
계층형 질의
- 테이블에 상위와 하위 데이터가 포함된 데이터
- 사원emp - 상관mgr
순방향 질의
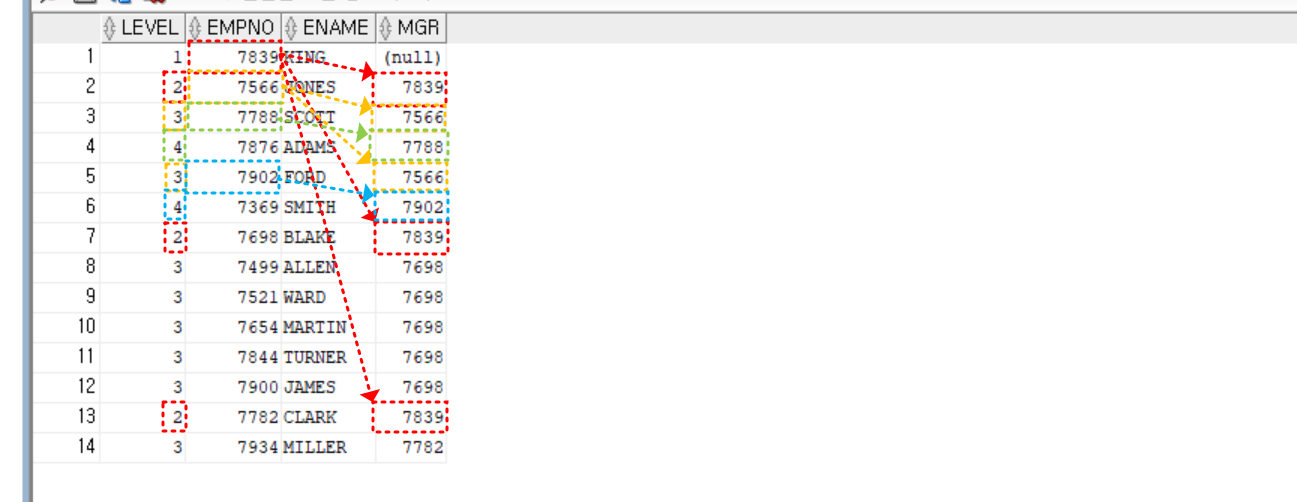
select level, empno, ename, mgr
from emp
start with ename = 'KING'
connect by prior empno = MGR -- PRIOR 자식 = 부모 (순방향 전개)
;
역방향 질의
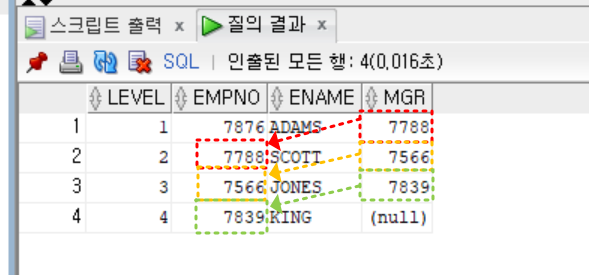
select level, empno, ename, mgr
from emp
start with ename = 'ADAMS'
connect by prior mgr = empno -- PRIOR 부모 = 자식 (역방향 전개)
;
경로 출력
- 순방향 질의
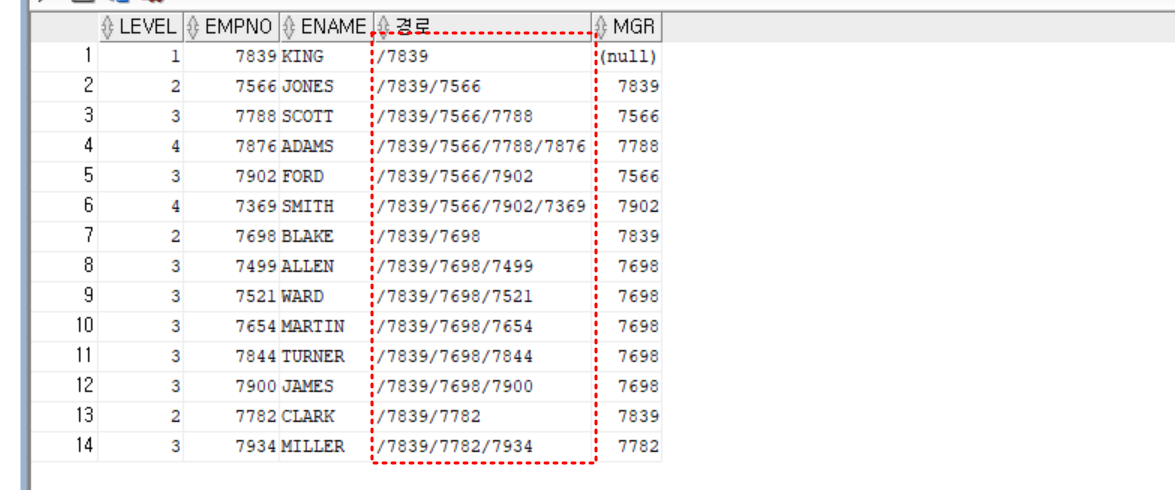
select level, empno, ename, sys_connect_by_path(empno, '/') as 경로, mgr
from emp
start with ename = 'KING'
connect by prior empno = MGR -- PRIOR 자식 = 부모 (순방향 전개)
;
- 역방향 질의
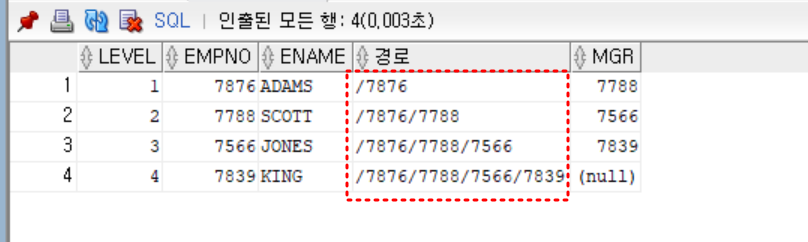
select level, empno, ename, sys_connect_by_path(empno, '/') as 경로, mgr
from emp
start with ename = 'ADAMS'
connect by prior mgr = empno -- PRIOR 부모 = 자식 (역방향 전개)
;
서브쿼리
서로 다른 테이블을 참조하는 메인쿼리와 서브쿼리 간에 공통 칼럼이 존재함.
select dname
from dept
where deptno = (select deptno
from emp
where ename = 'SCOTT')
;- 실습
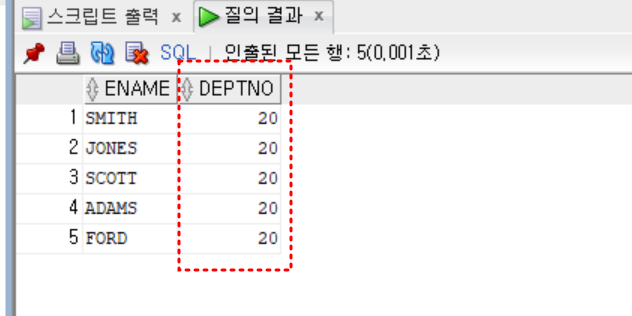
- scott과 같은 부서에서 근무하는 사원의 이름과 부서번호
select ename, deptno
from emp
where deptno = (select deptno
from emp
where ename = 'SCOTT')
;
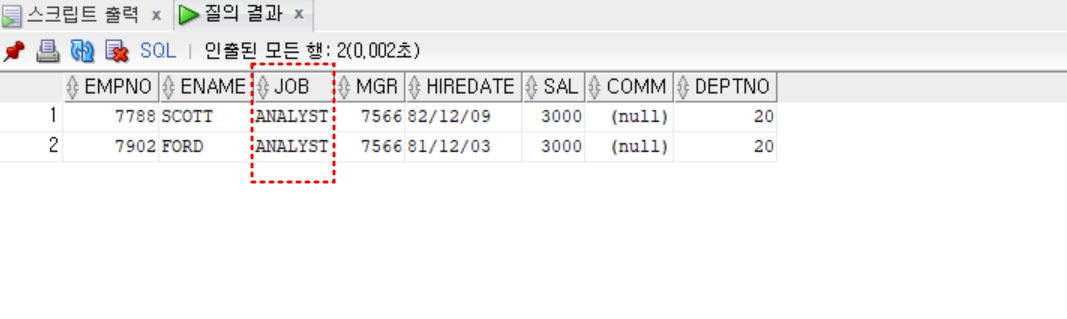
- 실습
- scott과 동일한 직무를 가진 사원
select *
from emp
where job = (select job
from emp
where ename = 'SCOTT')
;
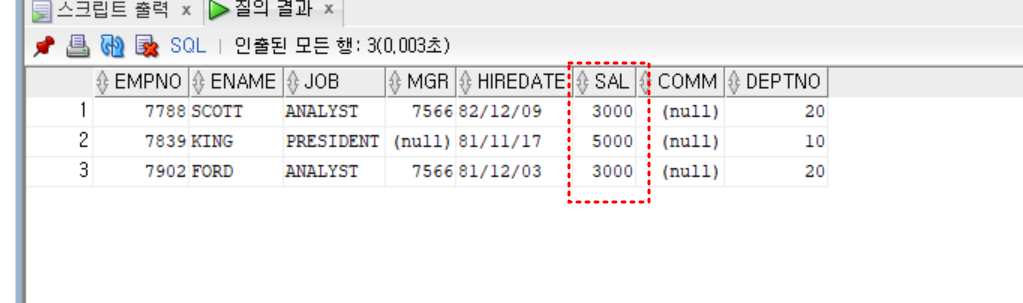
- 실습
- scott의 급여와 동일하거나 더 많이 받는 사원
select *
from emp
where sal >= (select sal
from emp
where ename = 'SCOTT')
;
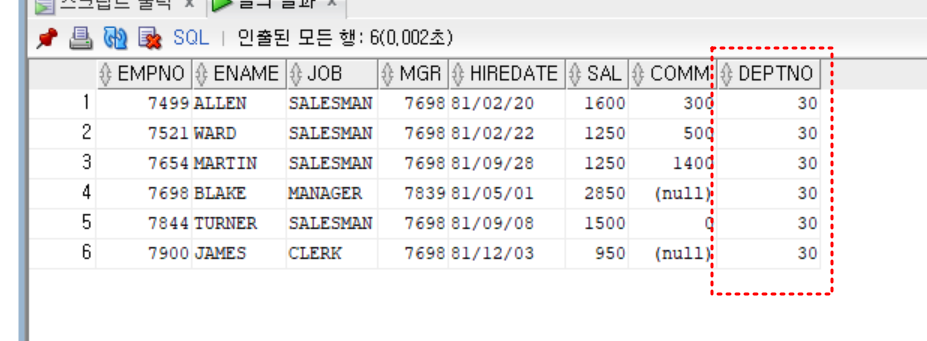
- 실습
- sales 부서에서 근무하는 모든 사원
select *
from emp
where deptno = (select deptno
from dept
where dname = 'SALES')
;
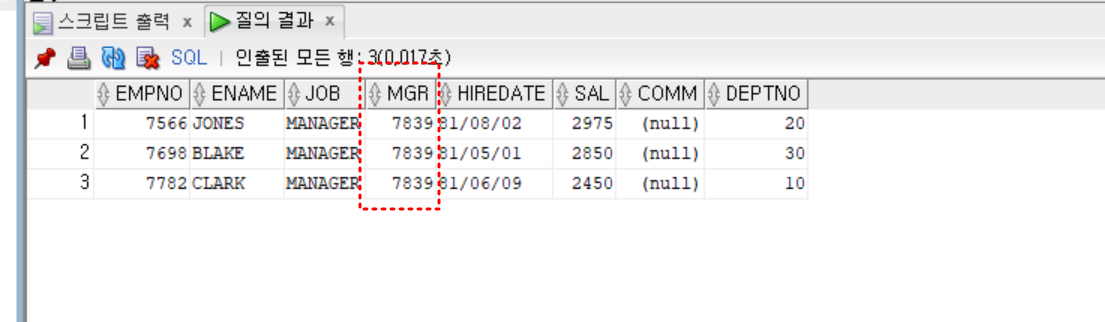
- 실습
- 매니저가 KING인 사원
select *
from emp
where mgr = (
select empno
from emp
where ename = 'KING')
;
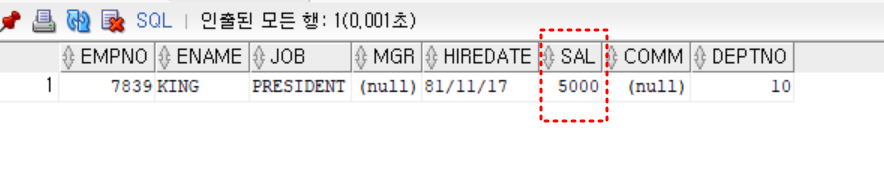
- 실습
- 스칼라 서브쿼리: select절에 오는 서브쿼리로 1행만 반환
- 급여가 가장 많은 사원
select *
from emp
where sal = (select max(sal) from emp)
;
IN, Exists
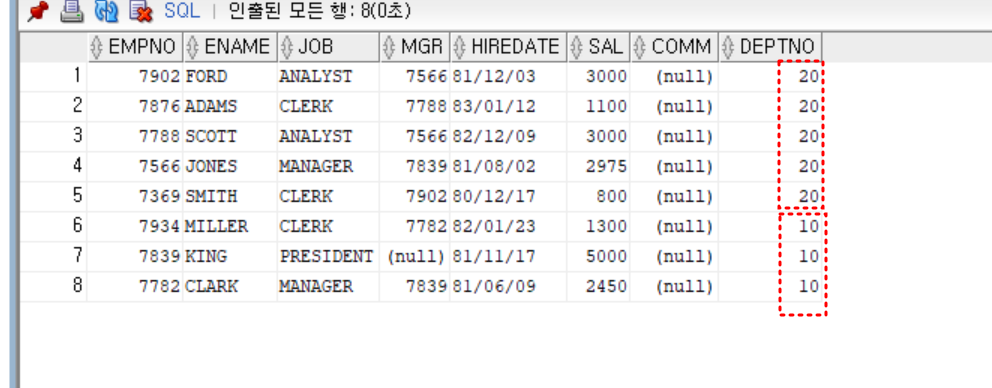
- 실습
- 급여가 3000 이상인 사원이 존재하는 부서의 직원 출력
select *
from emp
where deptno in (
select distinct deptno
from emp
where sal >= 3000
)
;-- 메인쿼리의 비교컬럼 deptno 서브쿼리의 조인조건으로 이동
select *
from emp e
where exists (
select distinct deptno
from emp
where deptno = e.deptno
and sal >= 3000
)
;차이점:
-
성능: 두 번째 쿼리(
EXISTS)는 첫 번째 쿼리(IN)보다 성능이 더 좋을 수 있습니다.EXISTS는 조건을 만족하는 첫 번째 행을 찾으면 바로 참으로 평가하고 다음 행으로 넘어갑니다. 반면,IN절은 서브쿼리의 모든 결과를 메모리에 저장하고 메인 쿼리의 각 행과 비교해야 합니다. -
중복 제거: 첫 번째 쿼리는
distinct를 사용하여 중복된 부서 번호를 제거합니다. 두 번째 쿼리에서exists는 단순히 해당 조건을 만족하는지 여부만 확인하므로distinct가 필요하지 않습니다. -
결과적으로 두 쿼리는 동일한 결과를 반환하지만, 데이터베이스의 구현과 데이터의 분포에 따라 성능 차이가 있을 수 있습니다.
EXISTS를 사용하는 두 번째 쿼리가 일반적으로 더 효율적일 가능성이 높습니다.
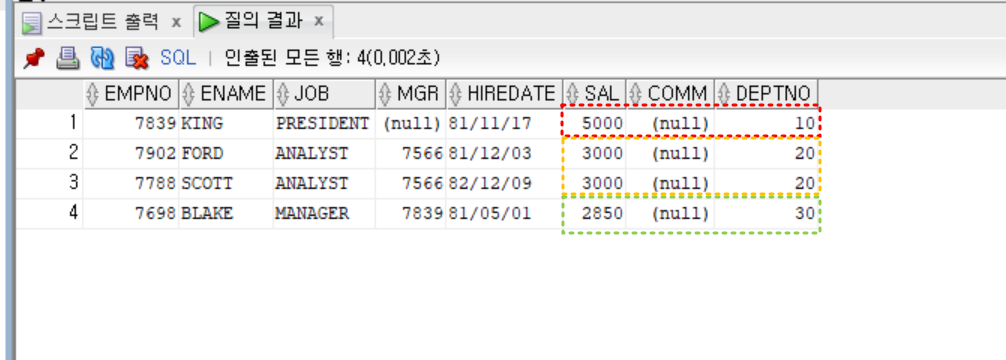
- 실습
- 부서별로 가장 급여를 많이 받는 사원의 정보
select *
from emp
where sal in (
select max(sal)
from emp
group by deptno
)
order by deptno
;
ALL
- 실습
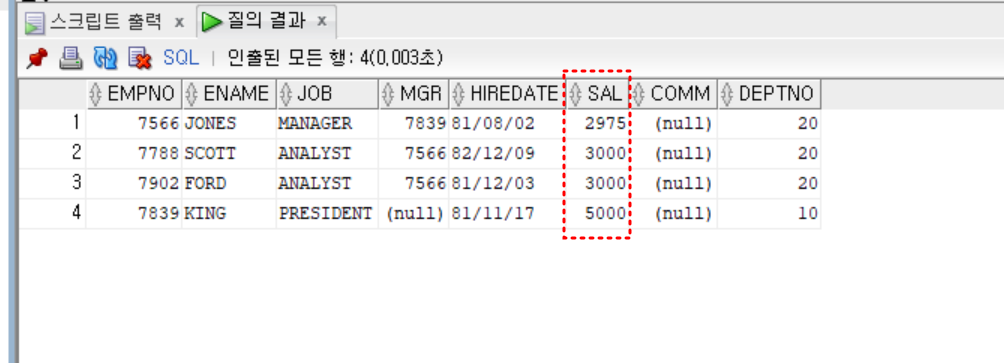
- 30번 부서 사원들 중 부서를 가장 많이 받는 사원보다 더 많은 급여를 받는 사원
select *
from emp
where sal > all (
select sal
from emp
where deptno = 30)
;select *
from emp
where sal > (
select max(sal)
from emp
where deptno = 30)
;
- 실습
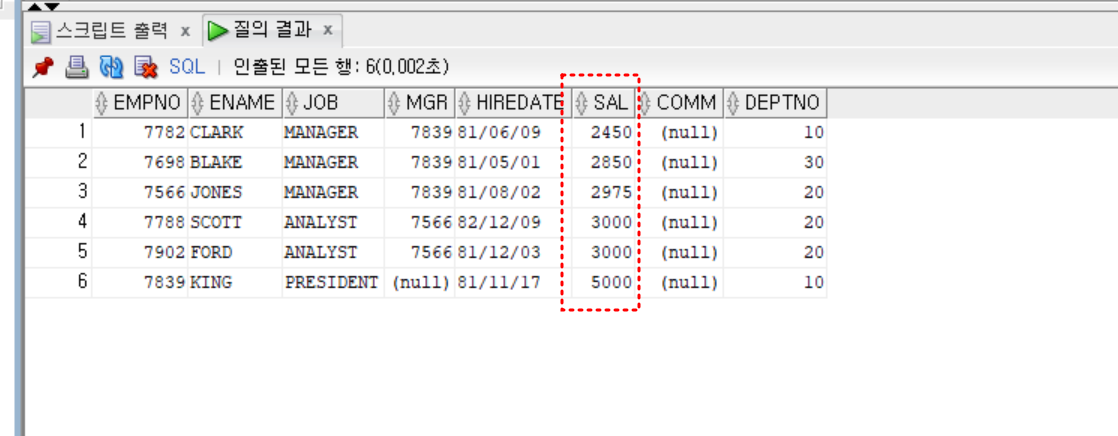
- 영업 사원 모든 급여들보다 급여를 많이 받는 사원들 출력. 단, 영업사원은 출력하지 않음
select *
from emp
where sal > (
select max(sal)
from emp
where job = 'SALESMAN')
;select *
from emp
where sal > ALL (
select sal
from emp
where job = 'SALESMAN')
; 
ANY
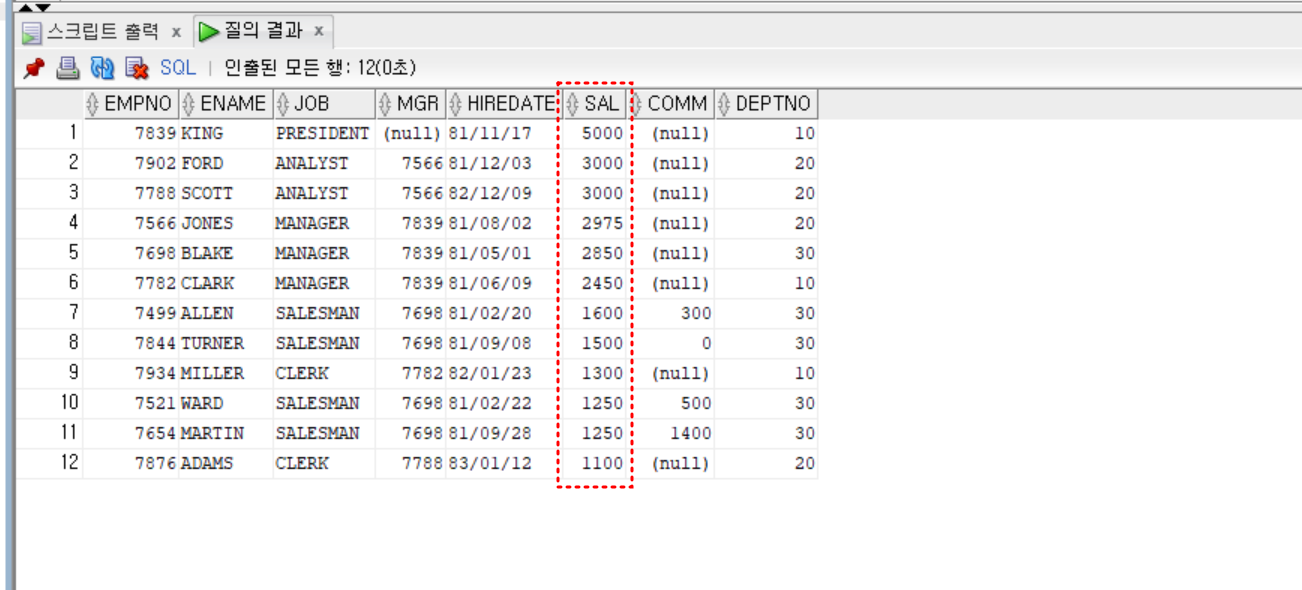
- 실습
- 부서번호가 30번인 사원들의 급여 중 값들 중에 임의의 한 개 보다 많은 급여를 받는 사원
select *
from emp
where sal > any (
select sal
from emp
where deptno = 30)
;select *
from emp
where sal > (
select min(sal)
from emp
where deptno = 30)
;
다중서브쿼리
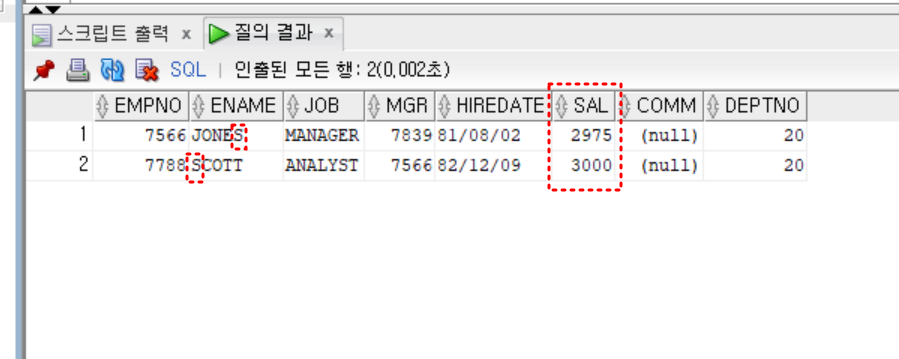
- 실습
- 자신의 급여가 평균급여보다 많고 이름에 S가 들어가는 사원
select *
from emp
where sal > (
select avg(sal)
from emp)
and ename like '%S%'
;
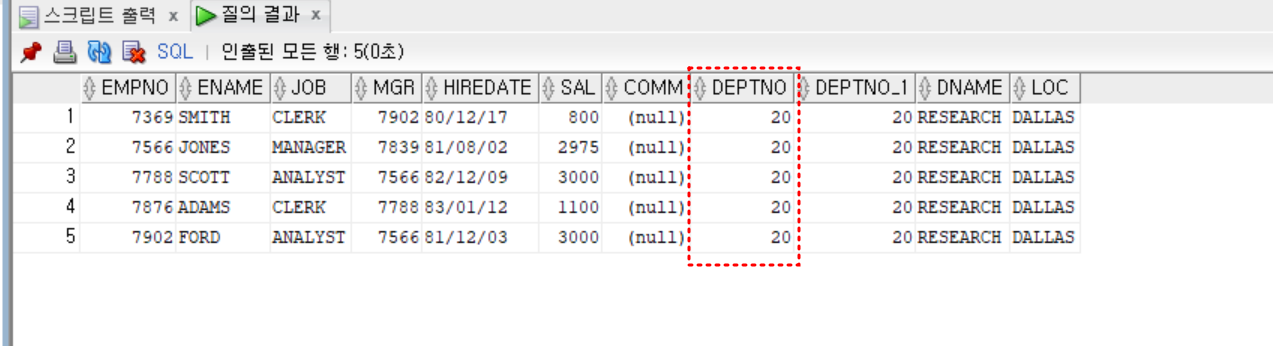
- 실습
- 자신의 급여가 평균급여보다 많고 이름에 S가 들어가는 사원과 동일한 부서에서 근무하는 모든 직원
select *
from emp, dept
where emp.deptno = dept.deptno
and emp.deptno in (
select distinct deptno
from emp
where sal > (
select avg(sal)
from emp)
and ename like '%S%')
;
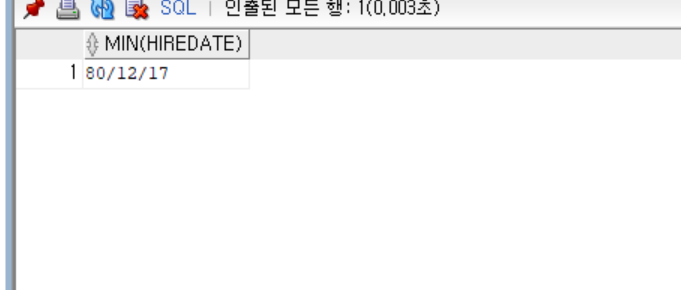
- 실습
- 입사일이 2번째로 빠른 사람
- step 1
- 가장 빠른 입사일 구하기
select min(hiredate) from emp
;
- step 2
- 두 번째 입사일 구하기
select min(hiredate)
from emp
where hiredate > (select min(hiredate) from emp);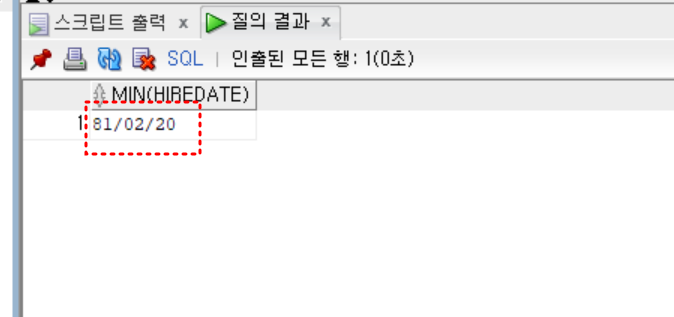
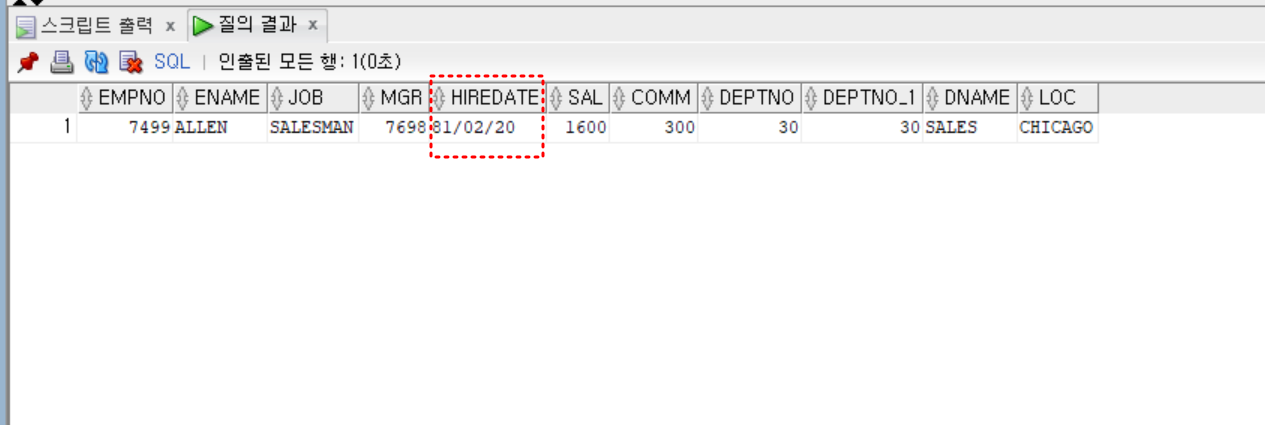
- step 3
- 입사일이 2번째로 빠른 사람 구하기
select *
from emp e, dept d
where e.deptno = d.deptno
and hiredate = (
select min(hiredate)
from emp
where hiredate > (select min(hiredate) from emp))
;
퀴즈
-- Q1
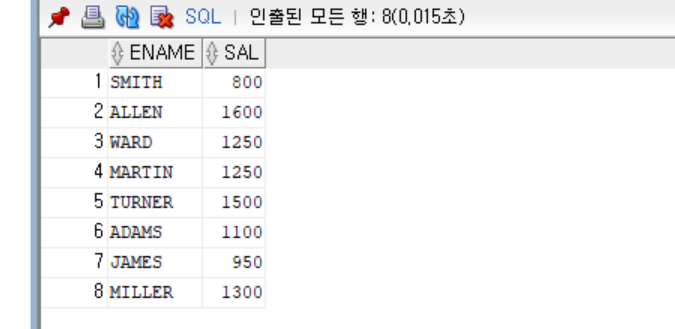
-- scott의 급여에서 1000을 뺸 급여보다 적게 받는 사원
select ename, sal
from emp
where sal < (
select sal
from emp
where ename = 'SCOTT') - 1000
;
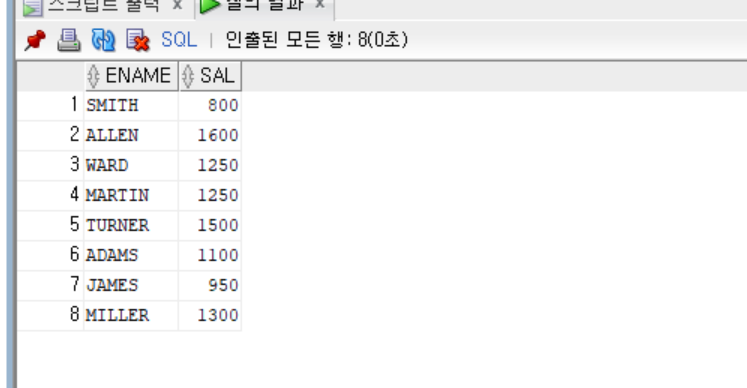
-- Q2
-- job이 manager인 사원들 중 최소급여를 받는 사원보다 급여가 적은 사원
select ename, sal
from emp
where sal < (
select min(sal)
from emp
where job = 'MANAGER')
;
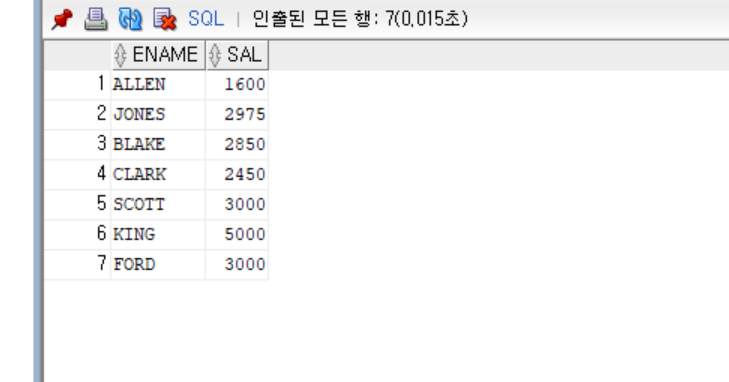
-- Q3
-- WARD가 소속된 부서 사원들의 평균 급여보다, 급여가 높은 사원
select ename, sal
from emp
where sal > (
select avg(sal)
from emp
where deptno = (
select deptno
from emp
where ename = 'WARD'))
;
-- Q4
-- 이름에 K가 들어가는 사원들 중 가장 급여가 적은 사원
select min(sal)
from emp
where ename like '%K%';
select *
from emp, dept
where emp.deptno = dept.deptno
and sal = (
select min(sal)
from emp
where ename like '%K%')
;
-- Q5
-- 두 번째로 많은 급여를 받는 사원의 이름과 급여
select max(sal)
from emp
;
select max(sal)
from emp
where sal < (select max(sal) from emp)
;
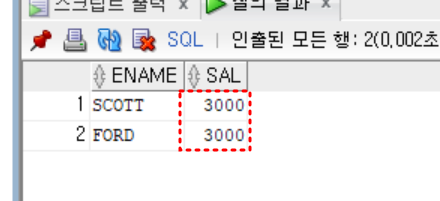
select ename, sal
from emp
where sal = (
select max(sal)
from emp
where sal < (select max(sal) from emp))
;
-- Q6
-- 커미션을 받는 부서명 출력
select distinct dname
from emp, dept
where emp.deptno = dept.deptno
and comm is not null
;
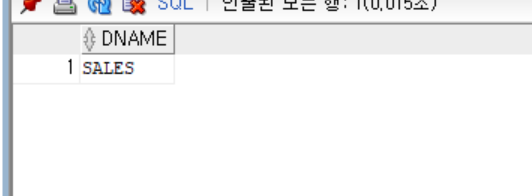
-- 커미션을 받는 부서명 출력(EXISTS 사용)
select distinct dname
from dept
where exists (
select *
from emp
where emp.deptno = dept.deptno
and emp.comm is not null
);
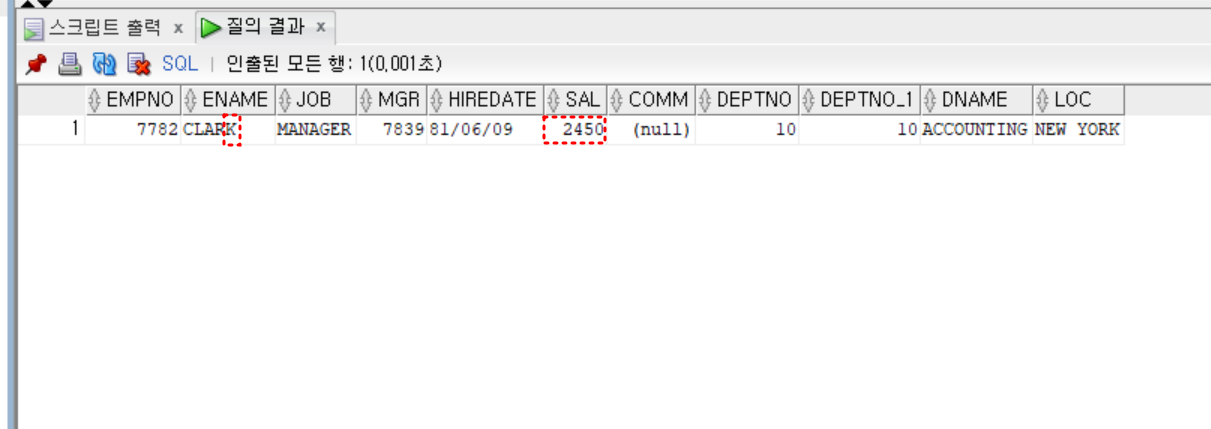
-- Q7
-- 최고 급여를 받는 사원과 같이 근무하는 모든 사원
select max(sal)
from emp
;
select deptno
from emp
where sal = (select max(sal) from emp)
;
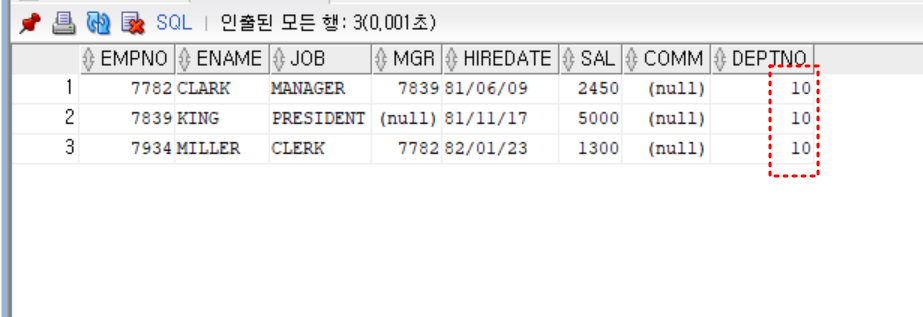
select *
from emp
where deptno = (
select deptno
from emp
where sal = (select max(sal) from emp))
;
Create
create table emp01_tbl (
empno number(4),
ename nvarchar2(20),
sal number(7, 2),
jumin char(13),
hiredate date,
resume clob
);- empno: 사원 번호를 저장하는 숫자(4자리) 데이터 형식의 열
- ename: 사원 이름을 저장하는 NVARCHAR2(20) 데이터 형식의 열
- sal: 급여를 저장하는 숫자(7,2) 데이터 형식의 열 (7자리 정수와 소수점 이하 2자리)
- jumin: 주민등록번호를 저장하는 고정 길이 문자열(char) 열 (13자리)
- hiredate: 입사일을 저장하는 날짜(date) 열
- resume: 이력서나 긴 텍스트를 저장하는 CLOB(Character Large Object) 열
- 테이블 복사
create table emp02
as
select * from emp;- 테이블의 구조만 복사 (데이터는 복사하지 않음)
create table emp06
as
select * from emp where 1=0; Alter
- 실습
desc emp01;
- 실습
- 컬럼 추가
alter table emp01
add (job varchar2(9))
;
desc emp01;
- 실습
- 컬럼의 유형 변경
alter table emp01
modify (job varchar2(30))
;
desc emp01;
- 실습
- 컬럼 제거
alter table emp01
drop (job)
;
desc emp01;
- 실습
- 컬럼 이름 변경
alter table emp01
rename column ename to emp_name
;
desc emp01
;
- 실습
-- 테이블 이름 변경
alter table emp01
rename to emp01_tbl
;
-- 테이블 삭제
drop table emp01;
-- 모든 행 삭제. 테이블은 미삭제
truncate table emp01;
-- comment 작성
comment on column emp01.empno is '사번'; - 실습
create table 점수 (
학번 char(4),
국어 number(3),
수학 number(3)
)
;
alter table 점수
rename to score
;
alter table score
rename column 학번 to hakbun
;
alter table score
rename column 국어 to kor
;
alter table score
rename column 수학 to math
;
comment on column score.hakbun is '학생번호';
comment on column score.kor is '국어점수';
comment on column score.math is '수학점수'; - 실습
-- 영어 칼럼 추가
alter table score
add (eng number(3))
;
comment on column score.eng is '영어점수';
-- 중간/기말점수 상태구분코드 컬럼 추가
alter table score
add (div char(1))
;
-- 학번 컬럼 유형 변경
alter table score
modify (hakbun char(6))
;- 실습
데이터베이스 내의 사용자 테이블 목록 확인
-- DD
select * from user_tables
order by table_name;
Insert
- 실습
-- dept 테이블의 구조만 복사. 데이터는 복사하지 않음
create table dept01
as
select * from dept where 1=2
;
-- 데이터 추가
insert into dept01 (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK')
;
insert into dept01
values (40, 'OPERATIONS', NULL)
;
-- dept 테이블의 행을 복사
insert into dept01
select * from dept
;- 실습
- 입사년도가 82년인 사원의 입사일을 1개월 이전 날짜로 수정
create table emp_test01
as
select * from emp
;
update emp_test01
set hiredate = add_months(sysdate, -1)
where to_char(hiredate, 'yy') = 82
;
select * from emp_test01
order by hiredate desc;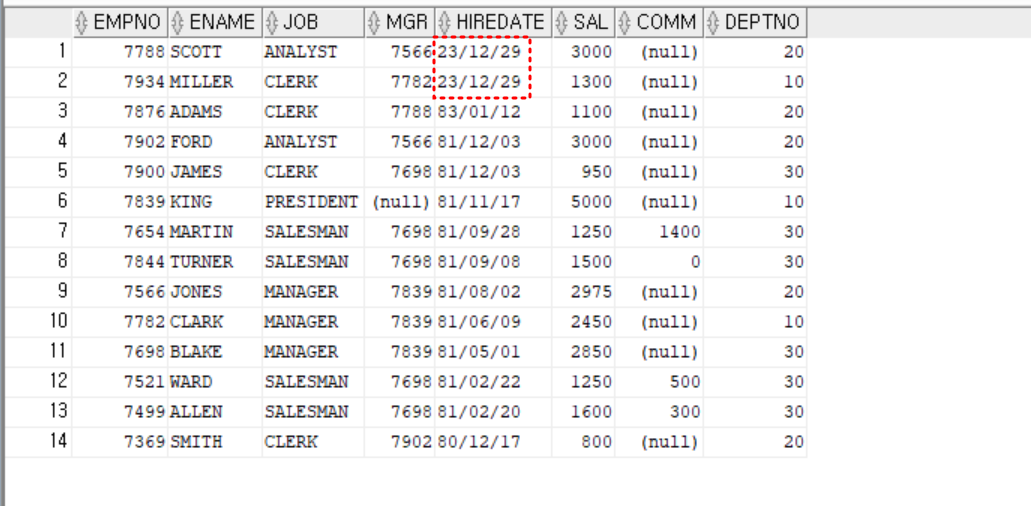
Delete
delete from dept01
where deptno = 40;
select * from dept01;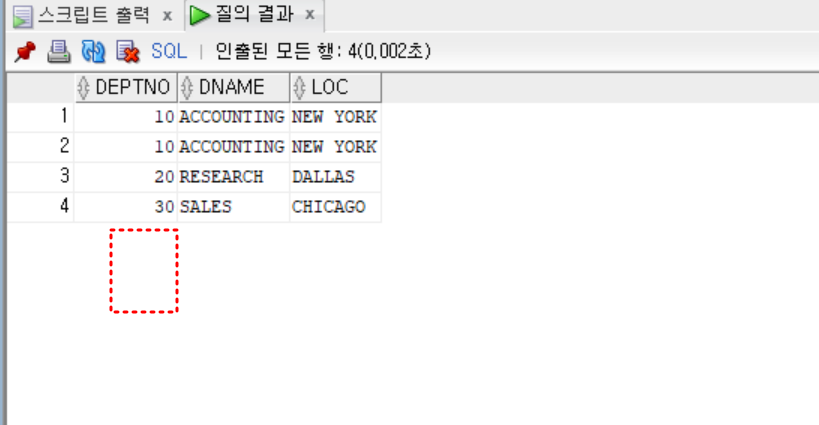
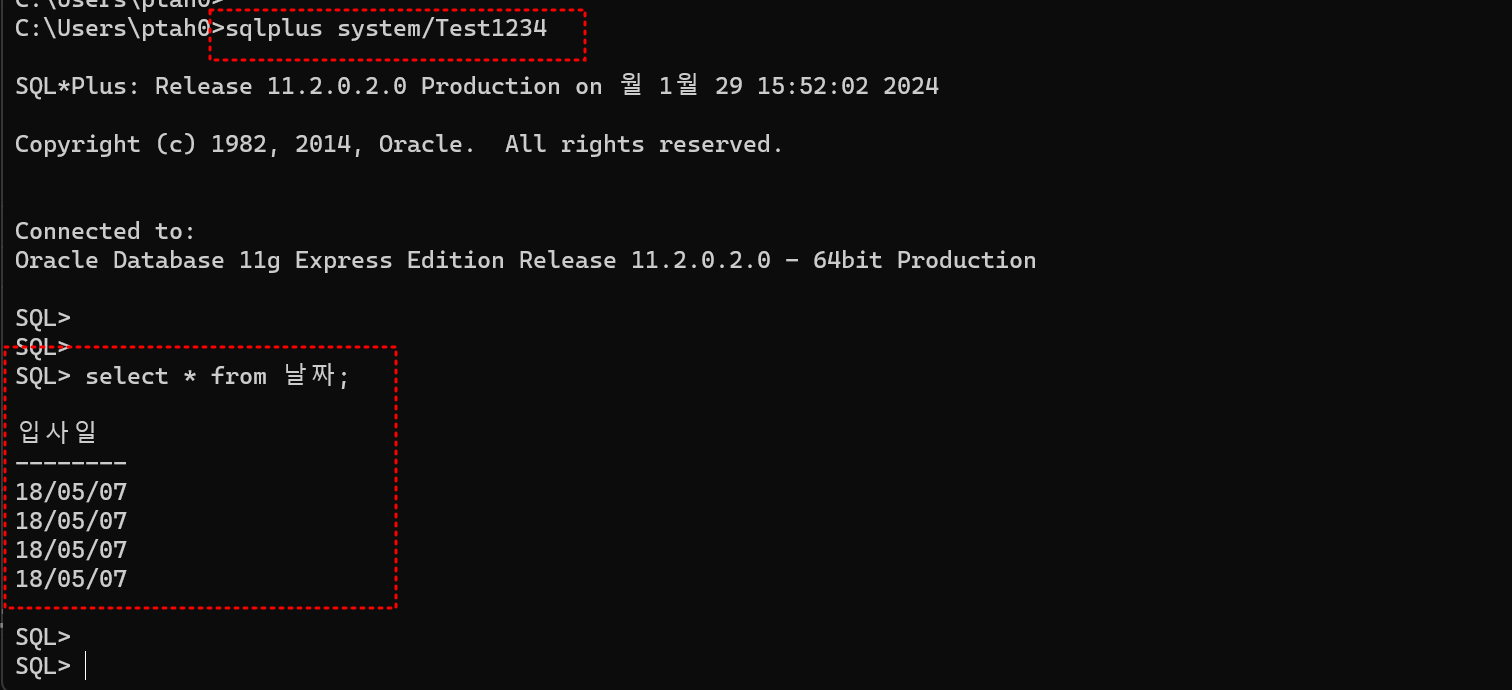
- 실습
create table 날짜 (
입사일 date
)
;
insert into 날짜 values('20180507'); -- ok
insert into 날짜 values('2018-05-07'); -- ok
insert into 날짜 values('2018/05/07'); -- ok
insert into 날짜 values('2018/05/07 12:24:00'); -- 에러 발생
insert into 날짜 values
(to_date('2018/05/07 12:24:00', 'yyyy/mm/dd hh24:mi:ss')); -- to_date로 형 맞추기 Commit, Rollback
Lock
- delete 수행
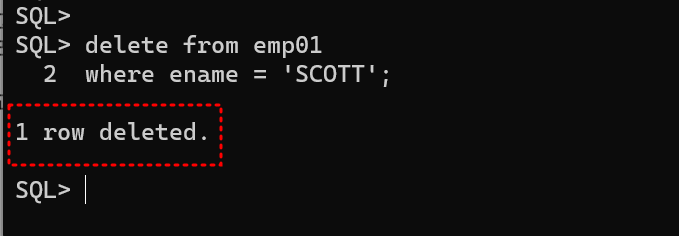
- delete 수행
- update 수행 시 Lock 발생
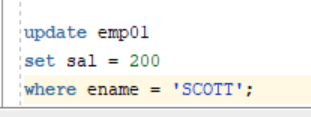
- rollback 수행
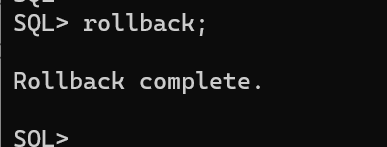
- lock 풀리며 update 완료됨
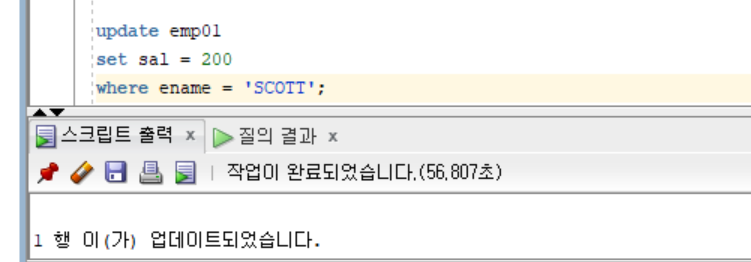
-
다시 SCOTT 제거 시도하면 lock 발생
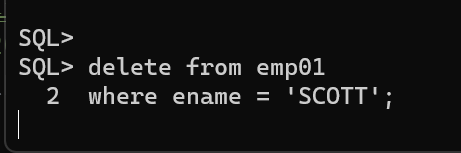
-
commit 수행하기
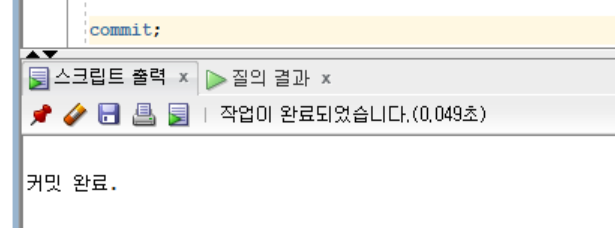
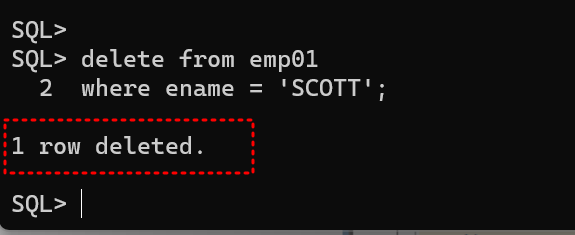
-
lock이 풀리며 성공적으로 delete 수행됨
퀴즈
--도서
CREATE TABLE BOOK (
bno NUMBER(3) NOT NULL,--도서번호
bname VARCHAR2(20) NOT NULL,--도서명
bdesc VARCHAR2(4000),--도서설명
bprice NUMBER--가격
);
INSERT INTO BOOK VALUES (101 ,'오라클1', '기본',1000);
INSERT INTO BOOK VALUES (102 ,'오라클2', '기본',2000);
INSERT INTO BOOK VALUES (201 ,'자바1', '기본',2000);
--회원
CREATE TABLE MEM(
MEMID VARCHAR2(20) NOT NULL,--회원아이디
MEMNAME VARCHAR2(20),--회원명
MEMADDR VARCHAR2(20)----회원주소
);
INSERT INTO MEM(MEMID ,MEMNAME ,MEMADDR )
VALUES('hong','홍길동','서울');
INSERT INTO MEM(MEMID ,MEMNAME ,MEMADDR )
VALUES('lee','이순신','서울');
--주문
CREATE TABLE BORDER(
-- 주문번호(1,2,.. 일련번호)
ONO NUMBER NOT NULL,
-- 주문도서번호
BNO NUMBER ,
--주문자ID
MEMID VARCHAR2(20),
--주문도서수량
OQTY NUMBER
);--- Q1
-- 홍길동이 도서번호 101인 도서 2권 주문
insert into border
values (1, 101, 'hong', 2);
select * from border;--- Q2
-- 이순신이 도서번호 201인 도서 3권 주문
insert into border
values (2, 201, 'lee', 3);
select * from border;--- Q3
-- 이순신의 주문도서수량을 5권으로 수정
update border
set oqty = 5
where ono = (
select ono
from border
where memid = 'lee'
)
;
select * from border;--- Q4
-- 김유신이 회원가입 후 도서번호 201인 도서 1권 주문
insert into mem
values ('kim', '김유신', '부산');
select * from mem;
insert into border
values (3, 201, 'kim', 1);
select * from border;--- Q5
-- 주문한 회원명 및 도서명을 주문수량과 함께 출력
-- 단, 주문테이블 기준으로 세개 테이블 연결조인
select * from book; -- bno, bname, bdesc, bprice
select * from mem; -- memid, memname, memaddr
select * from border; -- ono, bno, memid, oqty
select memname, bname, oqty
from book, mem, border
where border.bno = book.bno
and border.memid = mem.memid
;--- Q6
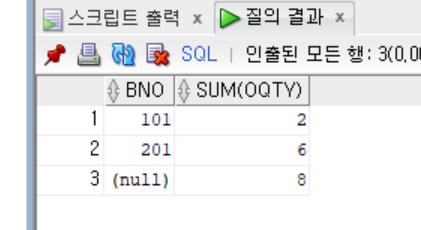
-- 도서번호별로 주문한 총 도서수량 출력
select *
from book, mem, border
where border.bno = book.bno
and border.memid = mem.memid
;
select border.bno, sum(oqty)
from book, mem, border
where border.bno = book.bno
and border.memid = mem.memid
group by rollup(border.bno)
order by bno
;
Constraint
create table emp02 (
empno number(4) constraint emp05_empno_pk primary key,
email varchar2(50) not null unique,
ename varchar(2) not null,
job varchar2(9),
deptno number(2) not null
);
insert into emp02
values (1, 'A', 'A', 'SALESMAN', 10); -- insert 수행
insert into emp02
values (1, 'A', 'A', 'SALESMAN', 10); -- insert 한번 더 수행 시 에러 발생 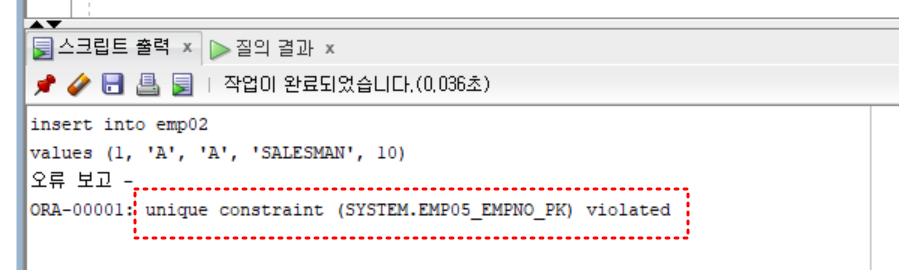
create table dept06 (
deptno number(2) primary key,
dname varchar2(20) not null,
loc varchar2(20)
);
insert into dept06
select * from dept
;
create table emp06 (
empno number(4) constraint emp06_empno_pk primary key,
ename varchar2(10) constraint emp_ename_nn not null,
job varchar2(9),
deptno number(2) constraint emp06_deptno_fk references dept06(deptno)
)
;
insert into emp06
values (7566, 'JONES', 'MANAGER', 30); -- ok
insert into emp06
values (7567, 'JONES2', 'MANAGER', 50); -- not ok 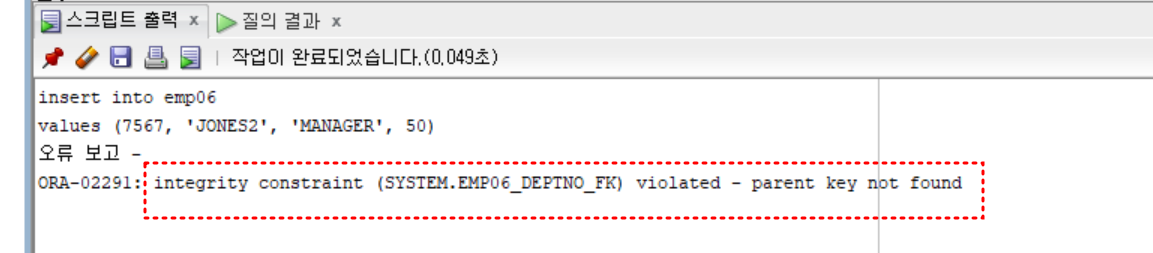

떼껄룩~ 이번주도 화이팅합시다