수치형 변수
집값과 상관계수 높은 데이터 보기
corr = df.corr()
# SalePrice와 상관계수 특정 수치 이상인 데이터
corr.loc[abs(corr['SalePrice']) > 0.6, 'SalePrice]
>>>>
OverallQual 0.790982
TotalBsmtSF 0.613581
1stFlrSF 0.605852
GrLivArea 0.708624
GarageCars 0.640409
GarageArea 0.623431
SalePrice 1.000000
Name: SalePrice, dtype: float64
# 특정 수치 이상인 변수의 인덱스
high_corr_col = corr.loc[abs(corr['SalePrice']) > 0.5, 'SalePrice'].index
high_corr_col
>>>>
Index(['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice'],
dtype='object')파생변수 만들기
df['TotalSF'] = df['TotalBsmtSF'] + df['1stFlrSF'] + df['2ndFlrSF']결측치 채우기
0 or None 으로 채우기
# 결측치 -> 'None' 대체
Garage_None = ['GarageType', 'GarageFinish', 'GarageQual', 'GarageCond']
df[Garage_None] = df[Garage_None].fillna('None')
df[Garage_None].isnull().sum()
>>>>
GarageType 0
GarageFinish 0
GarageQual 0
GarageCond 0
# 결측치 -> 수치형 '0' 대체
Basement_0 = ['BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath']
df[Basement_0] = df[Basement_0].fillna(0)
df[Basement_0].isnull().sum()
>>>>
BsmtFinSF1 0
BsmtFinSF2 0
BsmtUnfSF 0
TotalBsmtSF 0
BsmtFullBath 0
BsmtHalfBath 0
dtype: int64최빈값으로 채우기
- mode()
fill_mode = ['MSZoning', 'KitchenQual', 'Exterior1st', 'Exterior2nd', 'SaleType', 'Functional']
df[fill_mode].mode().loc[0]
>>>>
MSZoning RL
KitchenQual TA
Exterior1st VinylSd
Exterior2nd VinylSd
SaleType WD
Functional Typ
Name: 0, dtype: object
df[fill_mode] = df[fill_mode].fillna(df[fill_mode].mode().loc[0])
df[fill_mode].isnull().sum()
>>>>
MSZoning 0
KitchenQual 0
Exterior1st 0
Exterior2nd 0
SaleType 0
Functional 0
dtype: int64
train[fill_mode[0]].unique()
>>>>
array(['RL', 'RM', 'C (all)', 'FV', 'RH'], dtype=object)데이터 타입 바꾸기
- 수치데이터의 nunique 구해서 어떤 값이 one-hot-encoding 하면 좋을지 찾아보기
- 수치 데이터를 ordinal encoding 된 값을 그대로 사용해도 되지만 범주 값으로 구분하고자 하면
category나 object 타입으로 변환하면 one-hot-encoding 가능 - ordinal encoding -> one-hot-encoding
num_nunique = df.select_dtype(include='number').nunique().sort_values()
num_nunique[num_nunique < 10]
>>>>
BsmtHalfBath 3
HalfBath 3
KitchenAbvGr 4
BsmtFullBath 4
YrSold 5
Fireplaces 5
FullBath 5
BedroomAbvGr 8
OverallCond 9
dtype: int64
df['MoSold'].value_counts()
>>>>
6 503
7 446
5 394
4 279
8 233
3 232
10 173
9 158
11 142
2 133
1 122
12 104
Name: MoSold, dtype: int64
# 수치형 데이터 -> 문자형 데이터
num_to_str_col = ["MSSubClass", "OverallCond", "YrSold", "MoSold"]
df[num_to_str_col].nunique()
>>>>
MSSubClass 16
OverallCond 9
YrSold 5
MoSold 12
dtype: int64
# 문자 형태로 변경하게 되면 나중에 one-hot-encoding 가능
df[num_to_str_col] = df[num_to_str_col].astype(str)
df[num_to_str_col].dtypes
>>>>
MSSubClass object
OverallCond object
YrSold object
MoSold object
dtype: object나머지 수치 변수 중앙값으로 결측치 대체
수치형 변수 찾기
feature_num = df.select_dtype(include="number").columns.tolist()
feature_num.remove('SalePrice')중앙값으로 대체
df[feature_num] = df[feature_num].fillna(df[feature_num].median())
df[feature_num].isnull().sum().sum()
>>>> 0왜도 (Skewness) & 첨도 (kurtosis)
train['SalePrie'].skew(), train['SalePrice'].kurt()
>>>> (1.8828757597682129, 6.536281860064529)
train['SalePrice_log1p'].skew(), train['SalePrice_log1p'].kurt()
>>>> (0.12134661989685329, 0.809519155707878)왜도가 특정 수치 이상인 값
feature_skew = abs(df.skew()).sort_values(ascending=False)
skewd_col = feature_skew[feature_skew > 2].index
# 수치 데이터이지만 범주형 형태로 되어 있는 경우 로그값 변환할 필요X
df[skewd_col].hist(bins=50, figsize=(12,10));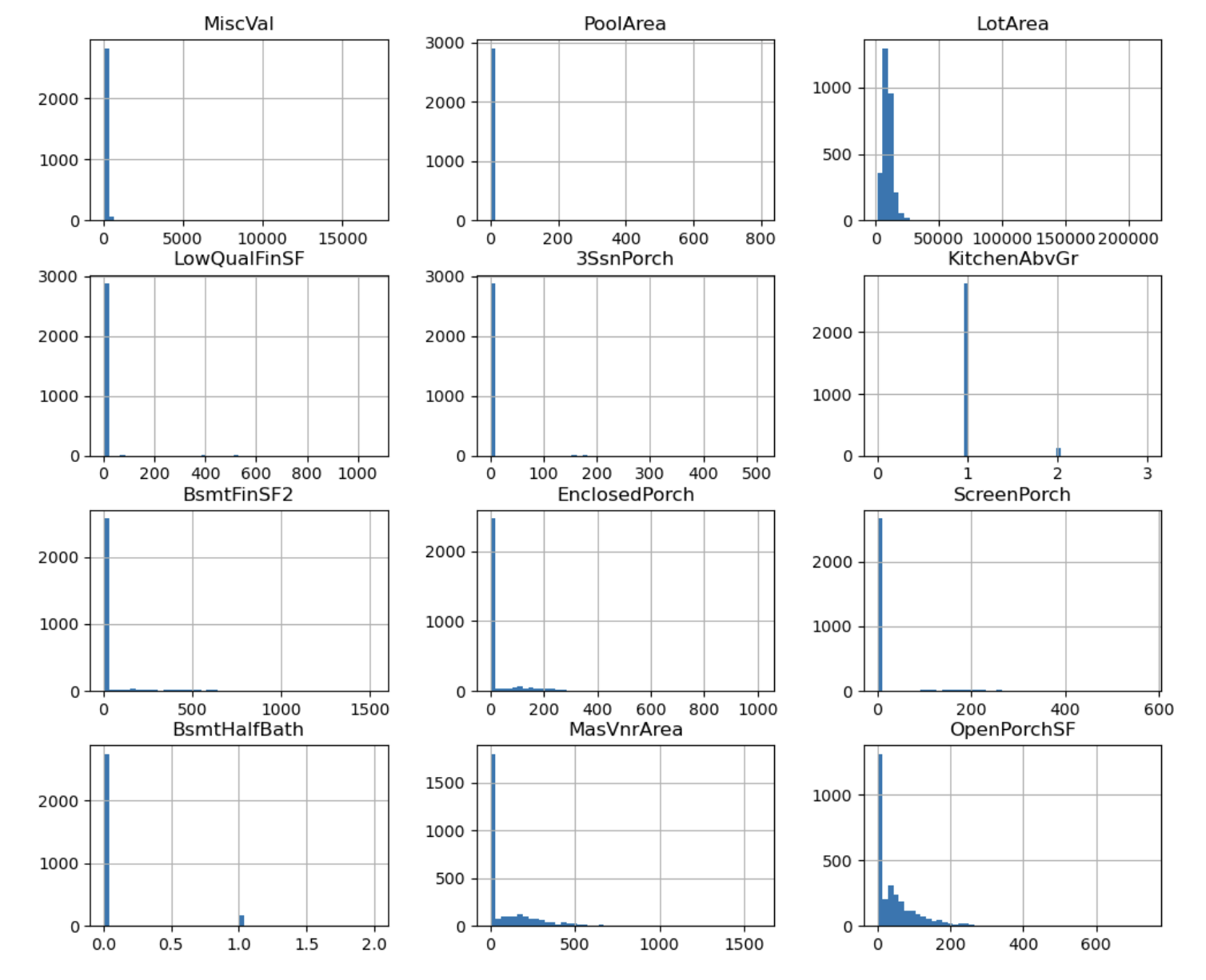
log 변환
범주형 데이터 제외하고 로그 변환
log_features = ['LotFrontage','LotArea','MasVnrArea','BsmtFinSF1','BsmtFinSF2','BsmtUnfSF',
'TotalBsmtSF','1stFlrSF','2ndFlrSF','LowQualFinSF','GrLivArea',
'BsmtFullBath','BsmtHalfBath','FullBath','HalfBath','BedroomAbvGr','KitchenAbvGr',
'TotRmsAbvGrd','Fireplaces','GarageCars','WoodDeckSF','OpenPorchSF',
'EnclosedPorch','3SsnPorch','ScreenPorch','PoolArea','MiscVal','YearRemodAdd']
# 수치데이터이지만 범주형 데이터 찾기
num_cate_feature = df[log_features].nunique()
num_cate_feature = num_cate_feature[num_cate_feature < 20].index
num_cate_feature
>>>>
Index(['BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr',
'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'PoolArea'],
dtype='object')
num_log_feature = list(set(log_features) - set(num_cate_feature))
num_log_feature
>>>>
['MasVnrArea',
'1stFlrSF',
'LotFrontage',
'TotalBsmtSF',
'ScreenPorch',
'OpenPorchSF',
'3SsnPorch',
'WoodDeckSF',
'YearRemodAdd',
'BsmtFinSF2',
'LowQualFinSF',
'MiscVal',
'EnclosedPorch',
'LotArea',
'GrLivArea',
'BsmtUnfSF',
'BsmtFinSF1',
'2ndFlrSF']
df[num_log_feature].info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2919 entries, 1 to 2919
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MasVnrArea 2919 non-null float64
1 1stFlrSF 2919 non-null int64
2 LotFrontage 2919 non-null float64
3 TotalBsmtSF 2919 non-null float64
4 ScreenPorch 2919 non-null int64
5 OpenPorchSF 2919 non-null int64
6 3SsnPorch 2919 non-null int64
7 WoodDeckSF 2919 non-null int64
8 YearRemodAdd 2919 non-null int64
9 BsmtFinSF2 2919 non-null float64
10 LowQualFinSF 2919 non-null int64
11 MiscVal 2919 non-null int64
12 EnclosedPorch 2919 non-null int64
13 LotArea 2919 non-null int64
14 GrLivArea 2919 non-null int64
15 BsmtUnfSF 2919 non-null float64
16 BsmtFinSF1 2919 non-null float64
17 2ndFlrSF 2919 non-null int64
dtypes: float64(6), int64(12)
memory usage: 497.8 KB
df[num_log_feature] = np.log1p(df[num_log_feature])
df[num_log_feature].hist(figsize=(12, 8), bins=100)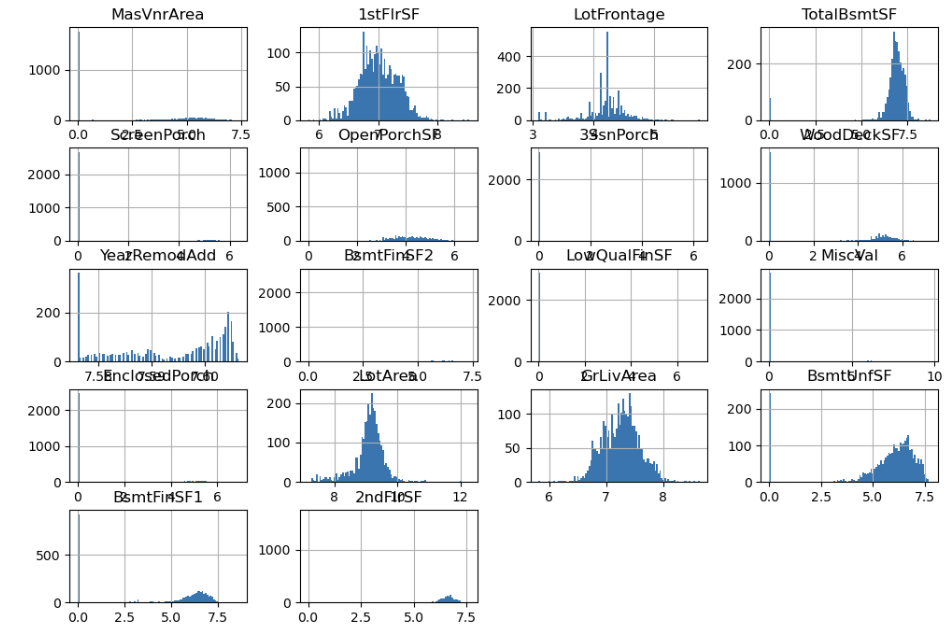
다항식 전개 (Ploynomials)

squared_features = ['YearRemodAdd', 'LotFrontage',
'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'GrLivArea','GarageArea', 'TotalSF']
df[squared_feature].hist(figsize=(12, 8), bins=50)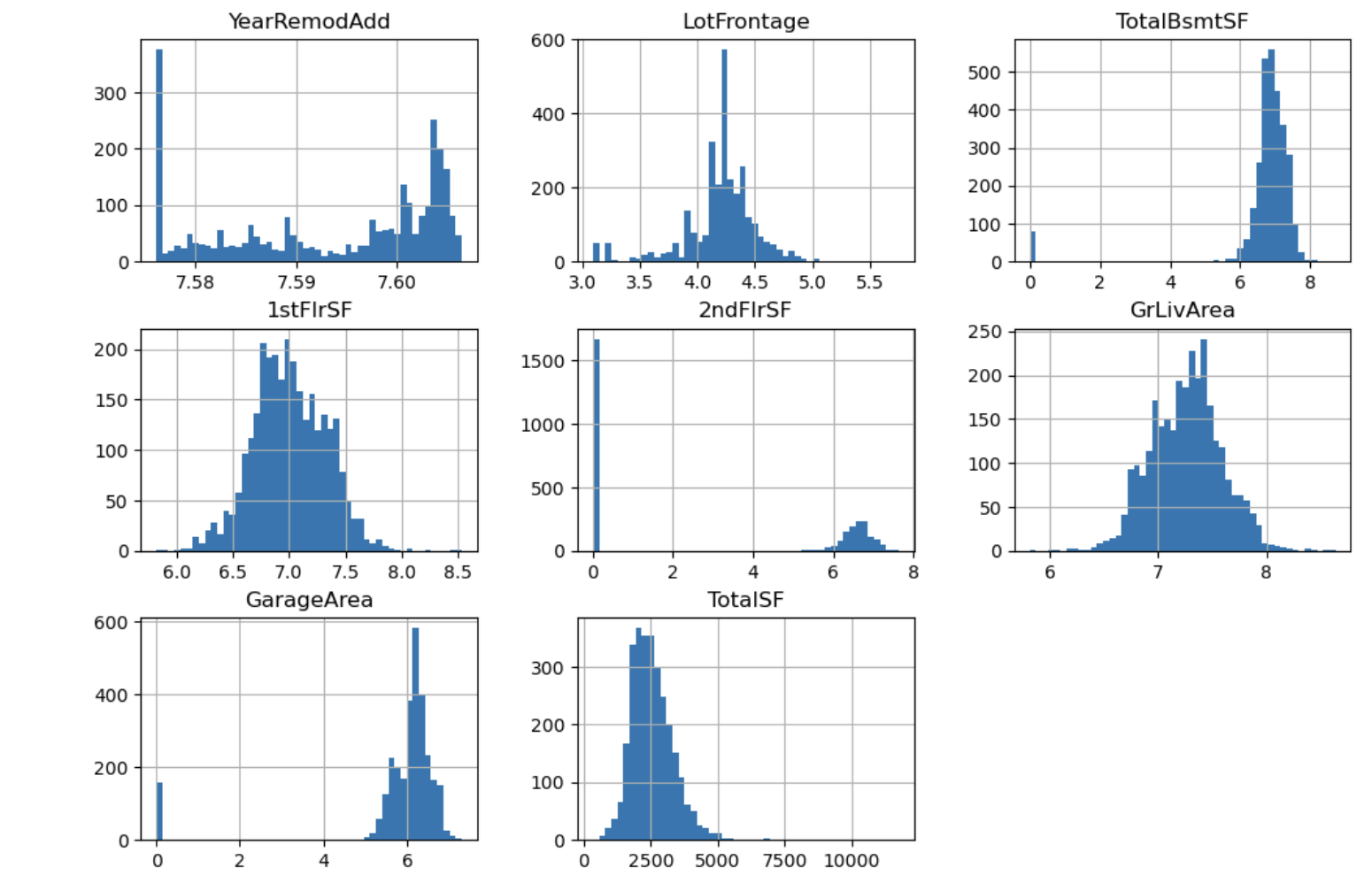
df_squre = df[squared_features] ** 2범주형 변수
df_cate = df.select_dtype(include='object')
# 데이터 정렬 후 결측치가 있는 데이터를 제거하기 위해 슬라이싱
feature_cate = df_cate.isnull().mean().sort_values()[:-2].index
feature_cate
>>>>
Index(['MSSubClass', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1',
'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'KitchenQual',
'Functional', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond',
'PavedDrive', 'MoSold', 'YrSold', 'SaleType', 'ExterCond', 'Foundation',
'Condition1', 'MSZoning', 'Street', 'LotShape', 'LandContour',
'LotConfig', 'LandSlope', 'Neighborhood', 'ExterQual', 'SaleCondition',
'Condition2', 'BldgType', 'HouseStyle', 'OverallCond', 'RoofStyle',
'RoofMatl', 'Exterior1st', 'Exterior2nd', 'Electrical', 'Utilities'],
dtype='object')Make Feature
정답값(Target) 지정
label_name = 'SalePrice_log1p'feature 지정
# 정답값은 제거
feature_names = []
feature_names.extend(num_log_feature)
feature_names.append("TotalSF")
feature_names.extend(feature_cate)
feature_names.remove("1stFlrSF")
feature_names.remove("2ndFlrSF")
feature_names.remove("BsmtFinSF1")
feature_names.remove("BsmtFinSF2")
feature_names.remove("SalePrice")KFold , Cross Validation
- KFold를 사용하여 분할
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)cross_val_score 와 cross_val_predict
- cross_val_predict로 예측 결과 구하기
- y_valid_predict에 결과 담기
import sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train, y_train, cv=kf, n_jobs=-1)Metrix
RMSE
from sklearn.metrics import mean_squared_error
rmse = mean_squared_error(y_train, y_valid_predict) ** 0.5
rmse
>>>> 0.1542173809461507실제값-예측값 비교
regplot
sns.regplot(x=y_train, y=y_valid_predict)
R^2 score
- 1에 가까울수록 잘 예측
from sklearn.metrics import r2_score
r2_score(y_train, y_valid_predict)
>>>>
0.8508439273691162kdeplot
sns.kdeplot(y_train)
sns.kdeplot(y_valid_predict)

Ⓓ🅰️🅣🄰 ♡♥︎