
-
최고 실력자는 개념적 데이터 모델링에 배치하는 것이 좋음
-
논리적 데이터 모델링 : 개념적 데이터 모델링에서 뽑아낸 개념을 관계형 데이터베이스 패러다임에 어울리게 데이터 형식을 정리정돈 하는 것
-
Mapping Rule : ERD를 RDB로 전환할 때 사용하는 방법론
- Entity -> Table
- Attribute -> Column
- Relation -> PK, FK
-
제약조건 : "특정 컬럼의 도메인을 설정함" 이라고도 함
-
PK, FK 연결 : 카디널리티 중유
-
1:N일땐, FK를 N쪽에 줌
-
1:1일땐, 의존성 관계 파악 필요
- ex) 휴먼저자의 id는 저자id에 의존함(혼자서 지냄 : 부모, 의존 필요 : 자식) -> 저자는 휴먼이거나 아닐 수도 있음 -> 1:1(Optional) -> 저자 : Mandatory, 휴먼 : Mandatory + Optironal
-
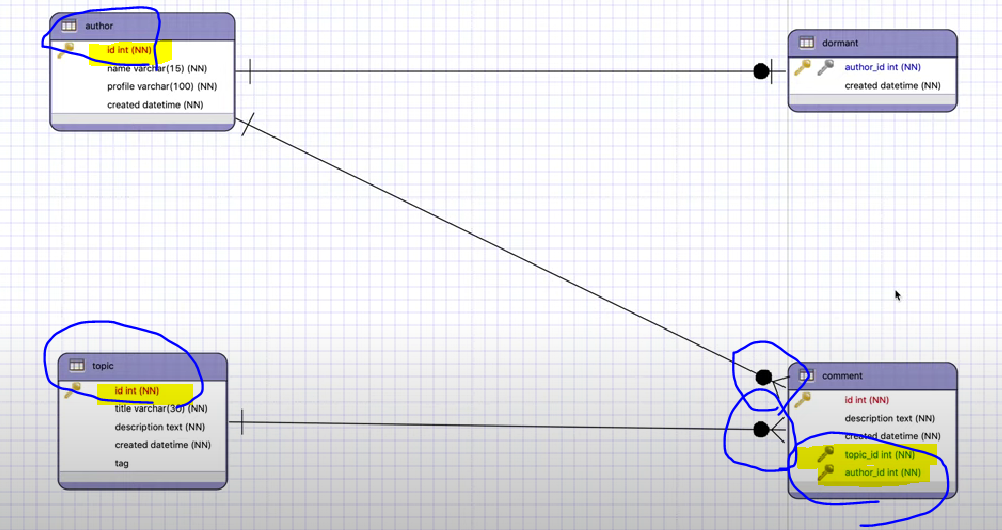
1:N일때, N쪽에 FK를 두면 됨!
- ex) author와 comment 1:N
-
N:M 관계 : 컬럼 추가 애매(한 필드에 2개의 값이 존재할 수 있음)
- Mapping Table 이용해서 1:N으로 나눔
- id속성이 결합했을 때 의미있는 정보를 필드에 추가하기도 함(각각의 저자가 그 글을 언제 수정하기 시작했는가 등)
ex) 저자:글 => N:M관계 => 중간에 저자, 글id정보를 담는 매핑테이블 - 추가하는 두개의 id 둘다 PK, FK 지정 => 두개의 속성 결합된 것이 PK이자 FK(복합키!!)
-
-
정규화(Normalizetion) : 정제되지 않은 데이터를 관계형 데이터베이스에 어울리는 표로 만들어 주는 규칙
- 산업적으로 3정규형까지 많이 사용됨
- 1정규화 : 각각의 Column이 Atomic하다.
- M:N관계의 속성 중 하나를 빼서 테이블화 하고, Mapping테이블을 중간에 만듦
- 2정규화 : 부분 종속성이 없어야 함(기본키 중 중복키가 없어야 함)
- ex) title, type이 복합키인데, 속성들 중 일부는 title에만 의존가능 => 부분 종속
- 부분적으로 종속되는 컬럼들만 모으고, 전체적 종속을 따로 쪼갬
- 3정규화 : 이행적 종속성 제거
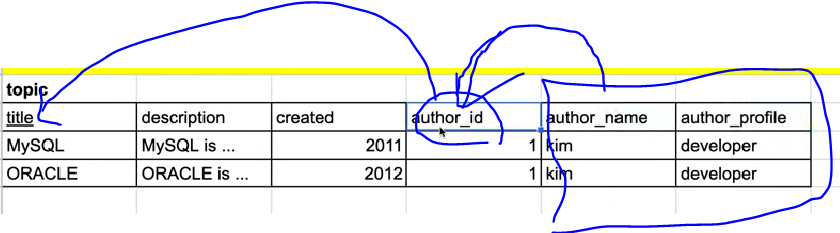
- author_id는 기본키인 title에 의존
- author_name, author_profile은 author_id에 의존
- 중복을 만들어내는 부분을 별도 테이블로 생성

- author라는 별도 테이블 생성하고 참조
- author테이블 내 중복행 삭제
-
물리적 데이터 모델링 : 이상적인 표를 구체적인 제품에 맞는 현실적인 표로 만드는 것(성능 중요)
- 제일 중요한 것은 우선 해보고, 병목 발생하는 지점을 해결하기!
- find slow query ! : 느려지는 쿼리 찾기!
- 최후의 보류 : 역정규화(이상적으로 구성한 표에 손대는 것)
-
속도 향상의 방법
- index : 행에 대한 읽기 성능을 향상 시킴, 쓰기 성능을 감소(쓰기 할 때마다 인덱스가 입력된 정보를 정리정돈 하기 위한 복잡한 연산 => 엄청 빠른 읽기 속도)
- application 영역에서 Cashe 활용
- denormalization : 성능 향상을 위해 최후의 보류인 역정규화 활용
-
denormalization : 정규화된 표를 성능 또는 개발의 편의성을 위해 구조를 변경하는 것
- 정규화 : 주로 쓰기(write)의 편리함을 위해 읽기(read)의 성능 희생
- 정규화 시 테이블 여러개 쪼개짐 -> 읽기 시 join 연산이 많음 -> 비용이 많이 듦(읽기 성능 저하) -> 읽기가 많아져 성능이 저하되는 케이스 종종 생김 -> 여러 방법들 해보고 최후의 수단으로 역정규화
- 정규화를 한다고 해서 반드시 성능을 떨어트리는 것은 아님
- 역정규화 : 규칙이 있는 것은 아니고, 영상에서 처럼 예시가 있다 정도만 이해
- 역정규화시 정규화 전에 발생한 문제를 그대로 겪게됨
-
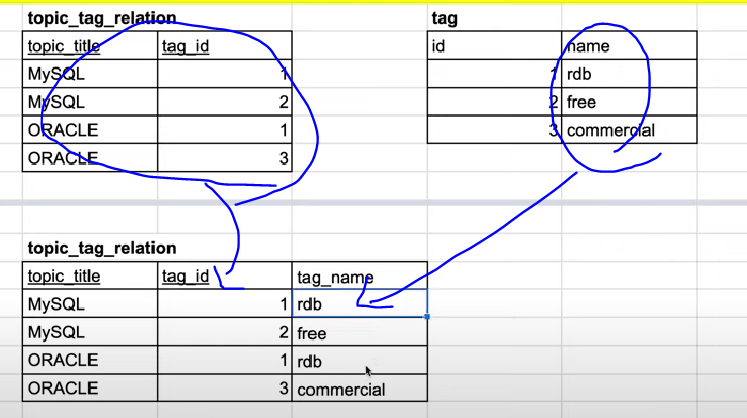
조인을 줄이기 위해 중복을 허용한 테이블로 변경 : 중복이 발생하나 조인이 없이 사용 가능
-
계산된 결과를 속성으로 추가하여 Join 연산을 줄임

- 기존에는 topic의 id를 count갯수를 groupby를 통해 구했음
- 데이터가 많아진다면 groupBy의 비용 증가 -> 미리 id별 갯수를 속성값으로 넣어 읽기 성능 향상
- 하지만 이렇게 설계할 경우 항상 카운트 값을 갱신해야하는 단점이 있음
-
컬럼 기준 테이블 분리

- description : 길이도 길고, description만 조회하는 연산이 많다 가정 /
description을 제외한 다른 속성을 조회하는 연산이 많다 가정 - 각각의 표들을 서로 다른 컴퓨터에 저장(분산)이 가능해지면 성능을 더 향상시킬 수 있음 -> 샤딩(스케일 아웃의 기법), 운영 및 유지 어려움
- description : 길이도 길고, description만 조회하는 연산이 많다 가정 /
-
행 기준 테이블 분리
- 이론적으론 한계가 없으나 관리가 어렵
- ex) 1억명의 author => 1000번까지 테이블 x 10개 분리
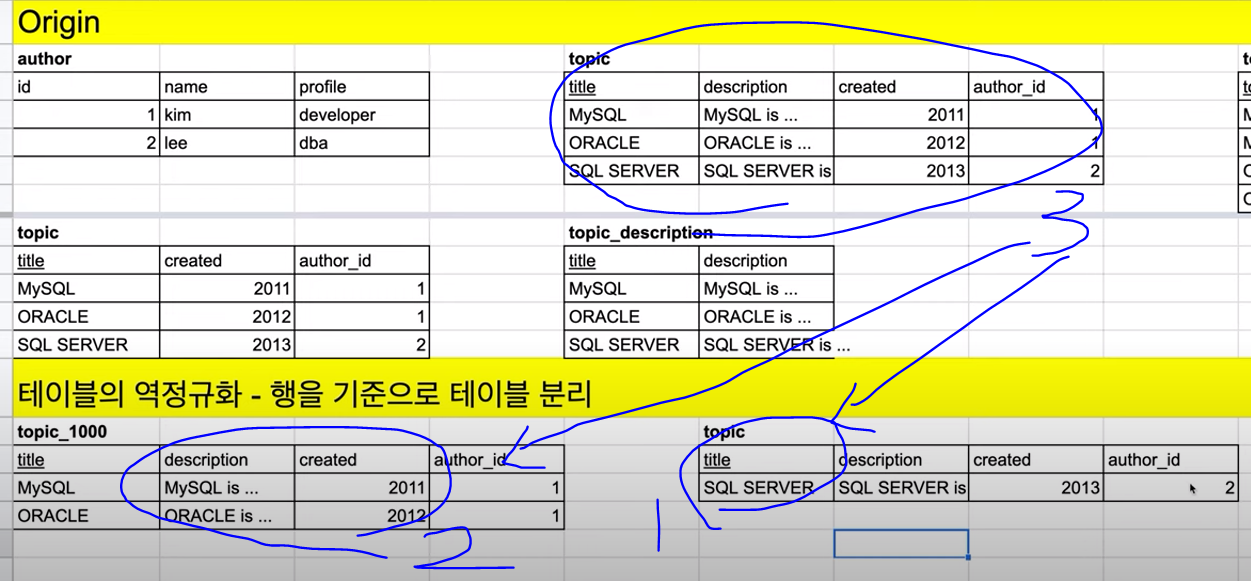
- 사용자의 id 번호에 따라 나눠진 테이블로 쿼리를 보내는 것으로 구분
- 물리적 서버마다 서로 다른 데이터를 조회하거나 저장 가능(무한히 많은식 가능, 물론 어렵고 사고의 위험..!)
- ex) 1번 id의 경우 topic_1000에 저장, 조회 이뤄짐
-
관계의 역정규화 - Join을 줄여 지름길을 만든다
- 속성을 추가하여 Join 2번 필요한 테이블을 1번으로 줄임
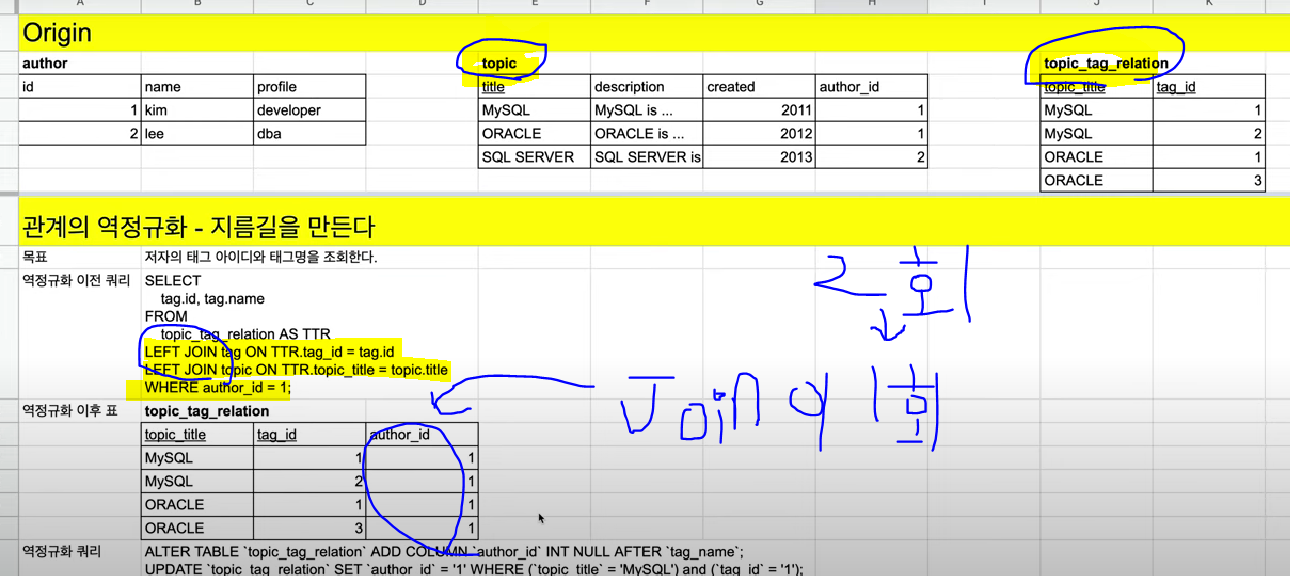
- 속성을 추가하여 Join 2번 필요한 테이블을 1번으로 줄임
-
지난번 ERD 영상까지 본 뒤, 프로젝트 ERD 구축에 막힘없이 진행한 것 같다.
-
내일부터 주말까지 DB복습과 QueryDSL까지 가보자고~~

비슷한 어려움을 겪는 누군가에게 도움이 되길