SSD(Sigle Shot MultiBox Detector
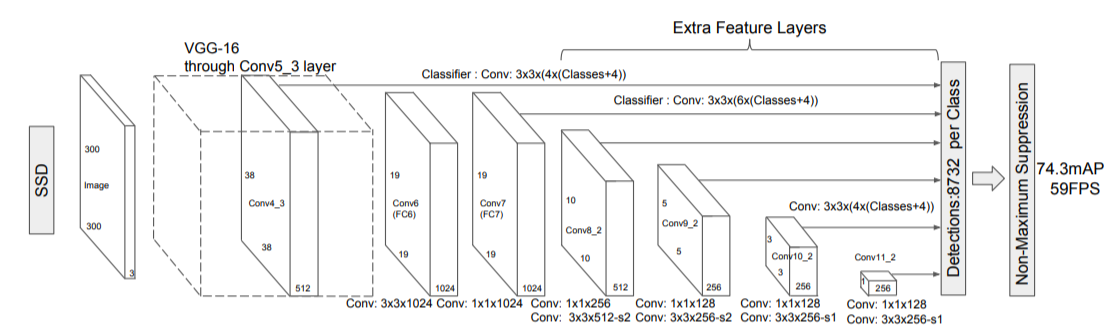
SSD는 효율성과 빠른 속도로 많은 주목을 받은 모델로 전통적인 Two Stage 접근 방식과 달리 SSD는 객체의 위치와 클래스를 One Stage로 동시에 예측한다. 이 글에서는 One Stage Detector, SSD의 개요, Multi Scale Feature Map의 활용, SSD 네트워크 구조, SSD의 성능에 대해 설명하겠습니다.
One Stage Detector
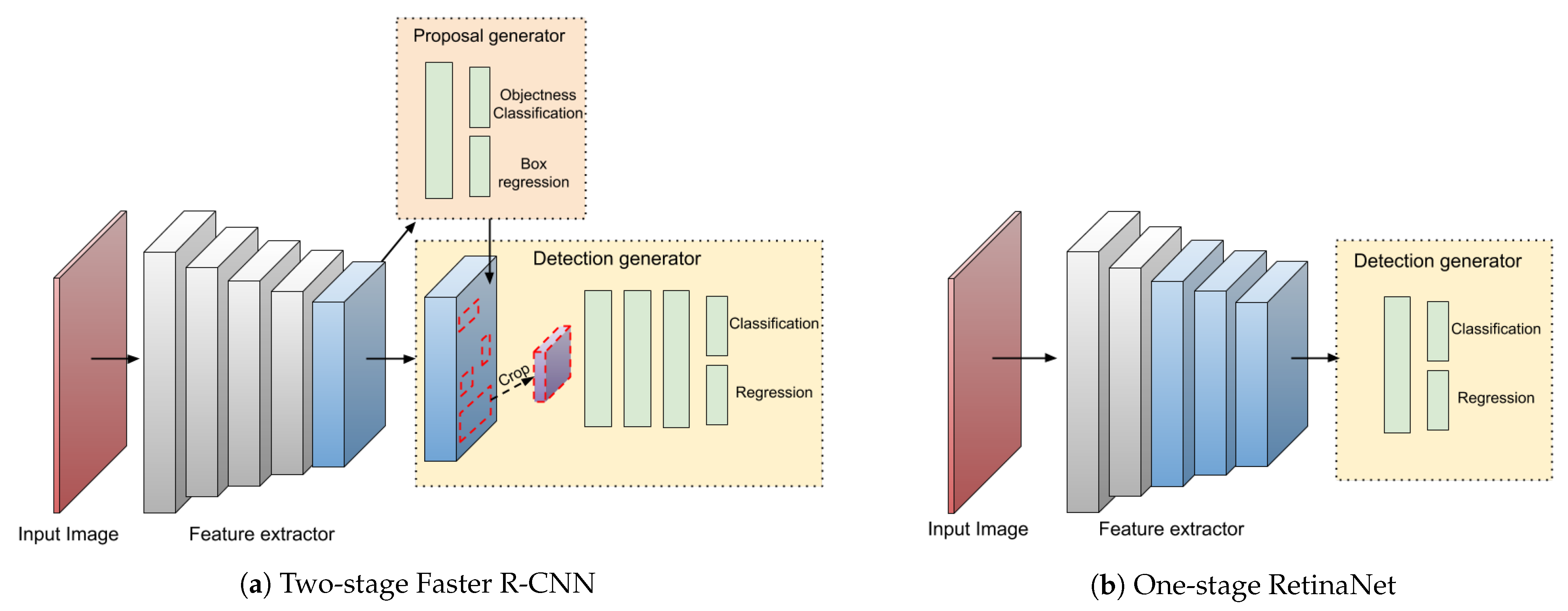
Object Detection 알고리즘은 크게 One Stage Detector와 Two Stage Detector로 분류 된다. One Stage Detector는 이미지 내의 객체를 식별하고 위치를 결정하는 과정을 단일 단계에서 수행하는 방식으로 속도와 효율성에 초점을 맞추고 있으며 실시간 처리에 적합하다.
One Stage Detector의 특징
- 1. 단일 네트워크 : 객체의 클래스와 위치를 추론하는 데 하나의 단일 네트워크를 사용한다.
- 2. 속도 : 복잡한 단계 없이 객체의 분류와 위치를 동시에 예측하므로 Two Stage Detector에 비해 빠른 처리 속도를 제공한다.
- 3. 단순화된 훈련 과정 : 후보 영역을 미리 생성하는 별도의 단계 없이 전체 이미지를 기반으로 직접 객체를 검출한다.
- 4. 실시간 검출 : 빠른 처리 능력으로 실시간 Object Detection에 매우 적합하다.
One Stage Detector의 성능
One Stage Detector는 Two Stage Detector에 비해 일반적으로 더 빠른 처리 속도를 간진다. 그러나 정밀한 객체 위치 결정이나 작은 객체의 검출과 같은 일부 측면에서는 Two Stage Detector가 더 우수한 성능을 보일 수 있다.
SSD의 개요
SSD는 이미지 내의 객체를 직접적으로 검출하는 One Stage Detector로 이는 전체 이미지를 한번만 처리하여 여러 크기와 종류의 객체를 식별하고 위치를 결정할 수 있다. Multi Scale Feature Map을 사용하여 다양한 크기의 객체에 적응할 수 있는 능력을 갖추고 있다.
Multi Scale Feature Map
SSD는 이미지를 통과시키면서 여러 단계에서 Feature Map을 추출한다. 이는 네트워크 초기 단계에서는 작은 객체를 후반 단계에서는 큰 객체를 탐지하는데 유리하며 각 Feature Map은 서로 다른 스케일의 객체를 검출하는 데 최적화되어 이를 통해 SSD는 다양한 크기의 객체를 Detection할 수 있다.
Multi Scale Feature Map과 Anchor Box의 활용
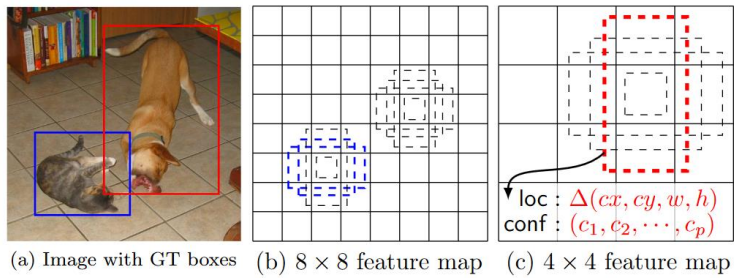
SSD에서는 Multi Scale Feature Map을 각각의 Anchor Box에 적용하여 객체의 위치를 예측한다. Multi Scale Feature Map과 Anchor Box를 결합함으로써 SSD는 단일 이미지 분석을 통해 다양한 크기와 비율의 객체를 Detection 할 수 있고 이러한 결합으로 정확도를 높혀 배경 Noise에 강한 Object detection을 가능하게 한다.
SSD 네트워크 구조
SSD의 네트워크 구조는 기본적으로 CNN(Convolutional Neural Network)으로 시작하여 여러개의 CNN 레이어를 통해 다양한 해상도의 Feature Map을 생성한다. CNN은 기본적인 VGG-16 구조를 사용하여 고수준의 Feature를 추출하고 여러 추가 레이어를 통해 점점 더 작은 크기의 Feature map을 생성하여 각각 다른 크기의 객체를 감지한다.
SSD Training
Bounding Box와 겹치는 IOU가 0.5 이상인 Anchor Box들의 Classification과 Bounding box Regression을 최적화 학습으로 수행한다.
Loss 함수
SSD 실습
OpenCV DNN을 이용하여 SSD 기반 Object Detection 수행
- Tensorflow 에서 Pretrained 된 모델 파일을 OpenCV에서 로드하여 이미지와 영상에 대한 Object Detection 수행.
- SSD+Inception과 SSD+MobileNet v3 를 모두 테스트
- CPU기반 환경에서 SSD의 Inference 속도 주시.
dnn에서 readNetFromTensorflow()로 tensorflow inference 모델을 로딩
import cv2
cv_net = cv2.dnn.readNetFromTensorflow('../pretrained/ssd/ssd_inception_v2_coco_2017_11_17/frozen_inference_graph.pb',
'../pretrained/ssd/ssd_config_01.pbtxt')coco 데이터 세트의 클래스 id별 클래스명 지정
labels_to_names = {1:'person',2:'bicycle',3:'car',4:'motorcycle',5:'airplane',6:'bus',7:'train',8:'truck',9:'boat',10:'traffic light',
11:'fire hydrant',12:'street sign',13:'stop sign',14:'parking meter',15:'bench',16:'bird',17:'cat',18:'dog',19:'horse',20:'sheep',
21:'cow',22:'elephant',23:'bear',24:'zebra',25:'giraffe',26:'hat',27:'backpack',28:'umbrella',29:'shoe',30:'eye glasses',
31:'handbag',32:'tie',33:'suitcase',34:'frisbee',35:'skis',36:'snowboard',37:'sports ball',38:'kite',39:'baseball bat',40:'baseball glove',
41:'skateboard',42:'surfboard',43:'tennis racket',44:'bottle',45:'plate',46:'wine glass',47:'cup',48:'fork',49:'knife',50:'spoon',
51:'bowl',52:'banana',53:'apple',54:'sandwich',55:'orange',56:'broccoli',57:'carrot',58:'hot dog',59:'pizza',60:'donut',
61:'cake',62:'chair',63:'couch',64:'potted plant',65:'bed',66:'mirror',67:'dining table',68:'window',69:'desk',70:'toilet',
71:'door',72:'tv',73:'laptop',74:'mouse',75:'remote',76:'keyboard',77:'cell phone',78:'microwave',79:'oven',80:'toaster',
81:'sink',82:'refrigerator',83:'blender',84:'book',85:'clock',86:'vase',87:'scissors',88:'teddy bear',89:'hair drier',90:'toothbrush',
91:'hair brush'}이미지를 preprocssing 수행하여 Network에 입력하고 Object Detection 수행 후 결과를 이미지에 시각화
import matplotlib.pyplot as plt
import cv2
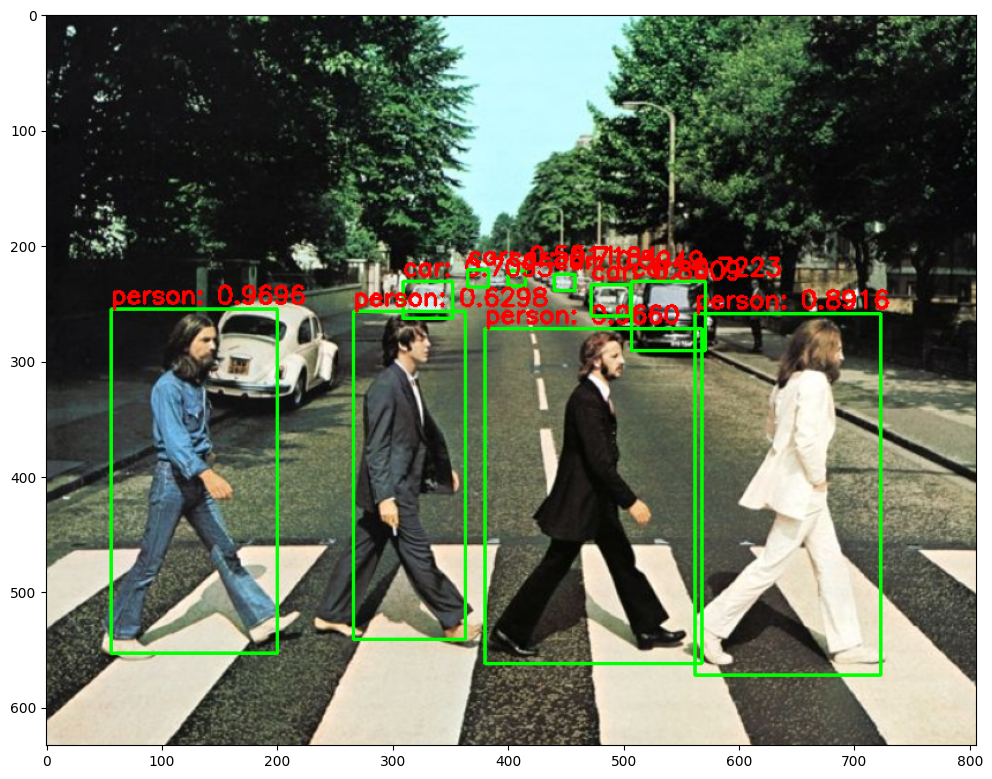
img = cv2.imread('../data/beatles01.jpg')
# 원본 이미지 (633, 806)를 네트웍에 입력시에는 (300, 300)로 resize 함.
# 이후 결과가 출력되면 resize된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
rows = img.shape[0]
cols = img.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img.copy()
# 원본 이미지 배열을 사이즈 (300, 300)으로, BGR을 RGB로 변환하여 배열 입력
cv_net.setInput(cv2.dnn.blobFromImage(img, size=(300, 300), swapRB=True, crop=False))
# Object Detection 수행하여 결과를 cv_out으로 반환
cv_out = cv_net.forward()
print(cv_out.shape)
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.4 이상만 추출
if score > 0.4:
# detected된 object들은 image 크기가 (300, 300)으로 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names 딕셔너리로 class_id값을 클래스명으로 변경. opencv에서는 class_id + 1로 매핑해야함.
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 2)
print(caption, class_id)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)(1, 1, 100, 7)
person: 0.9696 1
person: 0.9660 1
person: 0.8916 1
car: 0.8609 3
car: 0.7223 3
car: 0.7184 3
car: 0.7095 3
person: 0.6298 1
car: 0.5949 3
car: 0.5511 3
단일 이미지의 object detection을 함수로 생성
import time
def get_detected_img(cv_net, img_array, score_threshold, is_print=True):
rows = img_array.shape[0]
cols = img_array.shape[1]
draw_img = img_array.copy()
cv_net.setInput(cv2.dnn.blobFromImage(img_array, size=(300, 300), swapRB=True, crop=False))
start = time.time()
cv_out = cv_net.forward()
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.4 이상만 추출
if score > score_threshold:
# detected된 object들은 image 크기가 (300, 300)으로 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names 딕셔너리로 class_id값을 클래스명으로 변경. opencv에서는 class_id + 1로 매핑해야함.
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 2)
if is_print:
print('Detection 수행시간:',round(time.time() - start, 2),"초")
return draw_imgObject Detection 수행 후 시각화
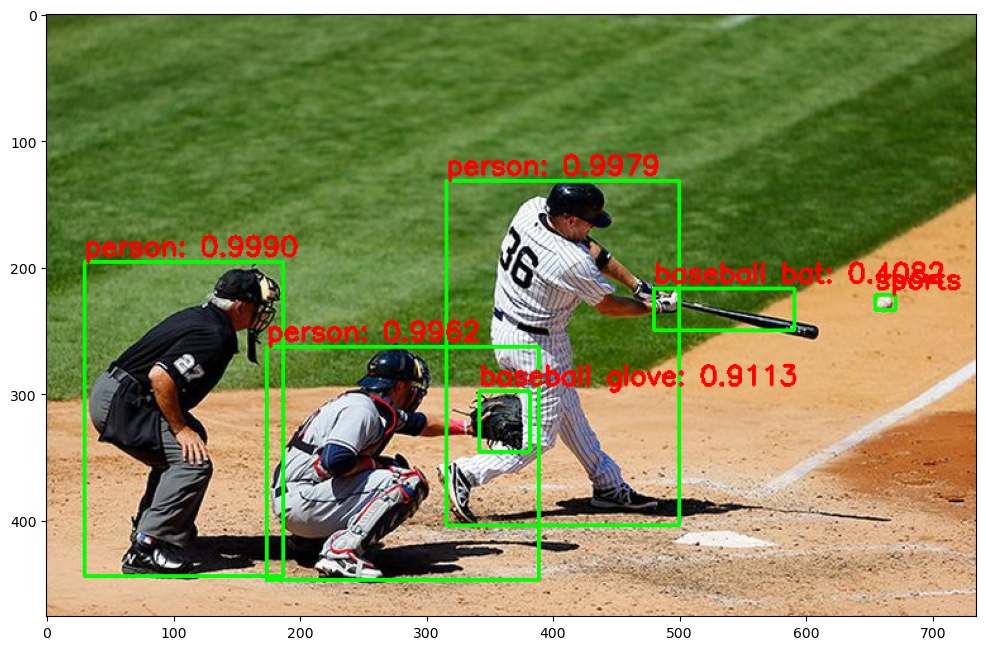
img = cv2.imread('../data/baseball01.jpg')
#coco dataset 클래스명 매핑
# Object Detetion 수행 후 시각화
draw_img = get_detected_img(cv_net, img, score_threshold=0.4, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)Detection 수행시간: 0.04 초
VideoCapture와 VideoWriter 설정하고 Video Detection용 전용 함수 생성
- VideoCapture를 이용하여 Video를 frame별로 capture 할 수 있도록 설정
- VideoCapture의 속성을 이용하여 Video Frame의 크기 및 FPS 설정.
- VideoWriter를 위한 인코딩 코덱 설정 및 영상 write를 위한 설정
총 Frame 별로 iteration 하면서 Object Detection 수행. 개별 frame별로 단일 이미지 Object Detection과 유사
def do_detected_video(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, )
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
returned_frame = get_detected_img(cv_net, img_frame, score_threshold=score_threshold, is_print=True)
vid_writer.write(returned_frame)
# end of while loop
vid_writer.release()
cap.release()총 Frame 갯수: 58
Detection 수행시간: 0.04 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.04 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.04 초
Detection 수행시간: 0.03 초
Detection 수행시간: 0.04 초
Detection 수행시간: 0.04 초
Detection 수행시간: 0.03 초
...
SSD+Mobilenet v3 Object Detection 수행.
- https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API 에 다운로드 URL 있음.
- weight파일은 http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz 에서 다운로드
- SSD + Mobilenet v3 backbone은 opencv dnn 모듈이 아니라 dnn_DetectionModel() 함수로 생성 가능하며, 이를 사용하기 위해서는 Opencv의 버전을 Upgrade해야함.
dnn_DetectionModel() 사용.
- https://github.com/opencv/opencv/pull/16760
- dnn_DetectionModel()은 dnn_Model 객체 반환
- 해당 SSD 모델은 image pixel값을 -1 ~ 1 사이로 정규화하고 image size는 320, 320으로 설정.
import cv2
cv_net_m = cv2.dnn_DetectionModel('../pretrained/ssd/ssd_mobilenet_v3_large_coco_2020_01_14/frozen_inference_graph.pb',
'../pretrained/ssd/ssd_config_02.pbtxt')
cv_net_m.setInputSize(320, 320)
cv_net_m.setInputScale(1.0 / 127.5)
cv_net_m.setInputMean((127.5, 127.5, 127.5))
cv_net_m.setInputSwapRB(True)dnn_Model 객체의 detect() 메소드는 입력 이미지를 받아서 특정 confidence threshold 이상의 모든 object inference 결과를 반환.
- class id값, confidence score값, bbox 좌표값이 arrary로 반환됨.
- bbox 좌표값의 경우 0~1사이 값이 아니라 정수형의 위치값이 반환됨. 단 xmin, ymin, width, height 형태로 반환되므로 유의 필요.
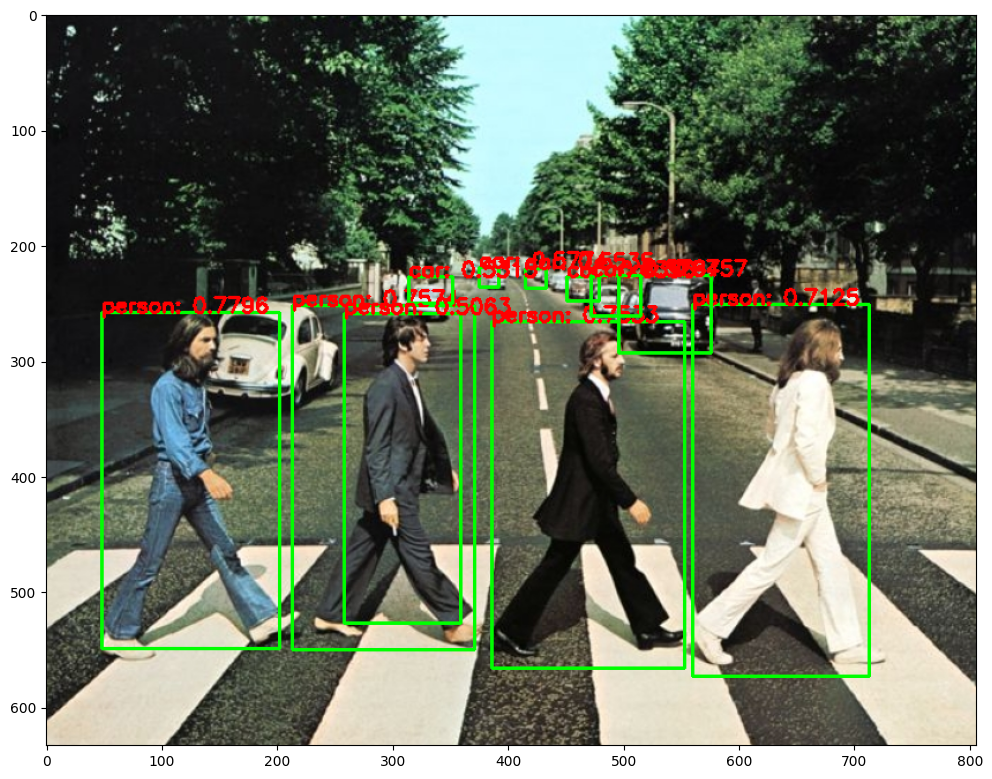
img = cv2.imread('../data/beatles01.jpg')
draw_img = img.copy()
classes, confidences, boxes = cv_net_m.detect(img, confThreshold=0.5)classes, confidences, boxes(array([1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 1]),
array([0.7795706 , 0.7573838 , 0.7533261 , 0.71246016, 0.6756759 ,
0.6396262 , 0.579421 , 0.5773533 , 0.5534913 , 0.5314795 ,
0.50632125], dtype=float32),
array([[ 48, 258, 154, 291],
[213, 252, 158, 298],
[386, 266, 167, 300],
[560, 251, 153, 322],
[496, 226, 80, 67],
[451, 227, 28, 21],
[472, 226, 43, 35],
[375, 219, 17, 17],
[415, 220, 18, 17],
[314, 227, 38, 23],
[258, 259, 101, 268]]))
classes.shape, confidences.shape, boxes.shape((11,), (11,), (11, 4))
import matplotlib.pyplot as plt
green_color=(0, 255, 0)
red_color=(0, 0, 255)
for class_id, confidence_score, box in zip(classes.flatten(), confidences.flatten(), boxes):
if confidence_score > 0.5:
caption = "{}: {:.4f}".format(labels_to_names[class_id], confidence_score)
# box 반환 좌표값은 정수형 위치 좌표임. xmin, ymin, width, height임에 유의
cv2.rectangle(draw_img, (box[0], box[1]), (box[0]+box[2], box[1]+box[3]), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (box[0], box[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.6, red_color, 2)
print(caption, class_id, box)
draw_img = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(draw_img)person: 0.7796 1 [ 48 258 154 291]
person: 0.7574 1 [213 252 158 298]
person: 0.7533 1 [386 266 167 300]
person: 0.7125 1 [560 251 153 322]
car: 0.6757 3 [496 226 80 67]
car: 0.6396 3 [451 227 28 21]
car: 0.5794 3 [472 226 43 35]
car: 0.5774 3 [375 219 17 17]
car: 0.5535 3 [415 220 18 17]
car: 0.5315 3 [314 227 38 23]
person: 0.5063 1 [258 259 101 268]
단일 이미지의 object detection을 함수로 생성
import time
def get_detected_img_renew(cv_net, img_array, score_threshold, is_print=True):
draw_img = img_array.copy()
start = time.time()
classes, confidences, boxes = cv_net.detect(img_array, confThreshold=0.5)
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for class_id, confidence_score, box in zip(classes.flatten(), confidences.flatten(), boxes):
if confidence_score > 0.5:
caption = "{}: {:.4f}".format(labels_to_names[class_id], confidence_score)
cv2.rectangle(draw_img, (box[0], box[1]), (box[0]+box[2], box[1]+box[3]), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (box[0], box[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.6, red_color, 2)
print(caption)
if is_print:
print('Detection 수행시간:',round(time.time() - start, 2),"초")
return draw_imgdnn_Model을 만드는 함수 생성
def get_cv_detection_model(pretrained_path, config_path):
cv_net = cv2.dnn_DetectionModel(pretrained_path, config_path)
cv_net.setInputSize(320, 320)
cv_net.setInputScale(1.0 / 127.5)
cv_net.setInputMean((127.5, 127.5, 127.5))
cv_net.setInputSwapRB(True)
return cv_net
cv_net_m = get_cv_detection_model('../pretrained/ssd/ssd_mobilenet_v3_large_coco_2020_01_14/frozen_inference_graph.pb',
'../pretrained/ssd/ssd_config_02.pbtxt')Objdect Detection 수행 후 시각화
img = cv2.imread('../data/beatles01.jpg')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img_renew(cv_net_m, img, score_threshold=0.5, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
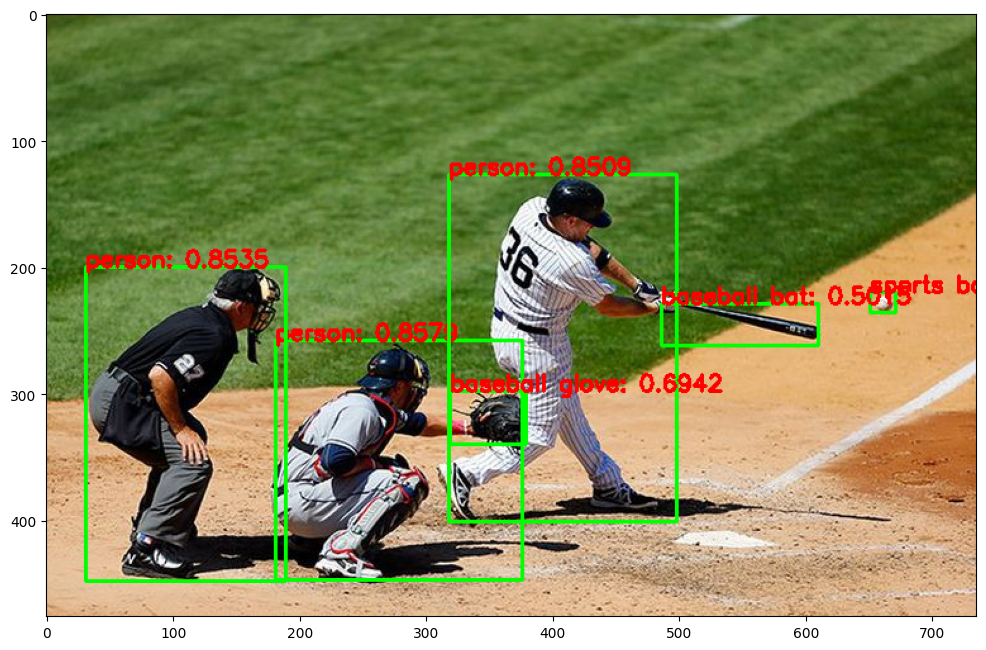
plt.imshow(img_rgb)img = cv2.imread('../data/baseball01.jpg')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img_renew(cv_net_m, img, score_threshold=0.5, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)person: 0.8579
person: 0.8535
person: 0.8509
baseball glove: 0.6942
sports ball: 0.5895
baseball bat: 0.5015
Detection 수행시간: 0.03 초
Viedeo inference 수행
def do_detected_video_renew(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, )
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
returned_frame = get_detected_img_renew(cv_net, img_frame, score_threshold=score_threshold, is_print=True)
vid_writer.write(returned_frame)
# end of while loop
vid_writer.release()
cap.release()do_detected_video_renew(cv_net_m, '../data/John_Wick_small.mp4', '../data/John_Wick_small_m3.mp4', 0.2, False)총 Frame 갯수: 58
car: 0.7007
car: 0.6426
person: 0.6268
car: 0.5965
car: 0.5591
car: 0.5143
car: 0.5111
person: 0.5018
Detection 수행시간: 0.03 초
car: 0.6978
car: 0.6462
person: 0.6340
car: 0.5995
car: 0.5576
car: 0.5123
car: 0.5123
person: 0.5040
Detection 수행시간: 0.03 초
person: 0.7225
car: 0.7070
car: 0.7001
car: 0.5805
car: 0.5615
Detection 수행시간: 0.03 초
...
