leader가 왜 필요할까?
사실 leader election 하면 웬지 Aapche Zookeeper나 etcd만 생각나고 어디에 써먹어야 할지 애매하게 다가올 수도 있다. 오늘 일하면서 동료와 함게 이야기 하던 중 손쉽게 써먹을 수 있지 않을까 싶어 기록으로 남긴다. 만약 아래에 나오는 요구사항과 비슷한 경우가 있다면 꼭 활용해보기 바란다.
현재 어떤 경우에 고려하고 있는가?
예를 들어 batch가 돌아가는 서버가 있다고 하자. 이 batch는 무조건 돌아야 되기도 하고 고가용성을 생각해보았을 때 VM 2대로 돌린다고 가정하자. 다른 코드로 VM 2대에 배포할 수는 없으니 같은 코드를 배포하여 사용한다고 했을 때 고민이 생긴다. 같은 시간대에 batch가 동시에 돌면 안되는데 어떻게 하지??
요구사항을 정리하면 아래와 같다.
- 2대 이상의 VM으로 구성하여 ha 구성을 한다.
- batch는 2대 중 한대만 실행되야 한다.
- 만약 처음 돌다가 실패했다면 다음 VM이 실행해야 한다.
그럼 leader election이 위 경우fmf 어떻게 도울수 있을까?
leader로 선출된 VM이 작업을 하고 나머지는 leader가 아니니 작업을 안하면 된다.
어떻게 구현할 수 있을까?
Azure에서 손쉽게 활용할 수 있는 것이 있을까?
우리는 Azure를 사용하고 있기에 Azure에서 가장 손쉽게 활용할 수 있는 Azure Storage Account 의 구성 중 blob storage를 활용할 것이다.
blob의 lease 상태값은 5가지가 있다.
- Available
- Leased
- Expired
- Breaking
- Broken
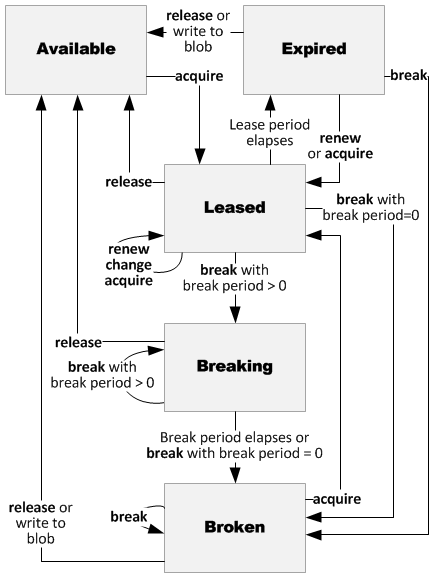
위의 5가지 상태값 중, 아래의 3개를 사용하는 것이 보편적인 leader election 과정에 포함된다.
- Available
- Leased
- Expired
위 3가지 상태 값이 있다는 것을 기억하고 아래의 개념만 추가해주면 완성이다.
- blob을 lease 할 수 있는 것은 단 한대의 VM 또는 하나의 프로세스만 가능하다.
- blob을 lease하면 lease id를 부여 받는데 해당 id로 상태 값을 변경하거나 renew 할 수 있다.
- lease를 renew하지 못한채로 시간이 지나면 expired로 변한다.
- expired된 blob은 일정시간이 지나면 available로 돌아온다.
그럼 방식으로 구현할까?
먼저 VM 2대다 lease id를 수령받는 코드를 특정시간에 돌아가게 한다. 2대중 한대만 받게 될 것이고 그 VM이 leader가 된다. leader VM은 batch를 돌리며 만약 60초안에 다 못돌릴 시에는 특정시간 마다 renew를 하게 한다. leader가 되지 못한 VM은 5~10초 간격으로 계속 blob의 status를 확인하는 요청을 해야한다. 혹여나 expired로 떨어지면 바로 leader로서 lease id를 가져온 후 작업을 시작해야한다. leader가 되지 못한 VM들이 계속 확인하며 해당 blob이 available로 변한게 확인 되었다면 해당 시간대에 돌아야하는 batchs는 성공적으로 돌아갔다고 판단하고 다음 batch 시간대를 기다린다. 아래와 같은 순서로 정리할 수 있다.
- 모든 VM이 lease 시도
- 하나의 VM 만이 lease 성공하여 lease id 수령
- lease id를 받은 VM은 leader로서 batch를 수행
- batch 수행 중 특정 주기로 renew (시간이 부족할 시)
- batch가 돌아갈 때 다른 leader가 되지 못한 VM들은 blob의 status를 5~10초 간격으로 계속 체크
- expired로 확인되면 다시 lease를 시도하여 batch 재실행
- leader VM이 batch 완료 후 lease id를 활용해 blob을 release함 (상태가 available로 변경됨)
- 다른 VM들도 다시 available이 된 것을 확인되면 해당 시간대에 돌아야하는 batch는 완료되었다고 간주하고 다음 batch를 기다림
제대로 된 leader election을 사용하고 싶다?
여러가지 알고리즘들이 있지만 아래의 알고리즘들을 고려해보자.
마치며
blob storage를 활용해서 간단한 소수의 유닛들간의 leader를 선출해보았지만 조금 더 큰 cluster라면 바로 위 알고리즘들을 고려해보자.
