Segmentation
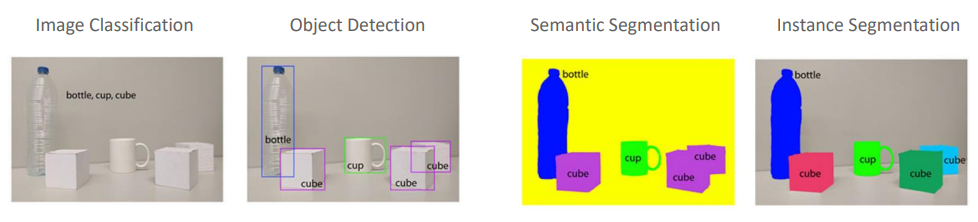
Computer Vision에서 Segmentation은 이미지를 픽셀 수준에서 이해하는데 사용되는 기술이다. 이미지를 분석할 때 단순히 이미지가 무엇을 포함하는지 식별하는 것을 넘어서서 이미지 내의 각 객체의 적확한 위치와 형태를 파악하는 것이 중요하다. 이 과정에서 주로 Sementic Segmentation과 Instance Segmentation이 사용된다.
-
Image Classification : 이미지 내에 있는 객체를 식별하고 해당 이미지가 어떤 카테고리에 속하는지 결정하는 과정이다. 위의 이미지에선 이미지에 병, 컵, 큐브가 있다고 분류해 이미지 전체에 대한 단일 레이블을 예측한다.
-
Object Detection : 이미지 내의 개별 객체를 식별하고 각각의 위치에 대해 Bounding Box를 그리는 작업으로 위의 이미지에서 병, 컵, 큐브에 대해 Bounding Box를 그리고 레이블을 할당하여 위치를 나타낸다.
-
Semantic Segmentation : 이미지 내의 모든 픽셀을 특정 클래스에 할당하는 과정으로 클래스는 병, 컵, 큐브와 같이 공통된 의미를 가진 픽셀 그룹이다. 여기서 모든 병 픽셀은 같은 색상으로, 컵은 다른 색상으로, 큐브는 또 다른 색상으로 표시되어 객체의 경계를 정확히 구분하는 것에 초점을 맞춘다.
-
Instance Segmentation : Semantic Segmentation의 더 세부적인 형태로 동일한 클래스에 속하는 개별 객체를 구분한다. 각 병, 컵, 큐브가 별도의 인스턴스로 구분되며 서로 다른 색상으로 표시된다. 이를 통해 같은 종류의 여러 객체를 개별적으로 식별할 수 있다.
Semantic Segmentation Encoder-Decoder Model
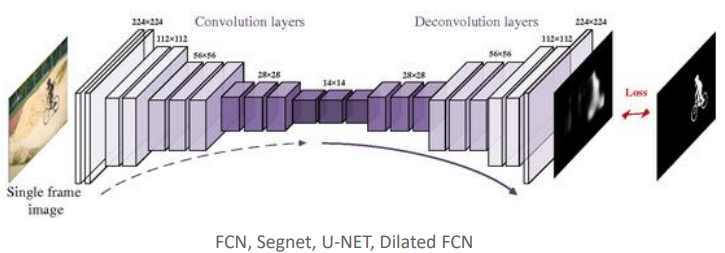
Semantic Segmentation에서 사용되는 Encoder-Decoder 아키텍처는 이미지에서 High-level feature를 추출하고(Encoder) 이후 이 feature를 사용해 원본 이미지 크기로 픽셀 단위의 분류를 수행하는 구조(Decoder)를 포함한다. 이 구조는 이미지의 픽셀마다 레이블을 할당하여 객체의 경계를 명확히 구분하고자 할 때 일반적으로 사용된다.
Encoeder
Encoder는 Convolution layers를 통해 이미지로부터 feature를 추출한다. 각 Convolution layer를 통과할 때 마다 이미지의 공간적 차원은 줄어들고 feature의 깊이(채널 수)는 증가한다. 이과정은 이미지 내의 중요한 정보를 요약하고 Semantic 정보를 압축하는 데 도움이 된다.
Decoder
Decoder는 Encoder를 통해 압축된 feature map을 다시 확장하여 원본 이미지의 해상도에 맞는 크기로 복원한다. De-convolution layer 층은 이 확장 과정에서 사용되며 High-level feature 정보를 픽셀 수준의 예측으로 변환한다. Decoder의 최종 출력은 각 픽셀에 대한 class 레이블이 할당된 픽셀 단위의 Segmentation map이다.
FCN(Fully Convolutional Network for Semantic Segmentation)
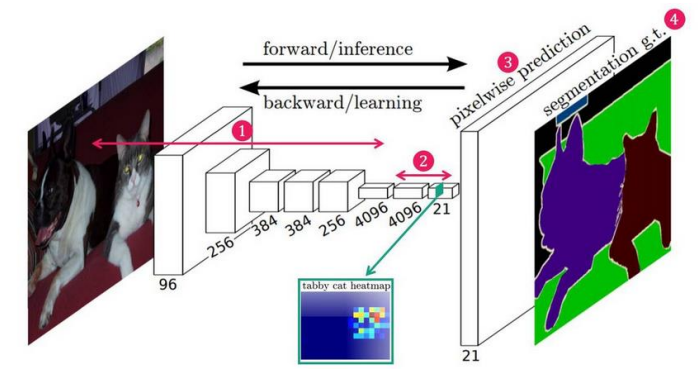
FCN(Fully Convolutional Network for Semantic Segmentation)은 Sementic Segmentation을 위한 신경망 아키텍처로 전체 네트워크가 Convolution layer로만 구성되어 있어서 이미지의 픽셀 수준에서 각각의 픽셀이 어떤 클래스에 속하는지를 결정한다. 이 모델은 고정된 크기의 입력에 제한을 받지 않고 임의 크기의 이미지에 적용이 가능하며 이미지 분류용으로 설계된 네트워크를 Segmentation 작업에 적용할 수 있도록 수정한 최초의 아키텍처 중 하나이다.
Fully Connected Layer vs Convolutional layer
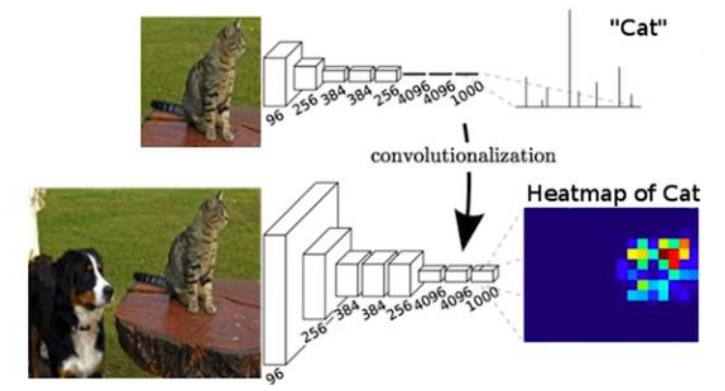
Fully Connected layer는 Classification 작업에 주로 사용되며 Convolutional layer는 feature를 추출하고 공간적인 Context를 이해하는 데 사용된다. 현대의 많은 신경망 아키텍처는 특히 이미지 처리 분야에서는 Convolutional layer가 중요한 역할을 담당하며 이를 통해 이미지 내의 객체를 인식하고 위치를 파악할 수 있다.
Fully connected layer
- 일반적으로 신경망의 마지막 단계에서 사용되며 모든 입력 뉴런이 다음 계층의 모든 뉴런과 연결되어 있다.
- 이미지가 벡터 형태로 Flatten되어 각 픽셀 값이 개별 뉴런의 입력으로 사용된다.
- 클래스별 확률을 출력하기 위해 사용되며 각 뉴런의 출력 값은 특정 클래스에 대한 확률을 나타내는 스코어가 된다.
Convolutional layer
- CNN의 주요 구성 요소로 각 이미지에서 feature를 추출하는 데 사용된다.
- Convolution 연산을 통해 이미지의 공간적 정보를 유지하면서 feature maps를 생성한다.
- 위치 불변성을 유지하면서도 이미지의 지역적 feature를 인식할 수 있다.
FCN의 주요 특징
Convolutional layer만을 사용한 구조
- FCN에서는 Fully Connected layers를 사용하지 않고 이를 Convolutional layer로 대체한다. 이를 통해 네트워크는 임의 크기의 이미지에 대해 픽셀 단위의 예측을 수행할 수 있게 된다.
Feature map upsampling
- Encoder에서 축소된 Feature map을 다시 원본 크기로 복원하기 위해 De-convolution layer를 사용한다. 이 과정에서 원본 이미지와 동일한 해상도의 Segmentation map을 얻게 된다.
Skip Connection의 도입
- FCN에서는 Encoder의 여러 단계에서 Feature map을 직접 Decoder로 전달하는 Skip Connection을 사요한다. 이를 통해 Low-level feature 정보를 유지하며 더 정확한 픽셀 분류를 가능하게 한다.
End-to-End 학습 가능
- FCN은 이미지를 입력으로 받아 픽셀 단위의 Segmentation map을 직접 출력으로 제공한다 이로 인해 단일 네트워크로 End-to-End 학습이 가능하다.
FCN Down Sampling과 Upsampling

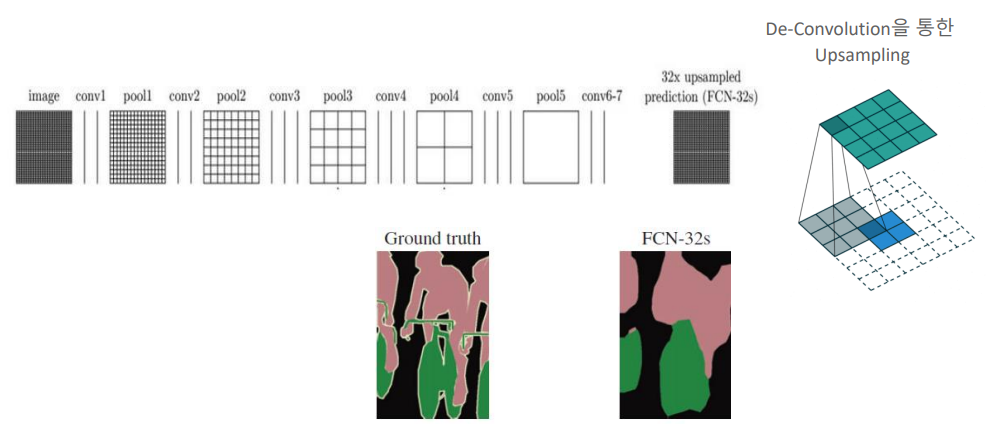
Down Sampling
- Down Sampling은 입력 이미지로부터 High-level feature를 추출하는 과정이다. 이는 일련의 convolution layers와 max pooling layer를 통해 수행된다. 각 단계를 거칠 때마다 이미지의 공간적 차원은 줄어들지만 더 높은 수준의 feature를 얻을 수 있다.
- feature의 차원 : 초기에는 224x224x3 크기의 이미지(높이 x 너비 x 채널)가 입력되고 네트워크를 통과하면서 7x7x512의 크기로 줄어든다.
- feature의 추출 : 네트워크의 깊은 층에 도달할 때까지 다양한 feature들이 추출되며 이는 이미지의 추상적인 정보를 나타낸다.
Up Sampling
Up Sampling은 Down Sampling을 통해 얻은 feature map을 원본 이미지 크기로 복원하는 과정이다. 이를 통해 각 픽셀에 대한 정확한 클래스 예측을 수행할 수 있다.
- 32배 Up Sampling : FCNl에서는 Down Sampling으로 인해 축소된 feature map을 다시 원래 크기로 확장한다. 예를 들어 7x7x512의 feature map을 32배 Up Sampling 하여 224x224x21 크기의 Segmentation map을 만든다. 여기서 21은 분할하려는 클래스의 개수를 나타낸다.
- Padding 삽입 : Upsampling 과정에서 정확한 크기 맞춤을 위해 때때로 padding이 추가된다.
Class Prediction Layer
Upsampling된 feature map에 클래스별 확률을 할당한다. 이는 각 클래스에 해당하는 위치에서 확률이 높아진다.
Segmentation Map
Upsampling과 Class Prediction Layer를 거쳐 얻은 최종 출력은 Segmentation map이다. 이 맵은 이미지의 각 픽셀이 어떤 클래스에 속하는지를 색상을 표시하여 객체의 경계와 형태를 명확하게 구분한다.
Feature Map을 혼합하여 Pixel Wise Prediction
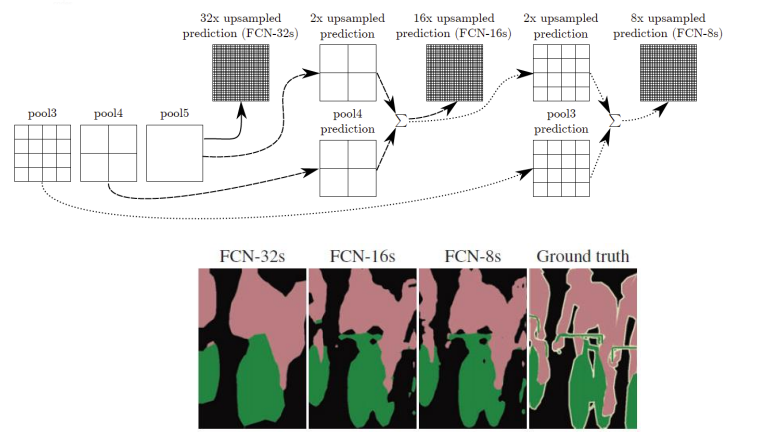
FCN-32s, FCN-16s, FCN-8s는 각각 다른 Up Sampling 비율을 나타낸다. 이 모델들은 Down Sampling된 Feature Map을 다시 원본이미지의 해상도로 Up Sampling하는 과정을 거치며 이를 통해 픽셀별 클래스 예측을 수행한다.
- FCN-32s : 단일 32배 Up Sampling을 통해 생성된 가장 기본적인 예측으로 이는 가장 낮은 해상도의 Feature map을 원본 크기로 복원한다.
- FCN-16s : 중간 해상도의 feature map(pool4)를 2배 Up Sampling하여 가장 낮은 해상도(pool5)와 결합한 후 최종적으로 16배 Up Sampling을 수행한다.
- FCN-8s : 가장 높은 해상도 (pool3)의 feature map을 2배 Up Sampling하고 중간 해상도(pool4)의 예측과 결합한 다음 가장 낮은 해상도(pool5)의 예측과 합쳐진 후 8배 Up Sampling을 통해 최종 예측을 만든다.
각각의 접근법은 더 정밀한 예측을 가능하게 하지만 Up Sampling의 비율이 높아질수록 더 세밀한 겨로가를 얻을 수 있다. 이러한 과정은 학습 중에 각 feature map에서 중요한 정보를 유지하면서 더 세밀한 feature를 추출하고자 할 때 사용 된다.
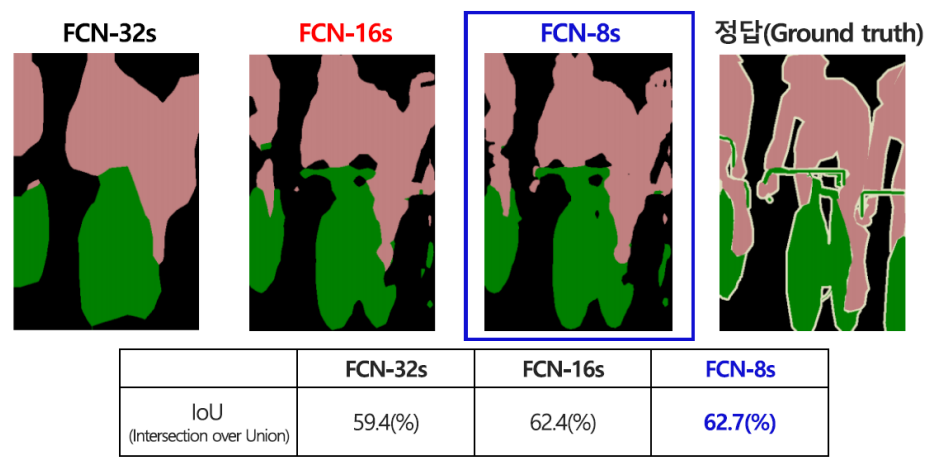
FCN-32s/16s/8s 별 성능
Mask R-CNN
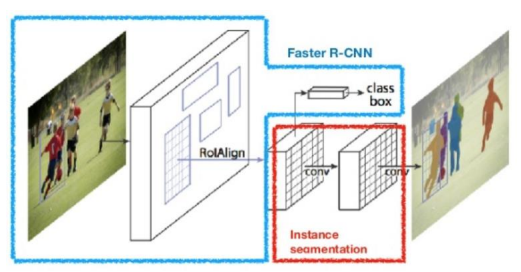
Mask R-CNN은 객체의 클래스를 분류하고 해당 객체의 위치를 Bounding Box로 감지하는 것뿐만 아니라 객체 각각에 대한 픽셀 단위의 마스크를 생성하여 Instance Segmentation을 수행하는 신경망 모델로 Faster R-CNN에 기반하여 Instance Segmentation 기능을 확장한 모델이다.
- Faster RCNN과 FCN 기법 개선 및 결합
- ROI-Align
- 기존 Bounding Box regression과 Classfication에 Binary Mask Prediction 추가
- 비교적 빠른 Detection 시간과 높은 정확도
- 직관적이고 상대적으로 쉬운 구현
Faster R-CNN 구조
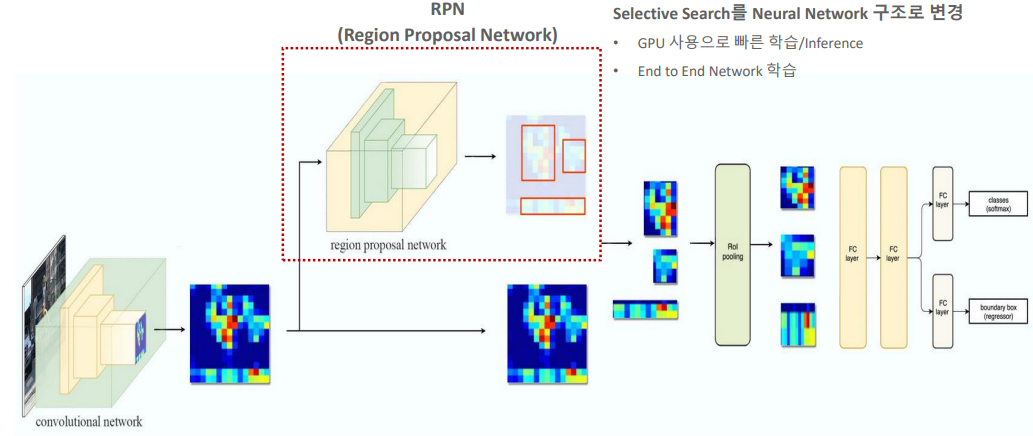
Faster R-CNN은 REgion Proposal에서부터 분류 및 Bounding Box regression,에 이르기 까지 전체 과정을 한 네트워크로 통합하여 처리하는 End-to-End 구조를 가지고 있다. 이 모델은 Object Detection을 위해 RPN(Region Proposal Network)와 Fast R-CNN을 결합한다.
RPN(Region Proposal Network)
- RPN은 이미지에서 객체 후보 영역을 제안하는 역할을 한다 이는 Convolution network에서 추출된 feature map 위에서 슬라이딩 윈도우 방식으로 anchor boxes를 사용하여 객체가 있을 만한 영역을 식별한다.
- 각 위치에 대해 다양한 크기와 비율의 anchor boxes를 생성하고 box들이 객체를 포함하는지 여부와 정확한 위치를 조정한다.
RoI Pooling
RPN으로부터 제안된 영역들은 RoI Pooling을 통해 고정된 크기의 feature map으로 변환된다. 이 과정은 다양한 크기의 제안된 영역들을 동일한 차원의 벡터로 변환하여 후속 분류 및 회귀 게측에 입력할 수 있게 한다.
Fast R-CNN 구조
변환된 RoI feature 벡터들은 Fast R-CNN 구조를 거쳐 객체의 클래스를 분류하고 Bounding Box regression을 통해 위치를 미세 조정한다. Fast R-CNN은 Fully Connected Layer를 사용하여 feature를 분석하고 클래스 분류와 Bounding Box 회귀를 동시에 수행한다.
Mask R-CNN 구조

-
RPN(Region Proposal Network)
- 이미지에서 객체 후보 영역을 식별한다.
- 이 영역들은 가능한 객체가 포함될 수 있는 위치를 나타낸다.
-
RoIAlign
- RPN에 의해 제안된 영역을 입력으로 받아 정확한 픽셀 단위의 객체 격ㄱ계를 추출한다.
- RoIAlign은 픽셀 수준에서의 정밀도를 높이기 위해 개발된 기술로 RoIPooling의 정확성 문제를 해결한다.
-
Bbox Regression
- 각 객체 후보 영역에 대해 정확한 위치와 크기를 결정하는 회귀 작업을 수행한다.
-
Classification
- 각 객체 후보 영역에 대해 클래스 레이블을 예측한다.
-
Binary Mask Prediction
- 각 객체 후보 영역에 대해 픽셀 단위의 분할 마스크를 생성한다. 이 마스크는 객체가 있는 위치의 픽셀을 1로 객체가 없는 위치의 픽셀을 0으로 구분한다.
Segmentation에서 RoI Pooling 문제점
-
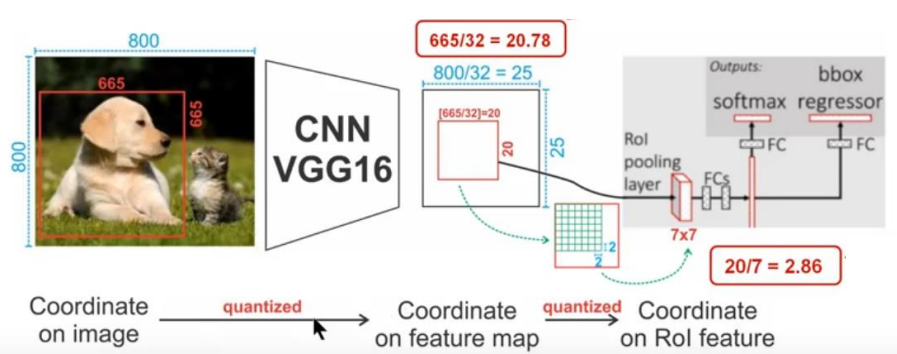
정밀도 손실 : RoI Pooling은 입력 Feature Map을 고정된 크기의 출력으로 변환하는 과정에서 원본 영역의 정확한 위치 정보를 일부 손실한다. 이는 특히 픽셀 단위의 정밀한 Segmentation 작업에서 문제가 될 수 있다.
-
Quantization Error : 영역의 좌표를 고정된 크기의 격자에 맞추어야 할 때 좌표의 quantization으로 인해 작은 객체나 경계 부분에서 정확한 위치가 왜곡될 수 있다. 이로인해 Bounding Box가 실제 객체보다 클 수도 있고 작을 수도 이쓰며 이는 Binary Mask의 정확성에 영향을 미친다.
-
비례적인 Scaling 부재 : 모든 RoI를 같은 크기로 변환하기 때문에 원본 영역의 크기와 비율을 고려하지 않는다는 문제가 있다. 따라서 객체의 형태와 크기가 다양한 실제 상황에서 RoI Pooling은 이런 다양성을 적절히 처리하지 못한다.
-
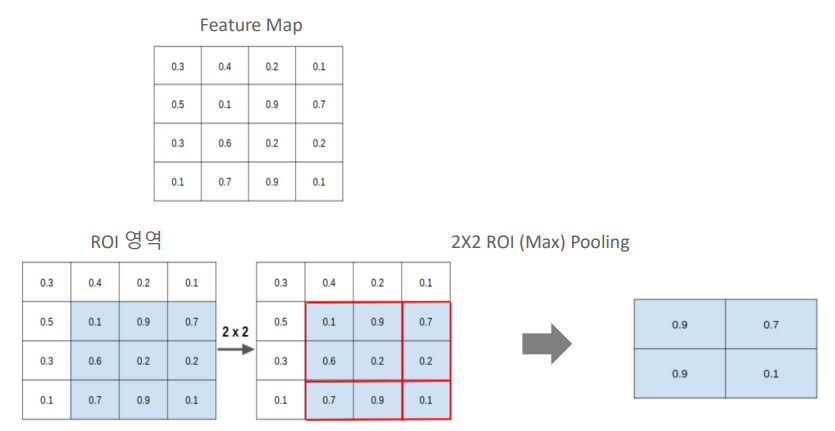
정확한 mask 생성이 어려움 : RoI Pooling의 정밀도 손실은 객체의 정확한 형태를 파악하고 분리해야 하는 Segmentation 작업에서 정확한 mask를 생성하는데 어려움을 초래한다.
-
경계 부정확성 : 특히 객체의 경계 부분에서 RoI Pooling의 정밀도 손실은 Binary Mask의 정확성을 저하시킬 수 있으며 이는 세밀한 Segmentation 작업에 부적합하다.
Bilinear Interpolation을 이용한 RoI-Align
RoI-Align의 원리
- RoI는 신경망의 Convolution Feature Map 상에서 정의되며 RoI-Align은 이 영역을 보다 정확하게 샘플링하기 위해 Bilinear Interpolation을 사용한다.
- RoI 영역의 임의의 위치에 있는 픽셀 값이 RoI 주변의 4개의 지점(A, B, C, D)의 feautre 갑셍 의해 결정되도록 한다.
- 각 지점의 값에 해당 지점까지의 거리에 기반한 가중치를 적용하고 weighted sum을 계산하고 계산된 포인트를 기반으로 Max Pooling을 수행해 RoI Pooling에서 발생하는 Quantization Error를 줄이고 객체의 경계를 더 정밀하게 추출할 수 있다.
Bilinear Interpolation
- Bilinear Interpolation은 주변 4개 픽셀 값의 가중 평균을 사용하여 주어진 위치의 픽셀 값을 추정하는 방법이다.
- 예를들어 (5,5) 위치의 픽셀 값은 주변 A, B, C, D 4개의 지점의 값에 거리에 따른 가중치를 적용하여 계산된다. 결과값은 실제 RoI의 정확한 위치를 더 잘 반영하므로 픽셀의 실제 위치와 크기를 더 정확하게 예측할 수 있다.
Feature Extractor
Mask R-CNN에서 Feature Extractor는 입력 이미지에서 유용한 정보를 추출하여 Object detection, classification, Segmentation 작업에 필요한 feature maps를 생성하는 역할을 한다. Mask R-CNN의 경우 ResNet과 FPN이 결합된 구조로 이루어져 있다.
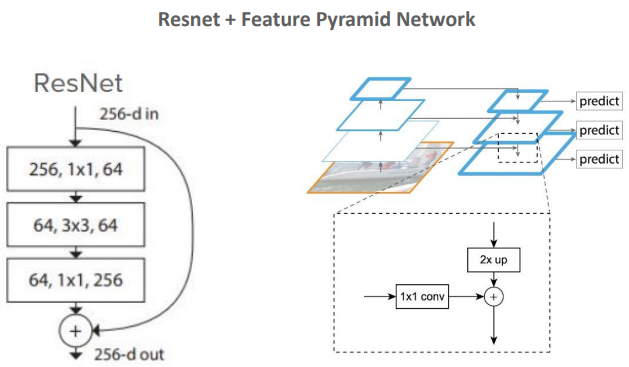
ResNet
ResNet은 Residual Connections 또는 Skip Connections를 사용한다. 이러한 연결은 입력을 출력에 직접 더해주어 신경망이 더 깊어질 때 발생할 수 있는 학습 문제를 완화시키는데 도움을 준다. 이미지에서 보이는 ResNet의 한 층은 1x1, 3x3, 1x1의 Convolution 연산을 연속으로 수행하며 각각은 다른 목적(차원 축소, Feature Extraction, 차원 복원)을 가지고 있다.
Feature Pyramid Network(FPN)
FPN은 Multi Scale Feature를 추출하여 다양한 크기의 객체를 Detection할 수 있게 하는 아키텍처로 ResNet에서 추출된 Feature Map은 FPN의 여러 층을 통해 다양한 해상도에서 처리된다. 이 과정은 큰 해상도의 Feature Map에서 시작하여 점점 작은 해상도로 내려가는 top-down 방식과 결합된다. 이렇게 합성된 Feature Map은 설로 다른 Scale의 객체를 예측할 때 사용된다.
Feature Extraction과 분할 예측
Feature Map은 2배 Up Sampling과 1x1 convolution을 통해 점진적으로 해상도를 높이는 방식으로 처리된다. 최종적으로 각 스케일에 해당하는 Feature Map에서 객체의 위치, 클래스, Binary Mask에 대한 예측이 이루어진다.
Mask R-CNN Loss Function
-
Mask R-CNN Loss
-
Classification Loss
Multiclass cross-entropy Loss -
Bounding Box Loss
-
Mask Loss
K개의 정해진 Class에 대해서 그 class에 pixel이 속하는지 아닌지 sigmoid로 결정
Binary cross-entropy Loss
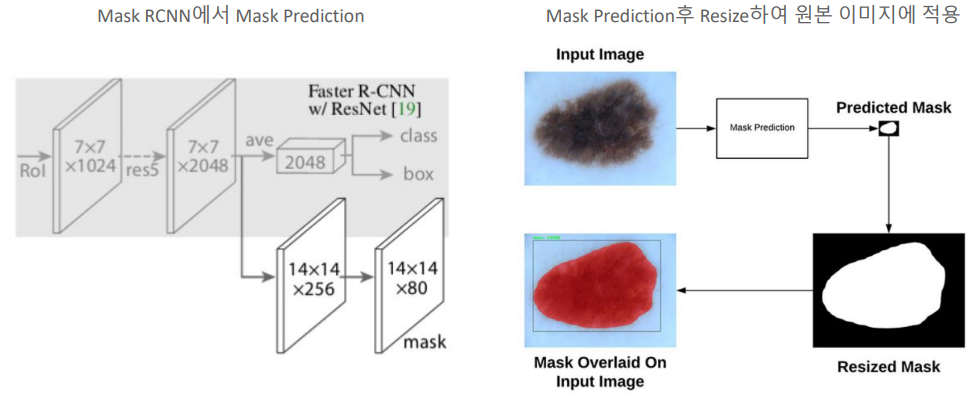
Mask Prediction
- 1. Feature Extraction : ResNet을 통해 이미지에서 Feature Extraction한다.
- 2. RoI Features : RoI-Align을 통해 추출된 Feature를 고정된 크기로 변환한다. 이를통해 클래스 예측과 Bounding Box regression을 위한 정확한 Feature를 얻을 수 있다.
- 3. Mask Branch : 별도의 Mask Branch에서는 RoI의 Feature Map을 사용하여 각 객체에 대한 mask를 예측한다. 이는 일반적으로 더 작은 해상도의 Feature Map(ex : 14x14)에서 이루어지며 각 픽셀이 객체에 속하는지 여부를 분류한다.
- 4. Mask Prediction : 예측된 mask는 원본 이미지 크기로 조정(resize)되어 실제 객체의 형태와 일치하도록 한다.
- 5. Overlay on Input Image : 최종적으로 조정된 mask는 원본 이미지 위에 오버레이 되어 시각적으로 객체의 위치와 형태를 보여준다.
- 6. Resized Mask : 예측된 mask는 입력이미지의 해상도에 맞춰 resize되어 객체의 정확한 위치와 형태를 나타낸다.
이 과정을 통해 Mask R-CNN은 Bounding Box와 함께 각 객체의 정확한 형태와 경계를 표현하는 Mask를 생성할 수 있다.
