오늘은 안드로이드 공부와 프로젝트를 하면서 백엔드를 스스로 해보고 싶어서 간단하게 해볼 수 있으면서 평소 관심이 있었던 AI 까지 해본 것을 작성해보겠습니다
Fast Api는 우선 튜토리얼을 보고 시작했습니다.
Fast Api : 튜토리얼
그리고 localhost 에서 사용하기 위해 uvicorn을 pip하고 나머지는 필요할 때 마다 pip하기로 했습니다.
app = FastAPI(
title="Disease Prediction API",
description="질병 예측을 위해 사용하는 API",
version="1.0.0"
)
@app.get("/", tags=["Features List"])
async def root():
return {"message": "Hello World2"}uvicorn main:app --reload 를 통해 웹서버를 실행한 후 http://127.0.0.1:8000/docs에서 swagger를 확인할 수 있습니다.
질병을 예측하기 위해 데이터 수집
-> kaggle에서 수집된 데이터를 사용
당연히 영어라서 한국어로 번역과정..ㅠ
거치고 난 후 질병을 판단하기 위한 피처가 굉장히 많아 사용자에게 하나하나 입력하기에는 많은 상황이라서 중요도가 높은 피처를 판단하기 위한 파이썬 코드를 작성했다
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
def get_features_with_high_importance():
# CSV 파일을 읽을 때 발생할 수 있는 인코딩 오류를 처리하기 위해 다양한 인코딩 시도
try:
train_data = pd.read_csv("train_disease_ko.csv", encoding='utf-8')
test_data = pd.read_csv("test_disease_ko.csv", encoding='utf-8')
except UnicodeDecodeError:
try:
train_data = pd.read_csv("train_disease_ko.csv", encoding='utf-8-sig')
test_data = pd.read_csv("test_disease_ko.csv", encoding='utf-8-sig')
except UnicodeDecodeError:
train_data = pd.read_csv("train_disease_ko.csv", encoding='euc-kr')
test_data = pd.read_csv("test_disease_ko.csv", encoding='euc-kr')
# 'prognosis' 컬럼 확인
if 'prognosis' not in train_data.columns or 'prognosis' not in test_data.columns:
print("Error: 'prognosis' column is missing.")
return
# X와 y 분리
X_train = train_data.drop(columns=['prognosis'])
X_test = test_data.drop(columns=['prognosis'])
y_train = train_data['prognosis']
y_test = test_data['prognosis']
# 결측값 처리
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)
# 레이블 인코딩
label_encoder = LabelEncoder()
y_train = label_encoder.fit_transform(y_train)
y_test = label_encoder.transform(y_test)
# 랜덤 포레스트 모델 학습
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
# 피처 중요도 추출
feature_importances = rf_model.feature_importances_
# 피처 중요도를 데이터프레임으로 변환
importance_df = pd.DataFrame({
'Feature': X_train.columns,
'Importance': feature_importances
}).sort_values(by='Importance', ascending=False)
# 상위 20개 중요한 피처 출력
top_20_features = importance_df.head(20)
return top_20_features랜덤포레스트 방식으로 과적합을 방지하고 노이즈 데이터에도 강함을 보이기 때문에 선택했고 또한 랜덤포레스트는 결정 트리 기반 모델이며, 여러 개의 트리를 학습하면서 각 피처가 예측에 얼마나 기여했는지를 평가할 수 있습니다. 그렇기에 랜덤포레스트 방식으로 중요도 높은 피처를 선택하고 그 피처들의 선택 값을 통해 질병을 예측할 수 있게 합니다.
from pathlib import Path
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
# 현재 파일의 경로 (prediction.py의 위치)
current_file = Path(__file__)
# 최상위 디렉토리로 이동
parent_dir = current_file.parent.parent
# train.csv 파일의 경로
train_csv_path = parent_dir / "train_disease_ko.csv"
# 데이터 로드
# train_data = pd.read_csv(train_csv_path, encoding='utf-8-sig')
# CSV 파일을 읽을 때 발생할 수 있는 인코딩 오류를 처리하기 위해 다양한 인코딩 시도
try:
train_data = pd.read_csv(train_csv_path, encoding='utf-8')
except UnicodeDecodeError:
try:
train_data = pd.read_csv(train_csv_path, encoding='utf-8-sig')
except UnicodeDecodeError:
train_data = pd.read_csv(train_csv_path, encoding='euc-kr')
# important_features = [
# "가려움", "관절 통증", "구토", "피로", "고열",
# "발한", "짙은 소변", "메스꺼움", "식욕 부진", "복부 통증",
# "설사", "미열", "눈의 황변", "가슴 통증", "비틀거림",
# "근육통", "감각 이상", "몸에 붉은 반점", "가족력", "집중력 부족"
# ]
# 사용된 중요 피처
important_features = [
"itching", "joint_pain", "stomach_pain", "vomiting", "fatigue",
"high_fever", "dark_urine", "nausea", "loss_of_appetite",
"abdominal_pain", "diarrhoea", "mild_fever", "yellowing_of_eyes",
"chest_pain", "muscle_weakness", "muscle_pain", "altered_sensorium",
"family_history", "mucoid_sputum", "lack_of_concentration"
]
# 중요 피처 정의
# important_features = [
# "fatigue", "vomiting", "high_fever", "loss_of_appetite", "nausea",
# "headache", "abdominal_pain", "yellowish_skin", "yellowing_of_eyes",
# "chills", "skin_rash", "malaise", "chest_pain", "joint_pain", "sweating"
# ]
# 학습 데이터 준비
X_train = train_data[important_features]
y_train = train_data['prognosis']
# 결측값 처리
X_train = X_train.fillna(0)
# 모델 학습
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
# 모델 저장
joblib.dump(rf_model, "rf_model.joblib")
print("모델이 저장되었습니다: rf_model.joblib")아까 얻은 중요 피처들을 이용하여 해당 값을 이용하여 질병을 예측하기 위한 모델을 학습하는 코드를 작성해줍니다.
이제 fast api에서 post로 피처들의 값을 받고 저장된 모델에 넣고 예측한 질병이름을 리턴해줍니다.
from pathlib import Path
import pandas as pd
import joblib
def load_model():
"""
학습된 모델과 중요 피처 리스트를 로드하는 함수
"""
# important_features = [
# "가려움", "관절 통증", "구토", "피로", "고열",
# "발한", "짙은 소변", "메스꺼움", "식욕 부진", "복부 통증",
# "설사", "미열", "눈의 황변", "가슴 통증", "비틀거림",
# "근육통", "감각 이상", "몸에 붉은 반점", "가족력", "집중력 부족"
# ]
important_features = [
"itching", "joint_pain", "stomach_pain", "vomiting", "fatigue",
"high_fever", "dark_urine", "nausea", "loss_of_appetite",
"abdominal_pain", "diarrhoea", "mild_fever", "yellowing_of_eyes",
"chest_pain", "muscle_weakness", "muscle_pain", "altered_sensorium",
"family_history", "mucoid_sputum", "lack_of_concentration"
]
# 중요 피처 정의
# important_features = [
# "fatigue", "vomiting", "high_fever", "loss_of_appetite", "nausea",
# "headache", "abdominal_pain", "yellowish_skin", "yellowing_of_eyes",
# "chills", "skin_rash", "malaise", "chest_pain", "joint_pain", "sweating"
# ]
# 현재 파일의 경로
current_file = Path(__file__).resolve()
# 최상위 디렉토리로 이동
parent_dir = current_file.parent.parent
# 모델 파일 경로 (모델 파일이 `a` 디렉토리에 있다고 가정)
model_path = parent_dir / "disease_prediction" / "rf_model.joblib"
# 학습된 모델 로드
model = joblib.load(model_path)
return model, important_features
def predict_disease(model, important_features, input_data):
"""
예측 수행 함수
:param model: 학습된 모델
:param important_features: 중요 피처 리스트
:param input_data: 사용자 입력 데이터
:return: 예측된 질병 이름
"""
# 입력 데이터를 DataFrame으로 변환
input_df = pd.DataFrame([input_data], columns=important_features)
# 예측 수행
prediction = model.predict(input_df)[0]
return predictionpost로 받을 데이터 모델
class UserInput(BaseModel):
itching: int
joint_pain: int
stomach_pain: int
vomiting: int
fatigue: int
high_fever: int
dark_urine: int
nausea: int
loss_of_appetite: int
abdominal_pain: int
diarrhoea: int
mild_fever: int
yellowing_of_eyes: int
chest_pain: int
muscle_weakness: int
muscle_pain: int
altered_sensorium: int
family_history: int
mucoid_sputum: int
lack_of_concentration: intpost용 fast api
@app.post("/disease-important-features", tags=["Recommend Medicine"])
async def disease_important_features(request : DiseaseRequestData):
"""
예측된 질병을 받아 해당 질병의 중요 피처를 반환
"""
# 질병 데이터 로드
disease_features = get_disease_features()
# 입력된 질병의 중요 피처 가져오기
important_features = disease_features.get(request.disease)
# 중요 피처가 없거나 데이터가 비어 있으면 에러 메시지 반환
if important_features is None or len(important_features) == 0:
return {"message": f"No important features found for disease: {request.disease}"}
# 중요 피처 반환
return important_features그리고 서버 실행
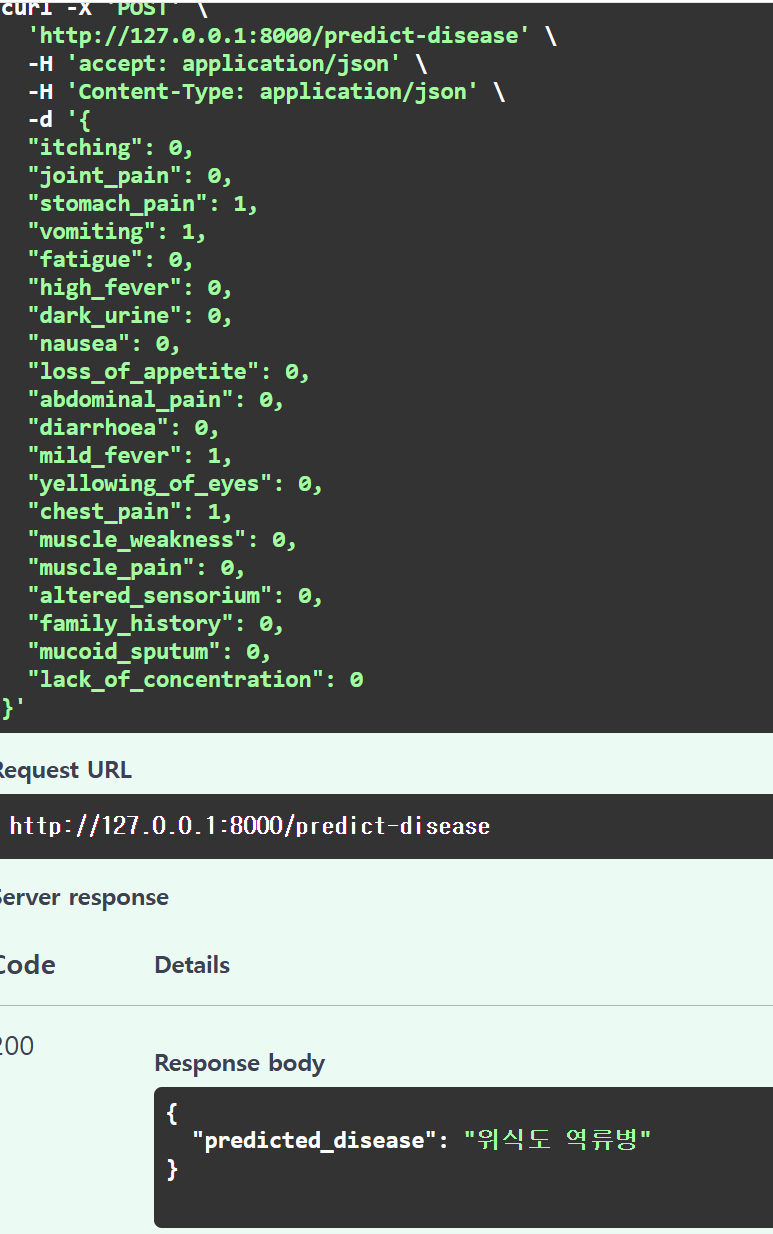
피처 선택 후 전송하고 질병을 예측한 모습을 확인할 수 있다