NLP (Natural Laguage Process
NLP는 인간이 일상적으로 사용하는 언어를 컴퓨터가 이해하고 처리할 수 있도록 만드는 기술로 언어의 의미를 파악하고 문장 구조를 분석하며 텍스트나 음성을 처리하는 다양한 응용 프로그램을 포함한다.
- NLU (Natural Language Understanding) : 텍스트나 음성을 분석하고 그 의미를 이해하는 과정이다.
- NLG (Natural Laguage Generation) : 컴퓨터가 스스로 텍스트나 음성을 생성하는 과정이다.
NLP가 어려운이유
언어의 복잡성
언어는 매우 복잡한 구조를 가지고 있으며 그 구조는 단순한 문법 이상의 의미를 담고있다. 예를 들어 같은 단어라도 문맥에 따라 다르게 해석될 수 있으며 동음이의어와 다의어도 많다. 또한 언어의 규칙은 완벽하게 명문화되지 않았고 예외가 많아 이러한 복잡성은 컴퓨터가 단순히 규칙을 기반으로 언어를 처리하는 데 많은 어려움을 준다.
모호성과 중의성
언어는 본질적으로 모호해 같은 문장이라도 문맥에 따라 다양한 의미를 가질 수 있다. 컴퓨터가 이러한 문맥을 이해하고 정확한 의미를 파악하는 것은 어려운 문제이다.
비정형 데이터
인간이 사용하는 언어는 구조화되지 않은 형태로 존재하는 경우가 많아 오타, 축약어, 속어, 문법 오류 등으로 인해 데이터 자체가 불완전한 경우가 많아 이를 처리하고 정제하는 과정은 자연어 처리에서 중요한 과제이다.
자연어 처리를 위한 언어학 기초
언어학 (Linguistics)
언어학은 인간의 언어를 과하적으로 연구하는 학문으로 NLP의 기초가 되는 중요한 분야이다. 언어의 구조와 기능을 분석하여 컴퓨터가 언어를 이해하고 처리하는 데 기여하며 크게 형태론, 통사론, 의미론, 화용론 등으로 구분된다.
음절 (Syllable)
음절은 언어에서 발음되는 가장 작은 단위로 하나의 소리 묶음이다. 음절은 NLP에서 텍스트를 음성으로 변환한거나 음성을 텍스트로 변환할 때 중요한 요소로 작용한다.
품사 (Part-of-Speech, POS)
품사는 단어의 문법적 역할을 나타내는 범주로 명사, 동사, 형용사, 부사 등으로 구분된다. NLP에서 품사 태깅은 중요한 작업으로 각 단어가 문장에서 어떤 역할을 하는지 분석하는 과정으로 기계 번역, 문법 분석, 감정 분석등의 여러 NLP 응용 프로그램에 필수적이다. 품사 태깅을 통해 컴퓨터는 문장의 구조를 이해하고 문맥에 따라 단어의 의미를 파악한다.
형태소 (Morpheme)
형태소는 의미를 가진 언어의 최소 단위로 학교라는 단어는 하나의 형태소로 이루어져 있지만 학생들은 학생과 복수형 접미사 -들이라는 두개의 형태소로 이루어져있다. 형태소 분석은 문장의 구조를 분석하고 의미를 파악하는 데 중요한 역할을 한다.
형태론 통사론
형태론 (Morphology)
형태론은 단어의 구조와 단어 내부에서 어떻게 의미가 형성되는지를 연구하는 학문으로 NLP에서 형태론적 분석은 단어가 어떻게 구성되고, 변형되는지를 분석하는 데 중점을 둔다. 형태론 분석을 통해 컴퓨터는 단어의 접두사, 접미사, 어근을 분리하고 각 단어의 의미적 뿌리를 파악한다. 이를 통해 컴퓨터는 동일한 어근을 가진 단어들을 그룹화하거나 새로운 형태소 결합을 통해 생겨나는 단어의 의미를 이해할 수 있다.
통사론 (Syntax)
통사론은 문장의 구조 단어들이 어떻게 배열되어 문장이 형성되는지를 연구하는 학문으로 문법적 규칙에 따라 단어들이 결합하여 문장을 이루는 방식을 분석한다. 통사론적 분석은 NLP에서 문장의 구문 구조를 분석하는 작업 기계 번역, 문법 교정, 질의 응답 시스템 등에서 사용된다.
의미론 화용론
의미론 (Semantics)
의미론은 단어와 문장이 가지는 의미를 연구하는 학문으로 NLP에서 의미론적 분석은 문맥을 통ㅎ해 단어와 문장의 의미를 파악하는 데 사용된다.
화용론 (Pragmatics)
화용론은 언어가 사용되는 실제 상황에서 의미가 어덯게 전달되는지를 연구하는 학문으로 문장 자체의 의미뿐만 아니라 말하는 사람의 의도와 듣는 사람의 해석을 분석한다. NLP에서는 텍스트 내의 의미적 맥락을 분석해 사용자의 의도를 파악하는 역할을 하며 챗봇이나 대화형 AI 시스템에서는 사요앚의 질문 의도를 정확히 파악하고 적절한 답변을제공하는 것이 화용론에 기반한 분석이다.
언어학이 적용된 NLP 사례
개체명 인식 (Named Entity Recognition, NER)
개체명 인식은 텍스트 내에서 사람, 장소, 조직, 시간, 숫자 등 특정한 개체를 인식핳는 작업이다. 언어학적 분석을 통해 문맥과 의미를 파악하여 각 단어가 어떤 종류의 개체를 나타내는지를 결정한다. 이는 정보 추출, 검색 엔진, 자동 요약등의 다양한 응용 프로그램에서 중요한 역할을 한다.
문법 교정 (Grammatical Error Correction)
문법 교정은 텍스트 내의 문법적 오류를 자동으로 교정하는 작업으로 통사론적 분석을 통해 문장의 구조를 파악하고 문법적으로 올바른 표현을 찾는다. 예를 들어 그는 학교가 갔따 라는 문장은 주어와 동사의 호응 관계에 오류가 잇으므로 그는 학교에 갔다로 교정된다.
Dependency Parsing
Dependency Parsing은 문장에서 단어들이 어떻게 상호 의존하는지를 분석하는 작업으로 각 단어 간의 종속 관계를 그래프로 표현하여 문장의 구조적 의미를 파악한다. 예를 들어 고양이가 쥐를 잡았다. 라는 문장에서 고양이는 잡았다의 주어이고 쥐는 잡았다의 목적어로 종속 관계에 있다. 이러한 분석은 기계 번역, 정보 검색, 감정 분석 등에서 문장의 의미를 보다 정교하게 이해하는 데 기여한다.
텍스트 전처리
텍스트 전처리는 NLP 모델을 구축할 때 필수적인 단게로 원본 텍스트 데이터를 모델에 적합한 형식으로 변환하는 과정을 말한다. 전처리 작업을 통해 텍스트의 노이즈를 제거하고 데이터의 일관성을 유지하며 분서의 정확도를 높일 수 있다.
한국어 데이터 전처리
한국어는 고유한 어순, 복잡한 형태소 구조, 교착어적 특성 때문에 다른 언어와는 전처리 방식이 다르다. 단어 내의 다양한 접사와 조사, 어미 변화 등을 분석하고 처리하는 과정이 필수적이다. 이러한 특성 때문에 한국어에 맞는 전처리 도구와 라이브러리가 필요하다.
KoNLPy
KoNLPy는 한국어 전처리를 위한 파이썬 라이브러리로 한국어 텍스트를 분석하고 형태소 단위로 나누는 데 최적화된 도구이다. 여러가지 형태소 분석기를 제공하며, 이를 활용해 단어를 분리하거나 품사 태깅, 명사 추출, 어간 추출 등의 다양한 작업을 수행할 수 있다.
형태소 분석기
KoNLPy는 Okt, Kkma, Komoran, Mecab, hannanum 등 여러 형태소 분석기를 지원한다.
from konlpy.tag import Okt
okt = Okt()
text = "자연어 처리는 인공지능의 중요한 분야입니다."
print(okt.morphs(text))품사 태깅
KoNLPy는 각 단어의 품사를 태깅하는 기능을 제공해 단어가 문장에서 어떤 역할을 하는지 파악 가능하다.
print(okt.pos(text))
명사 추출
텍스트에서 주요 명사를 추출하여 분석하는 기능은 정보 추출, 키워드 분석 등에 활용된다
print(okt.nouns(text))어간 추출
어근을 추출하는 기능을 제공하며 이는 형태가 변하는 한국어의 특성에 맞춰 단어의 기본 형태를 파악하는데 유용하다.
print(okt.stem(text))NLTK
NLTK는 NLP 라이브러리로 주로 영어권 텍스트를 다루지만 한국어 전처리에서도 활용할 수 있는 기능을 제공한다. 한국어 데이터를 처리할 때는 KoNLPy와 함께 사용하여 텍스트 분석의 효율성을 높일 수 있다.
토큰화
문장과 단어를 토큰화 하는 기능을 제공하며 한국어 데이터에 대해서도 텍스트를 문장이나 단어 단위로 분리할 수 있다.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "자연어 처리는 인공지능의 중요한 분야입니다."
tokens = word_tokenize(text)
print(tokens)불용어 제거
한국어 불용어 사전을 별도로 정의하여 불용어를 제거하는 기능을 제공한다.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('korean'))
filtered_tokens = [w for w in tokens if not w in stop_words]
print(filtered_tokens)NLTK와 KoNLPy의 조합
NLTK는 텍스트 분리와 불용어 제거 등의 기본 전처리 작업에 유용하며 KoNLPy는 한국어의 고유한 특성을 반영한 형태소 분석, 품사 태깅 등에 더 적합하다. 이 두가지 라이브러리를 적절히 결합하여 한국어 텍스트 전처리를 수행하면 보다 정교한 분석이 가능하다.
NLP 응용 시스템
텍스트 분류 (Text Classification)
텍스트 분류는 주어진 텍스트 데이털르 특정 카테고리나 레이블로 분류하는 작업이다. 이는 감정 분석, 뉴스 기사 분류, 스팸 메일 필터링, 주제 분류 등에 사용된다.
정보 추출 (Information Extraction)
정보 추출을 비정형 텍스트에서 의미 잇는 정보를 자동으로 추출하는 작업으로 개체명 인식, 관계 추출, 이벤트 추출 등의 하위 작업을 포함한다. 대규모 데이터에서 필요한 정보를 빠르고 효율적으로 얻는데 필수적이다.
기계 번역 (Machine Translation)
기계 번역은 한 언어의 텍스트를 다른 언어로 자동으로 번역하는 기술로 기존의 기계 번역은 규칙 기반 번역 시스템을 사용했으나 최근에는 통계적 기계 번역과 신경망 기계번역이 주로 사용되고 있다. 특히 Transformer 기반의 모델 BERT, GPT, T5 등의 기술은 번역의 정확도를 향상시켰다.
대화 시스템 (Dialog System, Chatbot)
대화 시스템은 사용자의 질문에 대한 답변을 제공하거나 자연스러운 대화를 진행하는 시스템이다. 주로 챗봇 형태로 구현되며 FAQ 처리, 고객 지원, 대화형 인터페이스 등 다양한 응용 분야에서 사용된다. 최근에는 대화의 문맥을 이해하는 Transformer 기반의 언어 모델이 많이 활용된다.
문서 요약 (Text Summarization)
문서 요약은 긴 텍스트에서 중요한 정보를 추출하여 요약된 형태로 제공하는 작업으로 추출적 요약과 생성적 요약으로 나뉜다. 추출적 요약은 원본 문장에서 중요한 문장을 그대로 추출하는 방식이고 생성적 요약은 원본 문장을 바탕으로 새로운 문장을 생성하여 요약하는 방식이다.
기계독해/질의응답 (Machine Reading Comprehension & Question Answering)
기계독해는 컴퓨터가 주어진 텍스트를 읽고 이해한 후 질문에 대한 답을 추론하는 작업이다. 이 기술은 질의응답 시스템에서 사용된다. 질의응답 시스템은 사용자가 텍스트로 질문을 입력하면 텍스트의 트정 부분에서 답을 찾아주는 역할을 한다.
딥러닝 기반 NLP
RNN
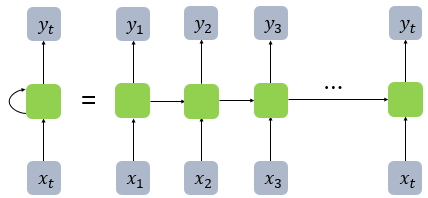
RNN은 이전 상태의 출력을 다음 입력으로 순환시키는 구조를 가지고 있어 문맥 정보를 저장하고 처리하는 데 유리하다
일반적인 RNN은 긴 문맥을 기억하는 데 어려움이 있다. 이를 기울기 소실 문제(Gradient Vanishing Problem)라고 부르며 역전파 과정에서 시간이 짐에 따라 기울기가 소실해버려 초기 입력의 영향을 잘 전달하지 못하는 현상이다.
LSTM
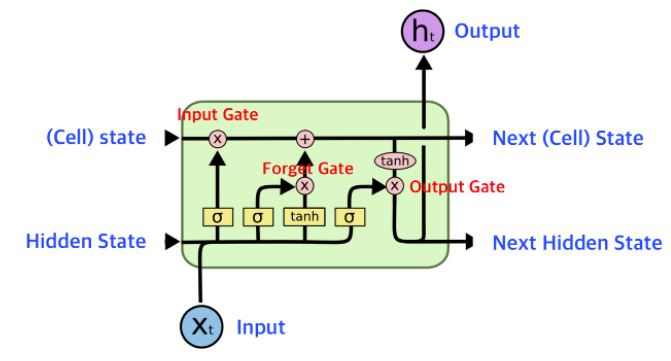
LSTM은 RNN의 한계를 보완하기 위해 고안된 구조로 장기 의존성(Long-Term Dependency) 문제를 해결한다. Cell State와 게이트 구조(Forget Gate, Input Gate, Output Gate)를 도입하여 이전 입력 정보 중 어느 것을 기억하고 어느 것을 잊을지를 조절해 중요한 정보는 장기적으로 기억하고 불필요한 정보는 잊어버릴 수 있다.
GRU
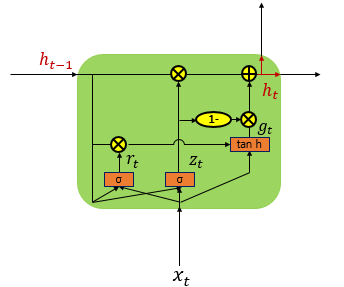
GRU는 LSTM의 변형된 형태로 보다 간단한 구조를 가지고 있다. LSTM과 마찬가지롤 장기 의존성을 처리할 수 있지만 LSTM과는 달리 셀이 없다. 대신 Update Gate와 Reset Gate만을 사용햏 정보를 조절한다. 이로 인해 GRU는 LSTM보다 더 적은 파라미터를 사용해 학습 속도가 빠르지만 유사한 성능을 보여준다.
Cross-Attention & Transformer
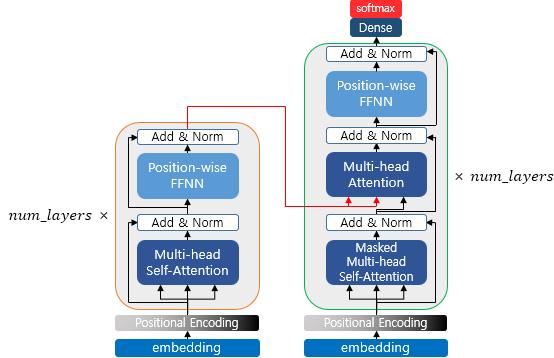
Transformer의 개념
Transformer는 RNN, LSTM과 같은 순차적인 처리 방식을 사용하지 않고 Attention Mechanism을 통해 병렬적으로 처리하는 딥러닝 모델이다. Attention Mechanism으로 각 단어가 문장의 다른 단어들과 얼마나 관련이 있는지를 동적으로 계산한다.
Cross-Attention
Cross-Attention은 주로 두개의 서로 다른 입력 시퀀스를 비교하고 연결하는 데 사용된다. 예를 들어 기계 번역에서 소스 언어와 타겟 언어 간의 상호 참조를 가능하게 하는 구조로 각 단어가 다른 문장의 다른 단어들과 얼마나 관련 있는지 계산하여 정확도를 높이는 역할을한다.
Self-Attention
Self-Attention은 문장 내의 모든 단어가 서로의 중요도를 평가해 정보를 교환하는 메커니즘으로 문장의 각 단어가 다른 모든 단어와 관계를 형성할 수 있게하여 문맥 정보를 포괄적으로 이해할 수 있도록 만든다.
-
Query, Key, Value : Self-Attention에서 각 단어는 Query, Key, Value로 변환된다. Query는 현재 단어에 대한 질문을 나타내고 Key는 다른 단어들이 얼마나 중요한지를 결정, Value는 해당 단어의 실제 값을 나타낸다.
-
가중치 계산 : Query와 Key 간의 유사도를 계산하여 가중치를 부여하고 이 가중치를 기반으로 Value를 가중 합산해 문맥을 반영한 출력값을 만든다.
