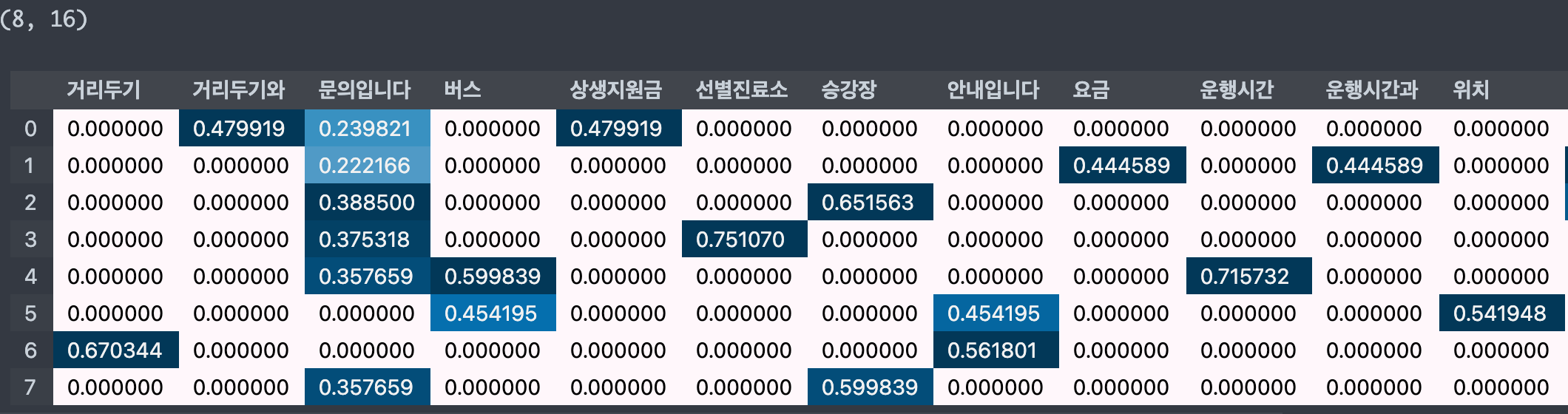
IDF
- 하나의 문서에만 나타나는 토큰은 idf 가중치가 높게 나옴
- 적게 나타난 토큰이라도 모든 문서에 있는 토큰은 idf 낮음
idf = tfidfVect.idf_
idf
>>>>
array([2.5040774 , 2.5040774 , 1.25131443, 2.09861229, 2.5040774 ,
2.5040774 , 2.09861229, 2.09861229, 2.5040774 , 2.5040774 ,
2.5040774 , 2.5040774 , 2.09861229, 1.81093022, 2.5040774 ,
2.5040774 ])
# 사전만들기
vocab = tfidfvect.get_feature_names_out()
vocab
idf_dict = dict(zip(vocab, idf))
idf_dict
>>>>
{'거리두기': 2.504077396776274,
'거리두기와': 2.504077396776274,
'문의입니다': 1.251314428280906,
'버스': 2.09861228866811,
'상생지원금': 2.504077396776274,
'선별진료소': 2.504077396776274,
'승강장': 2.09861228866811,
'안내입니다': 2.09861228866811,
'요금': 2.504077396776274,
'운행시간': 2.504077396776274,
'운행시간과': 2.504077396776274,
'위치': 2.504077396776274,
'지하철': 2.09861228866811,
'코로나': 1.8109302162163288,
'택시': 2.504077396776274,
'터미널': 2.504077396776274}- idf_dict 값 시각화
pd.Series(idf_dict).plot.barh()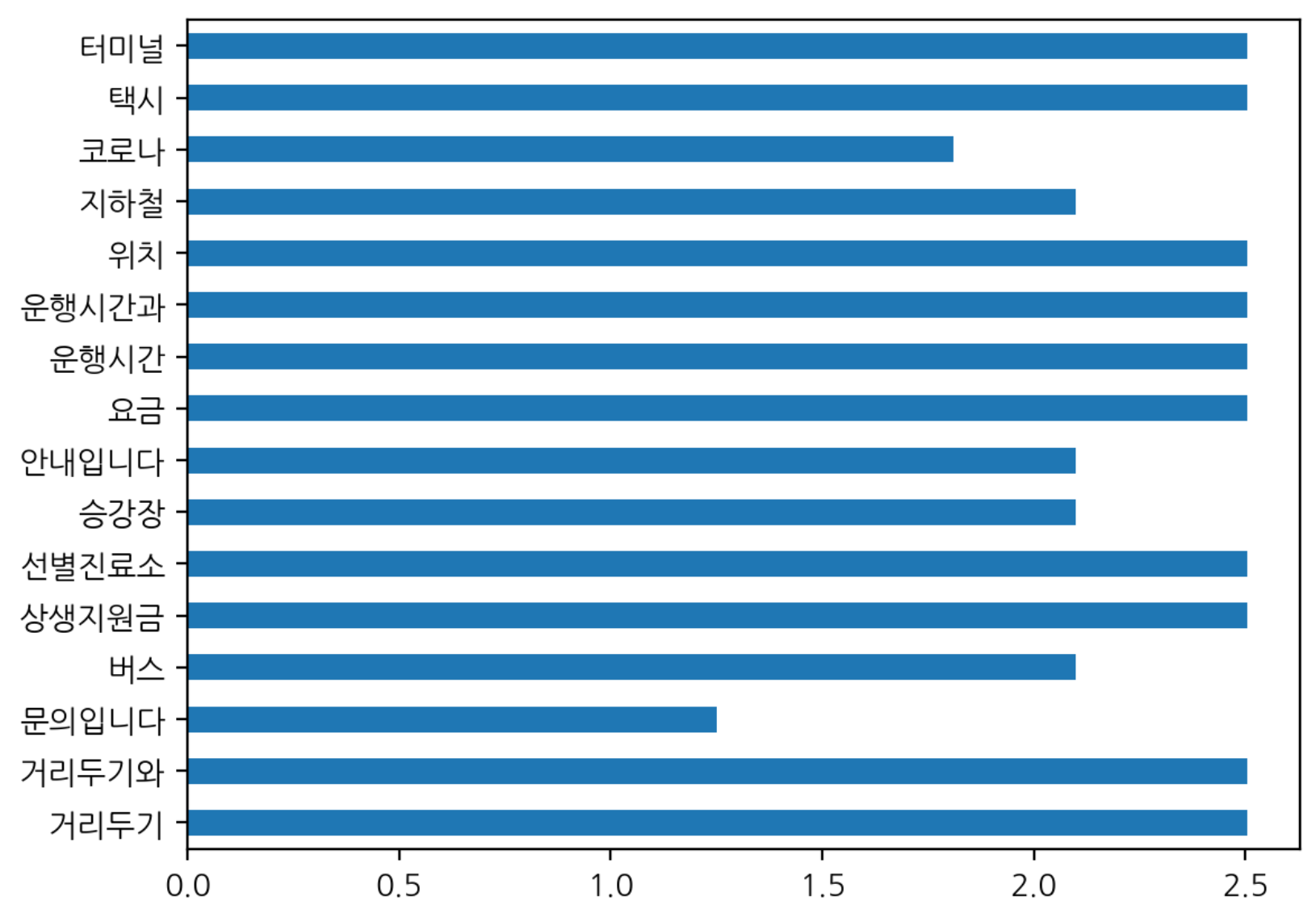
TfidfVectorizer 의 다양한 기능 사용하기
- analyzer
- n-gram
- min_df, max_df
- max_features
- stop_words
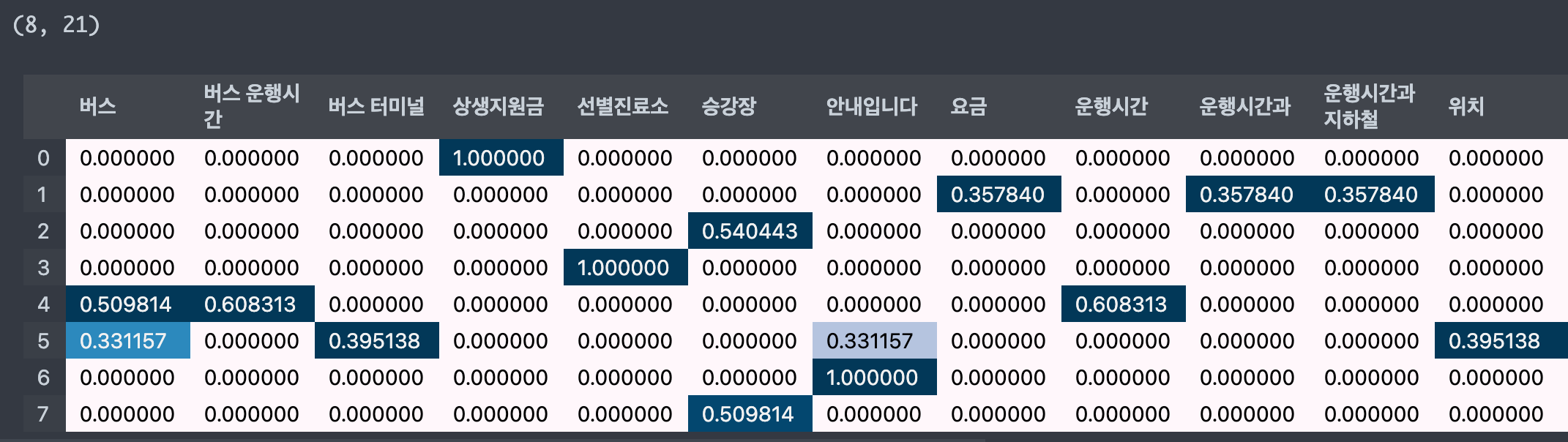
tv = TfidfVectorizer(analyzer='word', ngram_range=(1, 2), min_df=1, max_df=1.0,
stop_words=['거리두기', '거리두기와', '문의입니다', '코로나'])
tv.fit_transform(corpus)
display_transform_dtm(tv, corpus)