RetinaNet
RetinaNet은 특히 어렵고 작은 Object를 Detect하는 문제에 대해 높은 정확도를 보이며 Focal Loss라는 새로운 loss 함수를 도입하여 이전 모델들의 한계를 극복했다. 다양한 크기의 객체에 대해 뛰어난 Detection 능력을 보여주며 One Stage Detector의 속도와 Two Stage Detector의 정확도 사이에 균형을 맞춘다.
RetinaNet의 특징
Focal Loss의 적용
- 불균형 문제 해결 : Object Detection 시스템에서는 배경이 객체보다 훨씬 많아 학습 과벙에서 불균형이 발생한다. RetinaNet은 Focal Loss를 사용하여 쉬운 예제(배경)과 어려운 예제(객체) 사이의 불균형을 해결한다.
- 효율적인 학습 : Focal Loss는 잘못 분류된 예제에 더 많은 가중치를 두어 학습을 집중시키고 쉽게 분류되는 다수의 예제는 학습과정에서 덜 중요하게 다룬다.
Feature Pyramid Network(FPN)
- Multi Scale Detection : RetinaNet은 이미지 내의 다양한 크기와 형태의 객체를 검출하기 위해 FPN을 사용한다. FPN은 여러 스케일의 특성을 결합하여 각 스케일에서 효과적인 예측을 할 수 있도록 돕는다.
빠른 Detection 시간과 높은 정확도
- OneStage Detector의 빠른 Detection 시간의 장점을 가지면서 One Stage Detector의 Detection 성능 저하 문제를 개선했다.
- 수행시간은 YOLO나 SSD보다 느리지만 Fater RCNN보다 빠르다.
- 수행 성능은 타 Detection 모델 보다 뛰어나며 특히 타 One Stage Detector보다 작은 오브젝트에 대한 Detection 능력이 뛰어나다.
RetinaNet 성능
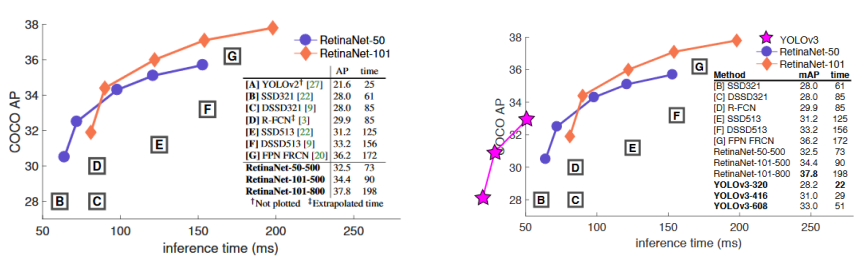
- RetinaNet vs YOLOv3
YOLOv3는 RetinaNet과 비교하여 추론시간이 매우 짧은 반면 AP또한 높은편이다. RetinaNet의 경우 추론시간은 더 소모되지만 더 높은 정확도를 보여 모델 선택시 속도와 정확도 간의 균형을 고려해 높은 정확도가 필요한 경우 RetinaNet을 선택 할 수 있지만 더 빠른 추론 속도를 요구해야하는 상황에서는 YOLOv3가 더 적합하다고 볼 수 있다.
Focal Loss의 필요성
Object Detection 시스템에서 One Stage Detector는 빠른 속도와 좋은 성능으로 인해 인기 있지만 Class imabalance 문제가 여전히 중대 과제였다. Class Imbalace는 모델이 소수의 객체 클래스보다 다수의 배경 클래스를 과도하게 학습하는 현상으로 이로 인해 모델이 실제 객체를 올바르게 Detect하는 데 어려움을 겪게 되며 이를 해결하기 위해 Focal Loss가 도입되었다.
Object Detection의 Class imbalance 이슈
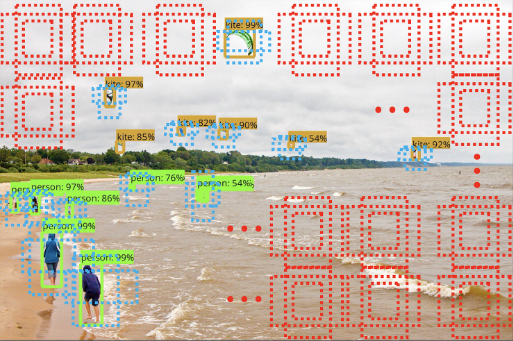
Object Detection 과정에서 수많은 배경 Negative(Non-object) 샘플과 상대적으로 적은 양의 Positive(Object) 샘플이 존재한다. 이로 인해 모델이 배경을 객체보다 더 잘 인식하게 되어 실제 중요한 객체 클래스에 대한 예측 성능이 저하된다.
One Stage Object Detector의 Class imbalance 문제
- Easy Example : 찾기 쉬운 대상들로 Background나 크고 선명한 대상 객체. 이미 높은 예측 확률을 가지고 있다.
- Hard Example : 찾기 어려운 대상들로 작고 형태가 불분명하며 낮은 예측 확률을 가지고 있다.
- Easy Example이 많고 Hard Example이 적은 Class imbalance 이슈는 Object Detection이 안고 있는 고유 문제이다.
- Two Stage Detector의 경우는 Region Proposal Network에서 오브젝트가 있을만한 높은 확률 순으로 필터링을 먼저 수행할 수 있다.
- One Stage Detector는 Region Proposal과 Detection을 같이 수행하므로 매우 많은 오브젝트 후보들에 대해서 Detection을 수행하야 하므로 Class imbalance로 인한 성능 저하 영향이 크다.
Class imbalance 상태에서 Cross entropy의 문제점
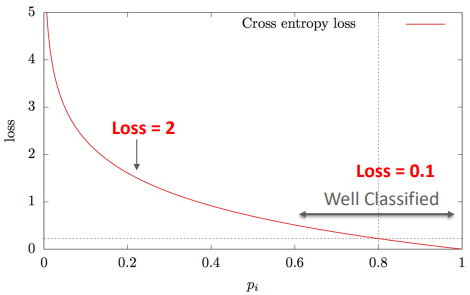
Cross Entropy 함수에서는 모든 에제를 동등하게 다루기 때문에 대부분의 Easy Example(Negative)들이 학습에 지배적인 영향을 끼치게 된다. 이에 따라 학습 과정에서 모델이 객체에 대한 예측을 개선하는 것보다 배경을 인식하는 데 더 초점을 맞추게 되는 문제가 발생한다.
Class imbalance 해결 방안
- 기존 One Stage Detector의 Class Imbalance 해결방안 : 학습 시 경험치에 기반한 샘플링이나 augmentation에 집중한다.
- RetinaNet의 Class imbalance 해결 방안 : Cross Entropy 함수에 가중치를 도입하여 Easy Example의 영향력을 줄이고 모델이 Hard Example에 더 집중하도록 해 모델이 잘못 분류된 예제들로부터 더 많은 것을 배우도록 하며 전체적인 Detect 성능을 향상시킨다.
Focal Loss는 확실한 Object들에 매우 작은 loss를 부여
- 쉽게 판별 : 0.1/0.00026 = CE 대비 384배 작은 Loss
- 잘못 판별 : 2.3/0.4667 = CE 대비 5배 작은 Loss
- 매우 쉽게 판별 : 0.01/0.00000025 = CE 대비 40,000배 작은 Loss
쉽게 판별 가능한 객체 (p= 0.9)
잘못 판별한 객체 (p = 0.1)
매우 쉽게 판별한 객체 (p = 0.99)
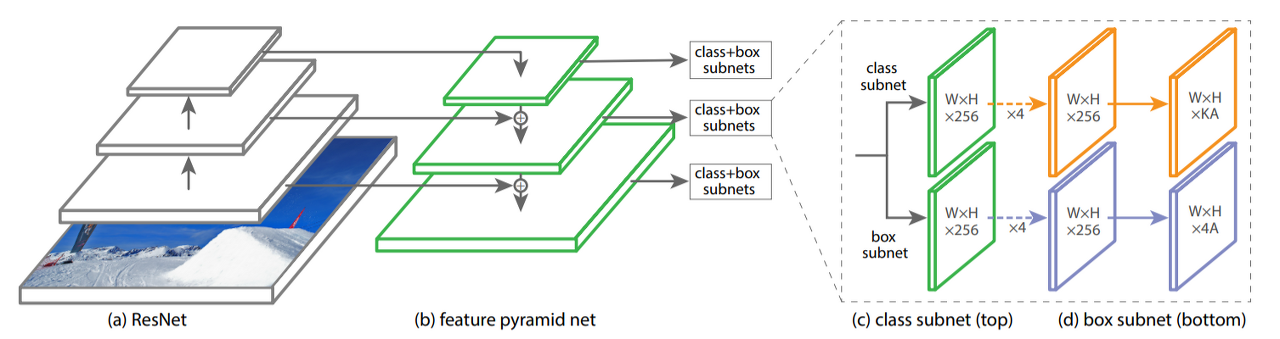
FPN(Feature Pyramid Network)
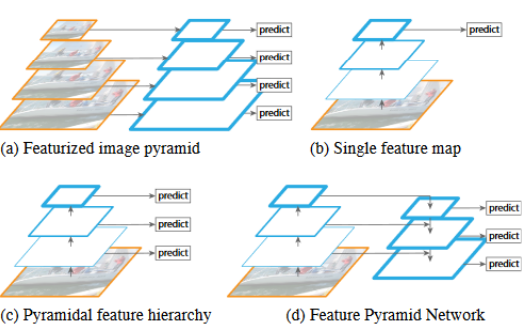
FPN은 서로 다른 크기를 가지는 Object들을 효과적으로 Detection 하기 위해서 bottom up 과 top down 방식으로 추출된 feature map들을 lateral connection으로 연결하는 방식이다.
Feature Pyramid Network 구조
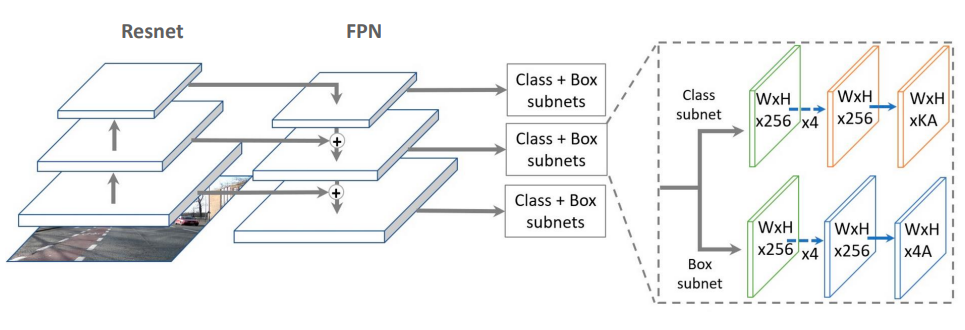
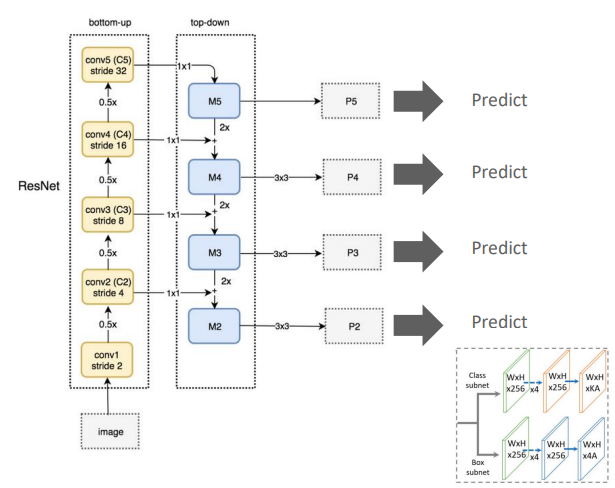
- 1. ResNet : 기본적인 feature extractor 역할을 하는 ResNet은 이미지로 부터 low-level부터 high-level feature까지 여러 단계의 feature를 추출한다. 각 단계에서는 이미지에 대한 다른 크기의 Feature Map을 생성한다.
- 2. Bottom-up pathway : 이 경로는 ResNet의 Convolution layer들을 통과하며 생성된 Feature Map들로부터 시작되어 더 깊은 층으로 갈수록 Feature Map의 크기는 감소하지만 Feature의 추상화 수준은 증가한다.
- 3. Top-down pathway and Lateral Connections : 고수준의 Feature Map에서 정보를 가져와 점차적으로 Up sampling하고 더 낮은 레벨의 Feature Map과 결합한다. 이 과정을 통해 FeatureMap의 각 레벨에 대해 동일한 크기의 고해상도 Feature Map을 생성한다.
- 4. Class + Box Subnets : FPN에서 생성된 각 레벨의 Feature Map은 클래스 분류와 Bounding Box 예측을 위해 별도의 Subnet으로 전달된다. 각 Subnet은 객체의 클래스를 결정하고 정확한 위치를 예측한다.
- 5. : 이는 Feature Map의 차원을 나타내며 예를들어 은 너비와 높이가 인 Feature Map에 256개의 Feature channel이 있다는 것을 의미한다. 와 같은 표현은 Sampling 비율을 나타낸다.
RetinaNet FPN ANchor box
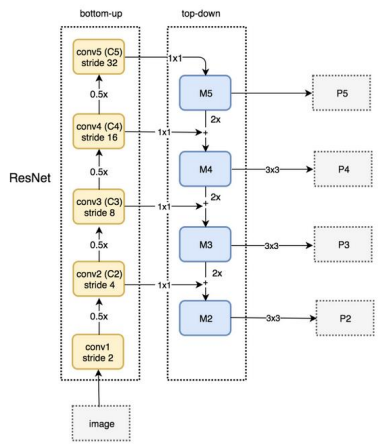
- 9개의 anchor box가 P2~P5의 개별 Layer의 개별 grid에 할당된다.
- 3개의 서로다른 크기와 3개의 서로 다른 스케일을 가진다.
- 약 100K의 anchor box 생성
- 개별 anchor box는 Classification을 위한 K개의 클래스 확률값과 Bounding Box regression을 위한 4개의 좌표값을 가진다.
EfficientDet
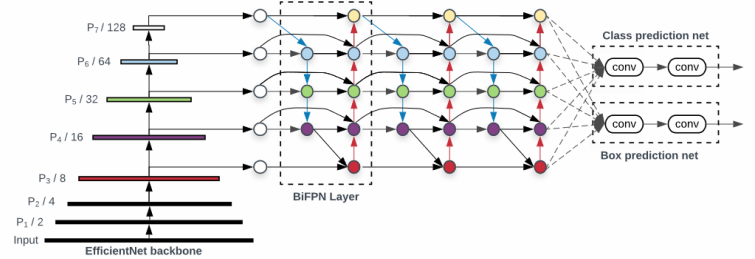
EfficientDet은 효율적인 구조와 새로운 기법을 통해 높은 정확도를 유지하면서 계산 비용을 줄이는 것을 목표로 개발되었다. EfficientDet은 Scale EfficientNet Backbones와 BiFPN(Bidirectional Feature Pyramid Networks), Compound Scaling을 통해 새로운 표준을 제시한다.
EfficientNet Backbone
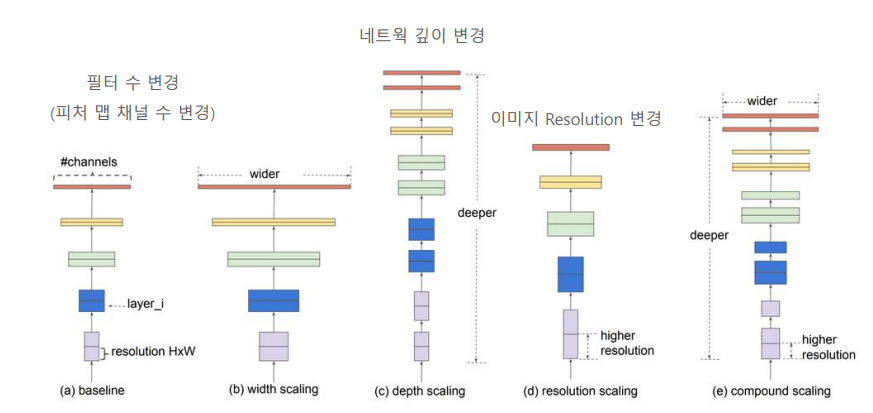
EfficientNet은 기본적으로 네트워크를 확장하는 새로운 방식인 Compund Scaling에 기초한다. 이 방식은 네트워크의 깊이(Depth), 필터 수(Width), 이미지 Resolution 세가지 차원에서 크기를 최적으로 조합해 모델의 성능을 극대화한다.
- Depth : 네트워크의 깊이(층의 수)를 확장하여 더 복잡한 Feature를 추출할 수 있도록 한다.
- Width : 각 층의 필터 수를 확장하여 네트워크가 더 다양한 Feature를 포착할 수 있게한다.
- Resolution : 입력 이미지의 해상도를 높여 네트워크가 더 세밀한 정보를 추출할 수 있게 한다.
EfficientNet 구조
EfficientNet은 총 8가지 버전(B0~B7)으로 제공되며 B0가 기본 모델이고 B7까지 점진적으로 크기가 커지고 복잡해진다.
- MBConv : Mobile Inverted Bottleneck Convolution이라고 하는 MBConf 블록은 EfficientNet의 주요 구성 요소이다. 이는 모바일 환경에 최적화된 이번티드 레지 듀얼 구조를 사용한다.
- SE Block : Squeeze-and-Excitation 블록은 각 채널의 특성을 자동으로 가중치를 조절하여 중요한 특성을 강조한다.
- Swish Activation : Swish 활성화 함수는 ReLU함수의 대안으로 사용되어 더 나은 성능을을 제공한다.
EfficientNet 개별 Scaling 요소에 따른 성능 향상 테스트
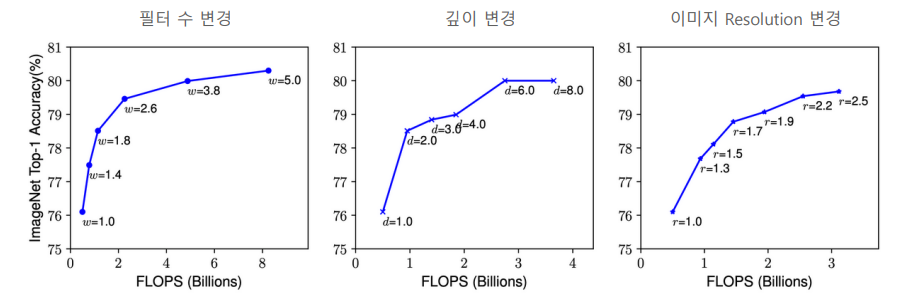
필터 수, 네트워크 깊이를 일정 수준 이상 늘려도 성능 향상이 미비하나 Resolution의 경우 어느정도 약간씩 성능 향상이 지속된다. ImageNet 데이터 세트 기준 80%의 정확도에서 개별 Scaling 요소를 증가 시키더라도 성능 향상이 어렵다.
EfficientNet 최적 Scaling 도출 기반 식
- depth, width, resolution에 따른 FLOPS 변화를 기반으로 최적 식을 도출한다.
- width, resolution은 2배가 되면 FLOPS는 4배가 되므로 제곱을 곱한다.
- 3가지 Scaling Factor를 동시 고려하는 Compound Scaling을 적용한다.
- 최초에는 를 1로 고정하고 grid search 기반으로 의 최적 값을 찾아낸다. EfficientNetB0의 경우 이다.
- 다음으로 를 고정하고 를 증가 시켜가면서 Efficient B1~B7까지 Scale up 구성한다.
BiFPN
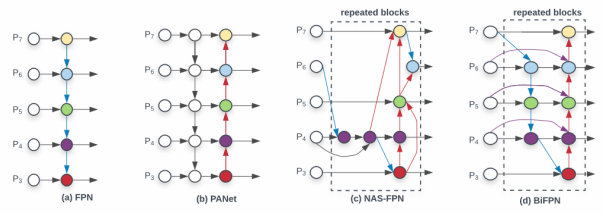
BiFPN은 효율적인 Object Detection을 위해 고안된 Bidirectional Feature Pyramid Network의 약자로 기존의 FPN을 개선한 아키텍처이다. BiFPN은 특히 다양한 크기의 객체를 검출하기 위해 설계 되었으며 여러 스케일의 특성 정보를 효과적으로 결합한다. BiFPN은 객체 검출 모델에서 중요한 특성인 Cross Scale Connection와 가중치가 있는 Weighted Feature Fusion을 통해 Object Detection의 정확도와 효율성을 극대화 한다.
Cross Scale Connections
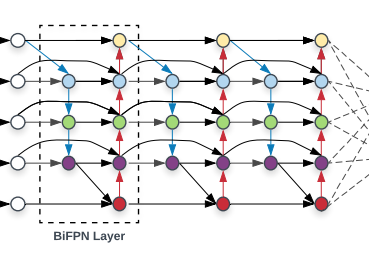
Cross Scale Connection은 다양한 해상도의 Feature maps 간의 정보를 통합하여 각각의 Feature Map이 서로의 정보를 활용할 수 있게 하는 중요한 구조이다. 이러한 연결은 특히 피라미드 구조에서 High-level(저해상도, 고수준의 feature)과 Low-level(고해상도, 저수준의 feature)간에 효과적으로 정보를 교류한다.
Cross Scale의 작동 원리
- 1. Up-sampling과 Down-sampling : 각 Feature Map은 Up-sampling을 통해 High-level의 정보를 얻거나 Low-sampling을 통해 Low-level의 정보를 전달 받는다.
- 2. 정보의 경로 : Cross Scale Connection은 Feature Map간의 다양한 경로를 제공함으로써 더 낮거나 높은 해상도의 Feature Map에서 유용한 정보를 얻을 수 있도록 한다. 이는 모든 레벨에서 정보가 상호 보완적으로 작용할 수 있게 해준다.
- 3. 효율적인 정보 통합 : Feature Map이 다른 Scale의 정보를 활용하여 보다 정확한 예측을 수행할 수 있도록 지원한다.
Weighted Feature Fusion
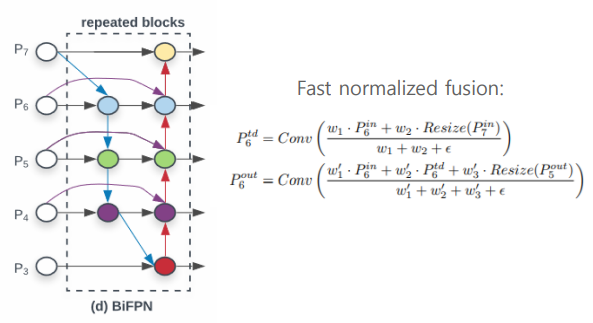
서로 다른 resolution(feature map size)를 가지는 input feature map들은 Output feature map을 생성하는 기여도가 다르기 때문에 서로 다른 가중치를 부여하여 합쳐질 수 있어야 한다.
- Unbounded fusion 입력 Feature Map에 가중치를 곱해서 출력 feature map을 생성한다. 여기서 는 정해진 값이 아닌 학습시켜서 도출된 weight이다.
- Softmax-based fusion
- Fast Normalized fusion
Compound Scaling
Compound Scaling은 모델의 규모를 조정할 때 고여해야할 세 가지 중 요소인 Depth, Width, Resolution을 동시에 조화롭게 확장하는 방법이다.
- 균형 잡힌 Sclaing : 모델의 Depth, Width, Resolution을 동시에 확장하여 최적의 성능을 달성한다.
- 효율적인 자원 활용 : 모델이 사용 가능한 컴퓨팅 자원을 고려하여 규모를 확장함으로써 제한된 자원 하에서도 성능을 극대화한다.
- 유연성 : 다양한 하드웨어 환경과 응용 프로그램에 모델을 쉽게 적응할 수 있도록 한다.
Compound Scaling 작동 원리
- 1. 네트워크의 Depth : Depth를 늘리면 모델이 더 복잡한 feature를 학습할 수 있지만 계산 비용이 증가하고 overfitting의 위험이 있을 수 있다.
- 2. 네트워크의 Width : Width를 늘리면 모델이 더 다양한 feature를 학습할 수 있지만 마찬가지로 계산 비용이 증가한다.
- 3. 입력 Resolution : Resolution을 늘리면 더 세밀한 정보를 모델이 포착할 수 있지만 이미지 처리 시간이 늘어난다.
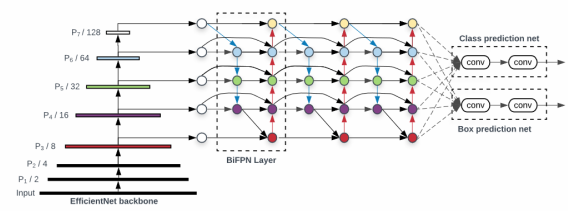
- Backbone network
EfficientNet B0~B6로 Scaling 그대로 적용한다. - BiFPN network
Depth는 BiFPN 기본 반복 block을 3개로 설정하고 Scaling 적용한다.Width(채널 수)는 (1.2, 1.25, 1.3, 1.35, 1.4, 1.45)중 Grid Search를 통해서 1.35로 Scaling 계수를 선택하고 이를 기반으로 Scaling 적용한다. - Prediction Network
Width(채널 수)는 BiFPN 채널수와 동일하고 Depth는 아래 식을 적용한다. - 입력 이미지 크기
