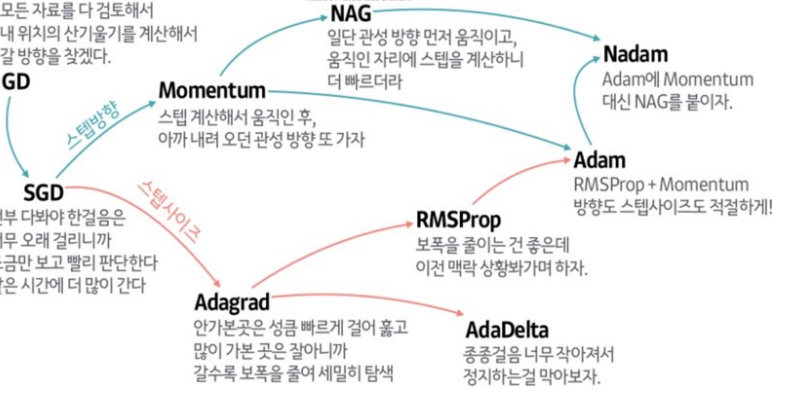
최적화
SGD : 확률적 경사 하강법
확률적 경사하강법(Stochastic Gradient Descent : SGD)은 손실 함수의 곡면에서 경사가 가장 가파른 곳으로 내려가다 보면 언젠가 가장 낮은 지점에 도달한다는 가정 아래에서 동작한다.
SGD : 고정된 학습률
학습률 : 최적화할 때 한 걸음의 폭을 결정하는 스텝 크기를 말하며 학습 속도를 결정한다.
확률적 경사 하강법은 지정된 지정된 학습률을 사용하는 알고리즘이므로 경험적으로 학습률을 조정할 수밖에 없다.
최적화가 어떻게 진행되는지 확인해 봐야 학습률을 어떻게 조정할지 감이 생기지만 감에 의존하는 방식은 최적이 아니므로 효율적이지 않다. 그만큼 최적의 학습률을 정하기란 어려운 일이다.
- 학습률을 조정하지 않으면 무슨 일이 생길까?
학습률이 고정되어 있기 때문에 최적화가 비효율적으로 진행된다.
학습률이 낮으면 학습속도가 느리고 반대로 학습률이 높으면 최적해로 수렴하지 못하거나 심지어는 손실이 점점 커지는 방향으로 발산하기도 한다.
SGD : 학습률 감소
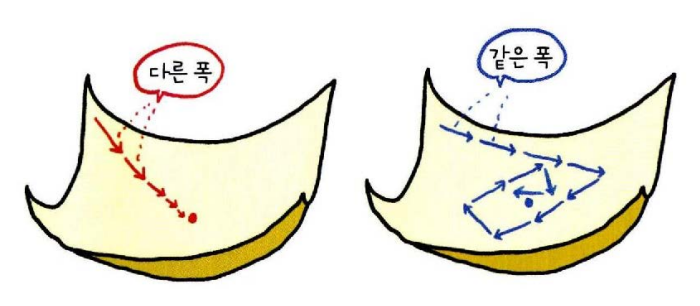
- 왼쪽 그림은 학습률이 잘 조절되어 최적해에 정확하고 빠르게 도달한다. 처음에는 큰 폭으로 이동하다가 최적해에 가까워질수록 이동 폭을 줄여서 안정적으로 수렴한다.
- 오른쪽 그림은 고정된 학습률을 사용하는 경우로 최소 지점 근처에서 진동 최적해에 가까이 갔을 때 남은 거리보다 걸음의 폭이 크기 때문에 최소 지점에 정확히 도달하지 못하며 학습률이 낮아지지 않는 한 최적해에 영원히 도달할 수 없으므로 모델의 성능은 떨어진다.
일반적으로 학습 초기에는 큰 폭으로 이동해서 최대한 빠르게 내려가고 어느정도 내려가면 작은폭으로 천천히 이동해서 최적해에 조심스럽게 접근하는 것이 좋다. 그래서 처음에는 높은 학습률로 학습을 시작하고 학습이 진행되는 상황에 따라 학습률을 조금씩 낮추는데 이런 방식을 학습률 감소(learning rate decay)라고 한다.
SGD : 적응적 학습률
경사가 가파를 때 큰 폭으로 이동하면 최적화 경로를 벗어나거나 최소지점을 지나칠 수 있으므로 적은 폭으로 천천히 이동하는 것이 좋고 경사가 완만하면 큰 폭으로 빠르게 이동하는 것이 좋다. 따라서 곡면의 변화에 따라 학습률이 적응적으로 조정된다면 안정적으로 학습할 수 있다. 이와 같이 학습의 진행 상황이나, 곡면의 변화를 알고리즘 내에서 고려해서 학습률을 자동으로 조정하는 방식을 적응적 학습률(adaptive learning rate)이라고 한다.
SGD : 협곡에서 학습이 안되는 문제
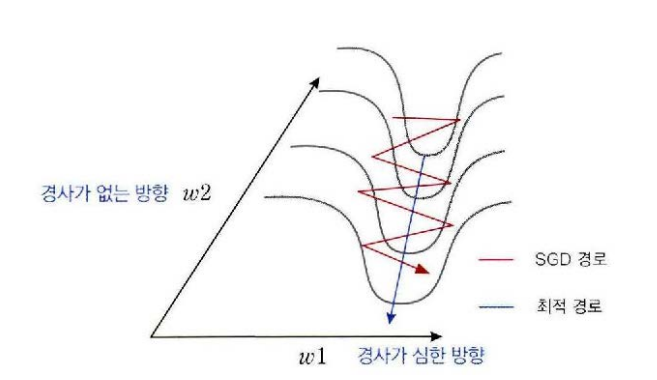
가로 방향으로는 경사가 매우 가파르고 세로 방향으로는 경사가 거의 없는 폭이 좁고 깊은 협곡이 있다고 하자. 확률적 경사 하강법은 이런 지형을 만나면 계곡의 벽면사이를 왔다갔다 하면서 진동만 하고 아래쪽으로는 잘 내려가지 못한다. 결국 최적해가 있는 곳에 도달하지 못하고 정체된 상태로 학습이 종료될 수 있다.
SGD : 안장점에서 학습 종료
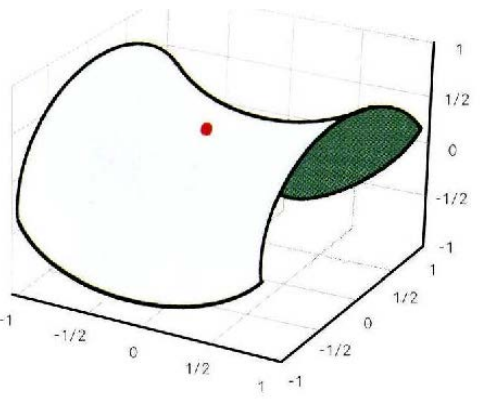
손실 함수 곡면에서 임계점은 미분값이 0인 지점으로 최대점, 최소점, 안장점(saddle point)이 된다. 안장점은 한쪽 축에서 보면 최소인데 다른 축에서 보면 최대인 지점으로 말의 안장과 같이 생겼다고 해서 붙여진 이름이다. 확률적 경사 하강법은 입계점을 만나면 최대점, 최소점, 안장점을 구분하지 못하고 학습을 종료한다. 문제는 손실 함수 곡면에는 안장점이 무수히 많기 때문에 안장점을 만나더라도 학습이 계속 진행될 방법이 필요하다.
SGD : 손실 함수 곡면에는 안장점이 얼마나 많을까?
n차원 공간에서 임계점을 만났을 때 차원별로 최대일 확률이 이고 최소일 확률이 이라고 하자. 입계점이 최소점일 확률은 모든 차원에서 최소이어야 하므로 이고 같은 논리로 지역 최대점일 확률도 이다 나머지 경우는 모두 안장점이기 때문에 임계점이 안장점일 확률은 가 되어 차원이 높아질수록 안장점일 확률은 점점 높아진다.
임계점을 만났을 때 최대점, 최소점, 안장점을 어떻게 구분할까?
임계점에서 손실을 확인해 보면 최대점, 최소점, 안장점을 어느 정도 구분할 수 있다. 손실이 매우 낮다면 최소점일 가능성이 크고 손실이 매우 높다면 최대점일 가능성이 크다. 반면 손실이 수렴했다고 보기에 매우 낮지 않으면 안장점이라고 추정할 수 있다.
손실 함수의 차원이 높을수록 안장점을 쉽게 만날 수 있는 만큼 확률적 경사 하강법이 학습을 중단할 가능성도 커진다. 다행히 안장점은 최대와 최소가 만나는 지점이므로 조금만 움직여도 내리막길이 나타난다. 안장점은 이러한 지형적 특성이 있으므로 진행하던 속도에 관성을 주면 안장점에서 쉽게 탈출할 수 있다.
SGD : 학습 경로의 진동
확률적 경사하강법에서 미니배치 단위로 그래디언트를 근사하면 원래의 손실 함수보다 거친 표면을 갖는 손실 함수를 근사하는 셈이다. 따라서 기울기가 자주 바뀌는 거친 표면에서 이동하므로 최적화 경로가 진동한다.
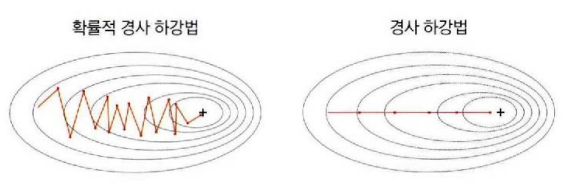
오른쪽 경사 하강법은 그래디언트가 정확하기 대문에 최적해를 향해 곧바로 내려가지만 왼쪽 확률적 경사 하강법은 그래디언트가 부정확하기 때문에 실제 내리막길이 아닌 근사된 내리막길로 가느라 여기저기 둘러서 최적해로 간다. 따라서 최적화경로는 길어지고 수렴 속도는 느려질 수밖에 없다. 최적화 경로가 최적해를 향해 일관성 있게 진행하려면 손실함수의 표면이 거칠더라도 민감하게 경로를 바꾸지 말하야 한다.
SGD 모멘텀
최적해를 향해 진행하던 속도에 관성을 주어 SGD의 느린 학습 속도와 협곡과 안장점을 만났을 때 학습이 안되는 문제 거친 표면에서 진동하는 문제를 해결한 최적화 알고리즘이다.
- SGD가 가장 가파른 곳으로 내려가는 방식이라면 SGD 모멘텀은 지금까지 진행하던 속도에 관성이 작용하도록 만든 방식이다.
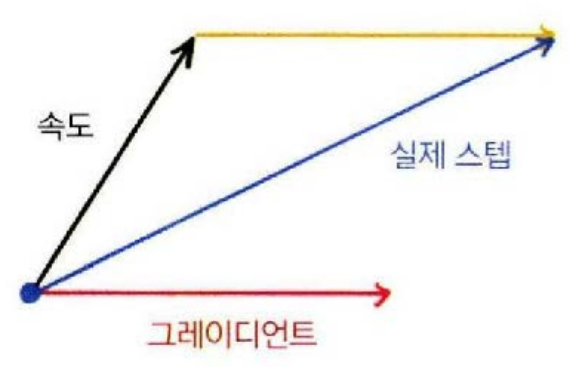
벡터로 표현하면 아래 그림에서 그래디언트 벡터는 현재 위치에서 가장 가파른 방향이고 속도 벡터는 현재 이동하는 속도를 나타낸다. SGD 모멘텀은 현재 속도 벡터와 그래디언트 벡터를 더해서 다음 위치를 정한다.
이렇게 속도에 관성이 작용하면 지금까지 진행하던 방향과 다른방향에 내리막길이 나타나더라도 갑자기 방향을 바꾸지 않고 관성이 작용하면서 학습 경로가 전체적으로 매끄러워지고 가파른 경사를 만나면 가속도가 생겨서 학습이 매우 빨라진다.SGD 모멘텀을 수식으로 표현하면 다음과 같다. 여기서 는 현재 속도이고 는 마찰 계수(friction coefficient)로서 보통 0.9 또는 0.99를 사용한다. 다음속도 은 현재 속도에 마찰 계수를 곱한 뒤 그래디언트를 더해서 계산 파라미터 업데이트 식은 SGD의 파라미터 업데이트 식과 같은 형태이며 그래디언트 대신 속도를 사용한다.
SGD 모멘텀 : 관성을 이용한 임계점 탈출과 빠른 학습
- 진행하던 속도에서 관성이 작용하면 이동 경로가 어떻게 개선되는지 살펴보자.
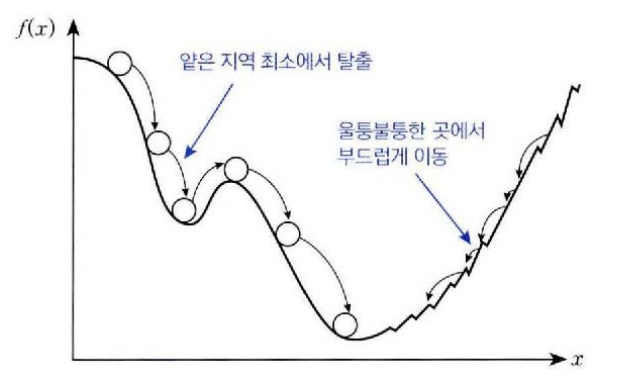
관성이 생기면 진행하던 속도로 계속 진행하려고 하므로 안장점을 만나거나 깊이가 얕은 지역최소에 빠지더라도 그 지점을 벗어날 수 있다.
손실 함수의 표면이 울퉁불퉁하면 기울기가 계속 바뀌기 대문에 다른 족으로 튕겨 나갈 수 있는데 이 때 관성이 작용하면 진행하던 속도를 유지하며 부드럽게 이동할 수 있다. 또한 경사가 가파르면 속도에 그래디언트가 더해져서 가속도가 생기므로 매우 빠르게 이동한다.
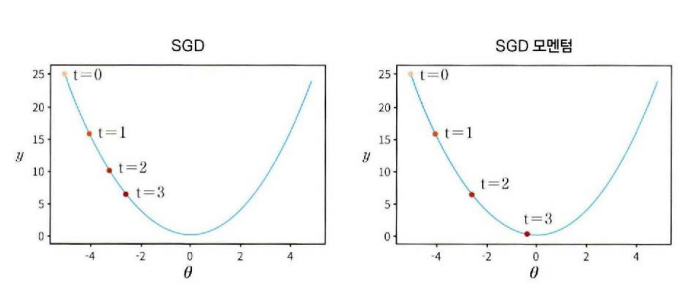
왼쪽은 SGD로 이동했을 때이고 오른쪽은 SGD 모멘텀으로 이동했을 때이다. 두 경우 모두 세 걸음을 이동했지만 SGD는 최소에 도달하지 못했고 sGD 모멘텀은 최소에 도달했다. 경로를 결정할 때 SGD는 기울기만 적용했고 SGD 모멘텀은 기울기에 속도의 관성을 적용했기 때문이다.
SGD 모멘텀 : 오버 슈팅 문제
SGD 모멘텀은 오버 슈팅이 되는 단점이 있다.
경사가 가파르면 빠른 속도로 내려오다가 최소 지점을 만나면 그래디언트는 순간적으로 작아지지만 속도는 여전히 크기 때문에 최소 지점을 지나쳐 오버슈팅이된다.
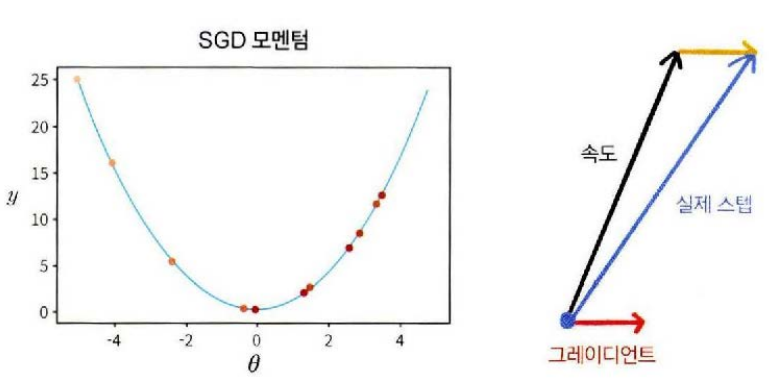
그림의 왼쪽은 최적화 경로가 최소 지점을 지나쳐서 반대편으로 높이 올라간 상황이다. 이를 벡터로 표현하면 다음과 같다. 그래디언트 벡터는 작지만 속도 벡터가 크기 때문에 실제 이동 스텝도 커져서 오버 슈팅이 된다. 최소 지점이 평평한 평지 위에 있다면 그래디언트와 속도가 모두 작으므로 오버슈팅이 되지 않는다. 하지만 최소 지점 주변의 경사가 가파르다면 속도가 크기 때문에 오버 슈팅이 될 수 밖에 없다. 이때 최적해 주변을 평평하게 만들어 주는 정규화 기법을 사용하면 오버 슈팅을 막을 수 있다.
네스테로프 모멘텀
네스테로프 모멘텀(Nesterov momentum)은 진행하던 속도에 관성을 준다는 점은 SGD 모멘텀과 같지만 오버슈팅을 막기 위해 현재 속도로 한걸음 미리 가보고 오버슈팅이 된 만큼 다시 내리막기로 내려가기 때문에 이동방향에 차이가 있다.
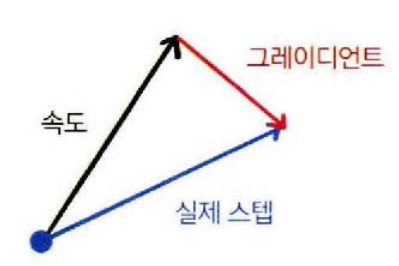
속도 벡터는 현재 이동하는 속도를 나타내고 그래디언트 벡터는 현재 속도로 한걸음 미리 가본 위치에서 내리막길 방향을 의미한다. 네스테로프 모멘텀은 현재 속도 벡터와 현재속도로 한 걸음 미리 가본 위치의 그래디언트 벡터를 더해서 다음위치를 정한다.
네스테로프 모멘텀을 수식으로 표현하면 다음과 같다. 여기서 는 현재 속도이고 는 마찰 계수(friction coefficient)로서 보통 0.9 또는 0.99를 사용한다. 다음 속도 $v_{t+1}은 현재 속도에 마찰 계수를 곱한 뒤 현재 속도로 한 걸음 미리 가 본 위치의 그래디언트를 빼서 계산한다. 파라미터 업데이트 식은 SGD 모멘텀의 파라미터 업데이트를 반대 방향을 하는 식으로 표현되었다.
네스테로프 모멘텀 : 오버슈팅 억제
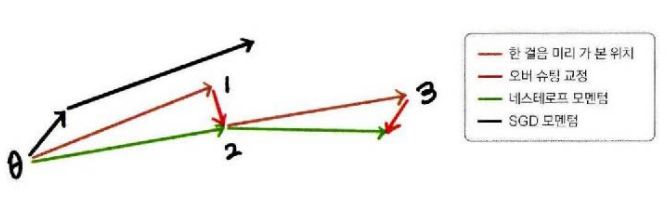
검정색은 SGD 모멘텀으로 두번 이동한 경로이고
녹색은 네스테로프 모멘텀으로 두번 이동한 경로이다. 갈색과 빨간색이 더해져서 계산되며 갈색은 현재 속도로 한걸음 미리 가 본 위치이고 빨간색은 갈색 지점에서 그래디언트로 이동한 위치로 오버슈팅을 교정한다. 이런 방식으로 네스테로프 모멘텀은 관성이 커지더라도 오버 슈팅이 될지 미리 살펴보고 교정하기 때문에 오버슈팅이 억제된다.
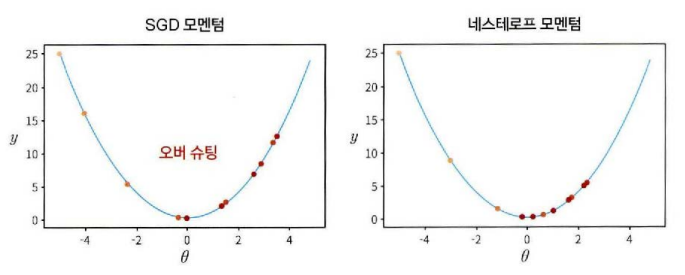
SGD 모멘텀은 최소 지점을 지나쳐서 오버 슈팅이 되지만 네스테로프 모멘텀은 최소 지점을 조금만 지나쳐서 오버슈팅을 억제하고 있음을 알 수 있다.
AdaGrad
AdaGrad(adaptive gradient)는 손실 함수의 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘이다.
손실 함수의 경사가 가파를 때 큰 폭으로 이동하면 최적화 경로를 벗어나거나 최소 지점을 지나칠 수 있으므로 작은폭으로 이동하는 것이 좋고, 경사가 완만하면 큰 폭으로 빠르게 이동하는 것이 좋다. 그러려면 곡면의 변화량에 학습률이 적응적으로 조정되어야 한다.
AdaGrad : 곡면의 변화량은 어떻게 계산할까?
곡면의 변화가 크다는 것은 기울기의 변화가 크다는 의미이므로 모든 단계에서 계산했던 기울기를 모아서 크기를 측정해보면 된다. 먼저 모든 단계의 기울기를 하나의 벡터로 표현해보자.
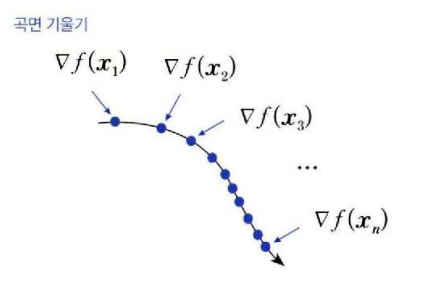
각 기울기의 제곱합을 계산해서 곡면의 변화량으로 사용할 수 있다.
SGD의 파라미터 업데이트 식에서 학습률 를 곡면의 변화량의 제곱근 로 나눠주면 적응적 학습률이 된다.
적응적 학습률은 곡면의 변화량에 반비례 하므로 곡면의 변화가 크면 천천히 학습하고 곡면에 변화가 작으면 빠르게 학습한다.
적응적 학습률이 반영된 파라미터 업데이트 식으로 그래디언트의 제곱을 누적하는 식과 파라미터 업데이트식으로 정의된다. 은 분모가 0이 되지 않게 더해주는 아주 작은 상수로 보통 1e-7이나 1e-8을 사용한다.
AdaGrad는 모델의 파라미터별로 곡면의 변화량을 계산하기 때문에 파라미터별로 개별 학습률을 갖는 효과가 생긴다.
손실 함수에서 파림터의 차원별로 곡면의 변화량이 다를 수 있기 때문에 파라미터별로 개별 학습률을 가지면 좀 더 정확하고 빠르게 최적해로 수렴할 수 있다.
AdaGrad : 학습 초반에 학습이 중단되는 현상
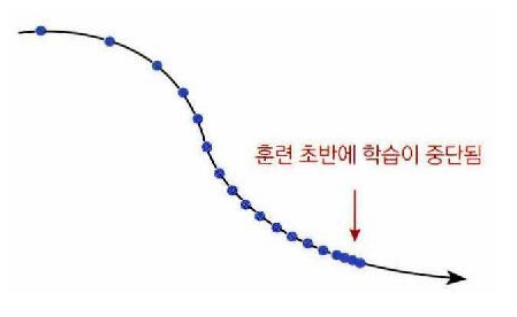
- 곡면의 변화량을 전체 경로의 기울기 벡터의 크기로 계산하므로 학습이 진행될수록 곡면의 변화량은 점점 커지고 반대로 적응적 학습률은 점점 낮아진다는 점이다. 만일 경사가 매우 가파른 위치에서 학습을 시작한다면 초반부터 적응적 학습률이 급격히 감소하기 시작해서 조기에 학습이 중단될 수 있다.
이처럼 조기에 학습이 중단되는 문제를 해결하기 위해 RMSProp이 제안되었다.
RMSProp
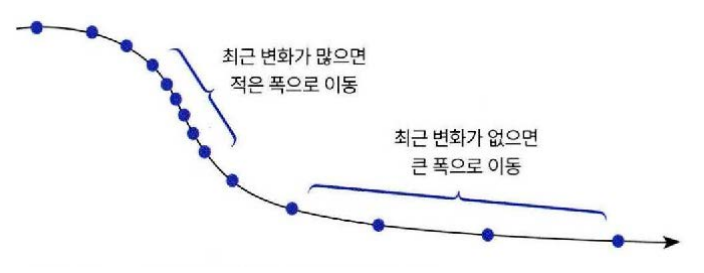
RMSProp(root mean square propagation)은 최근 경로의 곡면 변화량에 따라 학습률을 적응적으로 결정하는 알고리즘이다. 곡면 변화량을 측정할 때 전체 경로가 아닌 최근 경로의 변화량을 측정하면 곡면 변화량이 누적되어 계속 증가하는 현상을 없앨 수 있다.
을 계산할 때 와 그래디언트의 제곱 을 가중 합산해서 지수가중이동평균을 계산했다. 여기서 는 가중치로 보통 0.9를 사용하며 은 분모가 0이 되지 않게 더해주는 아주 작은 상수로 보통 1e-7이나 1e-8을 사용한다.
Adam
Adam(adaptive moemnt estimation)은 SGD 모멘텀과 RMSProp이 결합된 형태로 진행하던 속도에 관성을 주고 동시에 최근 경로의 곡면의 변화량에 따라 적응적 학습률을 갖는 알고리즘이다.
Adam은 관성에 대한 장점과 적응적 학습률에 대한 장점을 모두 갖는 전략을 취해 최적화 성능이 우수하고 잡음 데이터에 대해 민감하게 반응하지 않는 성질이 있다. 또한 두 알고리즘을 합치면서 학습 초기 경로가 편향된디는 RMSProp의 문제를 제거 했다.
첫 번째 식은 1차 관성으로써 속도를 계산한다. SGD 모멘텀의 첫 번째 식에 해당하는데 속도에 마찰계수 대신 가중치 을 곱해서 그레디언트의 지수가중이동평균을 구하는 형태로 수정되었다.
두 번째 식은 2차 관성으로써 그레디언트 제곱의 지수가중이동평균을 구하는 식이다. RMSProp의 첫 번째 식과 동일하다.
세 번째 식은 파라미터 업데이트 식으로 1차 관성과 2차 관성을 사용한다.
Summary