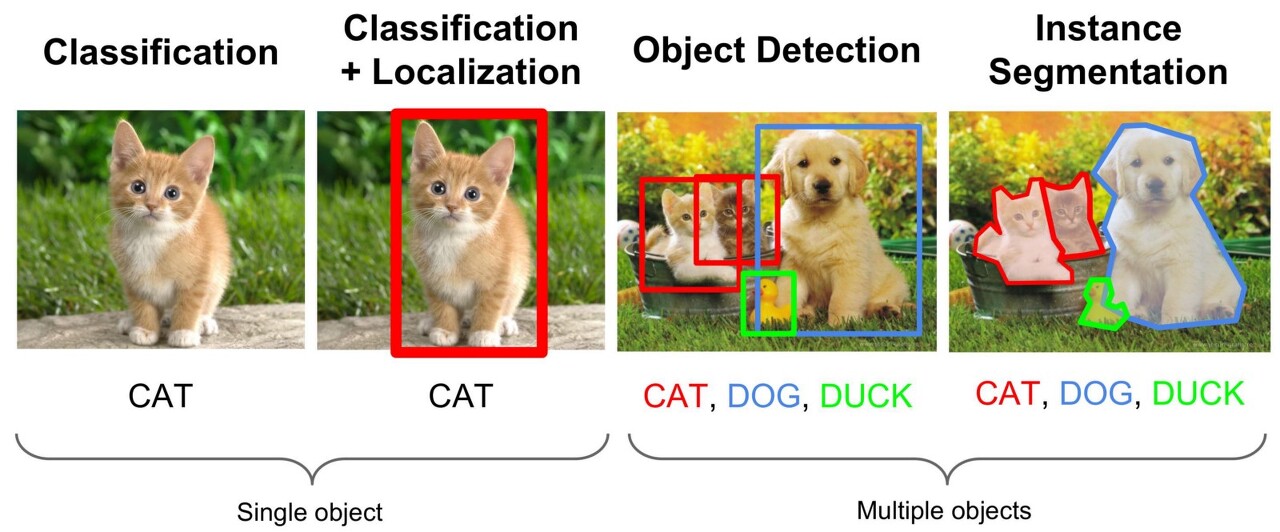
Object Detection과 Segmentation
Classfication
- 딥러닝에서 Classfication은 이미지 안의 주요 객체를 식별하고, 그 객체가 어떤 클래스에 속하는지를 결정하는 과정으로 전체 이미지가 하나의 레이블로 분류되는 작업이며, 주로 CNN(Convolutional Neural Network)과 같은 모델을 사용한다. 예를 들어 위 이미지의 사진 속 고양이가 있는지 없는지 여부를 판단하는 것이 Classfication 작업에 해당한다.
Localization
- Localization은 이미지 내의 특정 객체가 어디에 위치해 있는지를 찾는 과정으로 객체의 Bounding Box를 통해 위치를 표현해 객체의 분류와 위치를 함께 제공한다. 예를 들어 위 사진의 고양이의 위치를 알려주는 것이 Localization의 예시로 분류 모델에 위치 추정기능을 추가한 모델들이 이 작업에 사용된다.
Object Detection
- Object Detection은 이미지 내에 존재하는 여러 객체를 식별하고, 그 위치를 찾는 과정으로 다수의 객체가 있는 경우 각각에 대한 분류와 위치 정보(Bounding Box)를 제공하고 이는 단일 객체 뿐만 아니라 여러 객체의 정보를 동시에 처리할 수 있어야한다. 예를 들어 위 사진의 사진 속에 있는 고양이와 개를 모두 식별하고 각각의 위치를 찾는 것이 Object Detection의 예로 R-CNN, YOLO, SSD. 등 다양한 고급 모델이 이 분야에서 사용된다.
Instance Segmentation
- Instance Segmentation으 객체 검출을 한 단계 더 발전시켜 각 객체의 정확한 형태와 경계를 픽셀 수준에서 구분하는 과정이다. 이 방법은 각 객체의 모양과 경계를 훨씬 더 정밀하게 표현하며, 단순한 경계 상자보다 훨씬 자세한 정보를 제공한다. Instance Segmentation은 특히 복잡한 장면에서 개별 객체를 정밀하게 이해하는 데 유용해 Mask R-CNN과 같은 모델이 이 분야에서 주로 사용된다.
Object Detection의 주요 구성 요소
Object Detection은 컴퓨터 비전 분야에서 광범위하게 연구되고 있으며 다양한 실생활 응용에 사용된다. 이 분야는 복잡한 시스템을 필요로 하며 몇 가지 주요 구성 요소로 나눌 수 있다.
1. 영역 추정(Region Proposal)

객체 검출 과정에서 가장 먼저 수행되는 단계는 영역 추정이다. 이 과정에서는 이미지 내에서 객체가 존재할 가능성이 있는 영역들을 식별하며 이를 위해 R-CNN과 같은 알고리즘에서는 'Selective Search'와 같은 방법을 사용하여 잠재적인 객체 후보 영역들을 생성한다. 이렇게 추출된 영역들은 이후의 과정에서 더 정밀한 분석을 위해 사용된다.
2. 딥러닝 네트워크 구성
객체 검출을 위한 딥러닝 네트워크 구성은 크게 세 부분으로 나눌 수 있다.
-
Feature Extraction
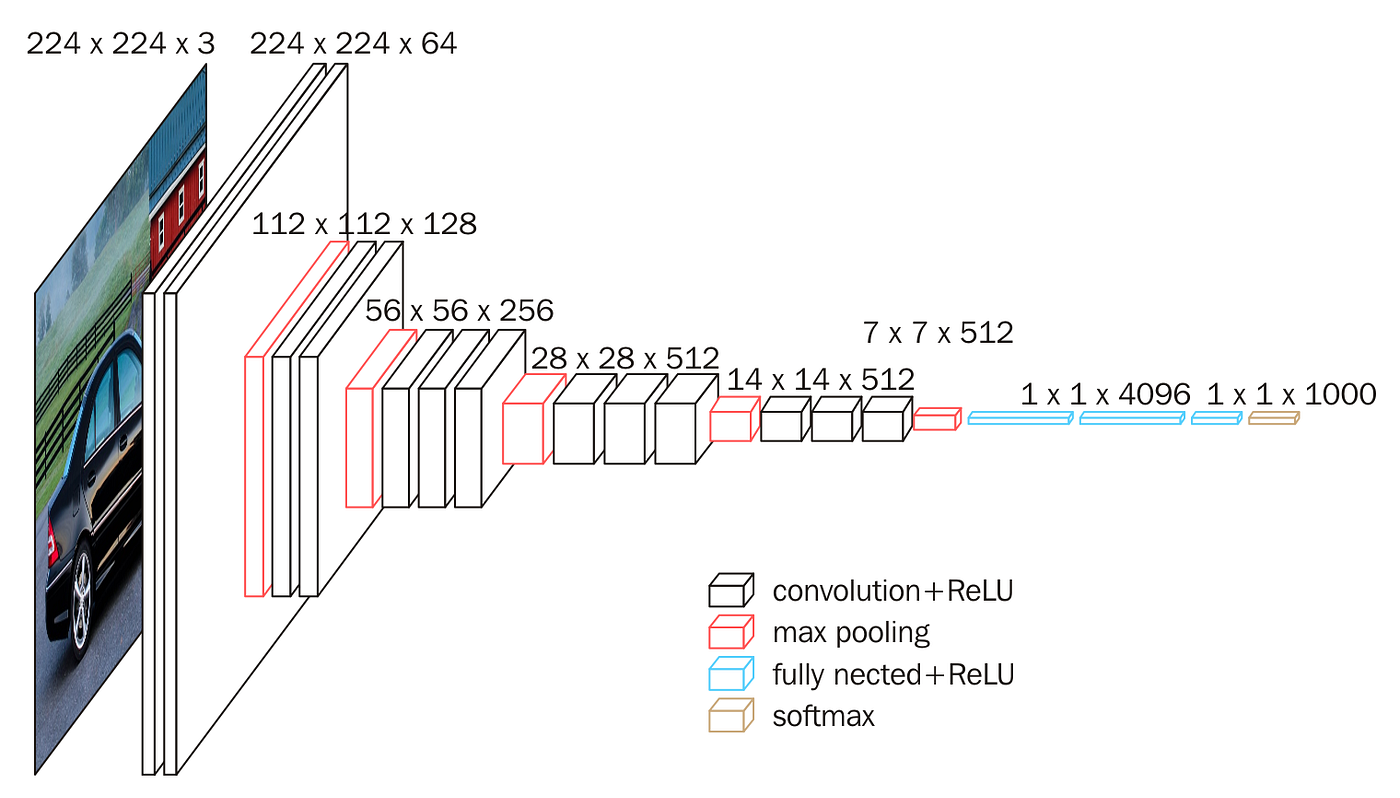
이 단계에서는 이미지로부터 중요한 특성을 추출한다. CNN이 이 역할을 주로 수행하며 이미지의 원시 픽셀 데이터에서 고수준의 특징을 추출하는데 중요하다. -
FPN
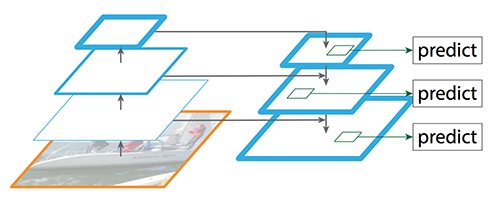
FPN은 다양한 크기의 객체를 효과적으로 검출하기 위해 사용된다. 여러 레벨의 특성 맵을 생성하여 객체의 크기 변화에 강인한 특성을 학습할 수 있도록 도와준다. -
Network Prediction
추출된 특성을 바탕으로 객체의 클래스와 위치(Bounding Box)를 예측한다.
3. Detction을 구성하는 기타요소
- IOU(Intersection Over Union)
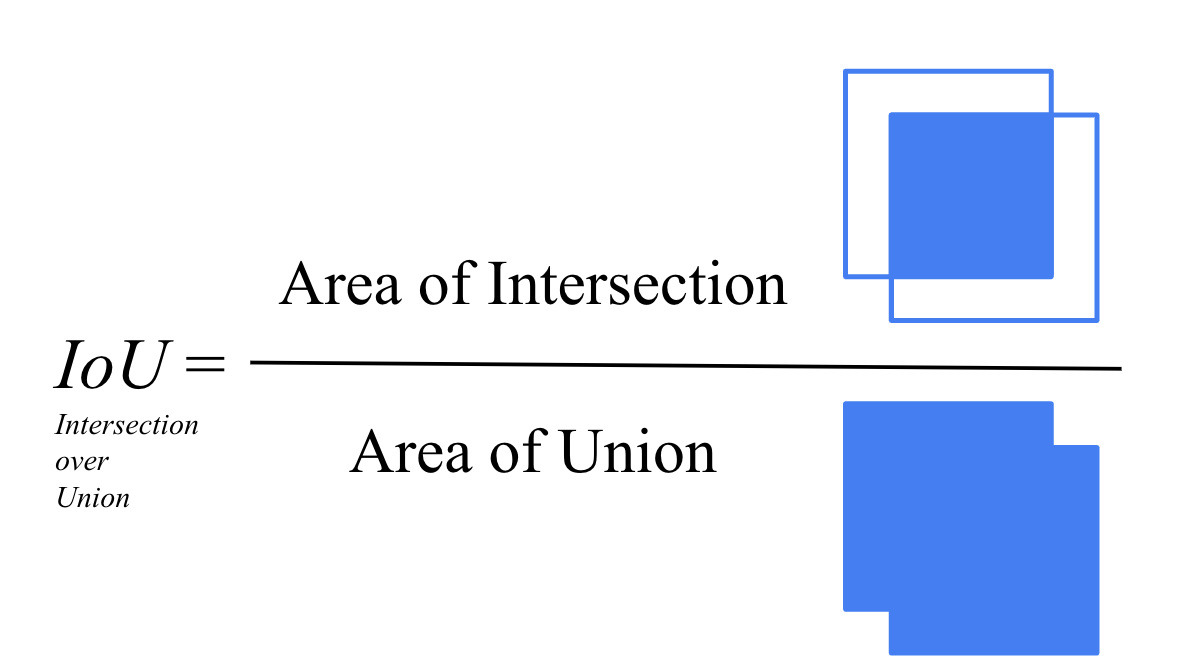
IOU는 예측된 Bounding Box와 실제 객체의 Bounding Box 간의 정확성을 측정하는 지표로 두 Box간의 교집합 영역을 합집합 영역으로 나눈 값으로 계산된다.
-
NMS(Non-Maximum Suppression)
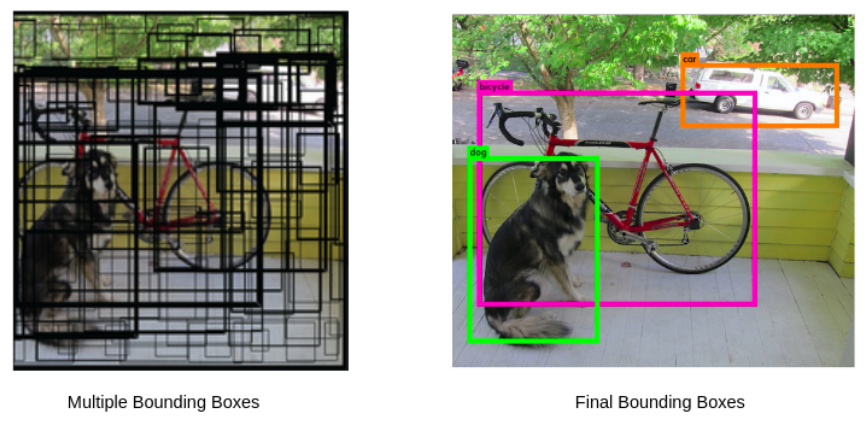
NMS는 여러 겹쳐진 Bounding Box 중에서 가장 정확한 것을 선택하는 과정으로 이를 통해 중복된 검출을 줄이고 더 정확한 검출 결과를 얻을 수 있다. -
mAP(Mean Average Precision)
mAP는 객체 검출 모델의 전체적인 성능을 평가하는 지표로 다양한 임계값에서의 Average Precision을 계산하여 모델의 정확성을 측정한다. -
Anchor Box
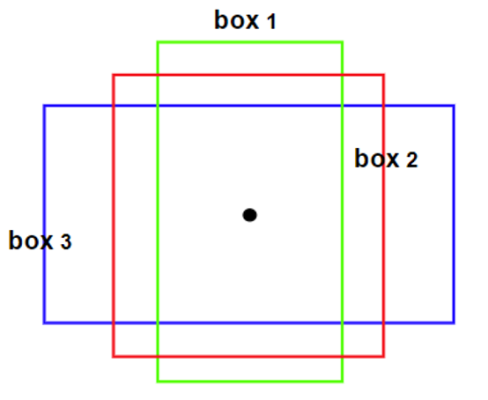
Anchor Box는 미리 정의된 다양한 크기와 비율의 상자들을 사용하여 객체의 위치를 더 잘 예측하는 데 도움을 준다. YOLO나 SSD와 같은 알고리즘에서 사용된다.
Object Detection의 난제
1. Classification + Regression을 동시에 수행해야 한다.
- Classification : 이미지 내의 각 객체가 어떤 클래스에 속하는지를 결정
- Regression : 객체의 정확한 위치를 결정하는 과정으로 보통 Bounding Box의 형태로 표현된다.
이 두 작업을 동시에 수행하는 것은 매우 복잡한 과제로 분류와 회귀 각각에 최적화된 네트워크를 구축하고 이를 효과적을 결합하는 것이 중요하다.
2. 다양한 크기와 유형의 객체가 섞여 있다.
실제 세계의 이미지는 다양한 크기와 유형의 객체들로 가득 차 있다.
- 다양한 크기 : 작은 객체부터 큰 객체까지 다양한 크기의 객체를 효과적으로 Detect해야한다.
- 다양한 유형 : 다양한 형태와 특징을 가진 객체들을 정확하게 식별할 수 있어야한다.
모든 크기와 유형의 객체에 대해 동일한 정확도로 Detect하는 것은 매우 어렵다. 이를 위해 다양한 스케일의 특성을 추출하고 처리할 수 있는 고급 알고리즘이 필요하다.
3. 검출 시간
- 실시간 처리 필요성 : 많은 응용 분야에서는 거의 실시간으로 객체를 검출할 필요가 있다. 예를 들어 자율 주행 차량이나 보안 시스템에서는 빠른 응답 시간이 필수적이다.
높은 정확도를 유지하면서도 빠른 Detect 속도를 달성하는 것은 큰 도전이다. 이를 위해 경량화된 네트워크 디자인과 효율적인 계산 방법이 필요하다.
4. 명확하지 않은 이미지
- 이미지 품질 : 흐릿함, 낮은 해상도, 불충분한 조명과 같은 요소들이 이미지 품질에 영향을 미친다.
실제 환경에서 촬영된 이미지는 종종 불명확하거나 품질이 낮을 수 있다. 품질이 낮은 이미지에서도 정확한 Object Detection을 위해서는 강한 특성 추출 방법과 향상된 알고리즘이 필요하다.
5. 데이터 세트의 부족
- 풍부한 데이터 필요성 : 정확한 모델을 구축하기 위해서는 다양한 시나리오를 포함하는 방대한 양의 데이터가 필요하다.
객체 검출 모델의 훈련과 검증을 위해서는 대규모의 다양한 데이터 세트가 필요하다. 고품질의 주석이 달린 데이터를 충분히 확보하는 것은 시간과 비용이 많이 든다. 또한 데이터의 다양성을 확보하는 것도 중요한 과제이다.
Sliding window
이 방식은 Object Detection 에서 이미지 상에 객체를 탐지하기 위해 일정한 크기의 Window를 이미지 전체에 걸쳐 이동시키면서 객체를 검출하는 방식이다. 초기에는 Object Detection의 기법으로 활용되었으나 성능이 낮고 비용이 많이 들어 최근에는 Region proposal 기법을 더 많이 활용한다.
다양한 형태의 window를 사용하는 방식
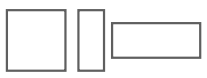
window의 크기와 형태를 다양화 함으로써 다양한 크기와 비율의 객체를 검출할 수 있다. 예를들어 작은 window는 작은 객체를, 큰 window는 큰 객체를 탐지하는데 사용된다. 따라서 다양한 크기의 개체에 대해 유연하게 대응할 수 있지만 모든 가능한 위치와 크기에 대해 윈도우를 이동시켜야 하기 때문에 시간과 자원이 많이 소모되어 계산 비용이 매우 높다.
window크기를 고정하고 이미지 스케일을 변경하는 방식

이미지의 크기를 다양하게 조절함으로써 동일한 크기의 window로 다양한 크기의 객체를 탐지할 수 있다. 예를들어 이미지를 축소하면 큰 window 가 상대적으로 더 작은 객체를 탐지할 수 있게 된다. 다양한 크기의 객체를 검출할 수 있으면서도 window 크기를 변경하는 것보다 계산비용이 적게들지만 이미지의 크기를 변경하는 과정에서 세부 정보가 손실될 수 있으며 이는 검출 정확도에 영향을 줄 수 있다.
Region Proposal
Region Proposal 방식은 매우 중요한 개념으로 특히 Selective Search는 Region Proposal의 대표적인 예시로 고전적인 컴퓨터 비전 기법과 최신 딥러닝 기법을 결합하여 사용된다.
Region Proposal 방식

Region Poroposal은 이미지 내에서 객체가 있을법한 영역을 제안하는 과정으로 전첸 이미지를 무작위로 스캔하는 대신 객체가 존재할 가능성이 높은 특정 영역에 초점을 맞춘다. 이를 통해 계산 효율성을 높이고 Detection 정확도를 개선할 수 있다.
Selective Search
Selective Search는 리전 프로포절을 생성하기 위한 방법 중 하나로 이미지의 텍스처, 색상, 크기 등 다양한 요소를 고려하여 객체가 존재할 법한 영역을 식별한다. 이미지의 다양한 규모와 구조에 적응할 수 있도록 설계되었으며 Object Detection에서 높은 성능을 달성하기 위한 중요한 요소이다.
Selective Search의 수행 프로세스
- 1. Segmentation : 이미지를 작은 영역으로 세분화한다. 이는 색상, 텍스처 등의 유사성을 기반으로 이루어진다.
- 2. Merging Similar Regions : 유사한 특성을 가진 인접 영역들을 서로 병합한다. 이 과정은 점차적으로 수행되며 각 단계에서 가장 유사한 영역들이 선택되어 병합된다.
- 3. Region Proposal Generation : 위의 과정을 통해 여러단계의 Segmentation과 Merging이 이루어진 후 최종적으로 객체가 존재할 가능성이 있는 영역들을 Region Propsal로서 제안한다.
- 4. Considering Multiple Scales : Selective Search는 다양한 크기의 객체를 감지할 수 있도록 여러 스케일에서 프로세스를 반복한다.
Selective Search 실습, 시각화
이미지 로드 및 시각화
import selectivesearch
import cv2
import matplotlib.pyplot as plt
import os
%matplotlib inline
### 오드리헵번 이미지를 cv2로 로드하고 matplotlib으로 시각화
img = cv2.imread('../data/audrey01.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print('img shape:', img.shape)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb)
plt.show()Selective Search 적용하기
import selectivesearch
#selectivesearch.selective_search()는 이미지의 Region Proposal정보를 반환
_, regions = selectivesearch.selective_search(img_rgb, scale=100, min_size=2000)
print(type(regions), len(regions))반환된 Region Proposal에 대한 정보 보기
- 반환된 regions 변수는 list 타입으로 세부 원소로 Dictionary를 가지고 있음 Dictionary 내 KEY값별 의미
- rect 키값은 x,y 시작 좌표와 너비, 높이 값을 가지며 이 값이 Detected Object 후보를 나타내는 Bounding box임.
- size는 segment로 select된 Object의 크기
- labels는 해당 rect로 지정된 Bounding Box내에 있는 오브젝트들의 고유 ID
- 아래로 내려갈 수록 너비와 높이 값이 큰 Bounding box이며 하나의 Bounding box에 여러개의 오브젝트가 있을 확률이 커짐.
regions# rect정보만 출력해서 보기
cand_rects = [cand['rect'] for cand in regions]
print(cand_rects)Bounding Box를 시각화 하기
# opencv의 rectangle()을 이용하여 시각화
# rectangle()은 이미지와 좌상단 좌표, 우하단 좌표, box컬러색, 두께등을 인자로 입력하면 원본 이미지에 box를 그려줌.
green_rgb = (125, 255, 51)
img_rgb_copy = img_rgb.copy()
for rect in cand_rects:
left = rect[0]
top = rect[1]
# rect[2], rect[3]은 너비와 높이이므로 우하단 좌표를 구하기 위해 좌상단 좌표에 각각을 더함.
right = left + rect[2]
bottom = top + rect[3]
img_rgb_copy = cv2.rectangle(img_rgb_copy, (left, top), (right, bottom), color=green_rgb, thickness=2)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb_copy)
plt.show()
Bounding box의 크기가 큰 후보만 추출
cand_rects = [cand['rect'] for cand in regions if cand['size'] > 10000]
green_rgb = (125, 255, 51)
img_rgb_copy = img_rgb.copy()
for rect in cand_rects:
left = rect[0]
top = rect[1]
# rect[2], rect[3]은 너비와 높이이므로 우하단 좌표를 구하기 위해 좌상단 좌표에 각각을 더함.
right = left + rect[2]
bottom = top + rect[3]
img_rgb_copy = cv2.rectangle(img_rgb_copy, (left, top), (right, bottom), color=green_rgb, thickness=2)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb_copy)
plt.show()
IOU 구하기 실습
입력인자로 후보 박스와 실제 박스를 받아서 IOU를 계산하는 함수 생성
import numpy as np
def compute_iou(cand_box, gt_box):
# Calculate intersection areas
x1 = np.maximum(cand_box[0], gt_box[0])
y1 = np.maximum(cand_box[1], gt_box[1])
x2 = np.minimum(cand_box[2], gt_box[2])
y2 = np.minimum(cand_box[3], gt_box[3])
intersection = np.maximum(x2 - x1, 0) * np.maximum(y2 - y1, 0)
cand_box_area = (cand_box[2] - cand_box[0]) * (cand_box[3] - cand_box[1])
gt_box_area = (gt_box[2] - gt_box[0]) * (gt_box[3] - gt_box[1])
union = cand_box_area + gt_box_area - intersection
iou = intersection / union
return iou이미지를 불러오고 Ground Truth 좌표 설정
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# 실제 box(Ground Truth)의 좌표를 아래와 같다고 가정.
gt_box = [60, 15, 320, 420]
img = cv2.imread('../data/audrey01.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
red = (255, 0 , 0)
img_rgb = cv2.rectangle(img_rgb, (gt_box[0], gt_box[1]), (gt_box[2], gt_box[3]), color=red, thickness=2)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb)
plt.show()
import selectivesearch
#selectivesearch.selective_search()는 이미지의 Region Proposal정보를 반환
img = cv2.imread('../data/audrey01.jpg')
img_rgb2 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
_, regions = selectivesearch.selective_search(img_rgb2, scale=100, min_size=2000)
print(type(regions), len(regions))[cand['rect'] for cand in regions]IOU 계산
cand_rects = [cand['rect'] for cand in regions]
for index, cand_box in enumerate(cand_rects):
cand_box = list(cand_box)
cand_box[2] += cand_box[0]
cand_box[3] += cand_box[1]
iou = compute_iou(cand_box, gt_box)
print('index:', index, "iou:", iou)cand_rects = [cand['rect'] for cand in regions if cand['size'] > 5000]
cand_rects.sort()
cand_rects특정 threshold 값 이상의 IOU 값을 가진 Bounding Box 시각화
img = cv2.imread('../data/audrey01.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print('img shape:', img.shape)
green_rgb = (125, 255, 51)
cand_rects = [cand['rect'] for cand in regions if cand['size'] > 3000]
gt_box = [60, 15, 320, 420]
img_rgb = cv2.rectangle(img_rgb, (gt_box[0], gt_box[1]), (gt_box[2], gt_box[3]), color=red, thickness=2)
for index, cand_box in enumerate(cand_rects):
cand_box = list(cand_box)
cand_box[2] += cand_box[0]
cand_box[3] += cand_box[1]
iou = compute_iou(cand_box, gt_box)
if iou > 0.5:
print('index:', index, "iou:", iou, 'rectangle:',(cand_box[0], cand_box[1], cand_box[2], cand_box[3]) )
cv2.rectangle(img_rgb, (cand_box[0], cand_box[1]), (cand_box[2], cand_box[3]), color=green_rgb, thickness=1)
text = "{}: {:.2f}".format(index, iou)
cv2.putText(img_rgb, text, (cand_box[0]+ 100, cand_box[1]+10), cv2.FONT_HERSHEY_SIMPLEX, 0.4, color=green_rgb, thickness=1)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)
plt.show()img shape: (450, 375, 3)
index: 8 iou: 0.5184766640298338 rectangle: (72, 171, 324, 393)
index: 18 iou: 0.5409250175192712 rectangle: (72, 171, 326, 449)
index: 28 iou: 0.5490037131949166 rectangle: (0, 97, 374, 449)
index: 32 iou: 0.6341234282410753 rectangle: (0, 0, 374, 444)
index: 33 iou: 0.6270619201314865 rectangle: (0, 0, 374, 449)
index: 34 iou: 0.6270619201314865 rectangle: (0, 0, 374, 449)
index: 35 iou: 0.6270619201314865 rectangle: (0, 0, 374, 449)
NMS(Non Max Suppression)
NMS(Non-Maximum Suppression)는 Object Detection 과정에서 생성된 다수의 Bounding Box 중 중복되거나 불필요한 상자를 제거하는 기법이다. Object Detection 모델은 하나의 객체에 대해 여러개의 Bounding Box를 생성할 수 있으며, 이 중 가장 정확한 것만을 선택해야한다. NMS는 이러한 상황에서 최적의 경계상자를 선택하는 데 사용된다.

NMS 수행 로직
- 1. Bounding Box의 신뢰도 점수 정렬 : 모든 Bounding Box를 각각의 신뢰도 점수(객체가 있을 확률)에 따라 내림차순으로 정렬한다.
- 2. 최대 점수를 가진 Bounding Box 선택 : 가장 높은 신뢰도 점수를 가진 Bounding Box를 선택하고 나머지 Box와의 IOU를 계산한다.
- 3. IOU 계산과 Bounding Box 제거 : 선택된 Bounding Box와 다른 Bounding Box 간의 IOU를 계산한다. IOU가 특정 threshold(예:0.5) 이상인 상자는 중복으로 간주하고 제거한다.
- 4. 반복 수행 : 위의 과정을 모든 Bounding Box에 대해 반복 수행한다. 이미 선택되거나 제거된 상자는 고려하지 않는다.
- 5. 최종 Bounding Box 선택 : 모든 과정을 통해 남은 Bounding Box들이 최종 Detection 결과가 된다.
Object detection 성능 평가 metric - mAP(Mean Average Precision)
mAP(Mean Average Precision)은 평균 정밀도의 평균을 의미한다. Object Detection 모델이 얼마나 정확하게 객체를 Detect하는지를 측정하는 데 사용되는 지표로 모델이 Detect한 객체들이 얼마나 정확한지(정밀도)와 관련된 객체들을 얼마나 잘 찾아내는지(재현율)을 동시에 고려한다.
mAP 계산 과정
- 1. 정밀도(Preicision)와 재현율(Recall) 계산
정밀도 : Detect된 객체중 실제로 맞는 객체의 비율
재현율 : 실제 객체중 Detect된 객체의 비율 - 2. Precision-Recall Curve 생성 : 각 클래스에 대해 정밀도와 재현율을 계산하고 이를 기반으로 Precision-Recall Curve를 생성한다.
- 3. Average Precision(AP) 계산 : 각 클래스에 대한 Precision-Recall Curve 아래 영역을 계산하여 평균 정밀도(AP)를 구한다.
- 4. mAP 계산 : 모든 클래스에 대한 AP를 평균하여 mAP를 계산한다. 이는 모델이 다양한 클래스를 얼마나 잘 검출하는지를 종합적으로 나타낸다.
mAP의 중요성
- 종합적 성능 평가 : mAP는 모델의 정밀도와 재현율을 모두 고려하여 모델의 종합적인 성능을 평가한다.
- 클래스 간 성능 비교 : 다양한 클래스에 대한 모델의 성능을 공정하게 비교할 수 있다.
- 다양한 검출 임계값 고려 : 다양한 임계값에서의 모델 성능을 평가함으로써 모델의 강건성을 측정할 수 있다.
