
Check
create table emp07 (
empno number(4) constraint emp07_empno_pk primary key,
ename varchar2(10) constraint emp07_ename_nn not null,
sal number(7, 2) constraint emp07_sal_ck check (sal between 500 and 5000),
gender varchar2(1) constraint emp07_gender_ck check (gender in ('m', 'f'))
)
;
insert into emp07
values (7566, 'JONES', 50, 'm'); -- sal이 500~5000이 아니라서 에러 발생 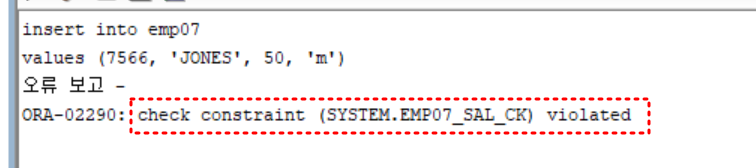
Partitioning
create table emp_part (
empno number(4) not null,
ename varchar2(10),
job varchar2(9),
mgr number(4),
hiredate date,
sal number(7, 2),
comm number(7, 2),
deptno number(2)
) partition by range(sal)
(
partition emp_part1 values less than(1000),
partition emp_part2 values less than(2000),
partition emp_part3 values less than(3000),
partition emp_default values less than(maxvalue)
);
select *
from emp_part
partition(emp_part1)
;
-- 자동으로 파티션키 기준으로 파티션 테이블 입력
insert into emp_part
values()
;
-- 파티션 테이블 추가
alter table emp_part
add partition emp_part0
values less than(500)
;
-- 파티션 테이블 제거
alter table emp_part
drop partition emp_part0
;
-- 파티션의 data truncate(제거)
alter table emp_part
truncate partition emp_part1
;
emp_part라는 테이블을 생성하고, sal(급여) 컬럼에 따라 파티션을 나누는 명령입니다. 각 파티션은 sal 값의 범위에 따라 분할됩니다.
파티션 설정 (partition by range(sal)): 이 테이블은 sal(급여) 컬럼을 기준으로 범위 파티셔닝(range partitioning)이 적용됩니다.
partition emp_part1 values less than(1000): 급여가 1000 미만인 직원들을 위한 파티션.partition emp_part2 values less than(2000): 급여가 1000 이상 2000 미만인 직원들을 위한 파티션.partition emp_part3 values less than(3000): 급여가 2000 이상 3000 미만인 직원들을 위한 파티션.partition emp_default values less than(maxvalue): 급여가 3000 이상인 직원들을 위한 기본 파티션.
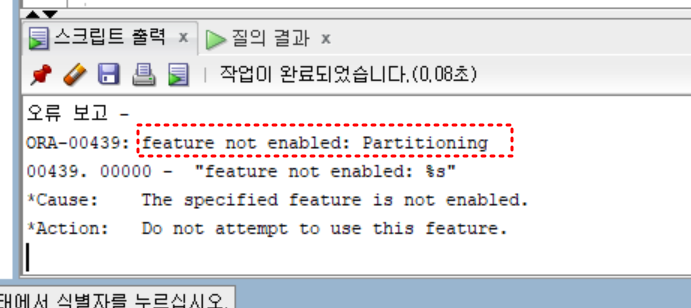
SE 버전은 파티셔닝 기능 사용할 수 없음ㅠ
View
create table emp_copy
as
select * from emp;
create view emp_view30
as
select empno, ename, deptno
from emp_copy
where deptno = 30
;
select * from emp_view30;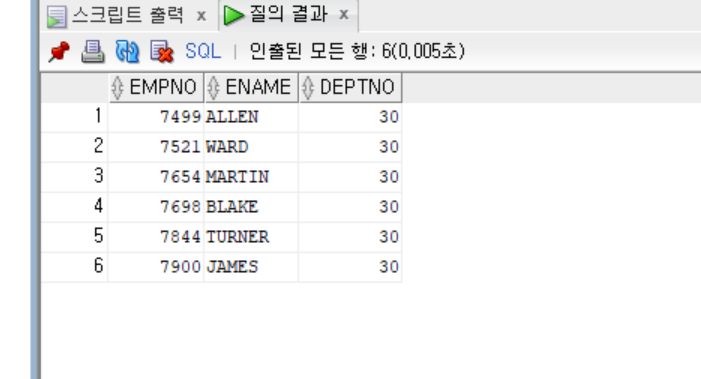
- 실습
-- 기본 테이블은 emp_copy로 하여 20번 부서에 소속된 사원들의 사번, 이름, 부서번호, 상관의 사번을 출력하기 위한 select 문을
-- emp_view20이란 이름의 뷰로 정의
create view emp_view02
as
select empno, ename, deptno, mgr
from emp_copy
where deptno = 20;
select * from emp_view02;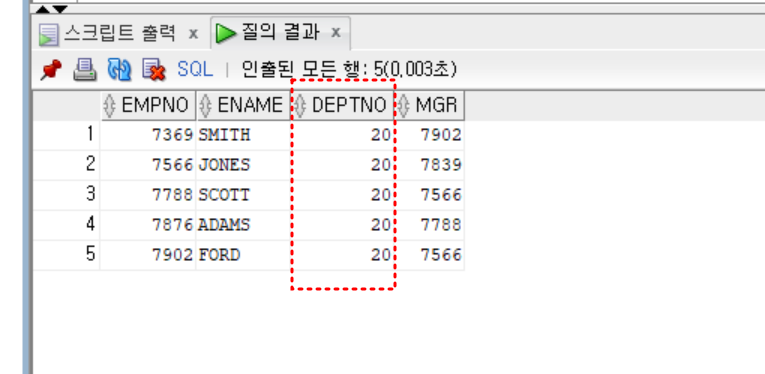
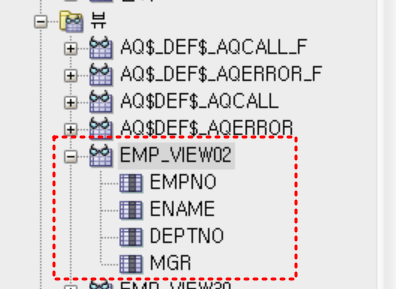
- 실습
create or replace view emp_view30(사원번호, 사원명, 부서번호, 상관사번)
as
select empno, ename, deptno, mgr
from emp_copy
where deptno = 20
;
select * from emp_view30;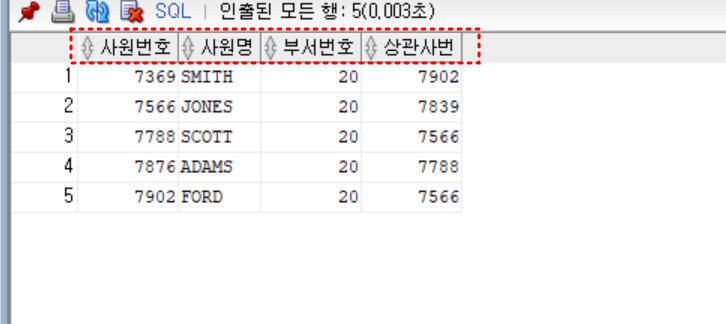
- 같은 이름의 view가 이미 존재하는 경우
create or replace view [뷰 이름]
as
...- 실습
-- view 생성 시 select 절의 수식이나 집계함수는 반드시 별명을 지정
create view view_sal
as
select deptno, sum(sal) as SalSum, avg(sal) as SalAvg
from emp_copy
group by deptno
;
select * from view_sal; 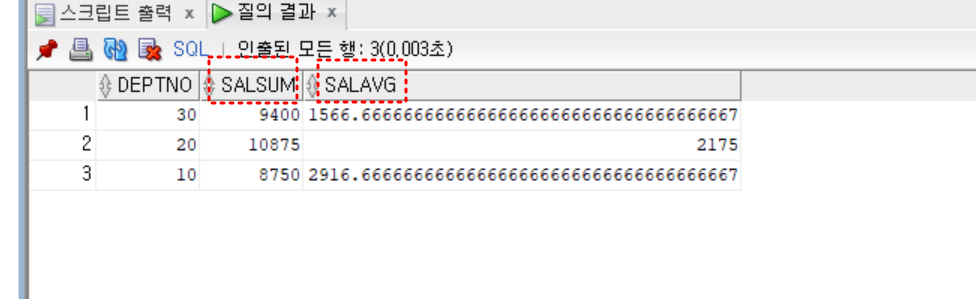
Rownum
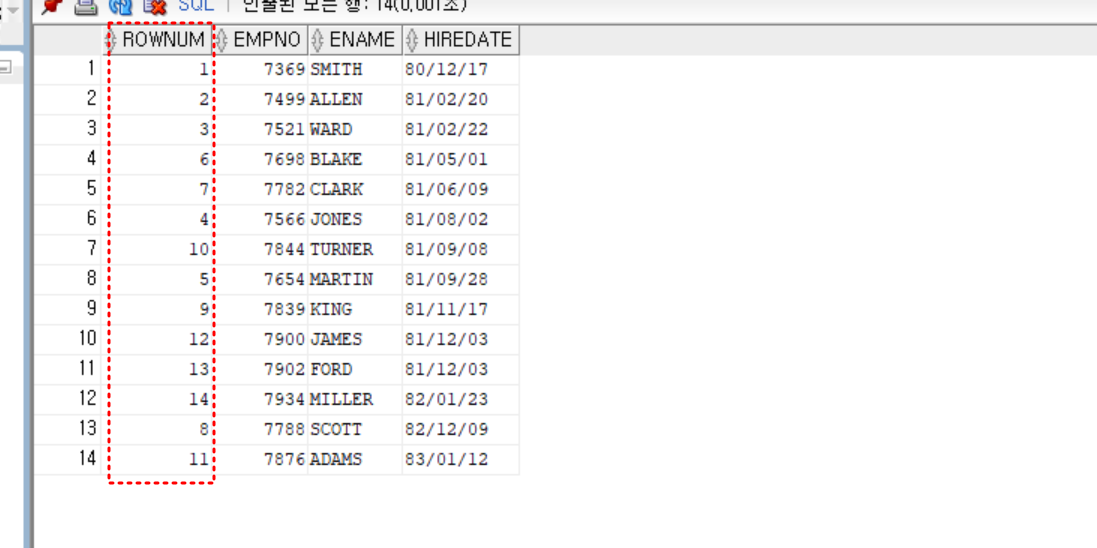
- 실습
select rownum, empno, ename, hiredate
from emp
order by hiredate
;
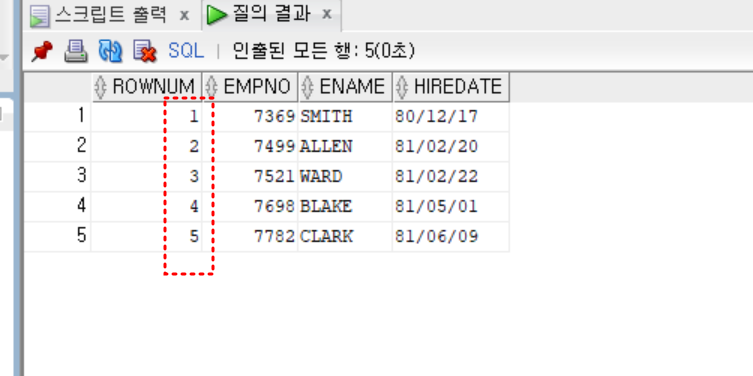
- 실습
-- 입사일이 빠른 사람 5명
select rownum, empno, ename, hiredate
from (
select empno, ename, hiredate
from emp
order by hiredate
)
where rownum <= 5
;
Rownum Between
- 문제) between을 사용하면 조회가 안 되는 문제 발생
select rownum, empno, ename, hiredate
from (
select rownum, empno, ename, hiredate
from emp
order by hiredate
)
where rownum between 2 and 5
;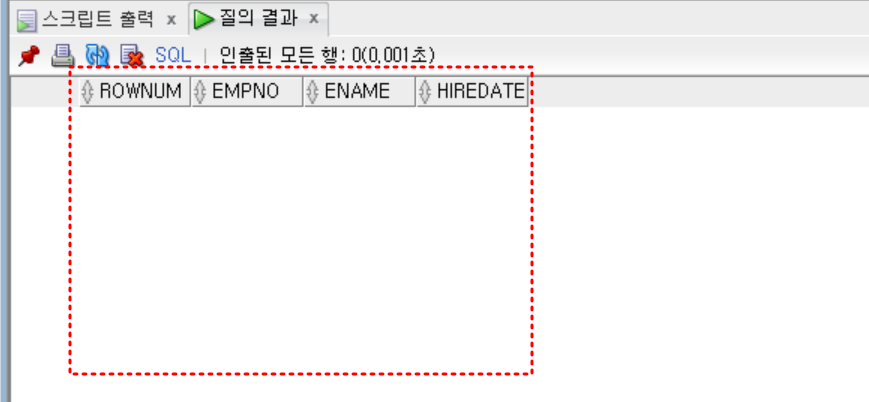
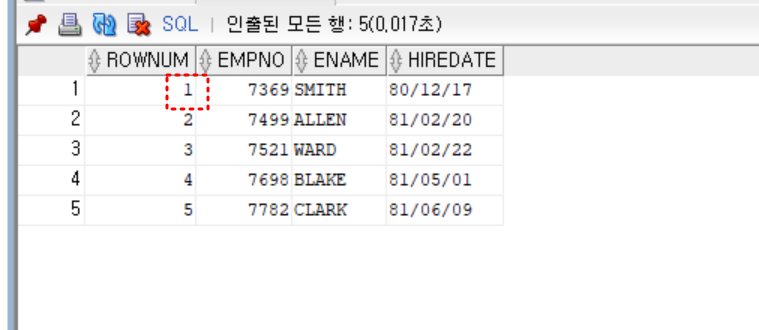
- 원인) rownum 1을 반드시 포함해야 조회가 됨
select rownum, empno, ename, hiredate
from (
select empno, ename, hiredate
from emp
order by hiredate
)
where rownum between 1 and 5
;
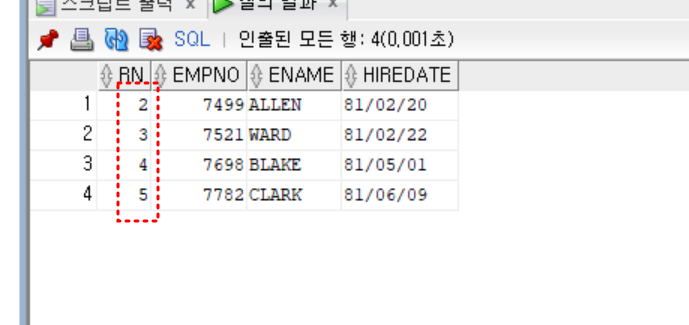
- 해결 1) rownum에 별칭을 부여한 뒤 서브쿼리 활용
-- 페이징
SELECT * FROM (
SELECT ROWNUM as rn, empno, ename, hiredate
FROM (
SELECT empno, ename, hiredate
FROM emp
ORDER BY hiredate
)
) WHERE rn BETWEEN 2 AND 5
;
- 해결 2) row_number() 함수 사용
select row_no, empno, ename, hiredate
from (
select row_number() over (order by hiredate) row_no, emp.*
from emp
)
where row_no between 2 and 5;- 팁) 테이블의 칼럼 외에 다른 칼럼을 추가적으로 출력하고 싶을 떄
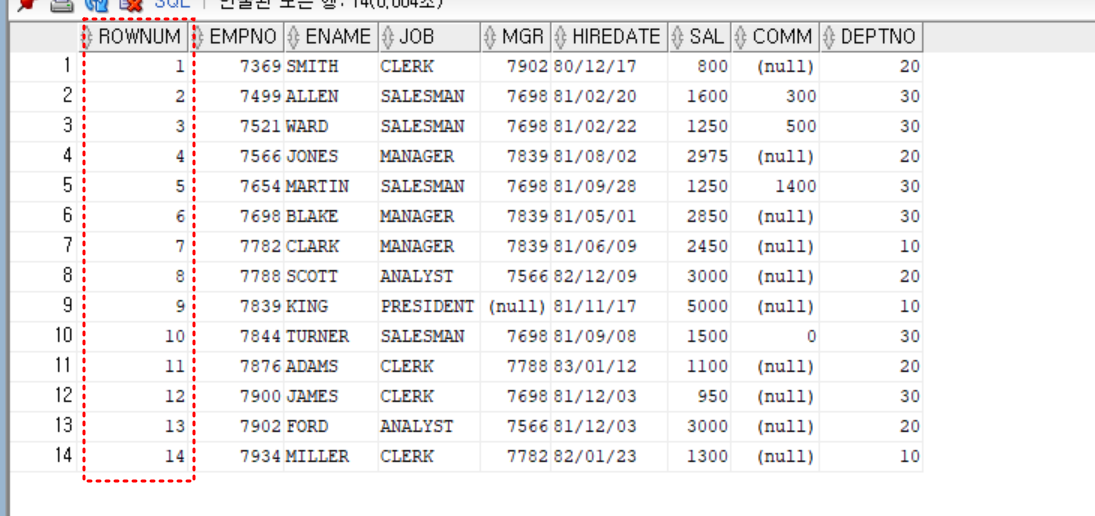
select rownum, emp.*
from emp
;
- 실습) 인라인 뷰
create or replace view view_hire
as
select empno, ename, hiredate
from emp
order by hiredate
;
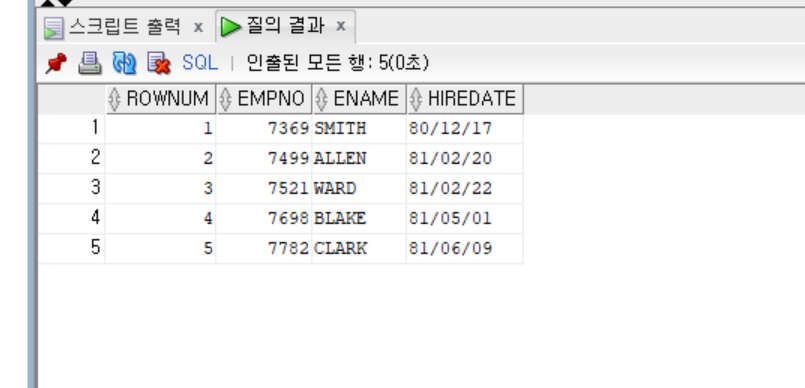
select rownum, empno, ename, hiredate
from view_hire -- 인라인 뷰: from 뷰
where rownum <= 5
;
- 해결 3) 인라인 뷰
-- 인라인 뷰를 사용하여 급여를 많이 받는 순서대로 3명만 출력하는 뷰(sal_top3_view)를 작성하시오
create or replace view view_sal
as
select *
from emp
order by sal desc
;
select rownum, view_sal.*
from view_sal
where rownum <= 3; 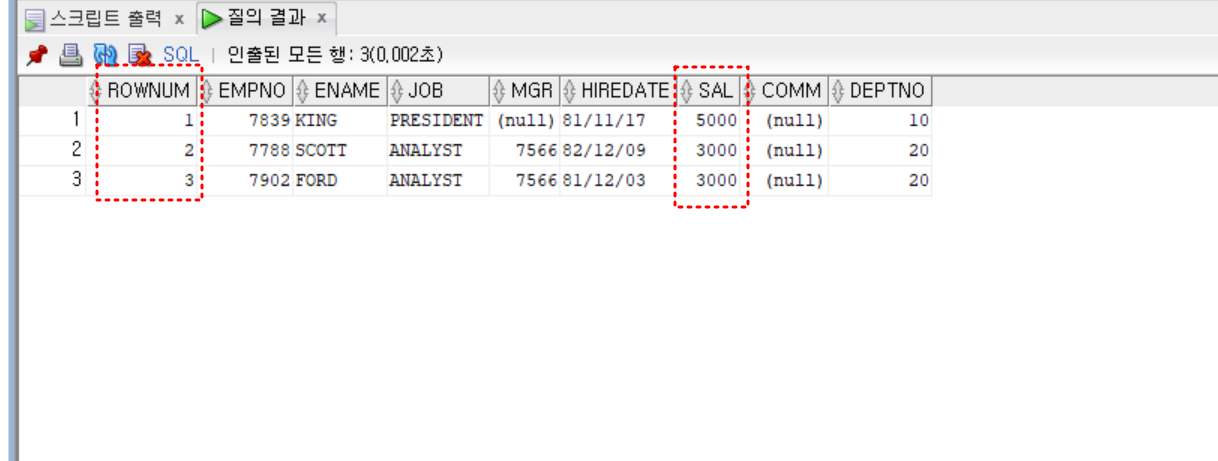
Rank
-- 순위 기반 추출
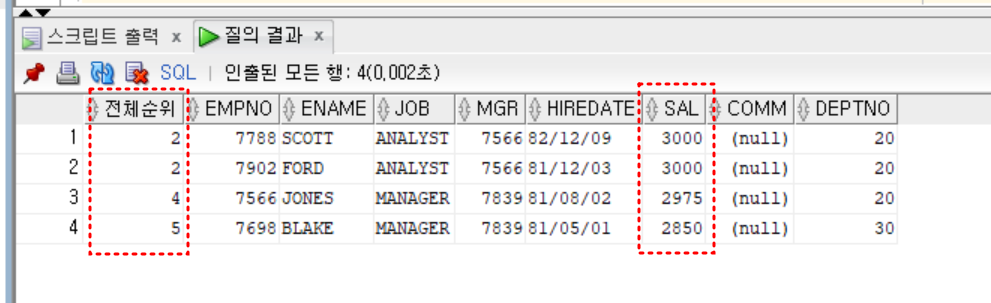
select *
from (
select rank() over (order by emp.sal desc) as 전체순위, emp.*
from emp
order by sal desc)
where 전체순위 between 2 and 5
;
Sequence
- 실습
create table emp_copy2
as
select * from emp
where 1=2
;
-- empno 값 넣기
insert into emp_copy2(empno)
values(1)
;
insert into emp_copy2(empno)
select max(empno)+1 from emp_copy2
;
select * from emp_copy2;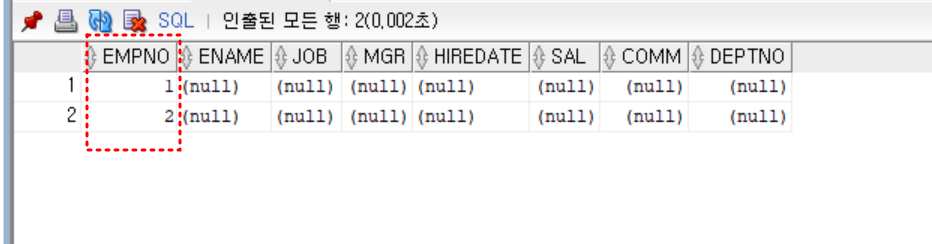
- 실습) empno가 number인 경우
create sequence emp_seq
start with 1
increment by 1
maxvalue 100000
;
drop table emp01;
create table emp01 (
empno number(4) primary key,
ename varchar(10),
hiredate date
);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
select * from emp01;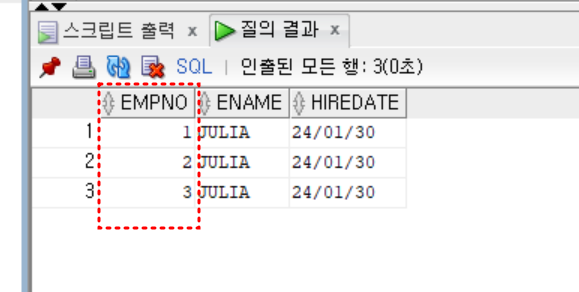
- 실습) empno가 char인 경우
drop table emp01;
create table emp01 (
empno char(4) primary key,
ename varchar(10),
hiredate date
);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
insert into emp01
values (emp_seq.nextval, 'JULIA', sysdate);
select * from emp01;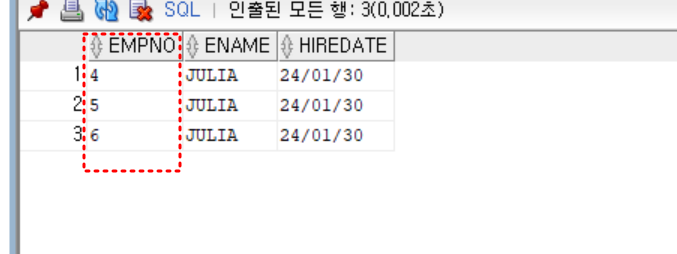
- 실습) LPAD 사용
-- 일련번호를 자동으로 생성할 때,
-- 번호 컬럼 총 자리수를 4자리로 하고, 왼쪽 빈 자리의 수는 0으로 채우기
-- ex) 0001, 0002, ...
insert into emp01
values (lpad(to_char(emp_seq.nextval), 4, '0'), 'JULIA', sysdate)
;
select * from emp01; 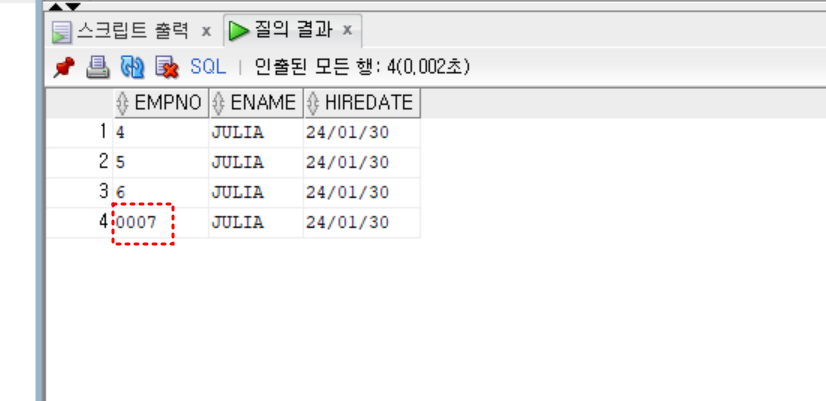
- 실습) FM 사용
insert into emp01
values (to_char(emp_seq.nextval, 'FM0000'), 'JULIA', sysdate);
select * from emp01;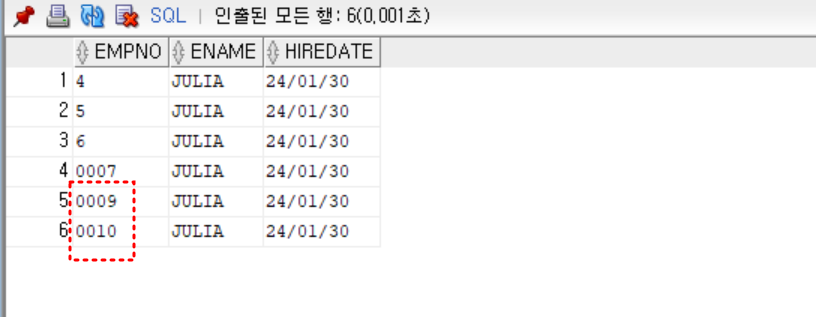
퀴즈
- 다음 구조의 상품 테이블을 생성하라
(
상품번호 고정길이문자(4) 기본키,
상품명 가변길이문자(20),
상품설명 4000자 이상 문자,
판매수량 숫자 기본값 0,--현재까지 판매된 총수량
가격 숫자
)
CREATE TABLE 상품 (
상품번호 CHAR(4) PRIMARY KEY,
상품명 VARCHAR2(20),
상품설명 CLOB, -- 4000자 이상의 문자를 저장하기 위해 CLOB 사용
판매수량 NUMBER DEFAULT 0,
가격 NUMBER
);- 1부터 1씩 자동증가시키는 P_SEQ 시퀀스를 생성하라
(단 최대값은 999)
CREATE SEQUENCE P_SEQ
START WITH 1
INCREMENT BY 1
MAXVALUE 999
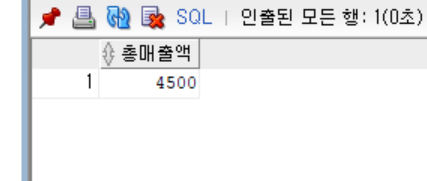
;- 다음의 INSERT문을 실행 후 현재 총매출액을 출력하라
단, 상품번호체계는 P001,P002..P999
insert into 상품
values(concat('P',lpad(to_char(P_SEQ.NEXTVAL),3,'0')),'진라면','라면',5,100);
insert into 상품
values(concat('P',lpad(to_char(P_SEQ.NEXTVAL),3,'0')),'신라면','라면',10,100);
insert into 상품
values(concat('P',lpad(to_char(P_SEQ.NEXTVAL),3,'0')),'너구리','라면',15,200);
commit;
SELECT SUM(판매수량 * 가격) AS 총매출액
FROM 상품
;
- 3번 문제의 총매출액 SELECT문을 p_view 뷰로 정의하라
create view p_view
as
SELECT SUM(판매수량 * 가격) AS 총매출액
FROM 상품
;
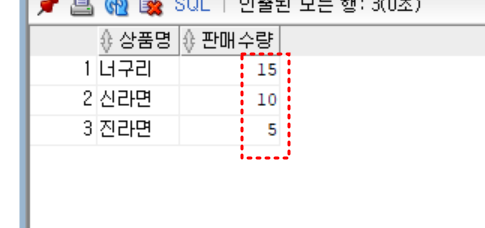
select * from p_view;- 상품 판매수량이 높은순으로 상품명, 판매수량을 출력하라
select 상품명, 판매수량
from 상품
order by 판매수량 desc
;
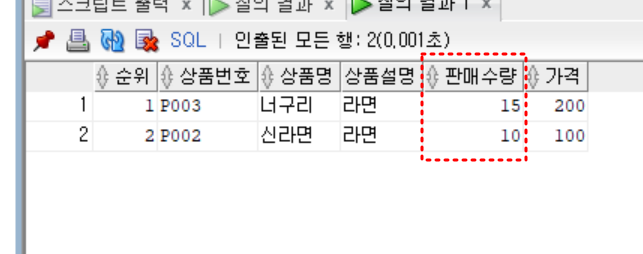
6.가장많이 팔린 2개 상품 출력
sol1) rank
select *
from (
select rank() over (order by 판매수량 desc) as 순위, 상품.*
from 상품
order by 판매수량 desc)
where 순위 <= 2
;
sol2) 인라인 뷰
create or replace view view_qty
as
select 상품명, 판매수량
from 상품
order by 판매수량 desc
;
select rownum, view_qty.*
from view_qty
where rownum <= 2
;Explain plan
explain plan for
select *
from emp
where empno = 7788;
select *
from table(dbms_xplan.display());
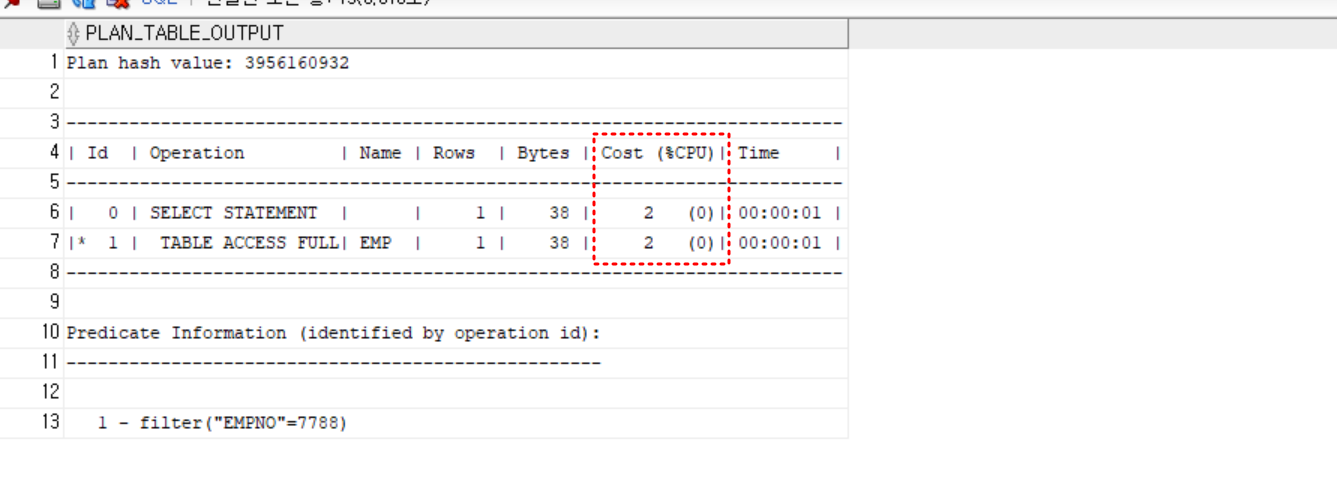
실행 계획 분석
-
Plan Hash Value: 이것은 실행 계획을 고유하게 식별하는 값입니다. 같은 쿼리에 대해 일관된 계획을 생성하기 위해 사용됩니다.
-
Operation과 Name:
TABLE ACCESS FULL | EMP: 이 부분은emp테이블에 대해 전체 테이블 스캔(Full Table Access)이 수행되고 있음을 나타냅니다. 이는 인덱스를 사용하지 않고, 테이블의 모든 행을 처음부터 끝까지 검사한다는 것을 의미합니다.
-
Rows:
- Oracle Optimizer는 이 쿼리가 단 하나의 행만 반환할 것으로 예측하고 있습니다.
-
Bytes:
- 반환되는 각 행이 38바이트의 데이터를 가질 것으로 예상됩니다.
-
Cost (%CPU) | Time:
2 (0) | 00:00:01: 이 쿼리의 예상 비용은 2이며, CPU 사용은 거의 없을 것으로 예상됩니다. 시간은 대략 1초 이내로 추정됩니다. 비용은 쿼리를 실행하는 데 필요한 상대적인 자원 사용량을 나타냅니다.
Predicate Information
filter("EMPNO"=7788): 이 부분은 쿼리가empno컬럼의 값이 7788인 행을 찾기 위해 필터를 사용하고 있음을 나타냅니다.
종합적인 해석
이 실행 계획은 쿼리가 emp 테이블 전체를 스캔하여 empno가 7788인 행을 찾는다는 것을 나타냅니다. 전체 테이블 스캔은 특히 큰 테이블에서 비효율적일 수 있으므로, empno 컬럼에 인덱스가 없는 경우 인덱스를 추가하는 것을 고려할 수 있습니다. 인덱스가 있다면 쿼리의 성능이 크게 향상될 수 있습니다.
JDBC
- EMPSelectList.java
package db;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class EMPSelectList {
// JDBC
//ojdbc6.jar 자바와 오라클의 연동 라이브러리
//ojdbc6.jar 저장경로 C:\oraclexe\app\oracle\product\11.2.0\server\jdbc\lib
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 1. Driver 연결(DB Open)
Class.forName("oracle.jdbc.driver.OracleDriver");
// 2. 계정 연결
String url = "jdbc:oracle:thin:@localhost:1521:xe";
String user = "system";
String password = "Test1234";
//DriverManager.getConnection("jdbc:oracle:thin:@dbhost:port:sid", “계정명”, “비번”);
Connection con = DriverManager.getConnection(url, user, password);
System.out.println(con);
// 3. Query 준비
Statement stmt = con.createStatement();
//Statement : 정적쿼리문장
String sql = "select * from emp";
// 4. Query 실행 및 ResultSet 리턴
ResultSet rs = stmt.executeQuery(sql);
//next() 메소드를 이용하여 한 행씩 커서 이동
//행이 없으면 false
while (rs.next()) {
//System.out.println(rs.getInt("empno")+","+rs.getInt(1));
//모든컬럼
System.out.println(rs.getInt(1) + " " + rs.getString(2) + " " + rs.getString(3) + " " + rs.getInt(4) + " "
+ rs.getDate(5) + " " + rs.getInt(6) + " " + rs.getInt(7) + " " + rs.getInt(8));
}
// 5. DB Close
//rs.close();
//stmt.close();
//Disconnected
con.close();
}
}-
라이브러리 추가 (jar 파일)
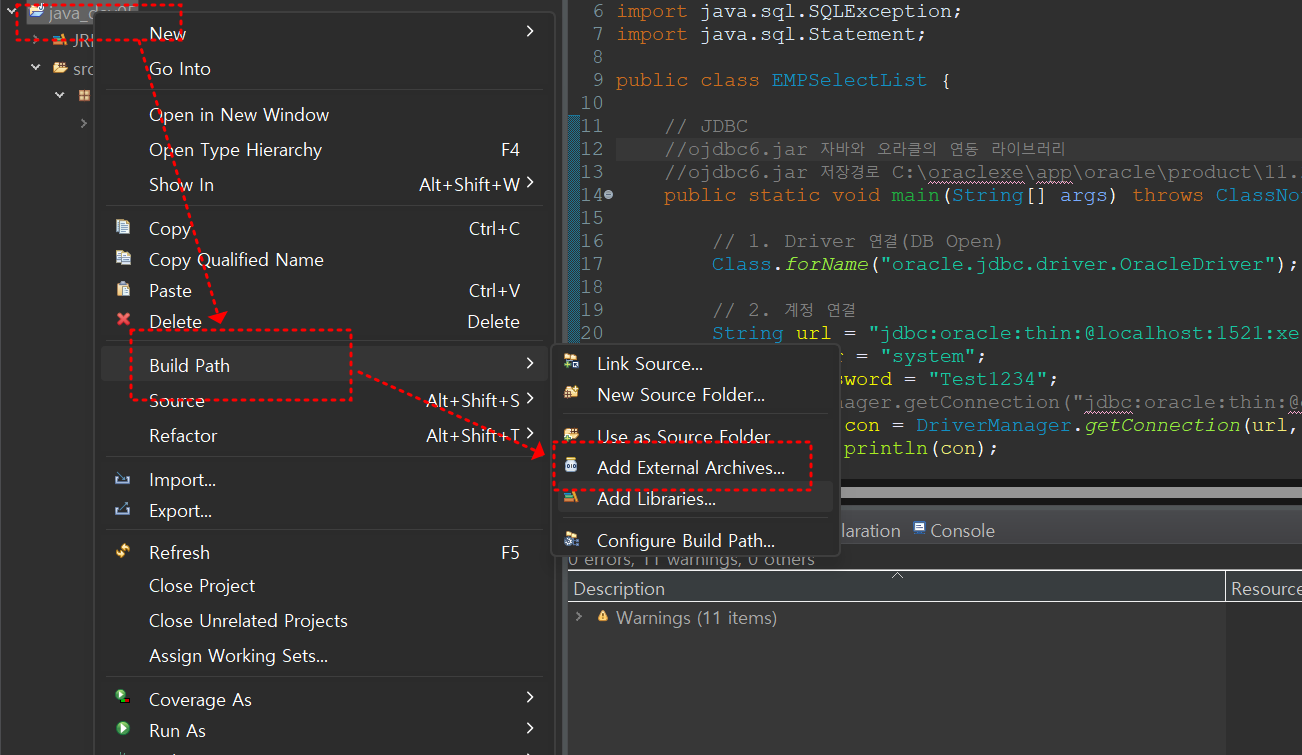
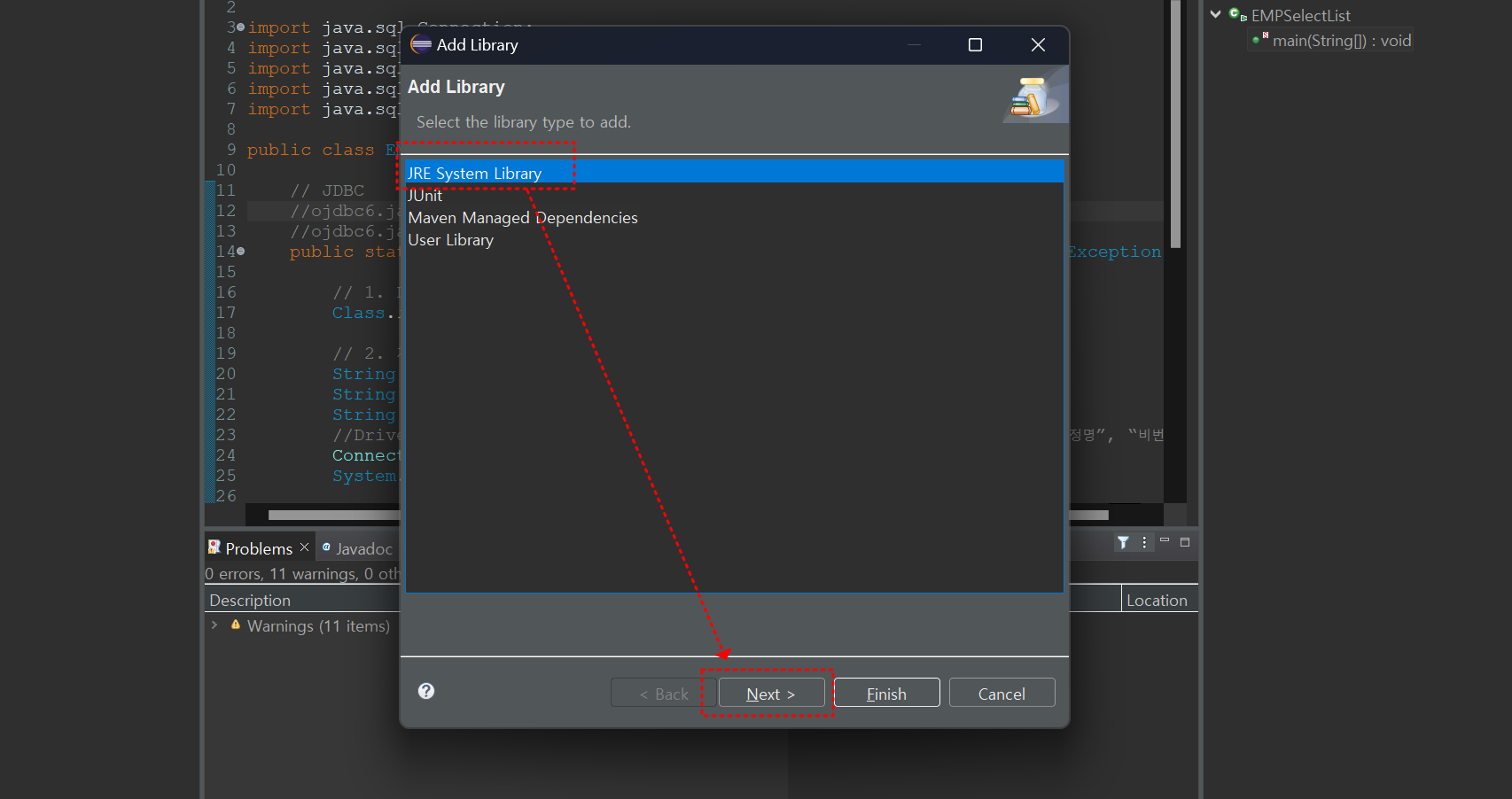
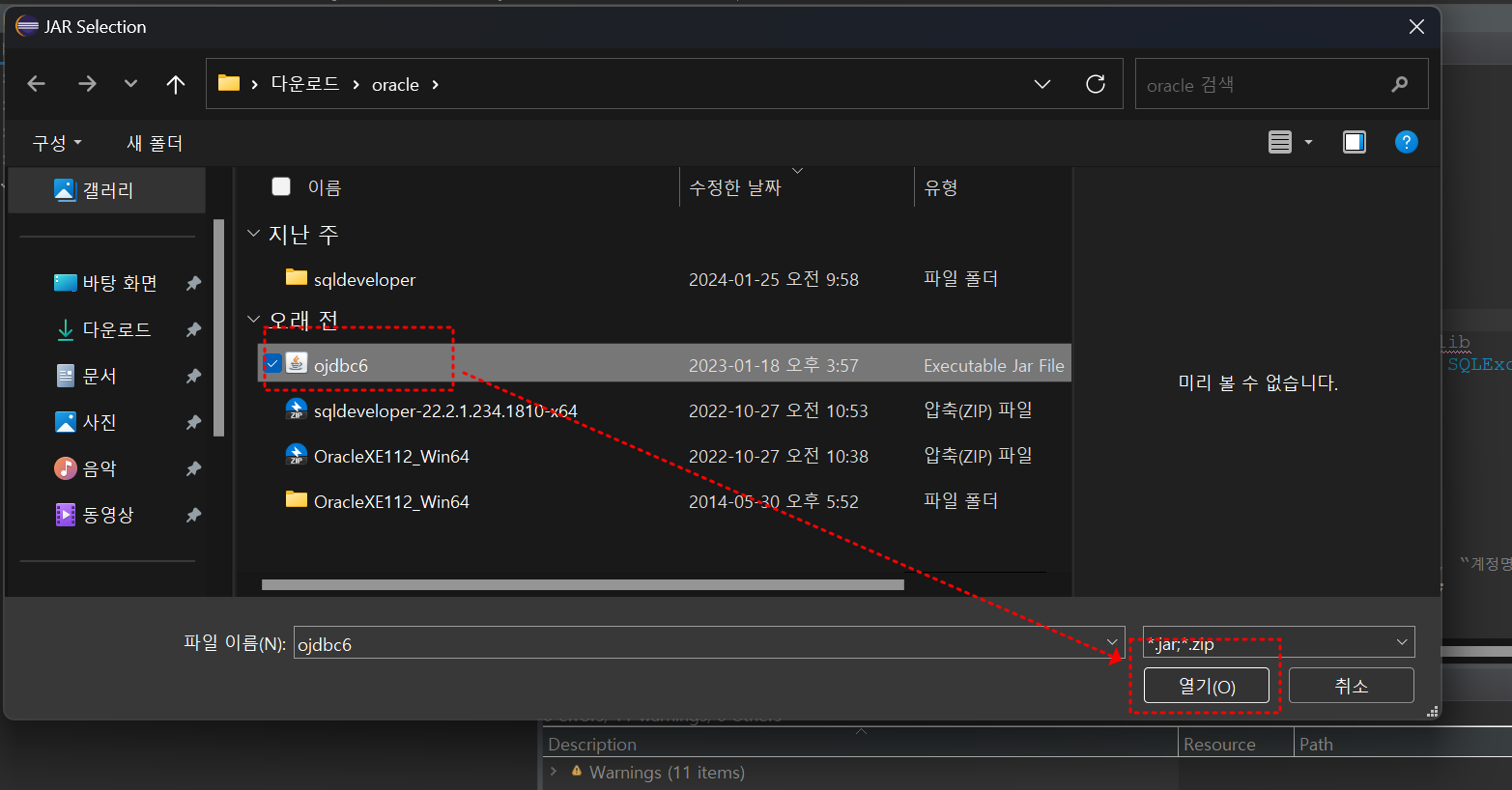
-
run
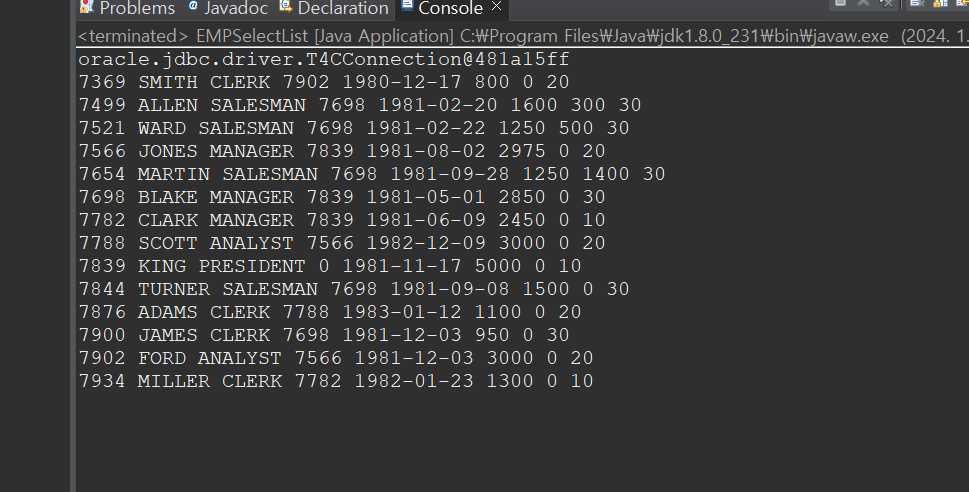

take a look
교육 마무리 잘하십쇼!!!!