이 글을 들어왔다는 뜻은,
KEDA나 AKS + Service Bus와 같은, 흔치 않으며 고통 가득한 키워드로 들어왔을텐데,
지금까지 web을 헤메며 여기까지 다다른 당신에게 경의를 표한다.
hpa란?
내가 잘 개발해놓은 서비스가, 실제 오픈하고 대박이 친다면?
너무 좋지만, 곧이어 이런 생각이 들 것이다.
트래픽... 버티겠지?
이 트래픽을 버티기 위해, 부하분산이라는 것을 하고, lb 뒤에 많은 서버들을 붙이는 작업을 우리는 여태까지 해왔다.
사람이 수작업으로 하기 불편하니, autoscaling 가능한 서비스들이 나왔고 인기를 끌었다.
kubernetes에서도 마찬가지다.
서비스 뒤에 다수의 pod를 둘 수 있으며, 이를 사람이 수작업 할 수 없으니, hpa, horizontal pod autoscaling, 이 cpu나 memory와 같은 특정 metric 기반으로 늘였다가 줄였다가 해준다.

분신술hpa!!
KEDA란?
Kubernetes-based Event Driven Autoscaler
위의 단어로만 봐서는 쉽게 예상이 가지 않을 것이다.
pod를 cpu 및 memory와 같은 metric으로 부하분산 해도 되지만, 조금 아쉬운 경우가 있다.
예를들어,
모든 요청이 at least once 처리가 필요하여, pod 앞에 service bus와 같은 queue 서비스를 이용한다고 가정해보자.
아래와 같은 상황들이 발생될 수 있다.
엔지니어가 상상하는 운영 환경
- 요청들이 차근차근 일정한 속도로 queue에 쌓인다.
- pod들이 queue에서 pulling하여 처리한다.
- 쌓인 요청이 많아서, 지속적으로 진행되면 cpu, memory 사용량이 올라갈 것이고, 해당 metric 설정에 따라서 hpa가 진행되어, pod들이 늘어나 더 빨리 처리할 수 있다.
- 처리가 끝나고, 다시 metric 값이 낮아지면 다시 pod의 개수는 점차 줄어든다.
실제 상황
- 어디 9시 뉴스라도 탔는지, 갑자기 미친듯이 요청이 들어온다.
- pod가 우선 처리를 하지만, queue depth는 손 쓸수 없을만큼 깊어지고 있다.
- pod의 cpu, memory 메트릭이 올라는 가지만, 깊어진 queue depth를 감당하려면 hpa를 통해 차례차례 늘어나는 속도로는 택도 없다.
- 사용자들은, "서버가 터졌나?", "라즈베리파이에 서버올려서 서비스하냐?" 등 태어나서 처음 보는 단어들의 조합이 sns 및 게시판을 장식한다.
- 이슈가 발생한 다음날, 오전에는 후속조치 + 보고서 작성, 오후에는 경과보고 들어가서 꿈인지 생시인지 자신을 꼬집어본다.
보통 metric 기반으로 autoscaling을 진행 할 때, "cpu가 특정 수준 이상 올라가면 pod를 50개 올려!!" 이렇게 하진 않는다.
적당한 숫자로 올리며 또 다시 평균치가 이상이면 다시 적당한 숫자로 올리게 설정해 놓았을 것이다.
만약, service bus 안의 queue depth의 깊이에 따라서 늘어나는 pod의 수를 결정할 수 있다면?
KEDA가 지원하는 서비스 중, service bus를 지원하고 있으며 queue depth에 따라서, hpa를 진행할 수 있다.
위와 같은 상황에서 queue depth 100당 pod 1개씩 늘어나게 했다면, 급격하게 queue에 요청이 10000개가 쌓여도, pod가 생성되는 시간만 기다린다면, 쌓여진 queue는 순식간에 처리될 것이다.
기존의 방식대로 hpa를 진행 한다면, pod가 차례차례, 점진적으로 늘어나기에, 10000번째로 queue에 요청이 쌓여진 사람은 response를 받을 때까지 한세월 걸릴 것이다.

올해 안에는 response 받을 수 있을까?
03/17/2022 기준 KEDA를 통해 hpa를 진행 할 수 있는 Azure 서비스는?
현재는 아래와 같이 8개의 Azure 서비스를 지원하고 있다.
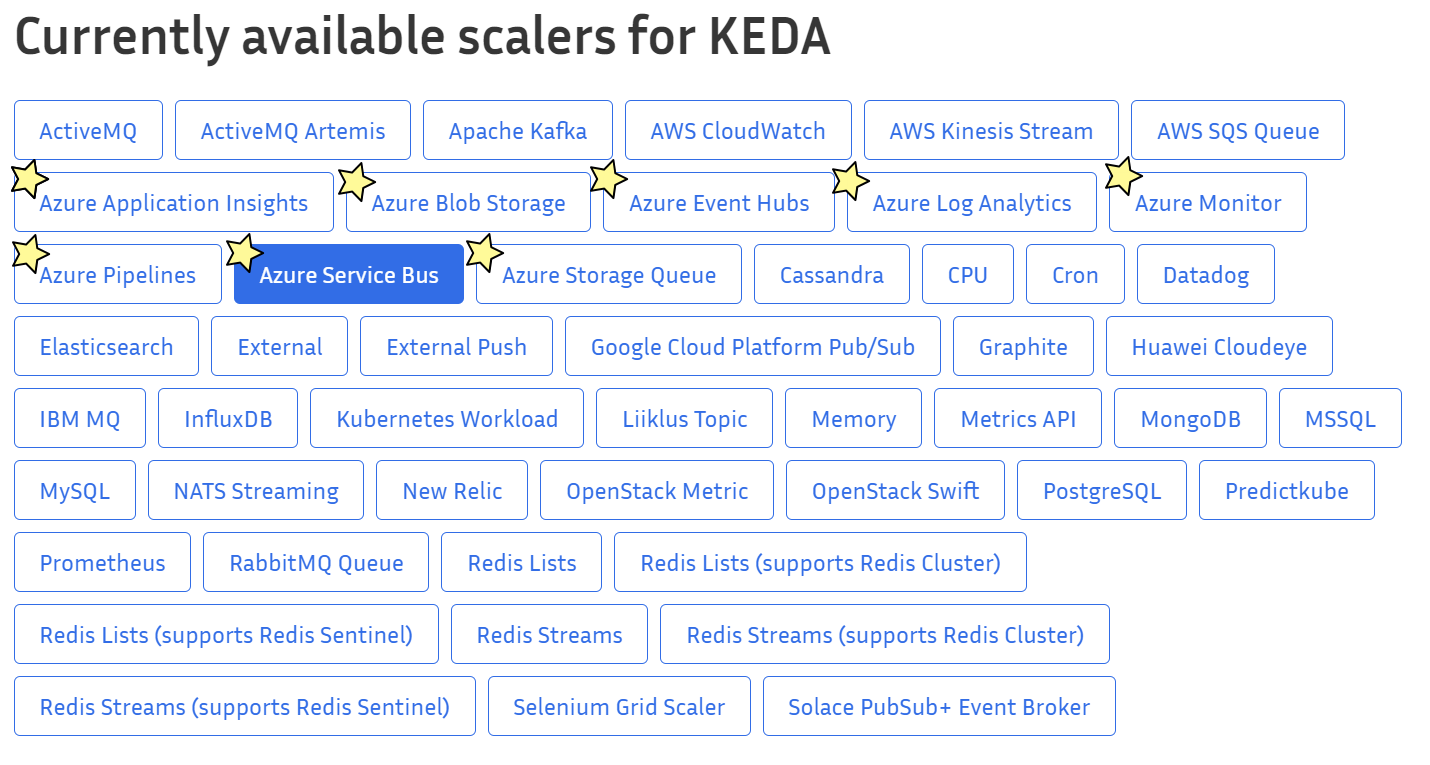
예열 끝! 어떻게 쓰는거야!?
우선 kubernetes에 KEDA를 deploy 해야한다.
deploy를 하지 않고, 바로 KEDA 문서 참조해서 쓰려고 한다면, 아래의 문구를 구경할 수 있다.
kubectl apply -f .\hpa.yaml
error: unable to recognize ".\\hpa.yaml": no matches for kind "ScaledObject" in version "keda.sh/v1alpha1"꼭 먼저 deploy!!
방법은 여러가지를 지원하지만, 이번에는 yaml을 이용하겠다.
자세한 다른 방법들에 대해서는 아래의 링크를 참고하자.
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.6.1/keda-2.6.1.yaml이렇게만 하면 우리는 KEDA를 쓸 준비가 되었다.
Service Bus, queue depth로 autoscaling!!
아래의 링크에 자세한 사용방법 또한 서술 되어져 있으니, 시간이 된다면 들여다 보는것도 좋을것 같다.
우선 내가 사용한 yaml.
yaml
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
labels:
app: testapp
spec:
replicas: 1
selector:
matchLabels:
app: testapp
template:
metadata:
labels:
app: testapp
spec:
containers:
- name: testapp
image: pwcasdf/goapp
resources:
limits:
cpu: 100m
memory: 200Mi
ports:
- containerPort: 8080
nodeSelector:
agentpool: targetpoolhpa.yaml
apiVersion: v1
kind: Secret
metadata:
name: secrets-order-management
labels:
app: order-processor
data:
# service bus queue level connection string needed
servicebus-order-management-connectionstring: <service_bus_queue_connectionstring>
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: azure-servicebus-auth
spec:
secretTargetRef:
- parameter: connection
name: secrets-order-management
key: servicebus-order-management-connectionstring
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: azure-servicebus-queue-scaledobject
namespace: keda-test
spec:
scaleTargetRef:
name: <deployment_name>
triggers:
- type: azure-servicebus
metadata:
queueName: <queue_name>
messageCount: "5"
authenticationRef:
name: azure-servicebus-auth
작성하다보니 hpa.yaml에 secret까지 넣어놓은건 봐달라구
hpa.yaml안의 ScaledObject 부분에서 짚고 넘어갈 부분은, 아래와 같다.
- scaleTargetRef: 어떤 것을 autoscaling 할것이냐?
- messageCount: 몇개의 쌓여진 msg 마다 scale out을 할 것이냐?
- queueName: 바라봐야 하는 queue의 이름은?
참고로, KEDA 예제에서는 pod identity를 사용하였지만, 나는 편의상 secret을 사용하였다.
위의 messageCount: "5"에 대해 조금 설명을 덧 붙여보자면, 쌓여진 message 5개당 pod 1개라고 보면 된다.
쌓여진 msg 0 ~ 5개 = pod 1개
쌓여진 msg 6 ~ 10개 = pod 2개
쌓여진 msg 11 ~ 15개 = pod 3개 ...
아래의 스크린샷을 보면,
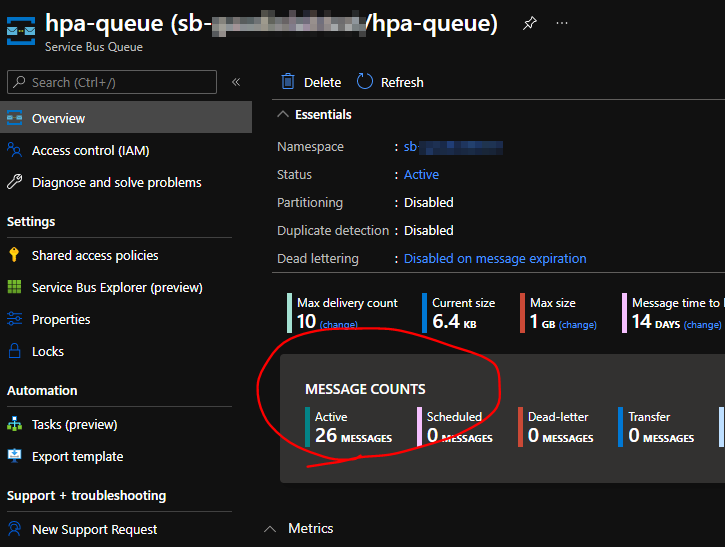
deployment의 초기 replicas는 1개였으며,
쌓여진 msg 개수가 25개라서 총 5개의 pod가 생성이 되어져있고,
추가로 1개 더 추가하면 pod가 6개가 되어야한다.
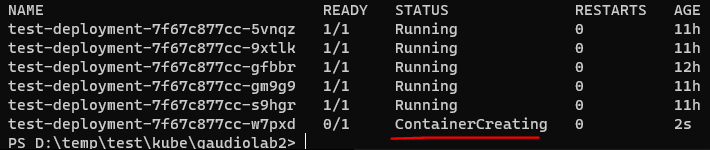
tada!!
5개는 11시간 정도 이전에 생성이되어 있었으며,
msg를 1개더 쌓아서 26개가 되자, container 한개가 추가되는 부분을 볼 수 있다.

이제 queue depth에 따라서 hpa 할 수 있으니, 아무리 많이 요청이 쌓여도 해결 할 수 해결 할 수 있다구!
너굴맨이 처리했으니 안심하라구!
마치며
이번 글에서는 Service Bus만 사용해 보았으나, KEDA가 지원하는 다른 서비스들을 활용한다면, 조금 더 다양한 시나리오에 맞는 hpa를 작업할 수 있을것이다.
추가적으로 service bus의 queue 뿐만 아니라 topic도 가능하다.
