House Price
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
라이브러리 & 데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("ggplot")
from glob import glob
data = glob("data/house/*")pd.set_option('display.max_columns', None)
train = pd.read_csv("data/house/train.csv", index_col="Id")
print(train.shape)
train.head(2)
(1460, 80)
test = pd.read_csv("data/house/test.csv", index_col='Id')
print(test.shape)
test.head(2)
(1459, 79)
# label
set(train.columns) - set(test.columns)
>>>>
{'SalePrice'}
sub = pd.read_csv('data/house/sample_submission.csv', index_col="Id")
print(sub.shape)
sub.head(2)
(1459, 1)EDA
info()
train.info()
>>>>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1460 entries, 1 to 1460
Data columns (total 80 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MSSubClass 1460 non-null int64
1 MSZoning 1460 non-null object
2 LotFrontage 1201 non-null float64
3 LotArea 1460 non-null int64
4 Street 1460 non-null object
5 Alley 91 non-null object
6 LotShape 1460 non-null object
7 LandContour 1460 non-null object
8 Utilities 1460 non-null object
9 LotConfig 1460 non-null object
10 LandSlope 1460 non-null object
11 Neighborhood 1460 non-null object
12 Condition1 1460 non-null object
13 Condition2 1460 non-null object
14 BldgType 1460 non-null object
15 HouseStyle 1460 non-null object
16 OverallQual 1460 non-null int64
17 OverallCond 1460 non-null int64
18 YearBuilt 1460 non-null int64
19 YearRemodAdd 1460 non-null int64
20 RoofStyle 1460 non-null object
21 RoofMatl 1460 non-null object
22 Exterior1st 1460 non-null object
23 Exterior2nd 1460 non-null object
24 MasVnrType 1452 non-null object
25 MasVnrArea 1452 non-null float64
26 ExterQual 1460 non-null object
27 ExterCond 1460 non-null object
28 Foundation 1460 non-null object
29 BsmtQual 1423 non-null object
30 BsmtCond 1423 non-null object
31 BsmtExposure 1422 non-null object
32 BsmtFinType1 1423 non-null object
33 BsmtFinSF1 1460 non-null int64
34 BsmtFinType2 1422 non-null object
35 BsmtFinSF2 1460 non-null int64
36 BsmtUnfSF 1460 non-null int64
37 TotalBsmtSF 1460 non-null int64
38 Heating 1460 non-null object
39 HeatingQC 1460 non-null object
40 CentralAir 1460 non-null object
41 Electrical 1459 non-null object
42 1stFlrSF 1460 non-null int64
43 2ndFlrSF 1460 non-null int64
44 LowQualFinSF 1460 non-null int64
45 GrLivArea 1460 non-null int64
46 BsmtFullBath 1460 non-null int64
47 BsmtHalfBath 1460 non-null int64
48 FullBath 1460 non-null int64
49 HalfBath 1460 non-null int64
50 BedroomAbvGr 1460 non-null int64
51 KitchenAbvGr 1460 non-null int64
52 KitchenQual 1460 non-null object
53 TotRmsAbvGrd 1460 non-null int64
54 Functional 1460 non-null object
55 Fireplaces 1460 non-null int64
56 FireplaceQu 770 non-null object
57 GarageType 1379 non-null object
58 GarageYrBlt 1379 non-null float64
59 GarageFinish 1379 non-null object
60 GarageCars 1460 non-null int64
61 GarageArea 1460 non-null int64
62 GarageQual 1379 non-null object
63 GarageCond 1379 non-null object
64 PavedDrive 1460 non-null object
65 WoodDeckSF 1460 non-null int64
66 OpenPorchSF 1460 non-null int64
67 EnclosedPorch 1460 non-null int64
68 3SsnPorch 1460 non-null int64
69 ScreenPorch 1460 non-null int64
70 PoolArea 1460 non-null int64
71 PoolQC 7 non-null object
72 Fence 281 non-null object
73 MiscFeature 54 non-null object
74 MiscVal 1460 non-null int64
75 MoSold 1460 non-null int64
76 YrSold 1460 non-null int64
77 SaleType 1460 non-null object
78 SaleCondition 1460 non-null object
79 SalePrice 1460 non-null int64
dtypes: float64(3), int64(34), object(43)
memory usage: 923.9+ KBdescribe()
train.describe()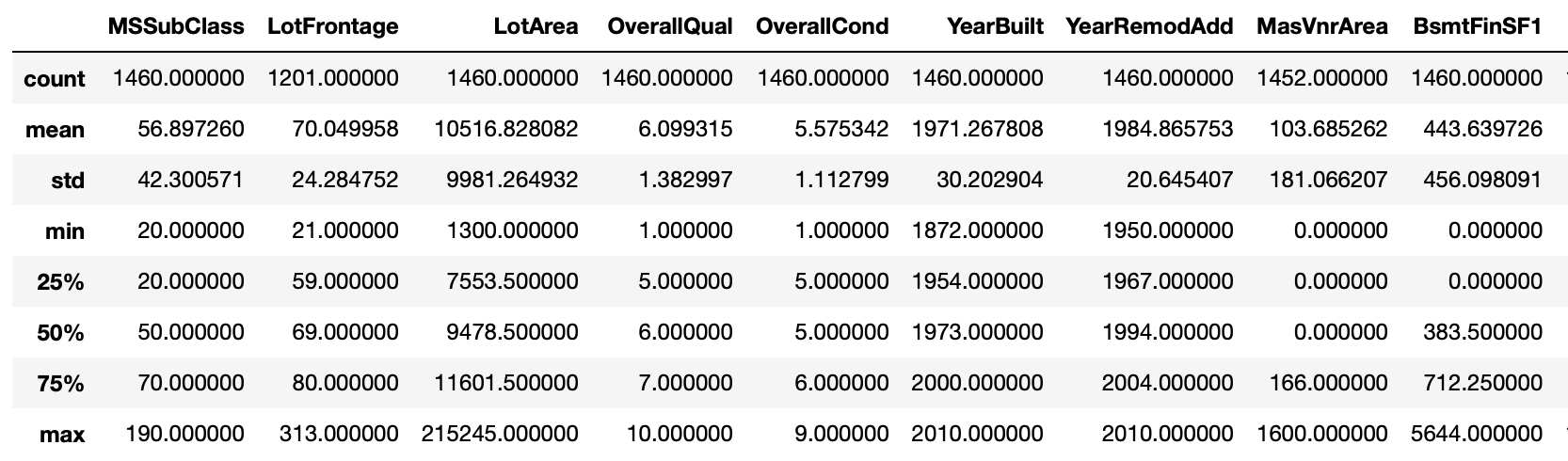
histplot
- 수치 데이터의 분포 확인, 첨도를 통해 너무 뾰족하지 않은지 -> 한 쪽에 데이터가 몰려있는지 확인
- 왜도 -> 너무 한쪽에 치우쳐져 있지 않은지 확인
- 정규분포 형태 확인
- 막대가 떨어져 있다면 수치데이터가 아니라 범주형 데이터가 아닌지 확인
train.hist(figsize=(20, 20), bins=50);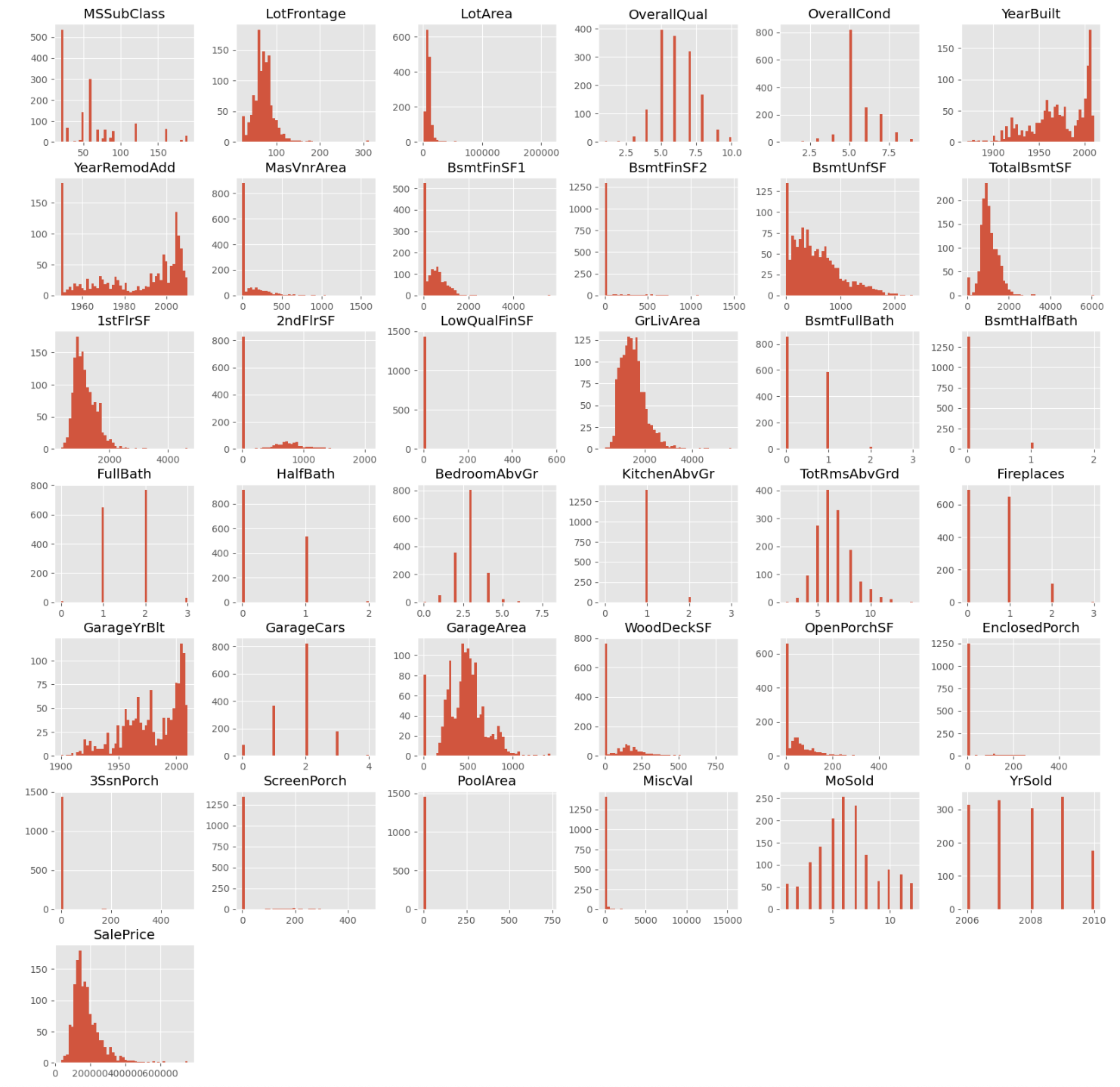
Feature Engineering
결측치 탐색
train_null = train.null().sum()
train_sum = train_null[train_null != 0].sort_values(ascending=False)
# train 결측치 수와 결측치 비율
train_na_mean = train.isnull().mean() * 100
pd.concat([train_null, train_na_mean], axis=1).loc[train_sum.index]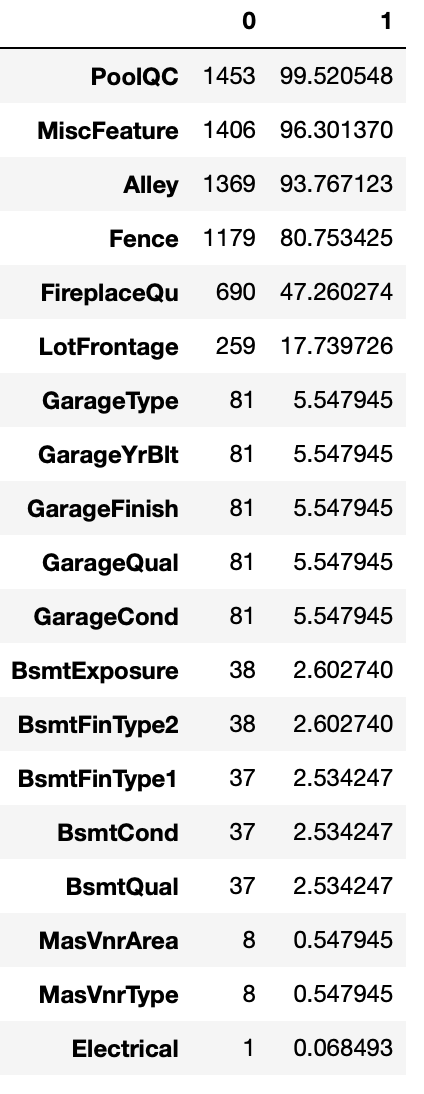
test_null = test.isnull().sum()
test_sum = test_null[test_null != 0].sort_values(ascending=False)
# test 결측치 수와 결측치 비율
test_na_mean = test.isnull().mean() * 100
pd.concat([test_sum, test_na_mean], axis=1).loc[test_sum.index]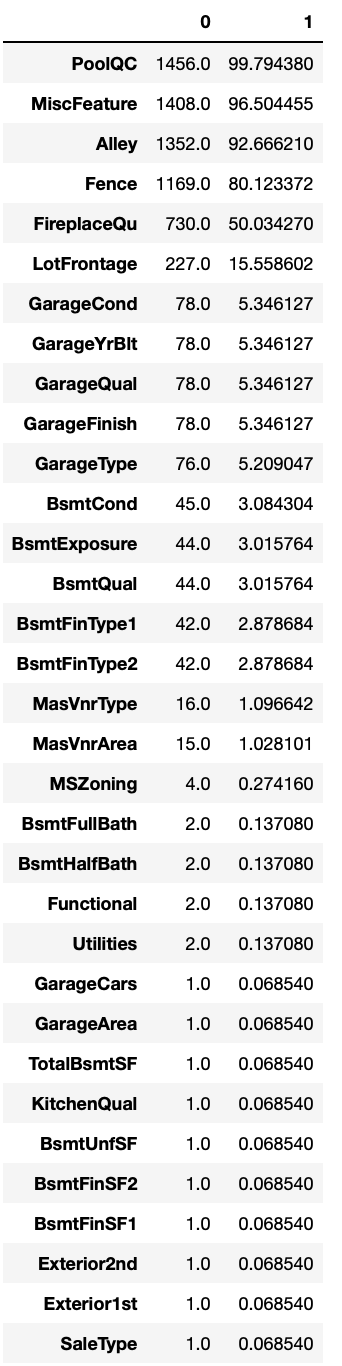
이상치 탐색
train["SalePrice"].describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
sns.scatterplot(data=train, x=train.index, y='SalePrice')
plt.axhline(50000, c='b', ls=":")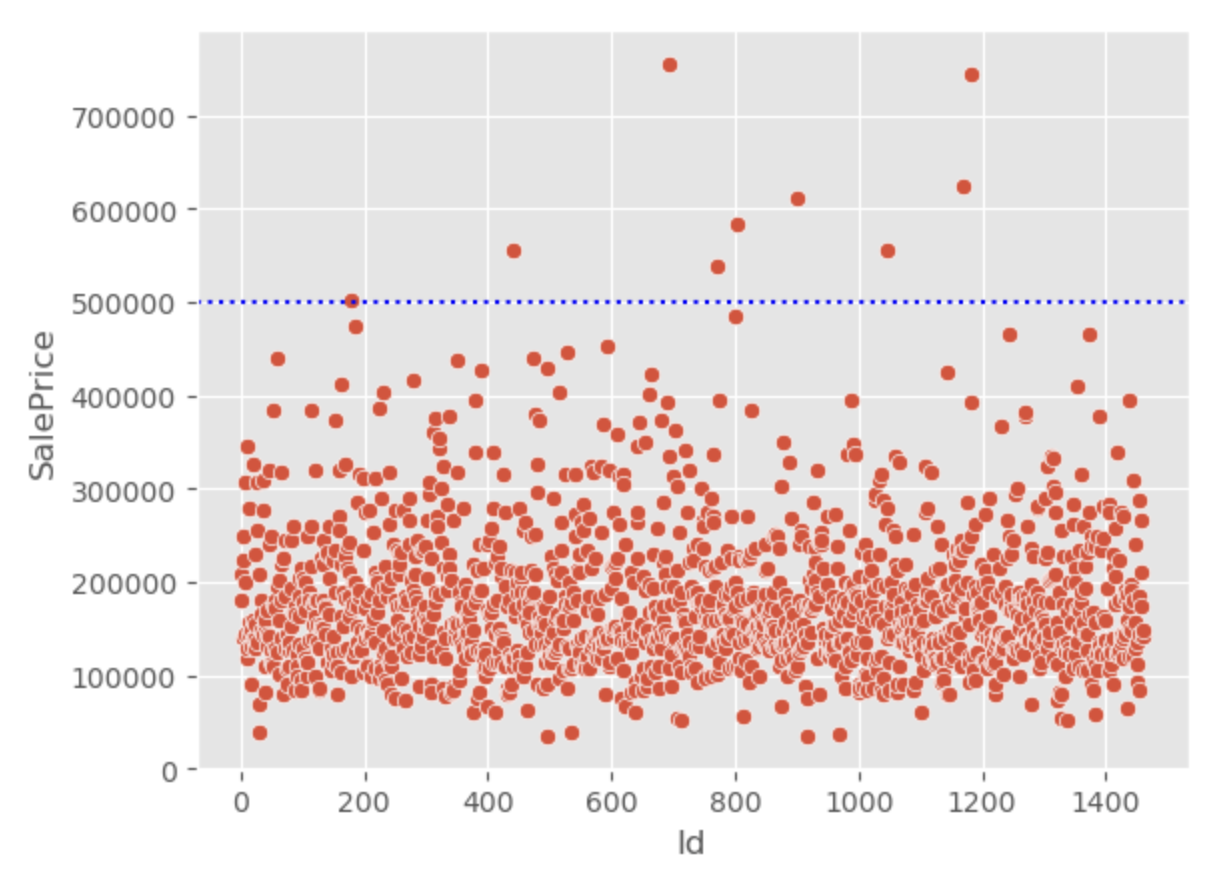
희소값 탐색
- 범주형 데이터 중에서 빈도가 적게 등장하는 값
-> one-hot-encoding 했을 때 빈도가 작은 값을 피처로 만들어 주면 연산시간이 더 오래걸림 - 오버피팅이 일어날 수 있음
- object type nunique
train.select_dtypes(include="O").nunique().nlargest(10)
>>>>
Neighborhood 25
Exterior2nd 16
Exterior1st 15
Condition1 9
SaleType 9
Condition2 8
HouseStyle 8
RoofMatl 8
Functional 7
RoofStyle 6
dtype: int64
# Neighborhood - value_counts
ncount = train['Neighborhood'].value_counts()countplot
- 희소값에 대해 one-hot-encoding 하게 되면 overfitting 발생 가능성 높음
- 많은 희소행렬이 생성되기 때문에 많은 resource 필요
- 희소값을 사용하고자 한다면
1) 희소값 결측치 처리하면 one-hot-encoding 하지 않는다.
2) 희소값을 '기타'로 처리 가능하다.
sns.countplot(data=train, y='Neighborhood', order=ncount.index)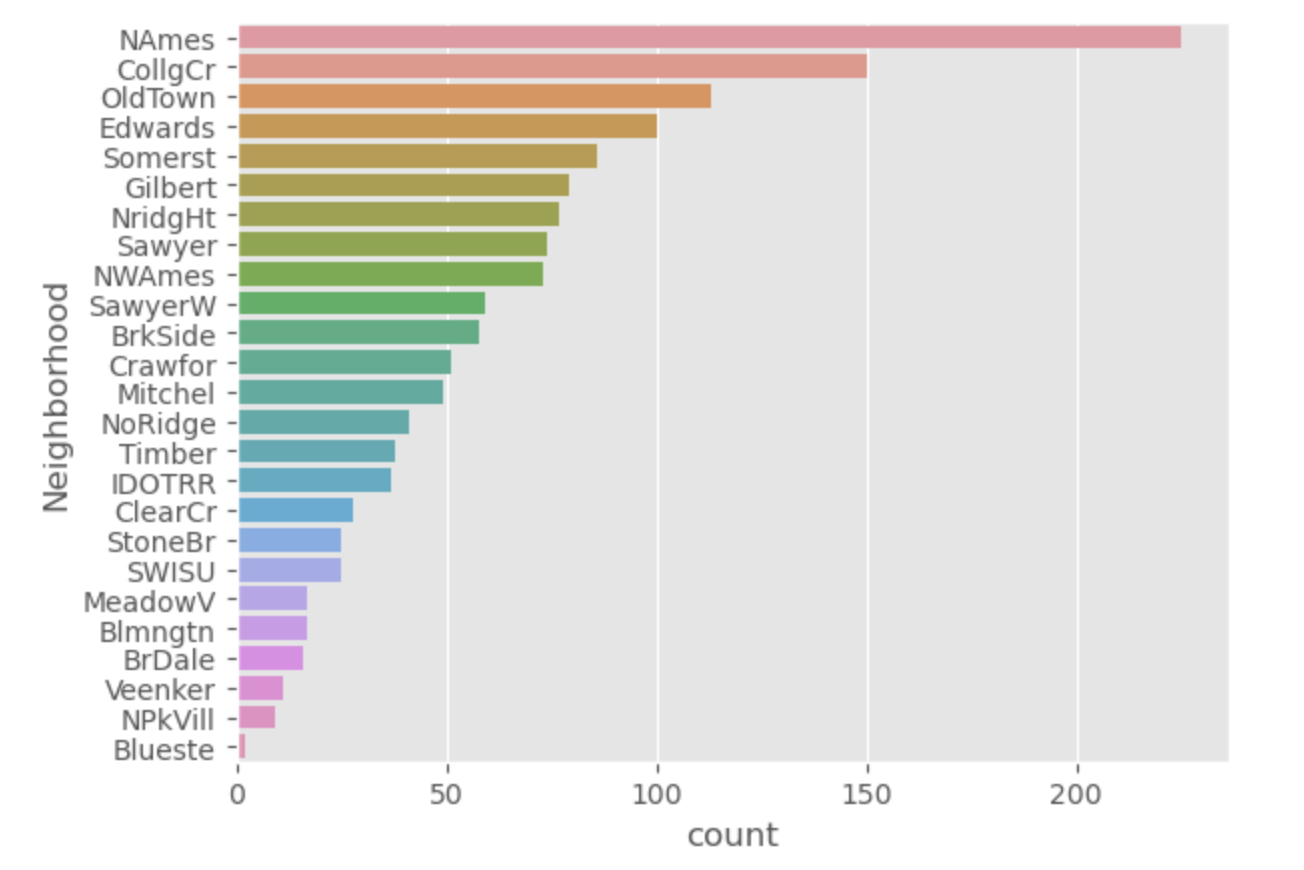
Scaling
- 정보균일도 기반
- 트리기반 모델은 피처스케일링이 필요 없음
(트리기반 모델은 상대적인 크기에 영향을 많이 받음) - Feature의 범위를 조정하여 정규화하는 것
- Feature의 분산과 표준편차 조정 -> 정규분포 형태 띄게하는 것
scaling 중요한 이유
- Feature의 범위가 다르면, Feature끼리 비교하기 어려우며 러닝머신 모델에서 제대로 작동X
- Feature Scaling이 잘 되어 있으면 서로 다른 변수끼리 비교 편리
- 더 빨리 작동
- 머신러닝 성능 상승
- Tree기반 알고리즘에서는 Feature Scaling의 영향 받지 않음
기법
-
Normalization-Standardization(Z-score) : 평균을 제거하고 데이터 단위 분산에 맞게 조정
- 장점 : 표준편차가 1이고 0을 중심으로 하는 표준 졍규 분포를 갖도록 조정
- 단점 : 변수가 왜곡되거나 이상치가 있으면 좁은 범위의 관측치를 압축하여 예측력 손상
-
Min-Max Scaling : Feature를 지정된 범위로 확장하여 기능을 변환 기본값은 [0, 1]
- 단점 : 변수가 왜곡되거나 이상치가 있으면 좁은 범위의 관측치를 압축하여 예측력을 손상
-
Robust Scaling : 중앙값을 제거하고 분위수 범위(IQR)에 따라 데이터 크기 조정
- 장점 : 편향된 변수에 대한 변환 수 변수의 분산을 더 잘 보존, 이상치 제거 효과적(이상치의 영향 덜 받음)
방식
-
Z-score scaling : z = (X - X.mean) / std
-> 평균을 빼주고 표준편차로 나눠줌
-> 평균을 0, 표준편차를 1로 만들어줌 -
Min-Max scaling : X_scaled = (X - X.min) / (X.max - X.min)
-> Min-Max 값이 0-1 사이
-> 최솟값 0, 최댓값 1 -
Robust : X_scaled = (X - X.median) / IQR
-> 중앙값으로 빼고 IQR로 나눠줌
-> 중앙값 0
train['SalePrice'].hist(bins=50, figsize=(6, 2));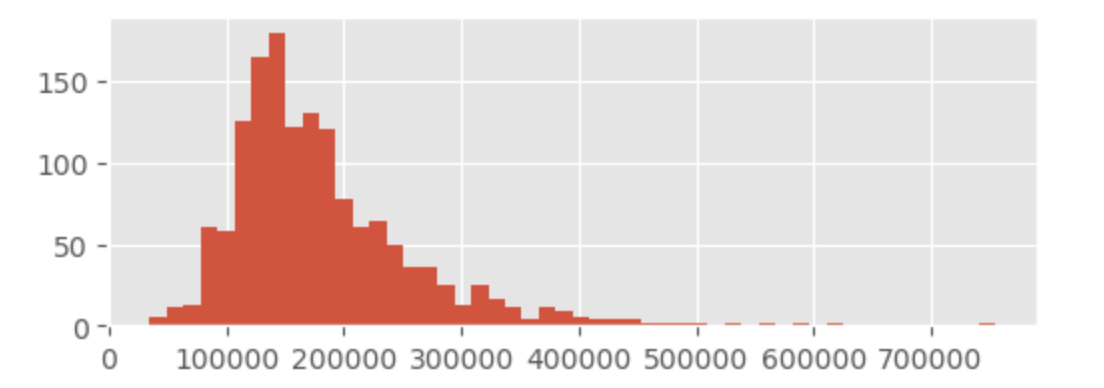
Scaling Lib
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler# StandardScaler
ss = StandardScaler()
# StandardScaler의 fit에는 matrix 형태를 넣어줘야함
# Series가 아닌 DataFrame 으로 넣어주기 위해 대괄호 2번 감싸야 함
# 반환값도 matrix 형태 -> 새로운 파생변수 만들 경우, 데이터프레임 형태로 파생변수 생성해야 함
# 전처리할 때 fir -> transform
# test data에는 fit 사용X, only transform만 사용
train[['SalePrice_ss']] = ss.fit(train[["SalePrice"]]).transform(train[["SalePrice'']])
train[['SalePrice', 'SalePrice_ss']].head(2)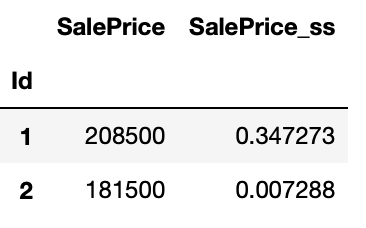
# MinMaxScaler
mm = MinMaxScaler()
train[['SalePrice_mm']] = mm.fit(train[['SalePrice']]).transform(train[['SalePrice']])
train[['SalePrice', 'SalePrice_mm']].head(2)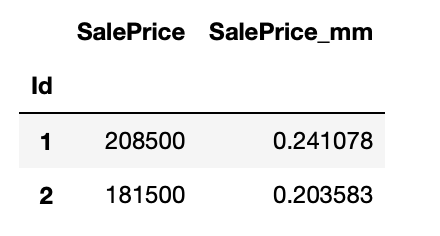
# RobustScaler
rs = RobustScaler()
train[['SalePrice_rs']] = rs.fit_transform(train[['SalePrice']])
train[['SalePrice', 'SalePrice_rs']].head(2)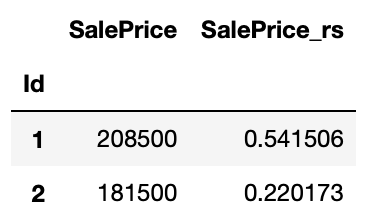
train[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]]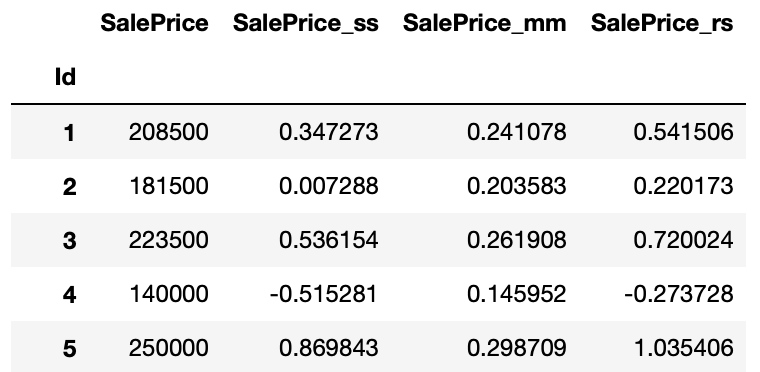
pd.options.display.float_format = '{:,.2f}'.formattrain[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]].describe()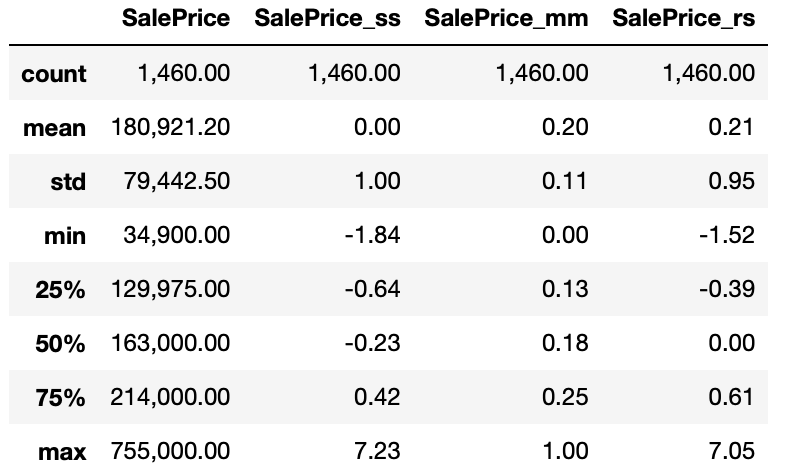
# histplot - "SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"
train[["SalePrice", "SalePrice_ss", "SalePrice_mm", "SalePrice_rs"]].hist(bins=50, figsize=(15, 6));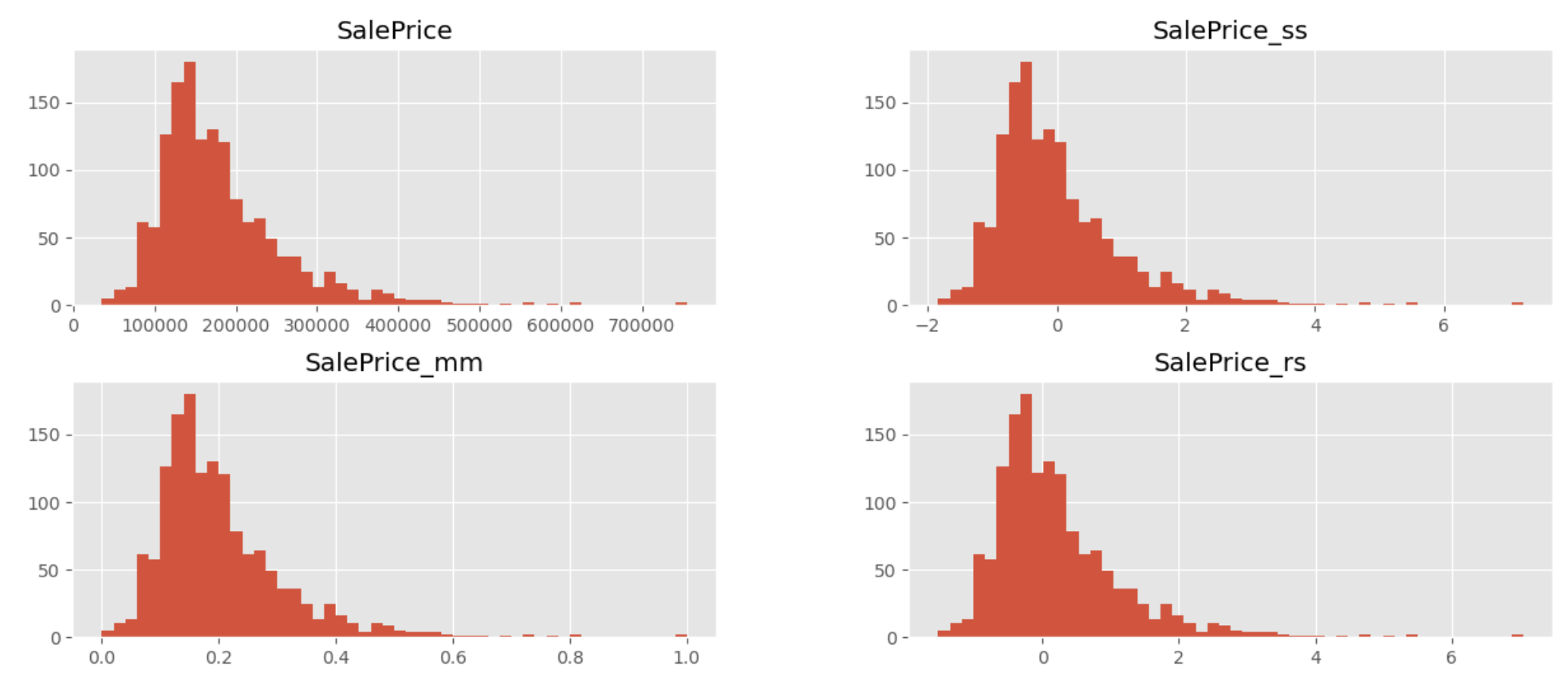
log Transformation
- log의 진수 조건 : x > 0
- numpy에 음수가 주어지면 nan값 반환
-> numpy.log1p() - Log transformation <-> np.exp() 둘 사이의 변환이 간편
- Log transformation된 상태로 학습 & 예측한 다음 예측한 값에 np.expm1() 적용후 출력
train['SalePrice_log1p'] = np.log1p(train['SalePrice'])
train['SalePrice_ss_log1p'] = np.log1p(train['SalePrice_ss'])
train['SalePrice_log1p_ss'] = ss.fit_transform(train[['SalePrice_log1p']])
# histplot - SalePrice_ss, SalePrice_ss_log1p, SalePrice_log1p, SalePrice_log1p_ss
train[['SalePrice_ss', 'SalePrice_ss_log1p',
'SalePrice_log1p', 'SalePrice_log1p_ss']].hist(bins=50, figsize=(15, 7));
# ss -> log 취하면 정규분포 형태 X
# log -> ss 표준정규분포 형태로 바뀜
# SalePrice_log1p_ss -> 가장 표준정규분포에 가깝다. 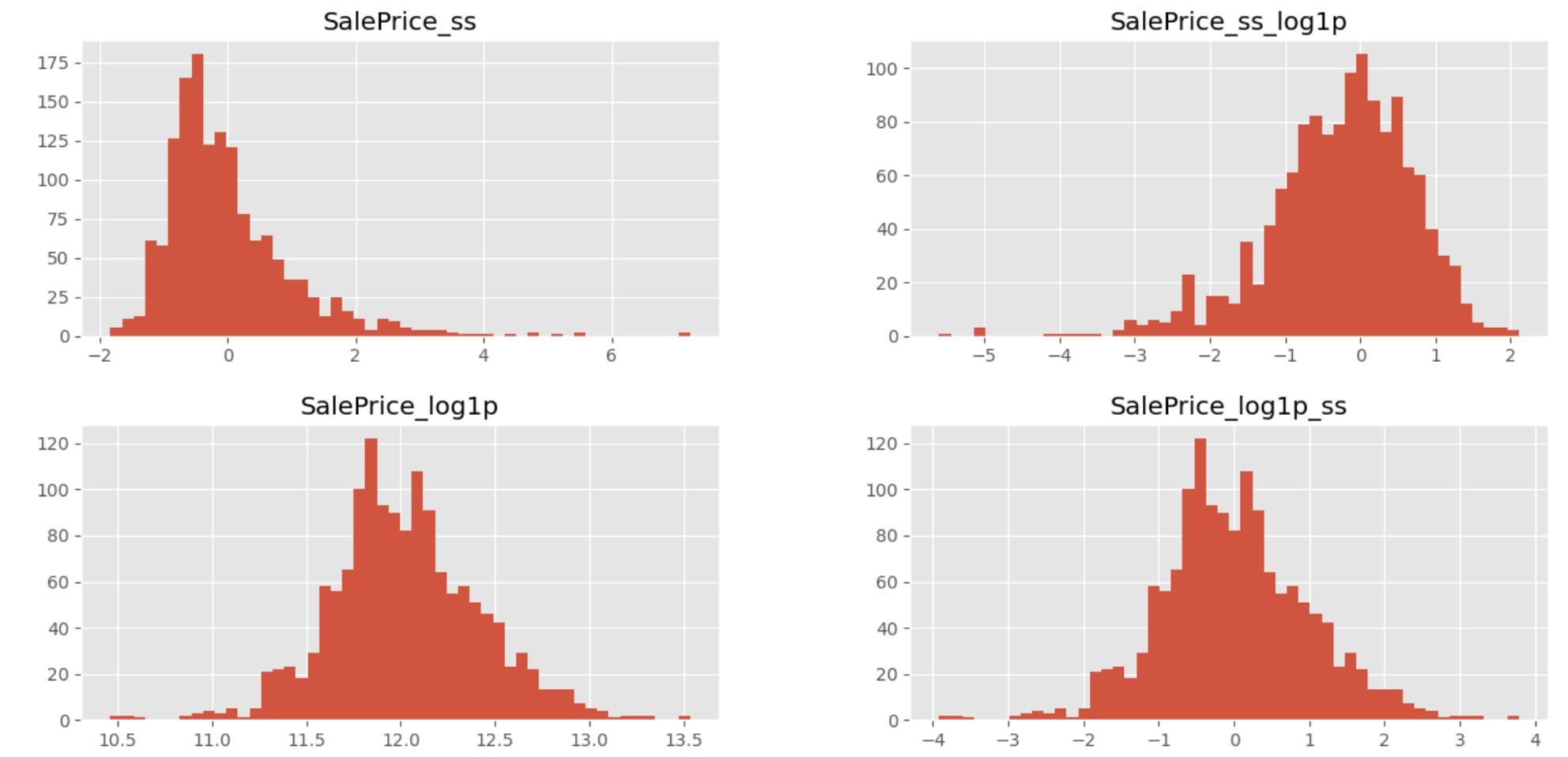
지수함수, 로그함수
x = np.arrange(1, 10, 0.5)
sns.lineplot(x=x, y=x)
sns.lineplot(x=x, y=np.log(x))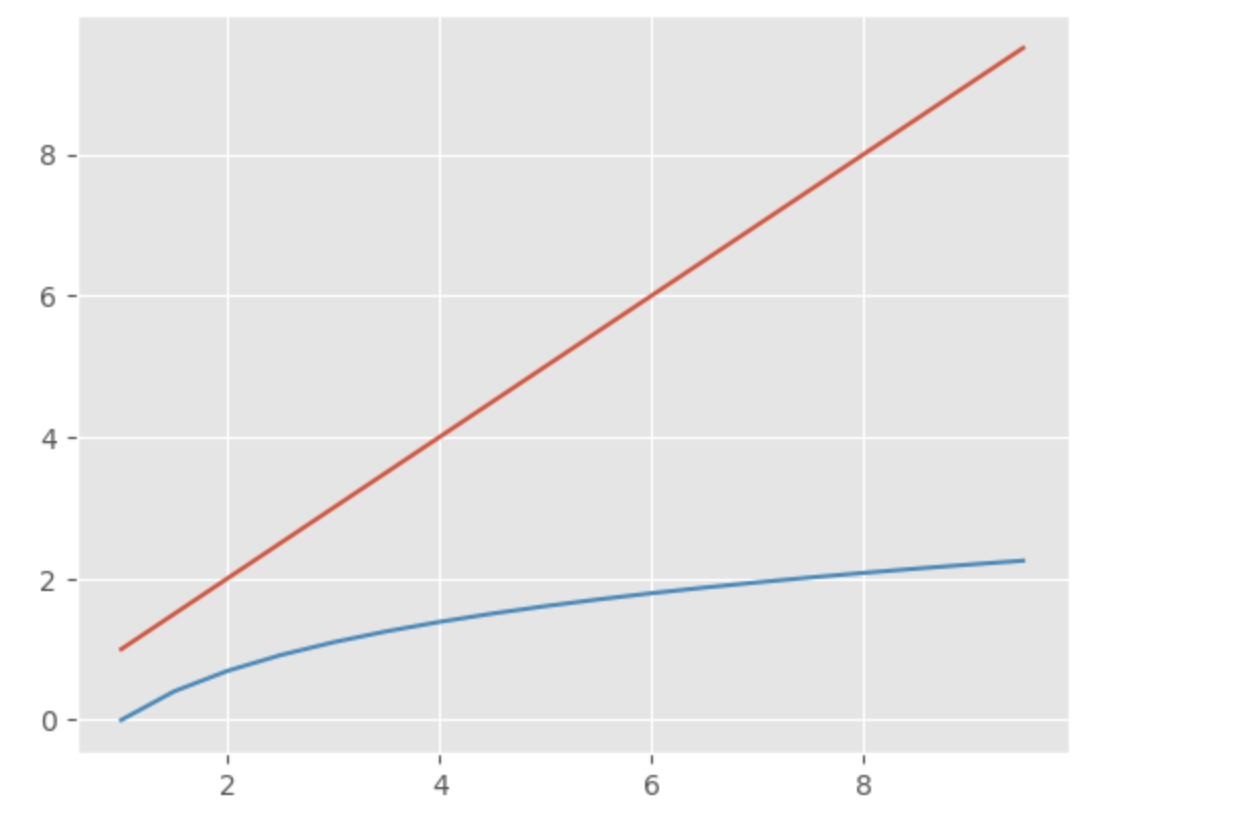
x = np.arange(-10,10,0.5)
sns.lineplot(x=x, y=np.exp(x))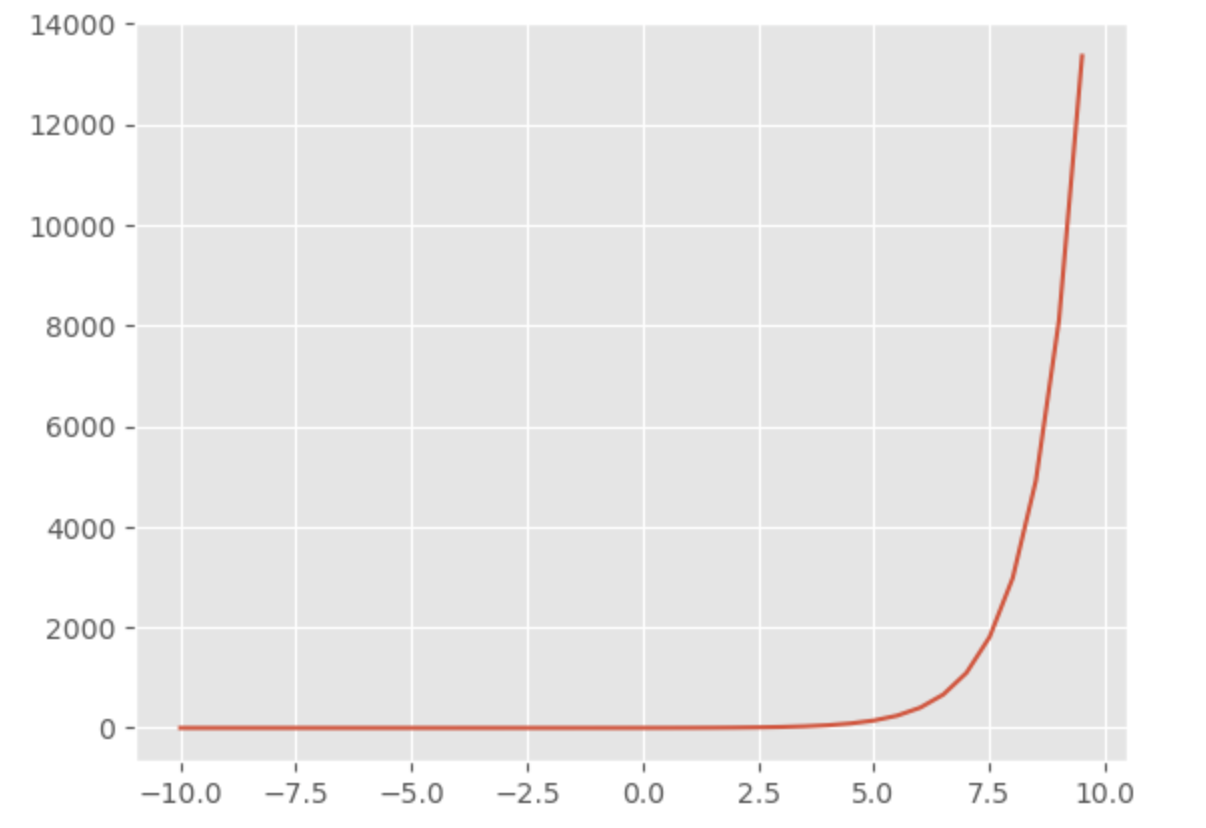
이산화
: numerical feature을 일정 기준으로 나누어 그룹화(binning)하는 것
Ex) 20대 30대 40대 식으로 10살 단위로 분석하면 경향 뚜렷
- 데이터 분석과 머신러닝 모델에 유리
- 유사한 예측 강도를 가진 유사한 속성을 그룹화하면 성능개선에 도움
- Numerical Feature로 인한 과대적합 방지
pd.cut()
: 범위 기준으로 나누는 것 (Equal width binning)
- 절대평가, 고객을 구매금액 구간에 따라 나눔
train['SalePrice_cut'] = pd.cut(train['SalePrice'], bins=4, labels=[1, 2, 3, 4])pd.qcut()
: 빈도 기준으로 나누는 것 (Equal frequency binning)
- 상대평가, 고객의 수 기준으로 나눔
- 비슷한 비율로 나눠준다 -> 알고리즘 성능 높이는데 도움
train['SalePrice_qcut'] = pd.qcut(train['SalePrice'], q=4, labels=[1, 2, 3, 4])# "SalePrice_cut", "SalePrice_qcut" - value_counts
display(train['SalePrice_cut'].value_counts())
display(train['SalePrice_cut'].value_counts(1))
display(train['SalePrice_qcut'].value_counts())
display(train['SalePrice_qcut'].value_counts(1))
1 1100
2 330
3 25
4 5
Name: SalePrice_cut, dtype: int64
1 0.75
2 0.23
3 0.02
4 0.00
Name: SalePrice_cut, dtype: float64
-----------------------------------
2 367
3 366
1 365
4 362
Name: SalePrice_qcut, dtype: int64
2 0.25
3 0.25
1 0.25
4 0.25
Name: SalePrice_qcut, dtype: float64시각화
- hist는 bins로 막대의 개수를 설정할 수 있는 데 pd.cut과 같은 개념
- pd.cut -> 절대평가와 유사
- SalePrice_cut 변수의 빈도를 시각화하면
- SalePrice 의 히스토그램의 막대 4개 설정해서 그린 것과 같음
train['SalePrice'].hist(bins=4, figsize=(5, 3))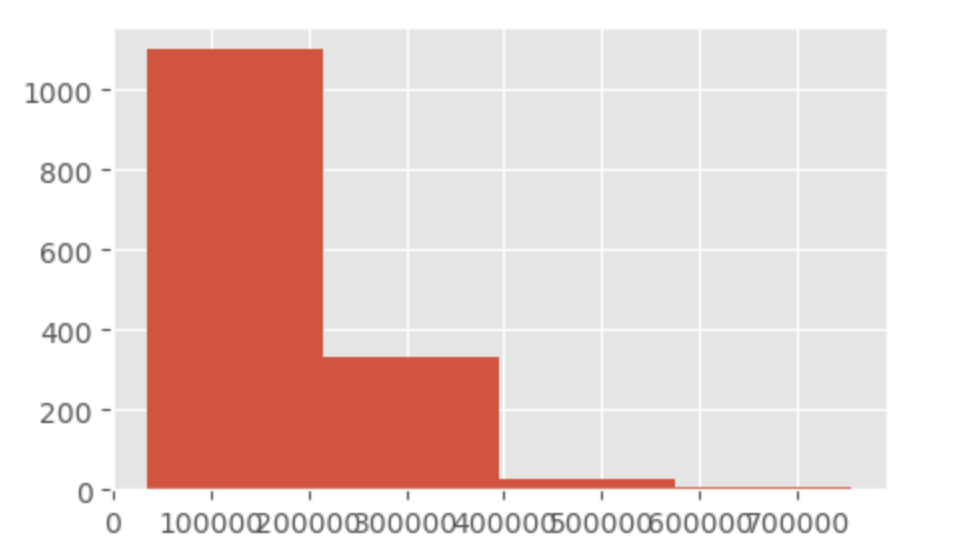
# "SalePrice_cut", "SalePrice_qcut" - countplot
# pd.qcut -> 상대평가와 유사
# pd.qcut 데이터 분할하게 되면 비슷한 비율로 나눠준다.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 3))
sns.countplot(data=train, x='SalePrice_cut', ax=axes[0])
sns.countplot(data=train, x='SalePrice_qcut', ax=axes[1])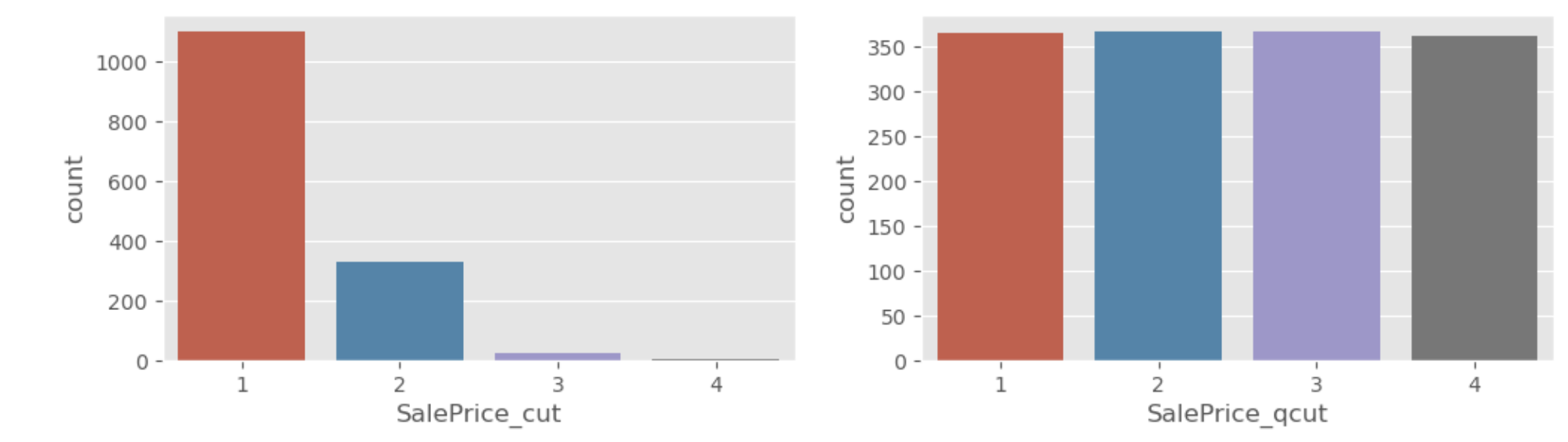
Encoding
: category feature -> numerical feature 변환과정
- Ordinal Encoding : category feature의 고유값들을 임의의 숫자로 변경
- 장점 : 직관적이고 개념이 복잡하지 않고 간단
- 단점 : 데이터의 추가적인 가치를 더해주지 않는다.
그 값이 크고 작은게 의미가 있을 때(순서가 있는 데이터)는 상관 없지만
순서가 없는 데이터에 적용해주면 잘못된 해석을 할 수 있으니 주의
- One-Hot-Encoding : categorical feature을 다른 bool변수 (0 or 1)로 대체하여 해당 관찰에 대해 특정 레이블이 참인지 여부를 나타낸다.
- 장점 : 해당 feature의 모든 정보를 유지
-단점 : 해당 feature에 너무 많은 고유값이 있는 경우 feature을 지나치게 많이 사용
Pandas를 이용한 인코딩
- cat.codes -> Ordinal Encoding
- get_dummies -> One Hot Encoding
- pandas의 get_dummies를 사용하여 인코딩 할 경우 train, test 각각 인코딩
train['MSZoning'].value_counts()
>>>>
RL 1151
RM 218
FV 65
RH 16
C (all) 10
Name: MSZoning, dtype: int64# MSZoning - .cat.codes -> Ordinal Encoding
# 결과가 벡터, 1차원 형태
# 순서가 있는 명목형 데이터에 사용 -> 예) 기간의 1분기 2분기 ...
train['MSZoning'].astype('category').cat.codes.value_counts()
>>>>
3 1151
4 218
1 65
2 16
0 10
dtype: int64# get_dummies -> One-Hot-Encoding
# 결과가 matrix, 2차원 형태
# 순서가 없는 명목형 데이터에 사용 -> 예) 주택의 종류, 음식의 종류
pd.get_dummies(train['MSZoning'])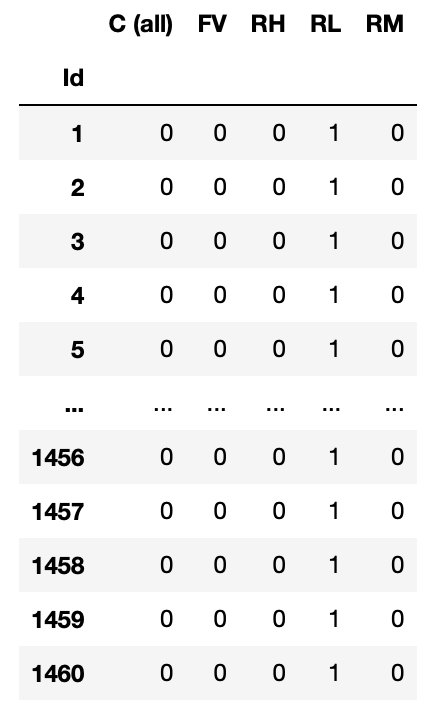
sklearn을 이용한 인코딩
# preprocessing - OneHotEncoder, OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import OrdinalEncoder
# MSZoning_oe
oe = OrdinalEncoder()
MSZoning_oe = oe.fit_transform(train[["MSZoning"]])
# test data -> transform만 해줌
# fit 하는 기준은 train data
ohe = OneHotEncoder(handle_unknown='ignore')
train_ohe = ohe.fit_transform(train[["MSZoning", "Neighborhood"]]).toarray()
test_ohe= ohe.transform(test[["MSZoning", "Neighborhood"]])
pd.DataFrame(train_ohe, columns=ohe.get_feature_names_out()).sample(10)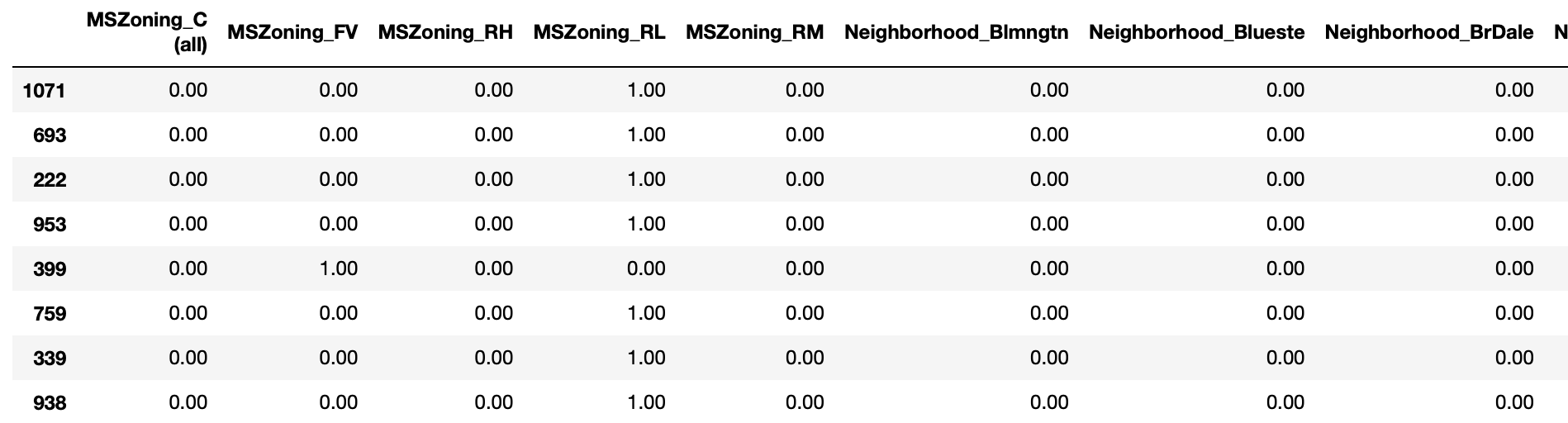
oe.categories_
>>>>
[array(['C (all)', 'FV', 'RH', 'RL', 'RM'], dtype=object)]
ohe.categories_
>>>>
[array(['C (all)', 'FV', 'RH', 'RL', 'RM'], dtype=object),
array(['Blmngtn', 'Blueste', 'BrDale', 'BrkSide', 'ClearCr', 'CollgCr',
'Crawfor', 'Edwards', 'Gilbert', 'IDOTRR', 'MeadowV', 'Mitchel',
'NAmes', 'NPkVill', 'NWAmes', 'NoRidge', 'NridgHt', 'OldTown',
'SWISU', 'Sawyer', 'SawyerW', 'Somerst', 'StoneBr', 'Timber',
'Veenker'], dtype=object)]
print(train_ohe.shape, test_ohe.shape)
>>>> (1460, 30) (1459, 30)Polynomial Expansion 다항식 전개
: 주어진 다항식의 차수 값에 기반하여 파생변수 생성
- 소수의 feature에 기반하게 되면 과대적합이 일어날 확률이 높아짐
- 다항식 전개에 기반한 파생변수를 만들게되면 머신러닝 모델이 여러 Feature에 기반하게 되어 안정성이 높아진다.
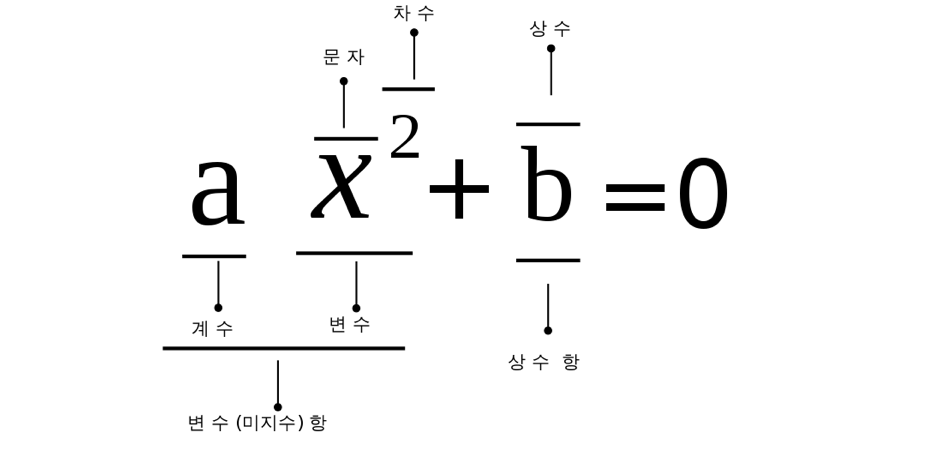
- Polynomial Feature는 [1, a, b, a^2, ab, b^2]
- degree == 차수
- np.reshape : array의 shape 값을 지정해서 shape를 변환
X = np.arange(6).reshape(3, 2)
print(X)
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
pd.DataFrame(X_poly, columns=poly.get_feature_names_out())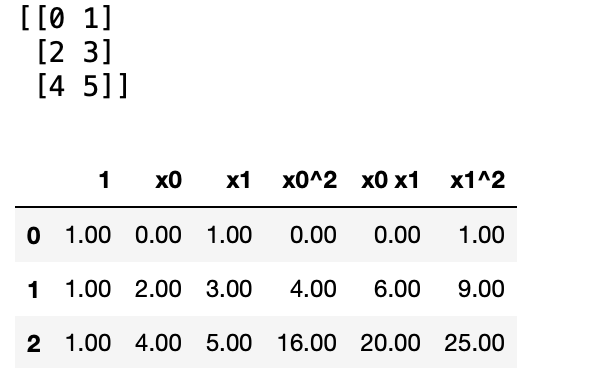
house_poly = poly.fit_transform(train[['MSSubClass', 'LotArea']])
pd.DataFrame(house_poly, columns=poly.get_feature_names_out())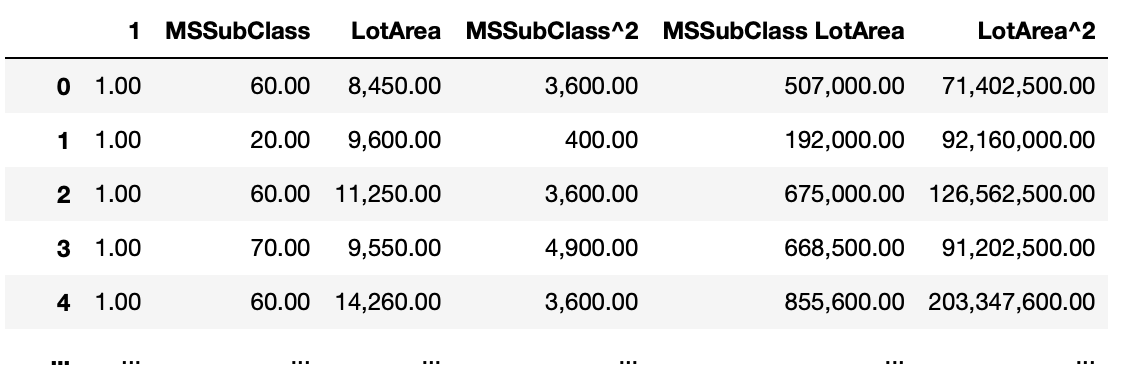
특성 선택
분산기반 필터링
# 범주형 변수 중에 어느 하나의 값에 치중되어 분포되어 있지 않은지 확인
for col in train.select_dtypes(include="O").columns:
if train[col].value_counts(1)[0]*100 >= 90:
print(col)
>>>>
Street
Utilities
LandSlope
Condition2
RoofMatl
BsmtCond
Heating
CentralAir
Electrical
Functional
GarageQual
GarageCond
PavedDrive
MiscFeature
# RoofMatl - value_counts
train['RoofMatl'].value_counts()
>>>>
CompShg 1434
Tar&Grv 11
WdShngl 6
WdShake 5
Metal 1
Membran 1
Roll 1
ClyTile 1
Name: RoofMatl, dtype: int64
# RoofMatl - countplot
plt.figure(figsize=(7, 2))
sns.countplot(data=train, x='RoofMatl')
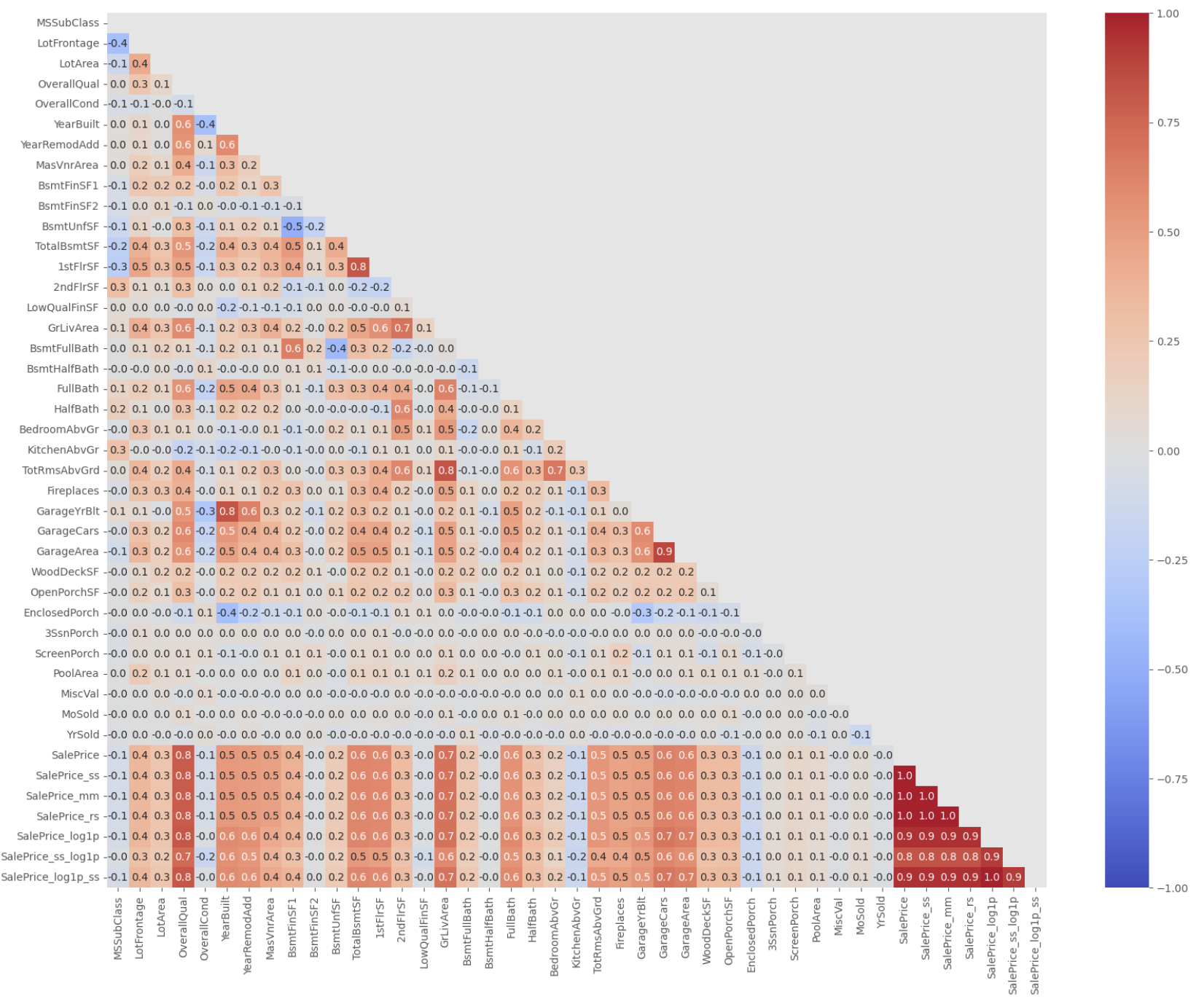
상관관계 기반 필터링
# corr
train_corr = train.corr()
# heatmap
mask = np.triu(np.ones_like(train_corr))
plt.figure(figsize=(20, 15))
sns.heatmap(train_corr, mask=mask, cmap='coolwarm',
annot=True, fmt='.1f',
vmax=1, vmin=-1)

Ⓓ🅰️🅣🄰 ♡♥︎