Introduction
기존 NLP 모델들의 한계
기존의 NLP 모델들(RNN, LSTM, LSTM, GRU)은 주로 seq2seq 구조를 기반으로 설계되어 다음과 같은 한계점이 있다.
-
장기 의존성 문제
RNN과 같은 순차적 모델들은 입력 시퀀스의 길이가 길어질수록 초반 입력 정보가 뒤로 갈수록 희미해지는 문제 발생 따라서 문장 내에서 멀리 떨어진 단어들 간의 관계를 제대로 이해하지 못하게 된다. -
단방향 처리
입력 시퀀스를 순차적으로 처리하면서 단방향 정보만을 사용해 문장을 왼쪽에서 오른쪽으로 읽으며 학습하는 경우 단어의 오른쪽 문맥 정보는 반영되지 않는 문제가 있다. -
병렬 처리의 어려움
RNN 기반 모델들은 순차적으로 데이터를 처리해야 하므로 병렬처리에 한계가 있어 대규모 데이터를 학습 시 속도 저하 문제가 발생한다. -
제한된 표현력
단어의 의미를 고정된 벡터로 표현하는 Word2Vec이나 GloVE 같은 임베딩 기법들은 단어의 문맥적 의미를 반영하지 못해 동일한 단어가 다른 문맥에서 다르게 해석될 수 있는 문제를 해결하지 못한다.
BERT의 등장 배경
BERT는 기존 모델들의 한계를 극복하기 위해 개발되어 다음과 같은 배경을 바탕으로 등장한다.
-
트랜스포머 모델의 도입
2017년 Vaswani et al.이 발표한 트랜스포머 모델은 자체 어텐션 메커니즘을 활용하여 시퀀스 내 모든 위치의 단어들 간의 관계를 동시에 고려할 수 있게 만들어 장기 의존성 문제를 해결하고 병렬 처리가 가능하게 했다. -
양방향 학습의 필요성
문장 내에서 단어의 의미는 문맥에 따라 달라져 양방향 정보를 활용하여 단어의 의미를 학습하는 것이 중요해 BERT는 트랜스포머 인코더를 이용하여 문자의 양방향 정보를 동시에 학습한다. -
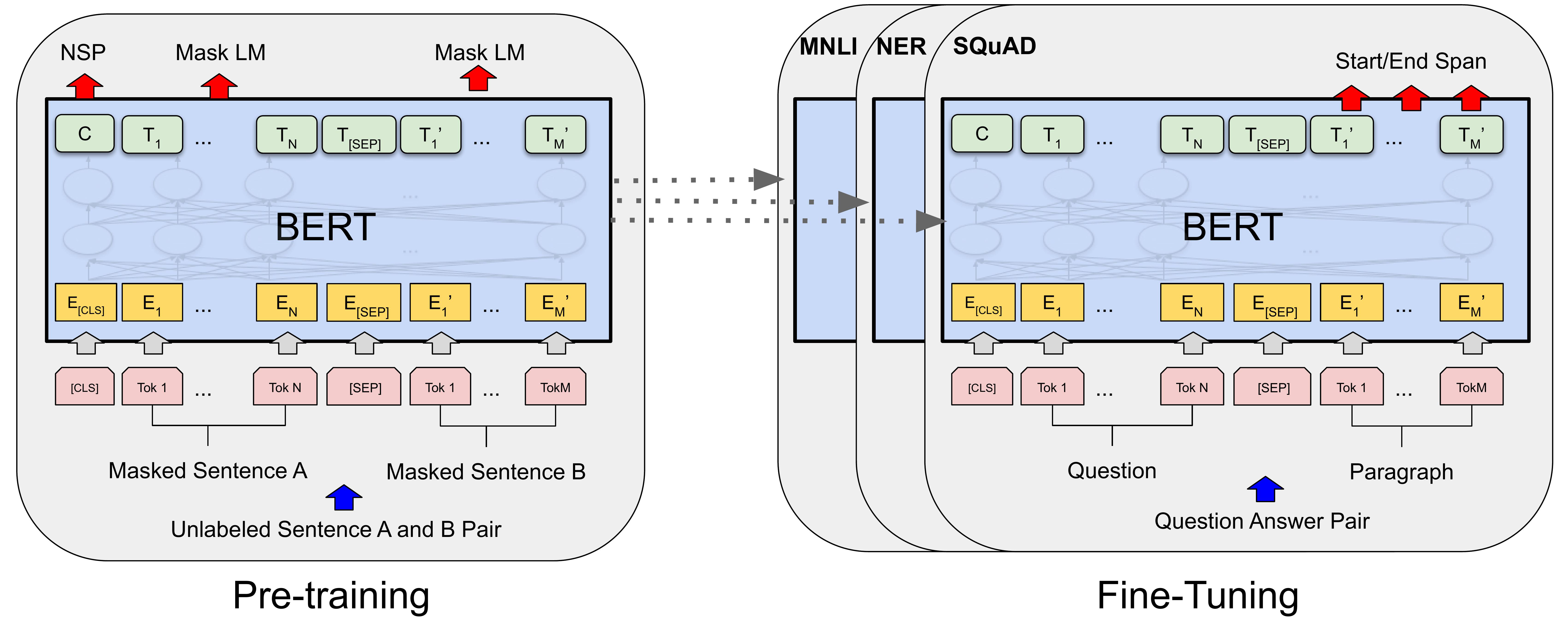
pre-training과 fine-tuning
대규모 텍스트 코퍼스를 사용하여 일반적인 언어 이해를 위한 pre-training을 수행하고 이후 특정 NLP task에 따른 fine-tuning을 수행해 다양한 task에서 높은 성능을 발휘할 수 있다. -
새로운 언어 모델링 기법
기존의 언어 모델링 기법과 달리 마스킹 언어 모데레과 다음 문장 예측을 사용하여 더 효과적으로 언어의 문맥적 의미를 학습한다.
BERT 모델 아키텍처
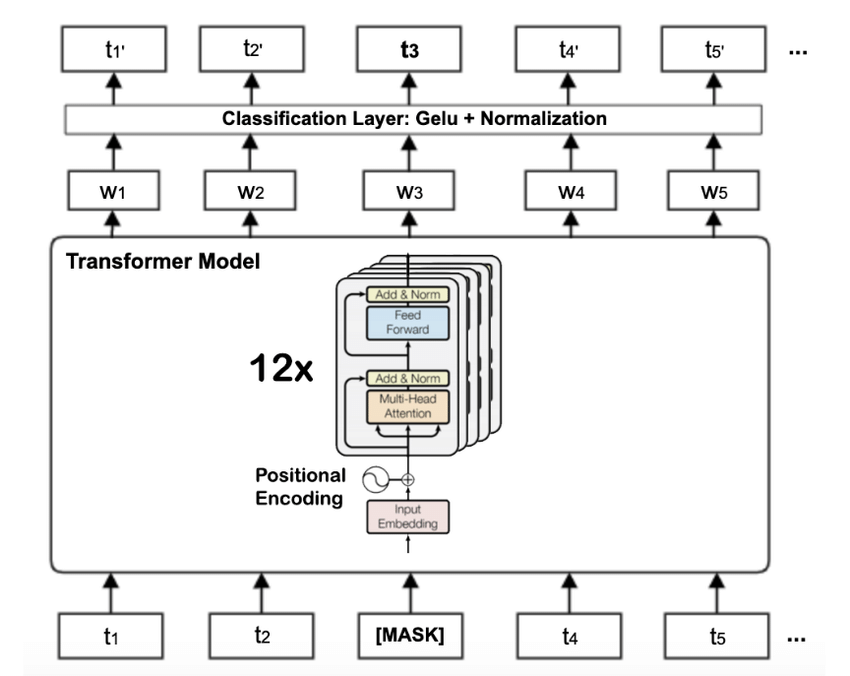
트랜스포머 인코더의 구조
BERT는 트랜스포머의 인코더 부분만을 사용하여 다음과 같은 구조를 가진다.
- Input Embedding
입력 문장은 단어 토큰으로 분할되고 각 토큰은 고차원 벡터로 변환된다. BERT는 단어 임베딩, 위치 임베딩, 세그먼트 임베딩을 결합하여 입력 벡터를 구성한다.
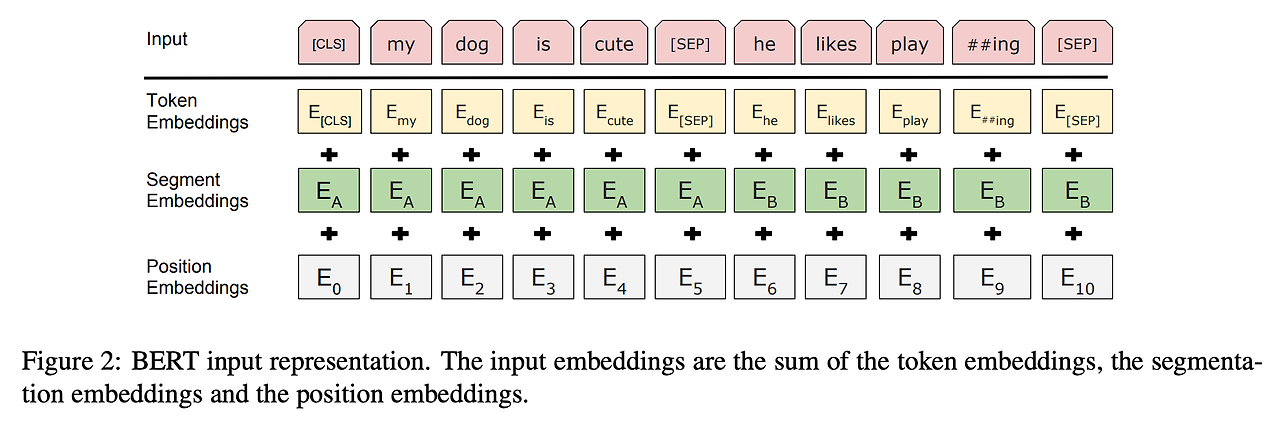
- 토큰 임베딩 : 문장을 단어의 의미 단위로 끊어서 임베딩한 결과
- 세그먼트 임베딩 : 문장 별 인덱스. BERT 는 2개의 문장도 입력으로 받을 수 있기 때문에 이를 구별하기 위함
- 포지션 임베딩 : 토큰별(단어별) 상대적 위치. 0~1 사이 값으로 문장 하나가 길더라도 모두 커버할 수 있게
- [CLS] : 분류 테스크를 위한 토근으로 문장 전체가 임베딩된 스페셜 토큰
- [SEP] : 두 문장을 입력으로 받는 경우 이 토큰을 기준으로 두 문장을 구분
-
Attention Mechanism
각 던어는 Query, Key, Value 벡터로 변환되고 Query는 모든 Key와 dot-product 하여 Attention Score를 계산한다. 이 Score는 softmax를 통해 정규화되고 값 벡터들과 weighted sum 하여 최종 출력 벡터를 생성한다. -
Multi-Head Attention
여러개의 Attention Head를 사용하여 다양한 Attention Score를 동시에 계산한다. 각 헤드는 다른 Query, Key, Value 벡터 집합을 사용하여 Attention Score를 생성하고 최종 출력을 위해 결합한다. -
Position-Wise Feed-Forward Network
Attention Layer의 출력은 Position-Wise Feed-Forward Network를 통과한다. 이는 각 위치별로 독립적인 Fully Connected Neural Network를 적용하는 것이다. -
Layer Normalization and Dropout
각 Attention Layer와 Feed Forawrd Network Layer 뒤에 Layer Normalization과 Dropout이 적용되어 모델의 일반화 성능을 향상시킨다.
양방향 학습의 중요성
-
문맥적 의미 이해
단어의 의미는 문맥에 따라 달라질 수 있어 양방향 학습을 통해 BERT는 문장의 앞뒤 문맥을 모두 고려하여 각 단어의 의미를 더 정확하게 이해할 수 있다. -
풍부한 표현력
단방향 모델들은 입력 시퀀스를 순차적으로 처리하며 문장의 한쪽 방향만을 고려하지만 양방향 모델은 전체 문장을 동시에 처리하여 더 풍부한 표현력을 제공한다. -
상황에 따른 다의어 처리
동일한 단어가 다른 문맥에서 다르게 사용될 때 양방향 학습은 해당 단어의 상황에 맞는 의미를 더 잘 파악할 수 있다. 예를들어 bank가 river bank와 financial bank에서 다르게 해석되는 것을 지원한다.
Pre-training 기법
마스킹 언어 모델 (MLM)
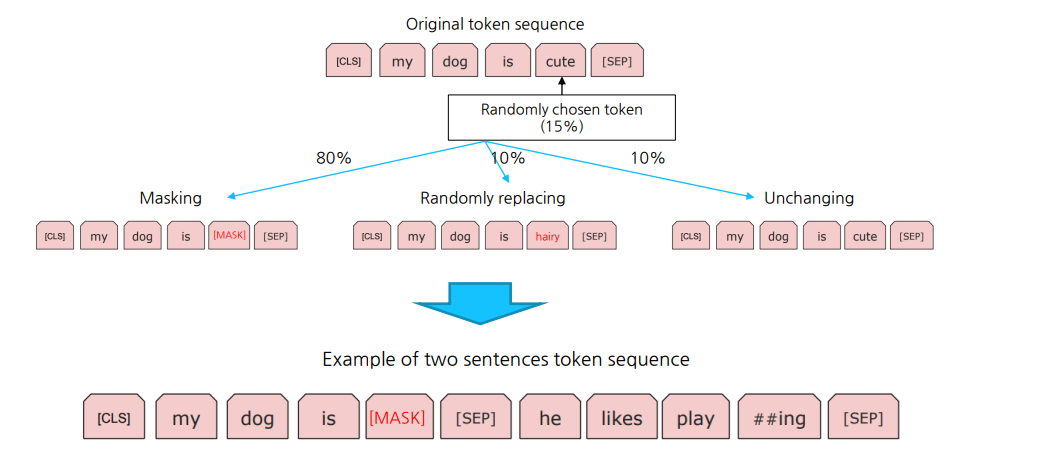
마스킹 언어 모델은 입력 시퀀스의 일부 단어를 마스킹 하고 모델이 마스킹된 단어들을 예측하도록 학습하는 방법이다.
-
입력 토큰 마스킹
입력 시퀀스의 15%의 토큰을 무작위로 선택하여 마스킹한다.
마스킹된 토큰 중 80%는 [MASK] 토큰으로 대체되며 10%는 무작위 다른 토큰으로 대체되고 나머지 10%는 원래 토큰을 유지한다. 이는 모델이 마스킹된 위치의 실제 단어를 예측하는 성능을 강화하기 위한 것이다. -
손실 함수
모델은 예측된 단어와 실제 마스킹된 단어간의 Cross-Entropy loss를 최소화하도록 학습된다.
다음 문장 예측 (NSP)
NSP는 모델이 문장 간의 관계를 이해할 수 있도록 돕는다.
-
문장 쌍 생성
사전 훈련 데이터에서 두 개의 문장을 쌍으로 선택한다. 50%의 확률로 두 번째 문장은 실제로 첫 번째 문장 다음에 오는 문장이고 나머지 50%는 무작위로 선택된 문장이다. -
입력 형식
두 개의 문장은 [CLS] 토큰으로 시작하고 [SEP] 토큰으로 분리된다. -
목표
두 번째 문장이 첫 번째 문장 다음에 실제로 오는 문장인지 아닌지를 예측하는 것이다. -
손실 함수
예측된 문장 관계와 실제 관계간의 Cross-Entropy Loss를 최소화 하도록 학습된다.
Pre-train 데이터와 과정
-
데이터셋
BookCorpus(8억 단어)와 영어 Wikipedia(25억 단어)로 구성된 대규모 텍스트 데이터 셋을 사용하여 Pre-trained 되었고 이 데이터셋은 다양한 주제와 스타일의 텍스트를 포함하여 모델이 광범위한 언어를 학습할 수 있도록 한다. -
Pre-train 과정
첫 번째 단계에서는 마스킹 언어 모델(MLM)을 통해 단어 수준의 문맥 정보를 학습하고 두 번째 단계에서는 다음 문장 예측(NSP)을 통해 문장 간의 관계를 학습한다.
BERT의 한계와 개선점
BERT의 한계
-
높은 계산 비용과 메모리 요구사항
BERT는 대규모 트랜스포머 인코더를 사용하기 때문에 훈련과 추론 과정에서 상당한 계산 자원과 메모리가 필요해 자원이 제한된 환경에서 실용적이지 않을 수 있다. -
훈련 시간
BERT를 pre-train할 때 많은 시간과 데이터가 필요하다. -
고정된 입력 길이
BERT는 입력 시퀀스 길이가 고정되어 있어 더 긴 문서나 텍스트를 처리하는 데 어려움이 발생할 수 있다. 길이 제한으로 인해 중요한 정보가 잘릴 수 있다. -
문장 수준의 정보 부족
BERT는 주로 문장 내 단어 수준의 문맥 정보를 학습하는 데 초점을 맞추고 있어 문장 간의 상호작용을 깊이 있게 처리하는 데 한계가 있다. 이는 문서 수준의 이해나 더 긴 맥락을 필요로 하는 작업에서 성능 저하가 발생할 수 있다.
이후 연구와 모델 변형 (RoBERTa, ALBERT, DistilBERT)
RoBERTa (Robustly Optimized BERT Approach)
RoBERTa는 Facebook AI에 의해 개발된 BERT의 변형 모델로 BERT의 pre-train 과정을 최적화하여 성능을 향상시켰다.
주요 개선점
- 더 큰 배치 크기와 더 긴 훈련 시간 사용
- NSP(Next Sentence Prediction) 작업 제거
- 더 많은 데이터셋 사용
- 동적 마스킹(dynamic masking) 기법 도입
RoBERTa는 GLUE, RACE, SQuAD 등 다양한 벤치마크에서 BERT를 능가하는 성능을 보여준다.
ALBERT (A Lite BERT)
ALBERT는 Google Research에서 개발된 BERT의 경량화 모델로 파라미터 수를 줄이고 훈련 속도를 높이는 데 중점을 두었다.
주요 개선점
- 파라미터 공유(Parameter-sharing) 기법 사용 : 모든 레이어에서 파라미터를 공유하여 모델 크기 감소
- 팩터라이즈드 임베딩(factorized embedding) 기법 도입 : 임베딩 매트릭스의 크기를 줄여 계산 효율성 향상
- NSP 작업을 SOP(Sentence Order Prediction) 작업으로 대체 : 두 문장의 순서 예측 작업으로 변경하여 더 효과적인 문장 간 관계 학습
- ALBERT는 BERT와 유사한 성능을 유지하면서도 계산 자원 요구량을 크게 줄였다.
DistilBERT
DistilBERT는 Hugging Face에서 개발한 BERT의 경량화 모델로 BERT의 작은 버전임에도 성능 저하를 최소화하였다.
주요 개선점
- 지식 증류(knowledge distillation) 기법 사용 : 큰 모델(BERT)의 지식을 작은 모델로 전이하여 경량화
- layer 수 감소 : BERT-Base의 절반인 6개의 층 사용
- 훈련 속도 향상 : BERT보다 약 60% 더 빠르, 메모리 사용량이 절반으로 줄어듦
- DistilBERT는 모바일 및 임베디드 환경과 같은 자원이 제한된 환경에서 사용하기 적합 하다.
