
[오해들]
-
연관관계 매핑 : 데이터베이스 테이블의 외래키를 객체의 참조와 매핑하는 것
-
단방향 매핑만으로 연관관계 매핑 이미 완료
-
양방향 매핑은 단방향 매핑에 비해 반대 방향으로의 객체 그래프 탐색 기능이 추가된 것 뿐
-
단방향으로 충분하나 보통 반대 방향으로의 그래프 탐색이 필요할 때 양방향 사용
-
영속성 전이 : Entity의 영속성 상태 변화를 연관된 엔티티에도 함께 적용하는 것
-> 연관관계의 다중성 지정 시 cascade 속성으로 설정
| Cascade Type | 설명 |
|---|---|
| PERSIST | Entity를 영속 객체로 추가할 때 연관된 Entity도 함께 영속 객체로 추가 |
| REMOVE | Entity를 삭제할 때 연관된 Entity도 함께 삭제 |
| DETACH | Entity를 영속성 컨텍스트에서 분리할 때 연관된 Entity도 함께 분리 상태 |
| REFRESH | Entity를 데이터베이스에서 다시 읽어올 때 연관된 Entity도 함께 다시 읽어온다 |
| MERGE | Entity를 준영속 상태에서 다시 영속 상태로 변경할 때 연관된 Entity도 함께 변경 |
| ALL | 모든 상태 변화에 대해 연관된 Entity에 함께 적용한다 |
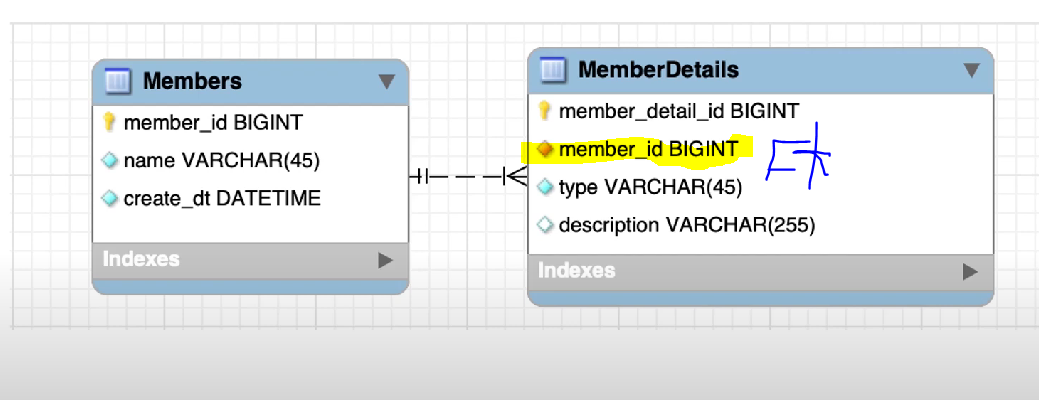
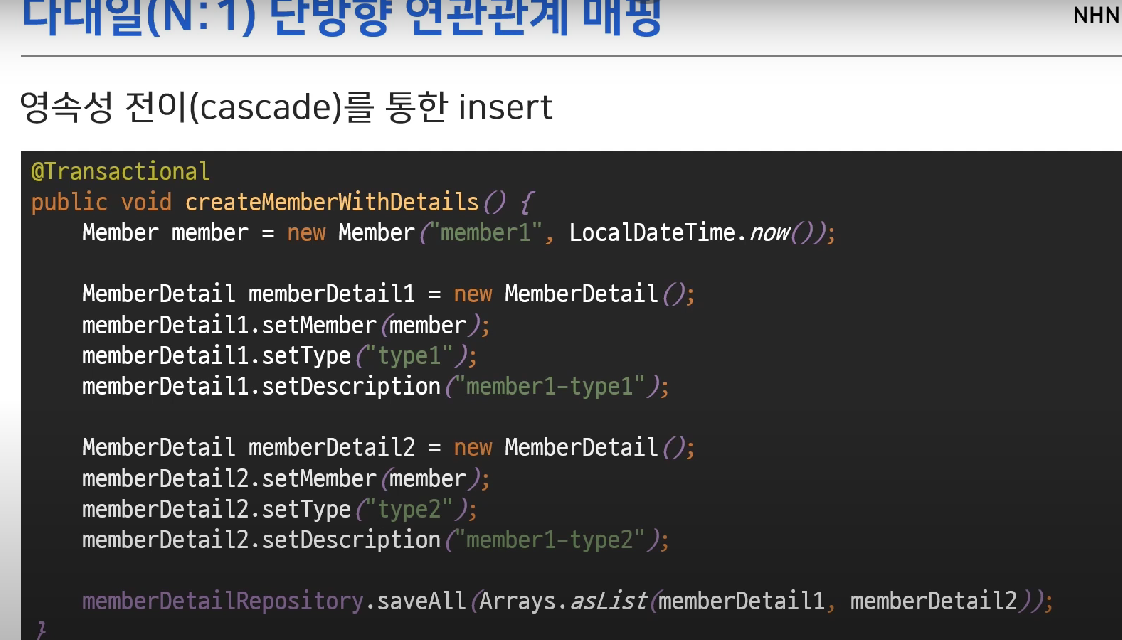
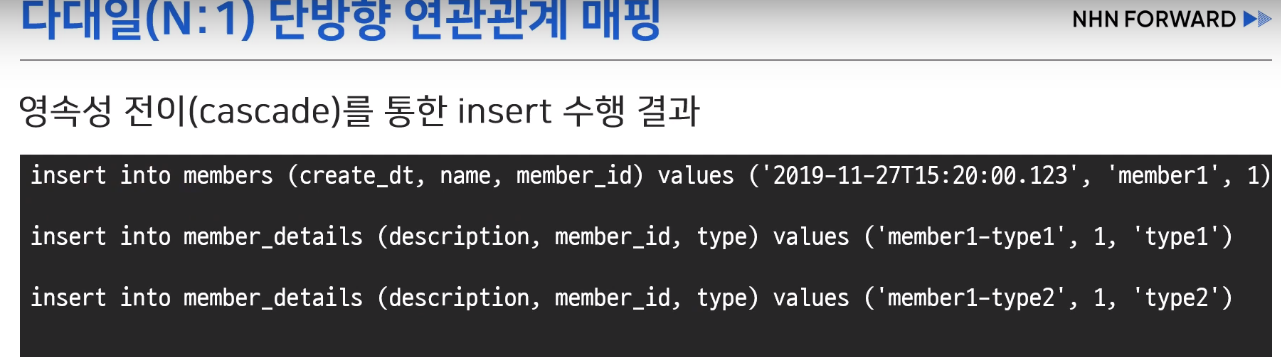
- MemberDetails에 N:1을 걸어주고, 아래의 코드를 실행하면 cascade를 걸어준 하위 객체인 Member도 저장된다.
-
1:N 단방향 매핑(@OneToMany)에서 cascade를 통한 insert시
-> 외래키 지정을 위해 추가적인 update쿼리가 발생하는 문제
-> 1:N 양방향 연관관계로 변경하면 추가적인 update쿼리가 없어짐 -
양방향 관계여도 주인을 설정하는것이 필요(포린키는 1개이기 때문), 기본키를 외래키로 사용하는 경우 @MapsId를 통해 연관관계 주인임을 밝힘
-
mappedBy로 연관관계 주인 표기
-
양방향 보다 단방향매핑이 낫다 라는 잘못된 오해 -> 1:N인 경우에서 단방향 영속성 전이를 사용하면 것이 update문 발생 -> 양방향 관계로 변경하는 편이 추가적 쿼리를 막을 수 있음
-
엔티티를 가져올 때 연관 관계에 있는 다른 엔티티들을 같이 가져오는 Fetch 관련 내용
1) 즉시 가져올 경우 : FetchType.EAGER
2) 참조가 일어날 때 : FetchType.LAZY -
기본 Fetch 전략
1) -ToOne (@OneToOne, @ManyToOne) : FetchType.EAGER
2) -ToMany(@OntToMany, @ManyToMany) : FetchType.LAZY -
N+1문제 : 엔티티에 대해 하나의 쿼리로 N개의 레코드를 가져왔을 때, 연관관계 엔티티를 가져오기 위해 쿼리를 N번 추가적으로 수행하는 문제
-
해결방법 : Fetch Join / Entity Graph
-
N+1 문제에 대해 흔히 하는 오해
1) EAGER Fetch전략 때문이다? LAZY도 N+1 발생
2) findAll()은 N+1 문제를 발생시키지 않는다? x
-> Fetch 전략을 적용해서 연관 Entity를 가져오는 것은 오직 단일 레코드에만 적용
-> 단일 레코드 조회가 아닌 경우 JPQL 먼저 수행(findAll()의 경우, 엔티티에 설정된 Fetch 전략 적용 안됨)
-> 반환된 레코드 하나하나에 대해 엔티티에 설정된 Fetch 전략을 적용해서 연관 엔티티를 가져옴
-> 이 과정에서 N+1 발생 -
Fetch JOIN으로 N+1 문제 해결 시 흔히 하는 실수
1) Pagination + Fetch JOIN : 페이지네이션 쿼리에 Fetch JOIN을 적용하면 실제로는 모든 레코드를 가져오는 쿼리가 실행됨
-> 메모리에 모든 레코드를 가져오고 추가 처리하여 반환
-> 같이 사용하는 경우는 페이지네이션 쿼리와 페치 조인 쿼리를 분리해서 실행해야 함
2) 둘 이상의 컬렉션을 Fetch JOIN - MultipleBagFetchException
-> Java의 java.util.List 타입은 기본적으로 하이버네이트 Bag 타입으로 맵핑
-> Bag은 하이버네이트에서 중복 요소를 허용하는 비순차 컬렉션
-> 둘 이상의 컬렉션을 Fetch Join하는 경우
--> 그 결과로 만들어지는 카테시안곱에서 어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은 지 판단할 수 없어 MultipleBagFetchException 발생
--> 해결방법 : List를 Set으로 변경, @OrderColumn으로 순서 부여하면 해결
[Spring Data JPA Repository 잘 알려지지 않은 기능]
-
Repository : 도메인 객체에 접근하기 위해서 컬렉션과 유사한 인터페이스를 사용해 도메인과 데이터 매핑 계층 사이를 중재
-> JPA 개념이 아닌, Spring Framework에서 제공하는 것 -
Spring Data Repository : data access layer 구현을 위해 반복적으로 작성했던 유사한 코드를 줄이기 위한 추상화 제공
-
Spring Data JPA Repository : 웬만한 CRUD, Paging, Sorting 메서드 제공(메서드 이름 규칙을 통한 쿼리 생성)
-
오해 - JPA Repository 메서드로는 JOIN 쿼리를 실행할 수 없다? (x)
-> 1:M 관계가 있을 때 "_"로 해당 엔티티의 속성을 참조할 때 Join 쿼리 실행 -
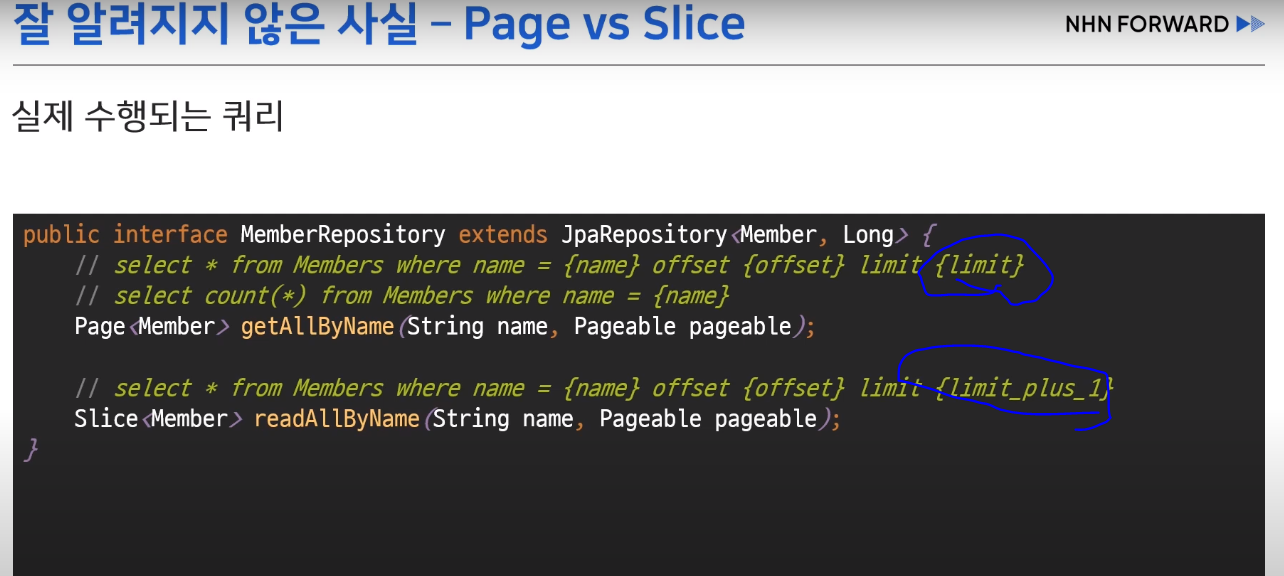
Page vs Slice : Page 인터페이스가 Slice 인터페이스 상속받음
-> page는 count 쿼리 수행 / slice는 count 수행x
-> slice 에서는 limit에 1을 더 더해서 레코드가 있는지 보고, 있으면 select를 더 수행
-> 쿼리가 하나 줄기때문에 성능상 이점일 수 있음
-> page를 쓰는 경우에도 limit보다 적은 갯수일 경우 count 쿼리는 안나감
-
DTO Projection 가능
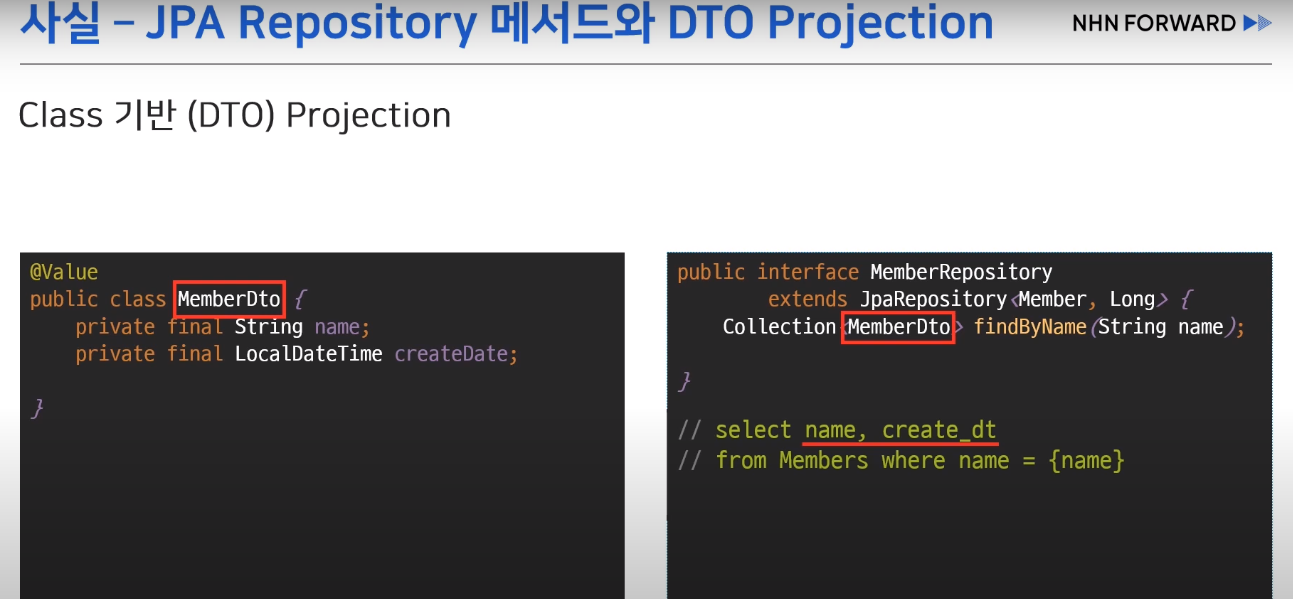
1) Class 기반 (DTO) Projection
-> @Value로 DTO 객체를 생성하고, JPA Repository에서 활용할 수 있음
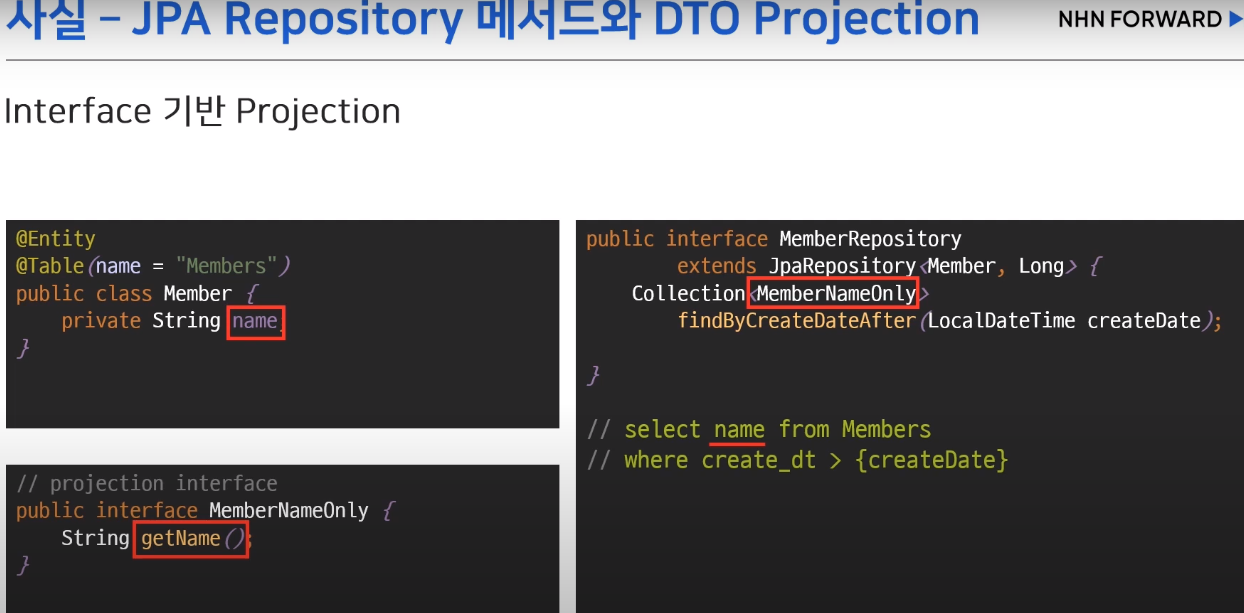
2) Interface 기반 Projection
-> 인터페이스 사용만 해주면 구현 객체는 프록시로 만들어서 수행
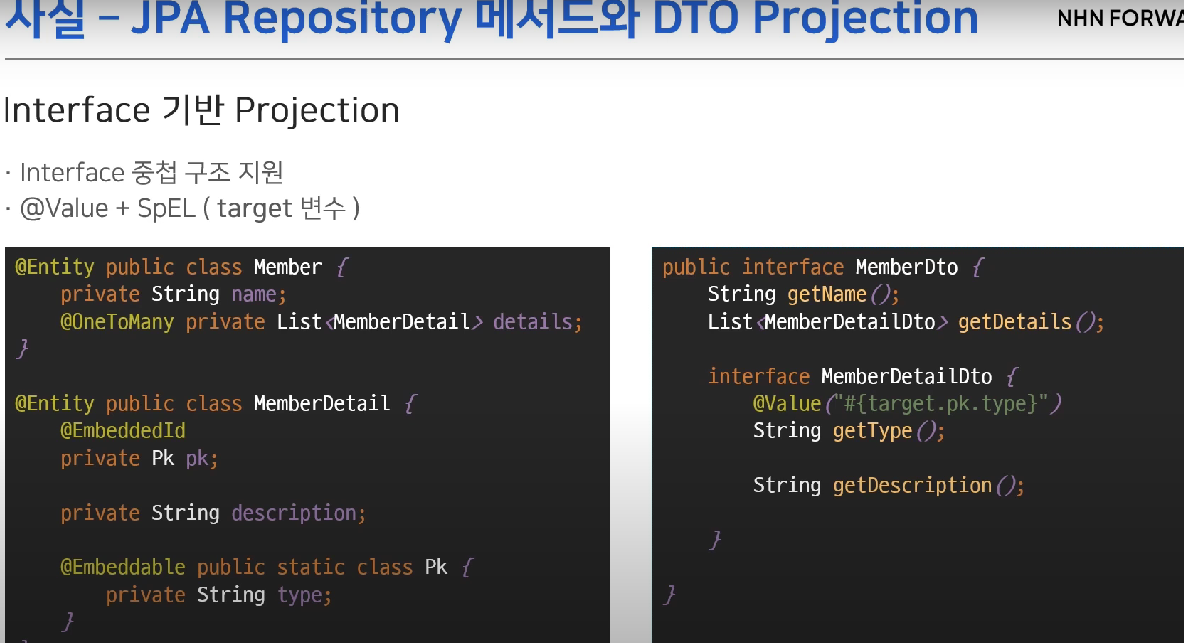
-> 중첩 구조 지원 : @Value + SpEl(target 변수)
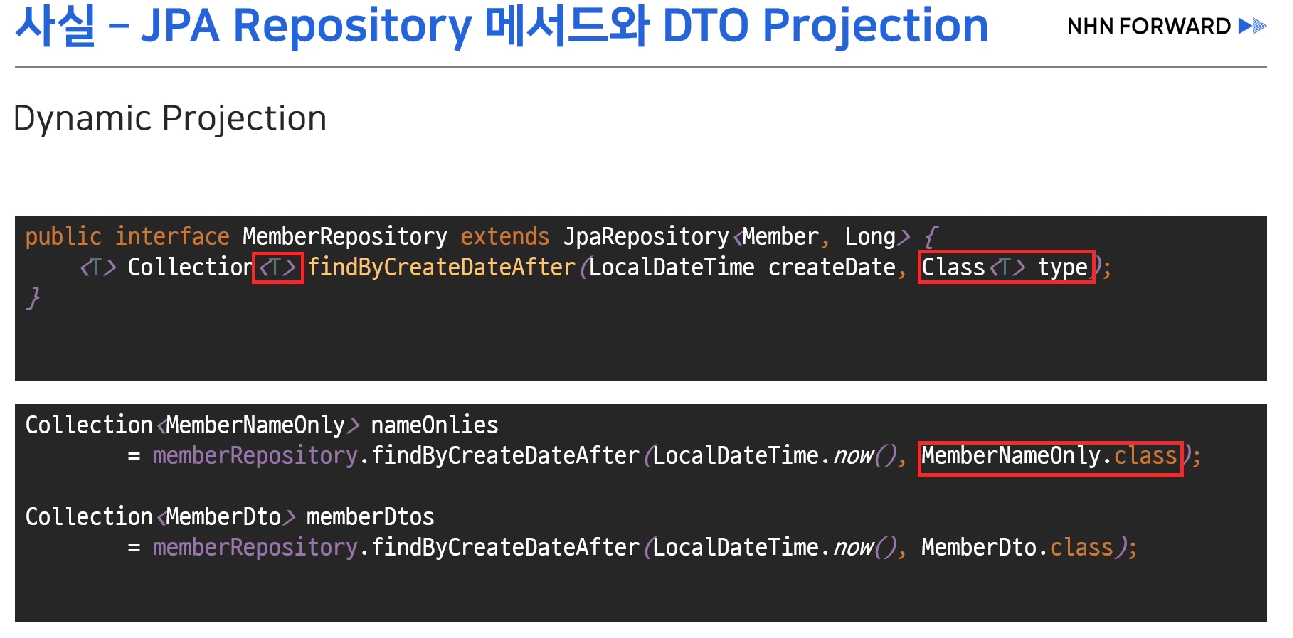
3) Dynamic Projection : 제네릭 활용 가능
- 요약
1) 연관관계 매핑
-> 단방향 매핑만으로 연관관계 매핑은 이미 완료
-> 대개의 경우 단방향 매핑이면 충분
-> 1:N 단방향 연관관계 매핑에서 영속성 전이를 사용할 경우 양방향 변경
2) Spring Data JPA Repository
-> JpaRepository 상속 - 웬만한 CRUD, Paging, Sorting 메서드 사용
-> 메서드 이름 규칙을 통한 쿼리 생성 - 이름 규칙에 따라 인터페이스에 메서드 선언만 하면 쿼리 생성
-> JPA Repository 메서드로도 JOIN 쿼리 수행 가능 - 이름 규칙에 따라 Entity 내 연관관계 필드 탐색
-> JPA Repository 메서드에서도 다양한 DTO Projection 지원
- 어려운게 너무많군..
