www.naver.com 검색 시 어떤 일이 일어나는지
1. 사전 개념
IP 주소
- 많은 컴퓨터들이 인터넷 상에서 서로를 인식하기 위해 지정받은 식별용 번호이다.
- 현재는 IPv4(32비트)로 구성되어 있다.
- 시간이 갈수록 IPv4 주소의 부족으로 IPv6가 생겼는데, 128비트 구성되기 때문에 IP주소가 부족하지 않다는 특성이 있다.
도메인 네임(Domain Name)

- IP주소는 12자리의 숫자로 되어 있어 사람이 외우기 힘들다.
- 그렇기 때문에 12자리 IP주소를 문자로 표현한 주소를 도메인 네임이라고 한다.
- ‘naver.com’과 같은 의미 있는 문자들과 ‘.’으로 구성된다.
- 도메인 네임은 사람의 편의성을 위해 만든 주소이므로 실제로는 컴퓨터가 이해할 수 있는 IP주소로 변환하는 과정이 필요하다.
- 이때, 사용할 수 있도록 미리 도메인 네임과 해당하는 IP주소값을 한쌍으로 저장하고 있는 데이터베이스를 DNS라고 한다.
- 도메인 네임으로 입력하면 DNS를 이용해 컴퓨터는 IP주소를 받아 찾아갈 수 있다.
DHCP(Dynamic Host Configuration Protocol) & ARP
- 대부분의 가정집에서 인터넷 접속시 DHCP를 사용한다.
- 호스트의 IP주소 및 TCP/IP 설정을 클라이언트에 자동으로 제공하는 프로토콜이다.
- 사용자의 PC는 DHCP 서버에서 사용자 자신의 IP주소, 가장 가까운 라우터 IP주소, 가장 가까운 DNS 서버 IP주소를 받는다.
- 이후, ARP 프로토콜을 이용해 IP주소를 기반으로 가장 가까운 라우터의 MAC 주소를 알아낸다.
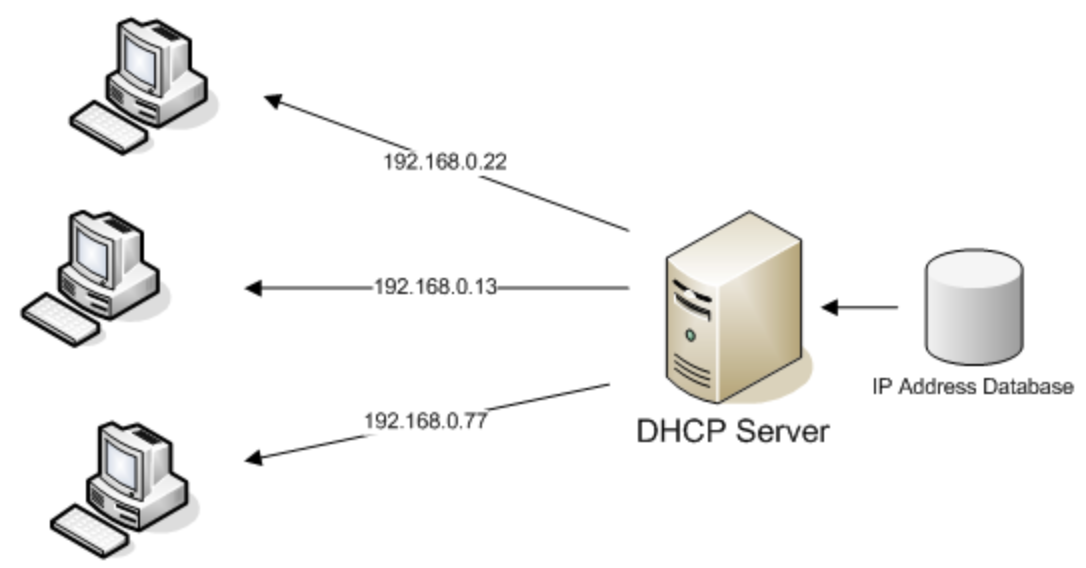
-> 클라이언트가 인터넷 접속을 시도하면 IP와 기본 정보를 제공해준다.
2. 전체 동작 과정(요약)
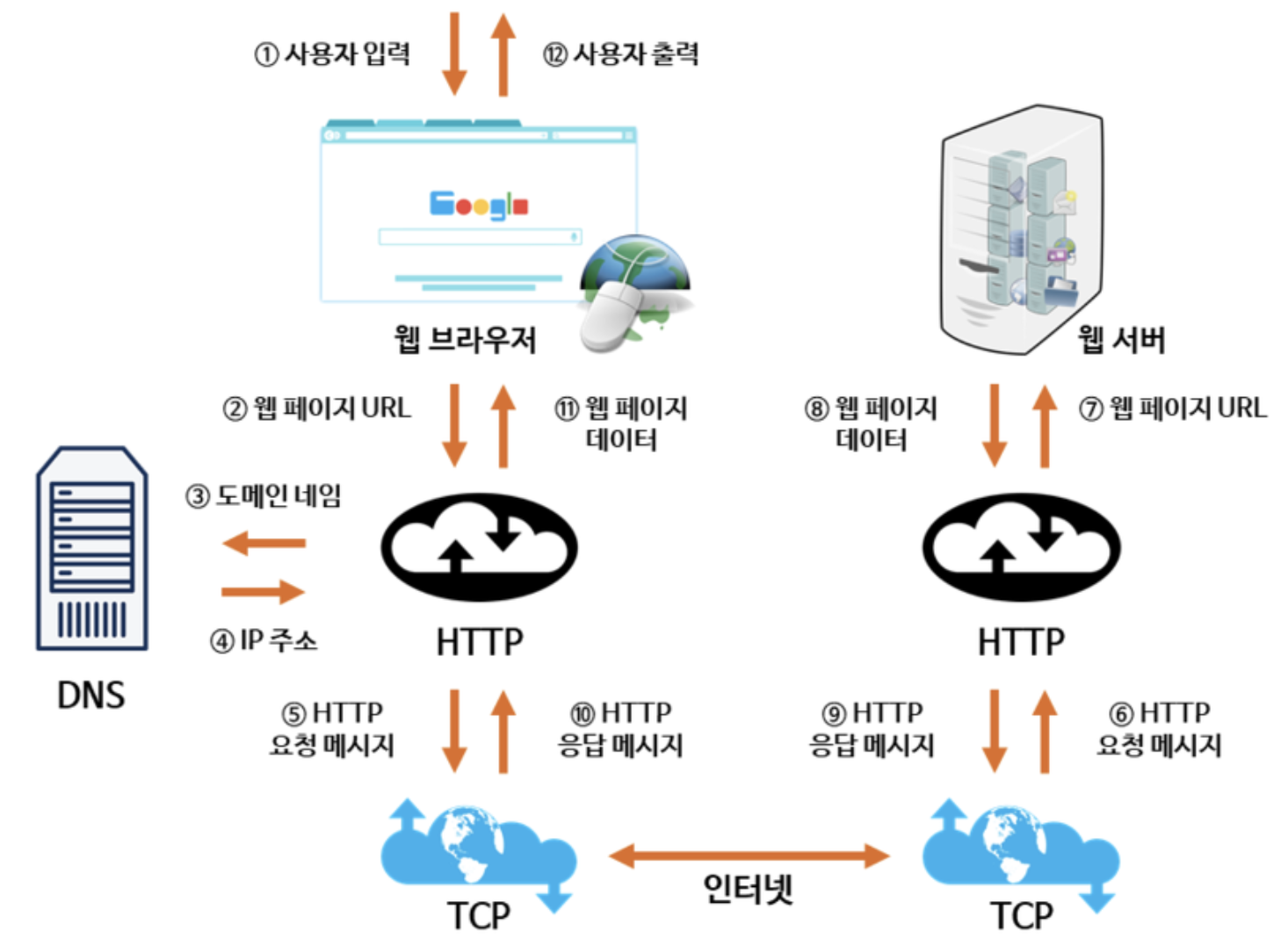
1. 사용자가 브라우저에 도메인 네임을 입력한다. ‘www.naver.com’
2. 사용자가 입력한 URL 주소 중 도메인 네임 부분을 DNS 서버에 검색하고, DNS 서버에서 해당 도메인 네임에 해당하는 IP주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다.
3. 페이지 URL정보와 전달받은 IP주소는 HTTP프로토콜을 사용해 HTTP 요청 메시지를 생성하고, 이렇게 생성된 HTTP 요청 메시지는 TCP 프로토콜을 사용하여 인터넷을 거쳐 해당 IP주소의 컴퓨터로 전송된다.
4. 이렇게 도착한 HTTP 요청 메시지는 HTTP 프로토콜을 사용해 웹페이지 URL 정보로 변환되어 웹 페이지 URL 정보에 해당하는 데이터를 검색한다.
5. 검색된 웹페이지 데이터는 또다시 HTTP 프로토콜을 사용해 HTTP 응답 메시지를 생성하고 TCP 프로토콜을 사용해 인터넷을 거쳐 원래 컴퓨터로 전송된다.
6. 도착한 HTTP 응답 메시지는 HTTP 프로토콜을 사용해 웹페이지 데이터로 변환되어 웹 브라우저에 의해 출력되어 사용자가 볼 수 있게 된다.
IP 정보 수신
위의 과정을 통해 외부와 통신할 준비를 마쳤고, DNS 쿼리를 DNS 서버에 전송한다.
DNS 서버는 이에 대한 결과로 웹서버의 IP주소를 사용자 PC에 돌려준다.
DNS 서버가 도메인에 대한 IP주소를 송신하는 과정은 약간 복잡하다.
www.naver.com 을 주소창에 검색했을 때 (DNS 원리)
- 로컬 DNS 서버에 해당 url이 등록되어 있는지 확인 후 있으면 바로 IP를 알려준다.
- 만약 IP주소를 찾지 못했을 경우, 루트 네임 서버에 www.naver.com을 질의하고 루트 네임서버는 최상위 도메인이
.com인 것을 확인 후,.com이 등록된 네임서버의 IP주소를 전달한다. 즉, com 도메인을 관리하는 DNS 서버에 문의해보라고 로컬 DNS 서버에게.comDNS 서버의 IP주소를 알려주는 것이다. - 로컬 DNS 서버는 이제
.comDNS 서버에게 해당 URL(www.naver.com)을 질의한다. 역시나.com서버에는 해당 URL(naver.com)이 없으므로naver.com을 관리하는 DNS 서버에게 질의하도록 로컬 DNS 서버에게naver.comDNS 서버의 IP주소를 알려준다. - 로컬 DNS 서버는 이제
naver.comDNS 서버에게 해당 URL(www.naver.com)을 질의한다. "naver.com 도메인을 관리하는 DNS 서버"에는 "www.naver.com"에 대한 IP 주소가 있으므로 로컬 DNS 서버에게 해당 IP를 알려준다.
이와 같이 여러번 왔다갔다하는 이유는, 도메인의 계층화 구조에 따라 DNS 서버도 계층화가 되어있기 때문이다. 이렇게 계층화되어 있으므로 도메인의 가장 최상단, 즉, 가장 뒷쪽(.com, .kr ..) 을 담당하는 DNS 서버는 전세계에 13개 뿐이다.
또한, 이와 같이 로컬 DNS 서버가 열 DNS 서버를 차례대로(로컬 DNS 서버 -> Root DNS 서버 -> com DNS 서버 -> naver.com DNS 서버) 물어보며 답을 찾는 과정을 Recursive Query(재귀적 쿼리)라고 부른다.
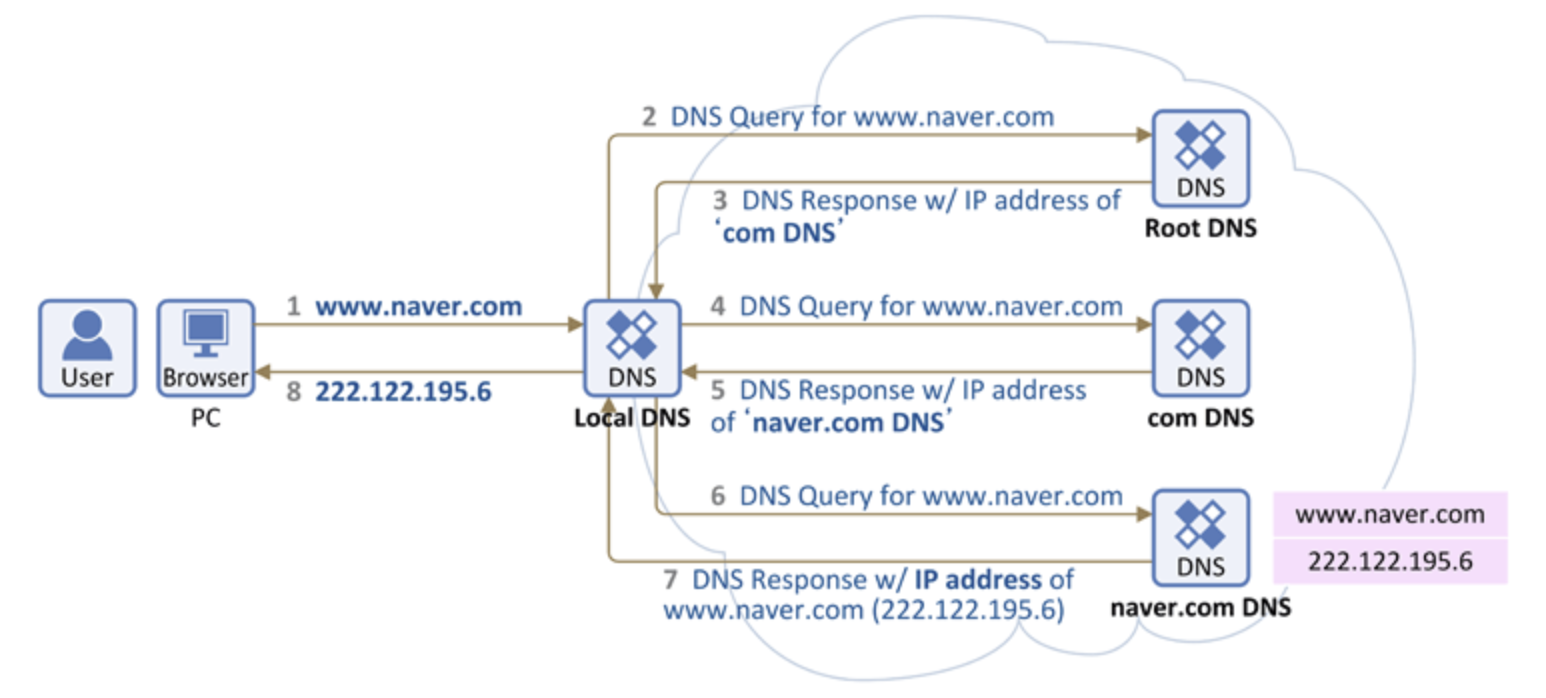
실제로는 위와 같이 여러 단계를 거치게 되지만 초기의 해당 단계를 거치게 되면 그 이후로는 도메인에 대한 데이터베이스가 캐싱되어 위 단계를 거치지 않고 바로 응답이 가능하다.
참고
.com : Top-level Domain Name
.naver.com : Second-level Domain Name
웹서버 접속
웹서버의 IP주소까지 알았다.
HTTP 요청을 위해 TCP 소켓을 개방하고 연결한다.
이 과정에서 3-way handshaking이 일어난다.
TCP 연결에 성공하면, HTTP 요청이 TCP 소켓을 통해 보내진다.
이에 대한 응답으로 웹 페이지의 정보가 사용자의 PC로 들어온다.
3. 자세한 동작 과정
1. 주소창에 URL(www.naver.com) 을 입력한다.
2. 웹 브라우저가 URL을 해석한다.
URL 구조
scheme:[//[user:password@]host[:port][/]path[?query][#fragment]
- scheme : 자원에 접근할 방법을 정의해 둔 프로토콜 (ex. gopher, telnet, ftp, http, usenet 등)
- “:” : 이름 다음에는 프로토콜 이름을 구분하는 구분자
- 만약 IP 혹은 도메인 네임 정보가 필요한 프로토콜이라면 “:” 다음에 “//”를 적는다.
- 프로토콜명 구분자인 “:” 혹은 “//” 다음에는 프로토콜마다 특화된 정보를 넣는다.
- ex) http://www.somehost.com/a.gif - IP 혹은 도메인 네임 정보가 필요한 형태 (www.somehost.com에 있는 a.gif를 가리키고 있음)
- ex) ftp://id:pass@192.168.1.234/a.gif - IP 혹은 도메인 네임 정보가 필요한 형태 (192.168.1.234에 있는 a.gif를 가리키고 있음)
- ex) somebody@mail.somehost.com - IP 정보가 필요없는 프로토콜 (mailto 프로토콜은 단지 메일을 받는 사람의 주소를 나타냄)
{kind=link}
만약, URL이 문법에 맞지 않는다면, 브라우저는 주소창에 놓인 텍스트를 브라우저의 기본 검색엔진으로 검색을 요청한다.
3. URL이 문법에 맞으면, 호스트명에서 ASCII 아닌 유니코드 문자열을 Punycode 인코딩을 한다.
4. HSTS (HTTP Strict Transport Security) 리스트를 확인한다.
HSTS 목록에 있으면 첫 요청을 HTTPS로 보내고, 아닌 경우 HTTP로 보낸다.
- HTTP Strict Transport Security란?
HTTP 대신 HTTPS 만을 사용해 통신해야 한다고 웹 사이트가 웹 브라우저에 알리는 보안기능
5. DNS(Domain Name Server) 조회한다.
- DNS에 요청을 보내기 전에 먼저 브라우저에 해당 도메인이 캐시에 들어있는지 확인한다. (크롬의 경우 chrome://net-internals/#dns 에서 확인 가능하다.)
- 없을 경우, 로컬에 저장되어 있는 hosts 파일에서 참조할 수 있는 도메인이 있는지 확인한다.
- 1), 2)가 모두 실패했을 경우 네트워크 스택에 정의된 DNS로 요청을 보낸다. (일반적으로 로컬 라우터나 ISP(인터넷 공급자)의 캐시 DNS 서버로 보내진다.)
- 만약 DNS 서버가 같은 서브넷에 존재한다면 이 네트워크 라이브러리는 DNS 서버에 대해 ARP 프로세스를 거친다.
- 만약 DNS 서버가 다른 서브넷에 존재한다면, 네트워크 라이브러리는 기본 게이트웨이 IP에 대해 ARP 프로세스를 거친다.
6. ARP(Address Resolution Protocol)로 대상의 IP와 MAC address를 알아낸다.
ARP broadcast를 보내기 위해서는 Network stack library가 검색할 목적지 IP 주소와 ARP broadcast를 보내는 데 사용할 인터페이스의 MAC address를 알아야 한다.
가장 먼저, ARP 캐시가 목적지 IP에 대한 ARP 항목을 가지고 있는 지 점검한다. 만약 캐시에 있다면 라이브러리 함수는 목적지 IP = MAC 주소 형태로 결과를 반환한다.
항목이 ARP 캐시에 없다면:
- 목적지 IP 주소가 로컬 라우트 테이블의 서브넷에 존재하는 지 확인하기 위해 라우팅 테이블 조회
- 존재한다면, 라이브러리가 그 서브넷에 속하는 인터페이스를 활용한다. 없다면, 라이브러리는 우리 기본 게이트웨이의 서브넷에 속하는 인터페이스를 활용한다.
- 선택된 네트워크 인터페이스의 MAC 주소가 검색된다.
- 네트워크 라이브러리는 링크 계층(OSI 모델 2계층)을 통해 ARP 요청을 보낸다.
ARP Request:
Sender MAC: interface:mac:address:here
Sender IP: interface.ip.goes.here
Target MAC: FF:FF:FF:FF:FF:FF (Broadcast)
Target IP: target.ip.goes.hereARP Reply:
Sender MAC: target:mac:address:here
Sender IP: target.ip.goes.here
Target MAC: interface:mac:address:here
Target IP: interface.ip.goes.here이제 네트워크 라이브러리는 우리 DNS나 DNS 프로세스를 재개할 수 있는 기본 게이트웨이 중 하나의 IP주소를 갖고 있다.- 응답에서 목적지의 MAC 주소와 IP 주소로 DNS 프로세스 다시 시작
- DNS 서버에게 53번 포트를 열어서 UDP 요청을 보낸다. (응답 데이터가 큰 경우 TCP가 대신 사용)
- 로컬/ISP의 DNS 서버가 해당 정보를 갖고 있지 않다면, 재귀적인 탐색이 수행되고 SOA(Service-oriented architecture)가 도달해서 해답이 되돌아 올 때까지 DNS 서버 리스트를 타고 올라간다.
7. 목적지와 TCP 통신을 통해 소켓을 연다.
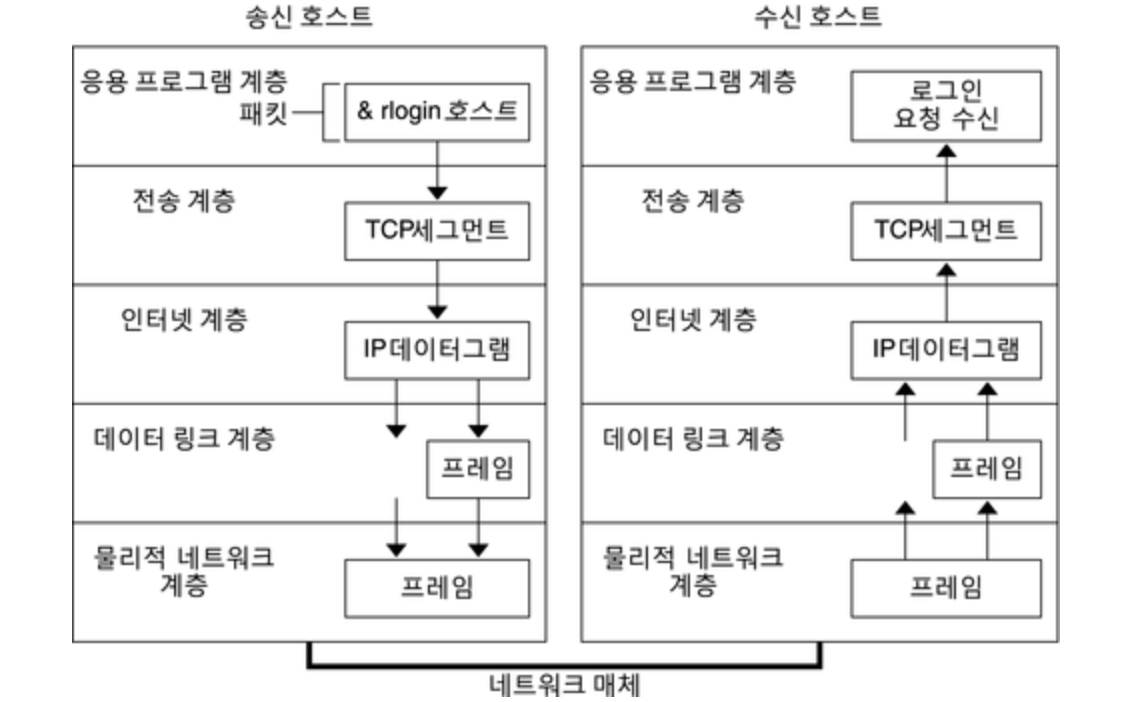
-
브라우저가 목적지 서버의 IP 주소를 받으면, URL에서 호스트명과 포트 번호(HTTP의 기본값은 80, HTTPS의 기본값은 443)를 가져와서, socket 이라는 이름의 시스템 라이브러리를 호출하고 TCP 소켓 스트림 - AF_INET/AF_INET6 과 SOCKET_STREAM 을 요청한다.
-
이 요청은 먼저 TCP 세그먼트가 만들어지는 전송 계층(OSI 모델 4계층)으로 전달된다. 목적지 포트는 헤더에 추가되고, 출발지 포트는 커널의 동적 포트 범위(리눅스 ip_local_port_range)에서 임의로 지정한다.
-
TCP 세그먼트는 추가적인 IP 헤더를 덧씌우는 네트워크 계층(OSI 모델 3계층)으로 보내진다. 세그먼트 헤더에 목적지 컴퓨터의 IP주소와 현재 컴퓨터의 IP주소를 담아 패킷을 구성한다.
-
패킷은 링크 계층(OSI 모델 2계층)으로 전달된다. 머신 NIC의 MAC 주소와 게이트웨이(로컬 라우터)의 MAC 주소를 포함한 프레임 헤더가 추가된다.(전과 마찬가지로, 커널이 게이트웨이의 MAC 주소를 모르는 경우 ARP 쿼리를 브로드캐스트 해서 찾아야 한다.)
-
패킷이 ethernet, Wifi, Cellular data network(무선 통신 네트워크) 중 하나로 전송될 준비를 마친다.
- 광인터넷을 쓸 경우 모뎀을 통해 광신호로 변경된 후 network node로 직접 전송한다.
-
패킷은 로컬 서브넷을 관리하는 라우터에 도착한다. 거기서부터, 패킷은 AS(Autonomous System)의 경계 라우터들을 통과하여 결국 목적지 서버까지 도착한다.
이 때 지나치는 각각의 라우터는 패킷의 IP 헤더로부터 목적지 주소를 추출해내서 적절한 다음 hop으로 이어준다. IP 헤더 내의 TTL(Time To Live)필드는 라우터를 하나씩 지날 때마다 감소된다.
TTL 필드가 0이 되거나 도달한 라우터의 큐에 (네트워크 혼잡과 같은 이유로) 공간이 없을 때 패킷은 드랍된다.이러한 송수신 동작은 다음 TCP 연결 흐름(connection flow)을 따라 여러 차례 일어난다.
-
TCP 소켓 통신 과정
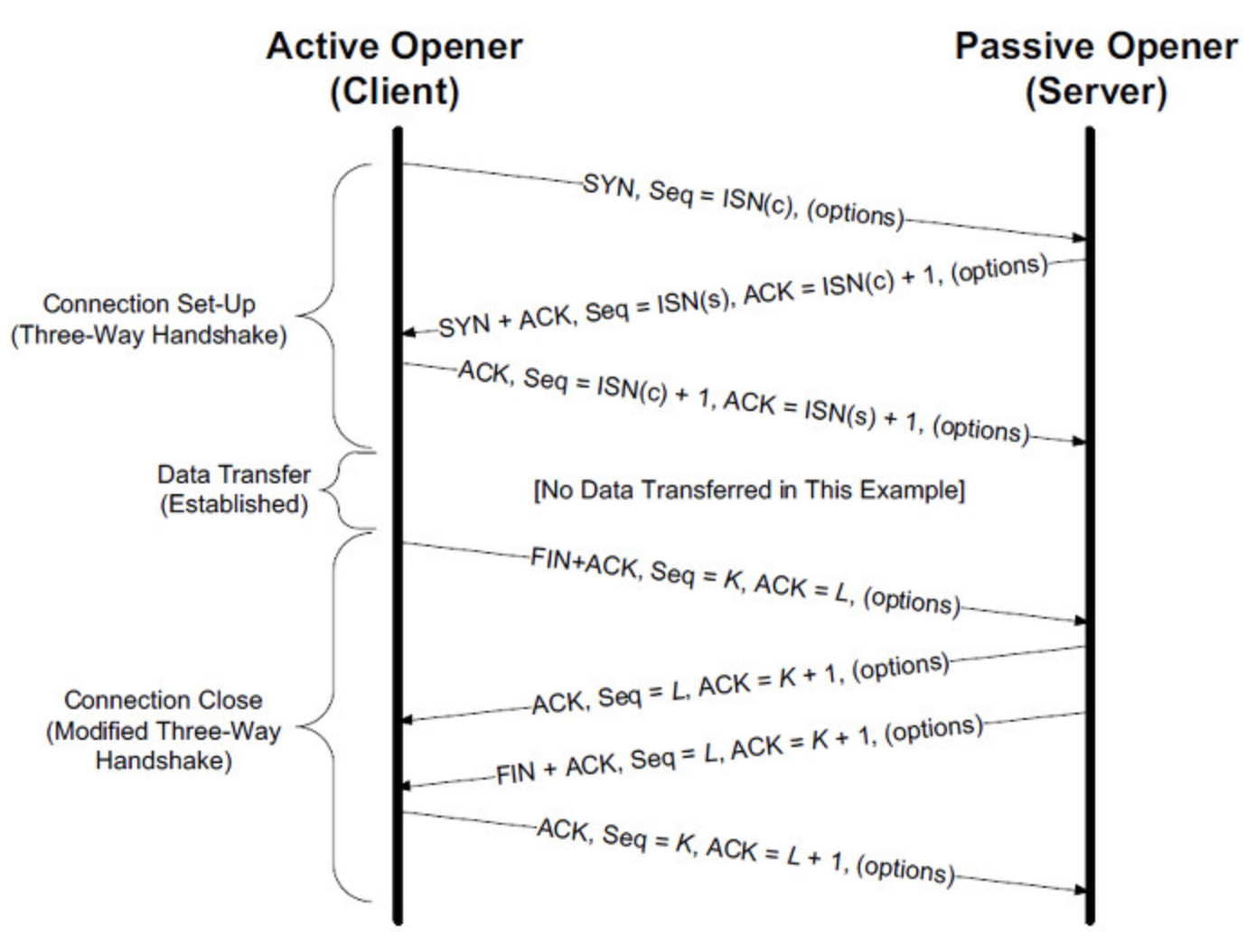
7-1. 클라이언트가 초기 순서 번호(ISN, Initial Sequence Number)을 선택하고, ISN을 설정하는 중임을 나타내는 SYN 비트가 set된 한 패킷을 서버로 보낸다.7-2. 서버가 SYN을 수신하고 수용가능한 상태인지 확인한다.
-
서버가 자신의 initial sequence number를 고른다.
- 서버가 ISN 선택중임을 알리는 SYN 비트를 set한다.
-
서버가 (클라이언트 ISN + 1)을 ACK 영역에 붙이고 첫번째 패킷을 확인했다고 알리는 ACK 플래그를 추가한다.
7-3. 클라이언트가 패킷을 하나 보내 연결을 확인해준다.
-
자신의 ISN을 하나 올린다.
-
수신자 확인 번호를 하나 올린다.
-
ACK 필드를 set한다.
7-4. 데이터가 다음과 같이 옮겨진다.
-
한쪽에서 N개의 데이터 바이트를 보내면서, SEQ를 해당 숫자만큼 증가시킨다.
-
반대편이 스 패킷(혹은 연결된 여러 패킷)을 받았다고 알리면, 상대로부터 마지막에 받았던 순서와 같은 ACK 값을 담아 ACK 패킷을 보낸다.
7-5. 연결을 끊을 때:
-
닫는 쪽이 FIN 패킷을 보낸다.
-
반대편이 FIN 패킷을 ACK하고 자신의 FIN을 보낸다.
-
닫는 쪽이 반대편의 FIN을 ACK와 함께 확인하고 알린다.
-
8. HTTPS인 경우 TLS(Transport Layer Security) handshake가 추가된다.
TLS는 SSL(Secure Sockets Layer)이 표준화 되면서 바뀐 이름이다. HTTPS로 통신을 하게 되면 7번 TCP 소켓 통신과정 전에 아래의 그림과 같은 통신이 추가된다. 여기서 시간은 큰 의미는 없다.
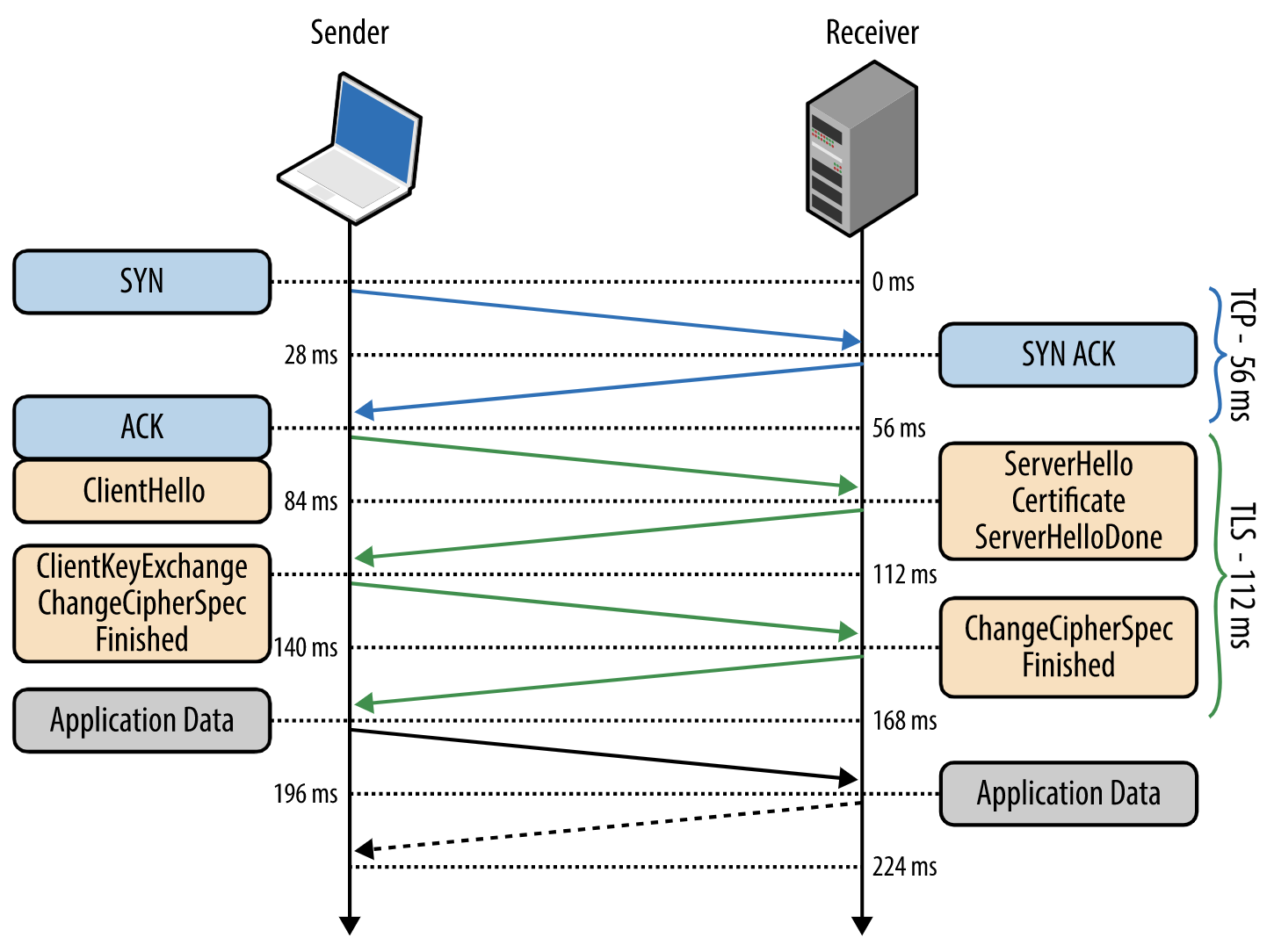
1. 0~28ms : TCP 소켓 생성 - TLS는 TCP 통신으로만 전송되기 때문에 일단 TCP 소켓이 생성돼야 한다.
- 56ms : TCP 연결을 통해 클라이언트는 다음 정보를 ClientHello 메시지에 담아 서버로 보낸다.
- 브라우저가 사용하는 SSL 혹은 TLS 버전 정보
- 브라우저가 지원하는 암호화 방식 모음(cipher suite)
- 브라우저가 순간적으로 생성한 임의의 난수(숫자)
- 만약 이전에 SSL handshake가 완료된 상태라면, 그 때 생성된 세션 아이디(Session ID)
- 기타 확장 정보(extension)
cipher suite : 보안의 궁극적 목표를 달성하기 위해 사용하는 방식을 패키지의 형태로 묶어놓은 것을 의미한다.
보안의 목표
- 안전한 키 교환
- 전달 대상 인증
- 암호화 알고리즘
- 메시지 무결성 확인 알고리즘
- 84ms : 서버는 클라이언트에게 다음 정보를 ServerHello 메시지에 담아 답장한다.
- 브라우저의 암호화 방식 정보 중에서, 서버가 지원하고 선택한 암호화 방식(cipher suite)
- 서버의 공개키가 담긴 SSL 인증서, 인증서는 CA의 비밀키로 암호화되어 발급된 상태이다.
이 인증서는 대칭키가 생성되기 전까지 클라이언트가 나머지 handshake 과정을 암호화하는 데에 쓸 공개키를 담고 있다. - 서버가 순간적으로 생성한 임의의 난수(숫자)
- 클라이언트 인증서 요청(선택 사항)
-
112ms : 클라이언트는 서버측 SSL 인증서가 유효한지를, 신뢰할 수 있는 CA 목록을 통해 확인한다
만약 CA를 통해 신뢰성이 확보되면, 클라이언트는 의사 난수(pseudo-random) 바이트를 생성해 서버의 공개키로 암호화한다. 이 난수 바이트는 대칭키를 정하는 데 사용된다.대부분 브라우저에는 공신력 있는 CA들의 정보와 CA가 만든 공개키가 이미 설치되어 있다. 서버가 보낸 SSL 인증서가 정말 CA가 만든 것인지를 확인하기 위해 내장된 CA 공개키로 암호화된 인증서를 복호화해본다. 정상적으로 복호화가 되었다면 CA가 발급한 것이 증명되는 셈이다. 만약 등록된 CA가 아니거나, 등록된 CA가 만든 인증서처럼 꾸몄다면 이 과정에서 발각이 되며 브라우저 경고를 보낸다.
인증서가 유효하면, 브라우저는 자신이 생성한 난수와 서버의 난수를 사용해 premaster secret을 만든다.
웹 서버 인증서에 딸려온 웹사이트의 공개키로 이것을 암호화하여 서버로 전송한다. -
140ms : 서버는 난수 바이트(premaster secret)를 자신의 사이트의 개인키(비밀키)로 복호화해 대칭 마스터키 생성에 활용한다.
복호화한 값을 master secret 값으로 저장한다. 이것을 사용하여 방금 브라우저와 만들어진 연결에 고유한 값을 부여하기 위한 session key를 생성한다. 세션키는 대칭키 암호화에 사용할 키다. 이것으로 브라우저와 서버 사이에 주고받는 데이터를 암호화하고 복호화한다. -
168ms : 서버/클라이언트는 SSL handshake를 종료하고, 드디어 HTTPS 통신을 시작한다.
클라이언트는 Finished 메시지를 서버에 보내면서, 지금까지의 교환 내역을 해시한 값을 대칭키로 암호화하여 담는다.
서버는 스스로도 해시를 생성해 클라이언트에서 도착한 값과 일치하는 지 본다. 일치하면, 서버도 마찬가지로 대칭키를 통해 암호화한 Finished 메시지를 클라이언트에 보낸다.이제부터 TLS 세션이 대칭키로 암호화된 어플리케이션 (HTTP) 데이터를 전송한다.
9. HTTP 프로토콜로 요청한다.
그냥 HTTP라면 7번의 connection set-up 이후 부터이고, HTTPS라면 8번에 있는 그림에서 168ms 부터이다.
클라이언트가 HTTP 프로토콜을 사용해서 서버에 다음과 같은 형식으로 요청을 보낸다.
GET / HTTP/1.1
Host: naver.com
Connection: close
[other headers]여기서 other headers는 콜론(:)으로 구분된 key, value 쌍을 말하며 HTTP 사양에 따라 형식이 지정되고 단일의 한 행으로 구분된다. (HTTP header 목록)
영구 연결을 지원하지 않는 HTTP/1.1은 응답이 완료된 후 연결이 닫히도록 하는 close 연결 옵션을 포함해야 한다.
Connection: close요청과 헤더를 보낸 후 웹 브라우저는 하나의 빈 줄을 서버에 보내 요청 내용이 완료되었음(모두 보냈음)을 알린다.
서버는 요청의 상태를 나타내는 코드와 아래와 같은 형식으로 응답한다.
200 OK
[response headers]이 응답에 빈 줄을 하나 붙인 뒤, www.naver.com의 HTML 본문을 페이로드에 담아 보낸다. 이 후에 서버는 곧 연결을 끊거나, 클라이언트가 보낸 헤더가 요청한 경우, 추가적인 요청을 위해 재사용될 수 있도록 연결을 유지해둔다.
만약 웹 브라우저가 보낸 HTTP 헤더에, 마지막으로 보냈던 파일이 브라우저에 캐시되어 있고 그 뒤로 수정되지 않았으면(HTTP header의 ETag 값으로 확인) 서버에선 다음과 같이 응답한다.
304 Not Modified
[response headers]이 응답에선 페이로드가 없는 대신 웹 브라우저가 자체 캐시에서 HTML 폼을 가져온다.
HTML을 파싱한 후 웹 브라우저와 서버는 이 과정을 HTML 페이지에서 참조되는 모든 자원(Image, CSS, favicon.ico 등)에 대해 이 프로세스를 반복한다.
만약 HTML이 www.google.com 이 아닌 도메인의 리소스를 참조하는 경우, 웹 브라우저가 다른 도메인을 확인하는 단계(5번 단계)로 되돌아가 해당 도메인에 대해 여기까지의 과정을 수행한다. 요청에 들어있는 Host 헤더는 google.com 대신 해당 서버의 이름으로 설정 된다.
10. HTTP 서버가 응답한다.
HTTPD(HTTP Daemon)서버는 요청/응답을 처리하는 서버이다. 가장 일반적인 HTTPD 서버는 리눅스의 경우 Apache 또는 Nginx이고 Windows의 경우 IIS이다.
-
HTTPD 서버가 요청을 수신한다.
-
서버는 요청을 다음 매개변수로 구분한다.
- HTTP 메서드 (GET, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, HEAD), 주소표시줄에 직접 입력한 url의 경우는 GET
- 도메인 (여기서는 google.com)
- 요청 된 경로 ( /path 형태, 여기서는 / 로 기본 경로이다.)
-
서버는 google.com에 해당하는 가상 호스트가 서버에 설정되어 있는지 확인한다.(하나의 서버에서 여러 도메인을 서비스 할 수 있음)
-
서버는 google.com이 GET 요청을 수락할 수 있는지 확인한다.
-
서버는 해당 클라이언트가 이 method를 사용할 수 있는 지 확인한다.(IP, 인증 등을 통해서)
-
서버에 rewrite module이 설치되어 있으면 (예: Apache의 경우 mod_rewrite, IIS의 경우 URL Rewrite) 요청된 rule 중 하나와 일치하도록 시도, 일치하는 rule이 있는 경우 서버는 해당 rule을 사용하여 요청을 다시 작성한다.
-
서버는 요청에 해당하는 콘텐츠를 가져오고, 여기서는 “/”가 기본 경로이므로 이 경우 index 파일을 해석한다.
-
서버는 가져온 파일을 핸들러를 통해 파싱한다. 구글이 php위에서 동작한다면, 서버는 php를 사용하여 index 파일 해석 후 출력을 클라이언트로 스트리밍한다.
11. 웹 브라우저가 그린다.
서버가 브라우저에 리소스(HTML, CSS, JS, Image 등)를 제공하면 브라우저는 아래 프로세스를 수행한다.
- 구문 분석(파싱) - HTML, CSS, JS
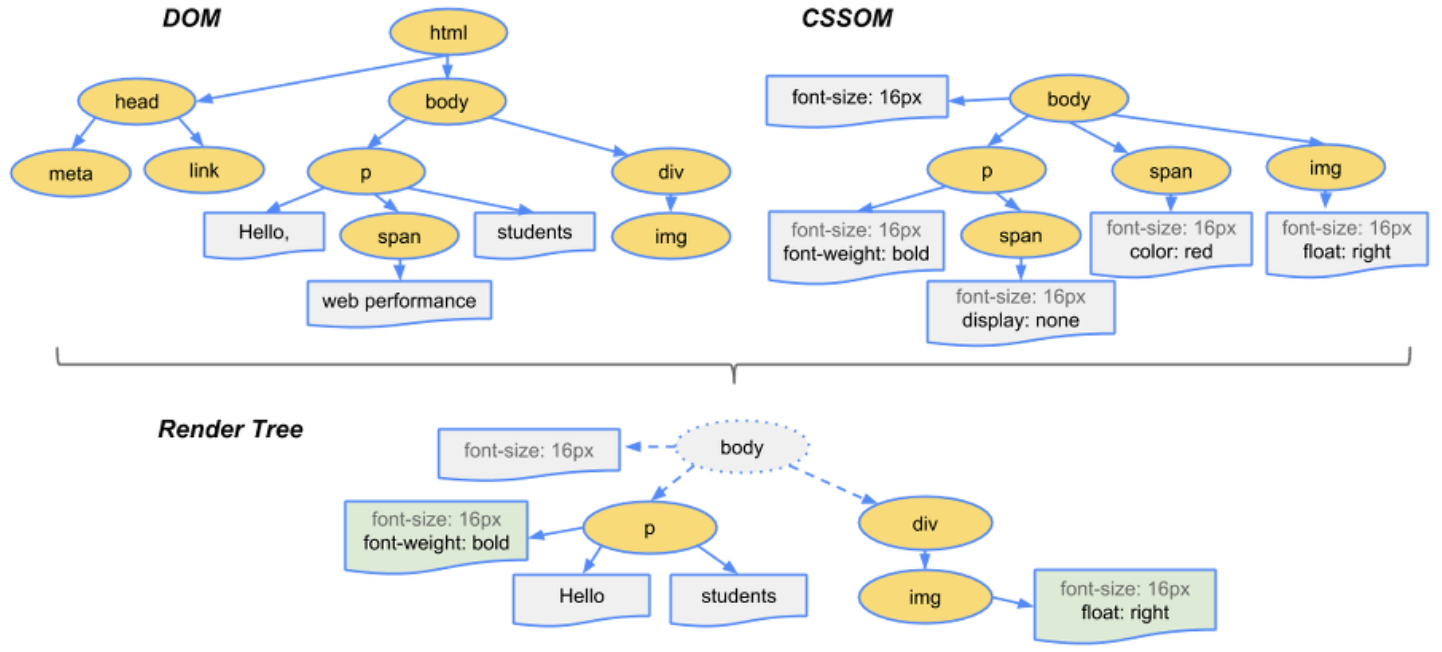
- 렌더링 - DOM Tree 구성 -> 렌더 트리 구성 -> 렌더 트리 레이아웃 배치 -> 렌더트리 그리기
12. 브라우저
웹 브라우저는 선택한 웹 리소스를 서버에 요청하고 브라우저 창에 보여주는 역할이다. 리소스는 일반적으로 HTML 문서이지만 PDF, 이미지 또는 다른 유형의 콘텐츠일 수도 있다. 리소스의 위치는 사용자가 지정한 URI(Uniform Resource Identifier)로 확인할 수 있다.
브라우저가 HTML파일을 해석하고 표시하는 방법은 HTML 및 CSS 스펙에 명시되어 있다. 이 스펙들은 웹 표준 단체인 W3C(World Wide Web Consortium)가 유지한다.
브라우저와 User Interface는 서로 유사한 점이 많다.
일반적인 User Interface 구성요소들은:
- URI를 입력하기 위한 주소창
- 뒤로 및 앞으로 버튼
- 북마크(즐겨찾기) 버튼
- 현재 문서에 대한 새로고침 및 중지 버튼
- 사용자의 홈페이지로 갈 수 있는 홈 버튼
브라우저 자세한 구조
브라우저의 구성요소는:
- User Interface : 사용자 인터페이스는 주소창, 뒤로/앞으로 버튼, 북마크 메뉴 등을 포함한다. 사용자가 요청한 페이지가 표시된 창을 제외한 브라우저의 모든 부분이다.
- Browser Engine : Brower Engine은 UI와 Rendering Engine 사이에 일어나는 일을 통제한다.
- Rendering Engine : Rendering Engine은 요청된 콘텐츠를 표시한다. HTML이 요청된 경우, Rendering Engine은 HTML과 CSS를 파싱하고, 파싱된 콘텐츠를 화면에 표시한다.
- Networking : Networking은 HTTP와 같은 네트워크 요청을, 플랫폼별로 다른 구현체를 활용해 플랫폼-독립적인 인터페이스 뒤에서 처리한다.
- UI backend : UI backend는 콤보박스나 창 같은 기본 위젯을 그리는 데 사용된다. 이 백엔드는 플랫폼에 구애받지 않는 포괄적인 인터페이스를 제공한다. 내부적으로는 운영체제의 User Interface method를 사용한다.
- Javascript Engine : Javascript 코드를 파싱하고 실행하는 데 사용한다.
- Data Storage(데이터 저장소) : 데이터 저장소는 유지가 되는 계층이다. 브라우저가 쿠키와 같은 갖가지 종류의 데이터를 로컬로 저장해야 할 수도 있다. localStorage, IndexedDB, WebSQL, File System과 같은 저장 매커니즘을 지원한다.
13. HTML parsing
- 렌더링 엔진은 요청된 문서의 내용을 네트워킹 계층에서 가져온다. 보통 8KB 단위로 이루어진다.
- HTML 파서의 주요 작업은 HTML 마크업을 parse tree로 파싱하는 것이다.
- 생성된 트리(parse tree)는 DOM(Document Object Model)요소와 속성 노드의 트리이다. parse tree는 HTML 문서와 HTML 요소를 Javascript 같은 외부 요소와 이어주는 인터페이스의 객체 표현 방식이다. 이 트리의 root는 “Document”객체이다. 스크립팅을 통한 조작 전에는 마크업과 DOM은 거의 일대일 관계를 유지한다.
Parsing 알고리즘
- HTML은 일반적인 top-down 방식이나 bottom-up 방식의 파서로는 분석할 수 없다.
- 이유
1) HTML은 관대한 언어이다.
2) 브라우저는 잘못된 HTML을 지원하기 위해 일반적인 오류 허용 범위를 갖고 있다.
3) HTML이 파싱되는 동안 변경될 가능성이 있다. (document.write()를 사용해서 동적 코드로 추가적인 토큰을 추가할 수 있다.) - 일반적인 parsing 기술을 사용할 수 없기 때문에, 브라우저는 임의의 파서를 사용해 HTML을 파싱한다. 파싱 알고리즘은 HTML5 스펙에 자세히 서술되어 있다.
- 이 알고리즘은 토큰화와 트리구조화의 두 단계로 구성된다.
파싱이 끝난 후의 동작
브라우저가 페이지에 연결된 외부 리소스(CSS, Image, Javascript file)를 가져오기 시작한다.
이 단계에서 브라우저는 해당 문서가 상호작용 중이라는 표시를 해두고 “deferred” 모드에 있는 스크립트를 파싱하기 시작한다. 문서 상태는 “complete”로 설정되고 “load”이벤트가 발생한다.
HTML 페이지에는 “Invalid Syntax” 오류가 없다. 브라우저가 잘못된 콘텐츠를 고쳐서 계속한다.
14. CSS parsing
- “CSS lexical and syntax grammar”를 사용하여 CSS파일,
- 각 CSS file은 StyleSheet object로 parsing된다. 각 object에는 CSS 문법에 해당하는 선택자와 객체가 일치하는 CSS 문법이 있다.
- CSS parser는 regular top-down 방식이거나 bottom-up parsers일 수 있다.
15. Page Rendering
- DOM 노드를 탐색하고 각 노드에 대한 CSS 값을 계산하여 “Frame tree” 또는 “Render tree”를 만든다.
- 자식 노드의 기본 width와 수평 margin, border, padding을 합해서 Frame tree 내 각 노드의 기본 너비를 거꾸로 계산한다.
- 각 노드가 사용 가능한 너비를 자식 노드에 할당하여 각 노드의 실제 width 값을 계산한다.
- 텍스트 래핑(wrapping)을 적용하고 자식 노드의 height와 margin, border, padding을 합해 각 노드의 높이를 거꾸로 계산한다.
- 위에서 계산된 정보를 사용해서 각 노드의 좌표를 계산한다.
- float, absolutely, relatively와 같은 속성이 사용되었을 경우 더 복잡한 단계가 수행된다.
- 레이어를 만들어 다시-래스터화 되지 않고 페이지 내 어떤 부분이 그룹으로 애니메이션화 될 수 있는지 설명한다. 각 frame/render object는 레이어에 할당된다.
- 페이지의 각 레이어를 위해 텍스처가 할당된다.
- 각 레이어의 frame/render object를 통해서 각 레이어 별로 그리기 명령이 실행된다.
- 위의 모든 단계를 최근에 웹페이지가 렌더링된 계산된 값을 재사용 할 수 있어서, 이후의 변화에 대해서 작업이 덜 필요하다.
- 페이지 레이어는 합성 프로세스로 보내져 chrome 브라우저, iframe, addon panels과 같은 시각적인 콘텐츠의 레이어와 결합된다.
- 최종 레이어 위치가 계산되고 합성 명령이 Direct3D/OpenGL을 통해 실행된다. GPU 명령 버퍼는 비동기 렌더링을 위해 GPU로 출력되고 frame은 window server로 전송된다.
16. GPU Rendering
- 렌더링 과정 동안 graphical computing layers(그래픽 처리 연산 레이어)는 범용 CPU 또는 GPU 모두 사용할 수 있다.
- GPU를 graphical rendering 연산에 사용하는 경우, 그래픽 담당 소프트웨어 레이어에서 해당 업무를 여러 조각으로 분할하여, GPU 의 막강한 부동 소수점 연산 병렬처리를 통해 렌더링을 수월하게 만들다.
17. 윈도우 서버
렌더링 후처리와 사용자에 의해 유도된 동작
렌더링이 완료되면, 브라우저는 Javascript 실행한다. 스크립트는 추가적인 네트워크 요청을 만들기도 하고, 페이지 자체나 레이아웃을 바꾸기도, 새로운 페이지 렌더링 및 페인팅을 다시 수행한다.
참고
https://github.com/SantonyChoi/what-happens-when-KR
https://brunch.co.kr/@sangjinkang/38
https://velog.io/@jaeyunn_15/Network-www.naver.com%EC%9D%84-%EC%B9%98%EB%A9%B4-%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94-%EC%9D%BC
https://velog.io/@minjae-mj/%ED%98%B8%EC%8A%A4%ED%8A%B8-%EB%84%A4%EC%9E%84%EA%B3%BC-%EB%8F%84%EB%A9%94%EC%9D%B8-%EB%84%A4%EC%9E%84
https://it-mesung.tistory.com/180
