김중헌 감사님의 설명 덕분에 그동안 헷갈렸던 개념들을 명확히 이해할 수 있었으며, 새로운 개념들을 배울 수 있는 유익한 시간이었습니다.
이번 주에는 언어 지능 딥러닝에 대한 강의가 진행되었습니다.
이 과정에서 선형회귀나 RNN과 같은 기존 개념을 다시금 짚어보고, 새로운 단어 임베딩과 NLP 등의 주제에 대해서도 학습할 수 있는 기회가 있었습니다.
NLP 란?
자연어 처리는 언어학, 컴퓨터 과학, 인공지능의 하위 분야로, 컴퓨터와 인간의 언어 사이의 상호작용에 관여합니다.
특히 많은 양의 자연어 데이터를 처리하고 분석하기 위해 컴퓨터를 프로그래밍하는 방법을 NLP(Natural Language Processing)라고 합니다.
이 기술을 통해 문서에 포함된 정보와 통찰력을 정확하게 추출할 수 있을 뿐만 아니라 문서와 문장을 분류하고 구성할 수 있습니다.
벡터의 유사도
사람들이 인식하는 문서 유사도는 주로 문서들 간에 공통적으로 사용된 단어나 유사한 단어의 빈도에 의존합니다.
기계도 이와 마찬가지입니다.
기계가 계산하는 문서 유사도의 효율성은 각 문서의 단어들을 어떻게 수치화하고 표현했는지(DTM, Word2Vec 등), 그리고 문서 간의 단어들의 차이를 어떻게 계산했는지(유클리드 거리, 코사인 유사도 등)에 달려 있습니다.
1. 코사인 유사도(Cosine Similarity)
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다.
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 됩니다.
따라서 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있습니다.
이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미합니다.
두 벡터 A, B에 대해서 코사인 유사도는 다음과 같이 식으로 표현됩니다.
2. 자카드 유사도(Jaccard similarity)
자카드 유사도(Jaccard similarity)는 두 개의 집합이 얼마나 비슷한지를 측정하는 지표입니다. 이는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나누어 계산됩니다. 자카드 유사도는 0과 1 사이의 값을 가지며, 두 집합이 동일할수록 1에 가까워지고, 두 집합이 완전히 다를수록 0에 가까워집니다.
자카드 유사도를 구하는 함수를 ( J(A, B) ) 라고 할 때, 해당 함수는 다음과 같이 정의됩니다.
3. 유클리드 거리(Euclidean distance)
유클리드 거리(Euclidean Distance)는 두 점 사이의 거리를 계산하는 기법입니다. 두 점 p와 q가 각각 (p_1, p_2, ..., p_n), (q_1, q_2, ..., q_n) 좌표를 가질 때, 두 점 사이의 거리를 유클리드 거리 공식으로 표현하면 아래와 같습니다.
다차원이 아닌 2차원 공간에서 유클리드 거리를 쉽게 알아보겠습니다(그림 1 참고).
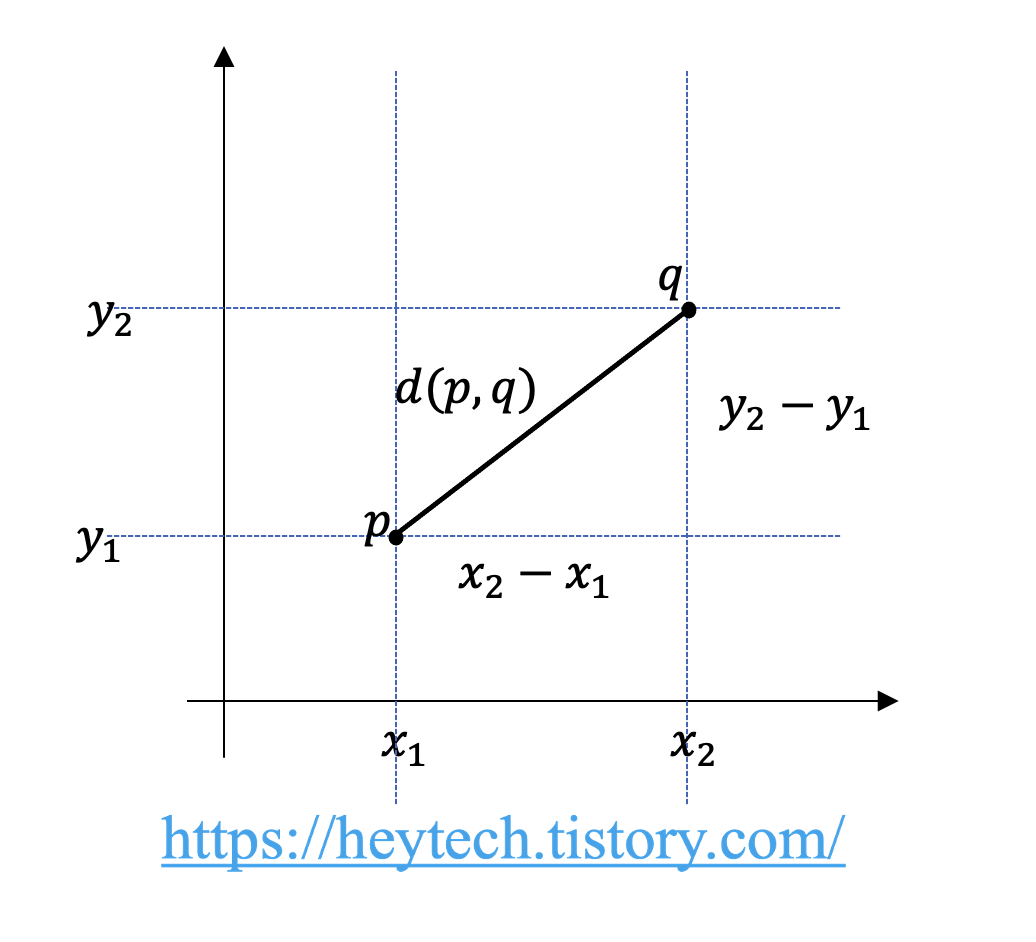
두 점 p와 q의 거리는 피타고라스를 활용해 아래와 같이 계산할 수 있습니다.
불용어 (Stopword)
불용어는 큰 의미가 없는 단어 토큰을 말한다.
예를 들어 I, my, me, over, 조사, 접미사는 문장에서는 자주 등장하지만, 실제 의미 분석에는 거의 기여하지 않는다.
NLTK는 100여개 이상의 영어 단어를 불용어로 패키지 내에서 미리 정의하고 있다.
또한 개발자가 직접 정의하기도 한다.
nltk.stopwords.words(”english”)를 통해 NLTK가 정의한 영어 불용어 리스트를 확인할 수 있다.
토큰화(Tokenization)
코퍼스 데이터 전처리는 용도에 맞게 토큰화, 정제, 정규화 작업을 하게 됩니다.
토큰화는 코퍼스를 토큰이라는 단위로 나누는 작업으로, 토큰의 단위는 상황에 따라 다르지만 일반적으로 '의미있는 단위'로 정의됩니다.
1. 단어 토큰화(Word Tokenization)
토큰의 기준을 단어로 하는 경우, 단어 토큰화라고 합니다.
여기서 단어는 단어구, 의미를 갖는 문자열로 간주됩니다.
입력으로부터 구두점과 같은 문자를 제외시키는 것도 간단한 단어 토큰화 작업에 해당합니다.
토큰화 중 선택의 순간
구두점을 제거하는 것으로 인해 토큰이 의미를 잃을 수 있습니다.
또한 아포스트로피를 어떻게 토큰으로 분류해야 하는지는 매우 복잡한 문제입니다.
이때는 사용 목적에 따라 다르게 처리할 수 있으며, 용도에 영향이 없는 것을 기준으로 정하면 됩니다.
print('word_tokenize:', word_tokenize("Can't you believe it?"))
print('WordPunctTokenizer:', WordPunctTokenizer().tokenize("Can't you believe it?"))
print('Keras text_to_word_sequence:', text_to_word_sequence("Can't you believe it?"))
# 출력
word_tokenize: ['Ca', "n't", 'you', 'believe', 'it', '?']
WordPunctTokenizer: ['Can', "'", 't', 'you', 'believe', 'it', '?']
Keras text_to_word_sequence: ['can', 't', 'you', 'believe', 'it']word_tokenize : 아포스트로피의 의미를 분리하였다.
WordPunctTokenizer : 아포스트로피를 별개의 문자로 처리했다.
Keras text_to_word_sequence : 아포스트로피를 포함하여 하나의 문자로 처리했으며, 다른 구두점 및 영어 대문자는 제거하였다.
2. 문장 토큰화(Sentence Tokenization)
토큰의 단위가 문장인 경우를 의미합니다.
마침표, 느낌표, 물음표가 항상 문장의 끝을 나타내지는 않기 때문에 이를 고려해야 합니다.
사용하는 코퍼스가 어떤 국적의 언어인지, 해당 코퍼스에서 특수문자가 어떻게 사용되는지에 따라 규칙을 정의할 수 있지만, 100% 정확도를 얻는 것은 쉽지 않습니다.
코퍼스가 정제되어 있지 않은 상태일 경우, 우선 사용하는 용도에 맞게 문장 토큰화가 필요할 수 있습니다.
!pip install kss
import kss
text_ko = "인공지능 기술은 발전하고 있지만, 여전히 문제가 많습니다. 특히 자연어 처리는 언어의 복잡성으로 인해 도전적입니다. 하지만 노력하면 이를 극복할 수 있을 거예요?"
print("한국어 문장 토큰화: ", kss.split_sentences(text))
# 출력
['인공지능 기술은 발전하고 있지만, 여전히 문제가 많습니다.', '특히 자연어 처리는 언어의 복잡성으로 인해 도전적입니다.', '하지만 노력하면 이를 극복할 수 있을 거예요?']3. 한국어에서의 토큰화의 어려움
한국어는 영어와 달리 띄어쓰기만으로는 토큰화를 충분히 수행하기 어렵습니다. 이는 한국어가 교착어라는 특성에서 비롯됩니다.
1) 교착어의 특성:
한국어는 조사, 어미, 접사 등이 띄어쓰기 없이 결합되어 사용되는 경우가 많습니다.
이로 인해 같은 단어임에도 조사의 여부에 따라 다른 단어로 인식될 수 있습니다. 이러한 경우 자연어 처리가 어렵고 번거로워지는 경우가 많습니다.
한국어 NLP에서는 조사를 분리해주는 과정이 필요합니다.
또한, 한국어 토큰화를 위해서는 형태소(morpheme)라는 개념을 이해해야 합니다.
- 자립 형태소: 접사, 어미, 조사와 상관 없이 독립적으로 사용할 수 있는 형태소로, 단어의 기본 형태를 나타냅니다.
- 의존 형태소: 다른 형태소와 결합하여 사용되는 형태소로, 접사, 어간, 어미, 조사 등이 해당됩니다.
예시: "에디가 책을 읽었다."
- 자립 형태소: "에디", "책"
- 의존 형태소: "가", "을", "읽-", "-었", "-다"
한국어에서 단어 토큰화와 유사한 형태를 얻기 위해서는 형태소 토큰화를 수행해야 합니다.
2) 띄어쓰기의 불규칙성:
한국어 코퍼스의 많은 경우, 띄어쓰기가 올바르게 지켜지지 않는 경우가 많습니다.
이러한 띄어쓰기의 불규칙성은 토큰화 작업을 어렵게 만듭니다.
4. 품사 태깅(Part-of-speech tagging):
한국어나 영어와 같이 단어의 표기가 같더라도 품사에 따라 의미가 달라지는 경우가 많습니다.
이러한 경우 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분하여 놓기도 합니다.
이러한 작업을 품사 태깅이라고 합니다.
예를 들어, '못'은 명사로는 '목재의 막대', 부사로는 '할 수 없다'의 의미를 갖고 있습니다.
정제(Cleaning) and 정규화(Normalization)
토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제 및 정규화하는 작업이 항상 존재한다.
정제 : 갖고 있는 코퍼스의 노이즈 데이터를 제거
정규화 : 표현 방법이 다른 단어들을 통합시켜 같은 단어로 만들어 준다.
1. 규칙에 기반한 표기가 다른 단어들의 통합
같은 의미를 가지지만 표기가 다른 단어들을 하나의 단어로 통합하는 방법을 사용할 수 있습니다.
필요에 따라 직접 코딩을 통해 정의할 수 있습니다.
2. 대, 소문자 통합
영어권 언어에서 대소문자를 통합하여 단어의 개수를 줄일 수 있습니다.
대문자는 특정 상황에서만 쓰이기 때문에 주로 소문자로 변환됩니다.
단, 고유명사를 나타내는 대문자는 유지되어야 합니다.
사용자들이 대소문자를 일관되게 사용하지 않는 경우, 코퍼스 전체를 소문자로 변환하는 것이 실용적인 해결책이 될 수 있습니다.
3. 불필요한 단어의 제거
노이즈 데이터는 자연어가 아니면서 아무 의미도 갖지 않는 글자들(특수 문자 등)을 의미합니다.
불필요한 단어를 제거하는 방법으로는 불용어 제거, 등장 빈도가 적은 단어, 길이가 짧은 단어를 제거하는 방법이 있습니다.
등장빈도가 적은 단어: 너무 적게 등장해서 자연어 처리에 도움이 되지 않는 경우 삭제합니다.
길이가 짧은 단어: 대부분 불용어에 해당하여 삭제하거나, 정규 표현식을 이용하여 삭제합니다.
4. 정규 표현식(Regular Expression)
정규표현식을 이용하여 코퍼스에서 불필요한 부분을 규칙에 기반해 한 번에 제거할 수 있습니다.
HTML 태그나 기타 불필요한 정보를 제거하는 데에 유용합니다.
원-핫 인코딩(One-Hot Encoding)
단어 집합(vocabulary)은 서로 다른 단어들의 집합이다.
단어 집합에 있는 단어들을 벡터로 바꾸는 것을 작업에는 여러가지 방법이 있는데, 원-핫 인코딩은 그 방법 중 하나이다.
텍스트를 단어 토큰화 한 뒤, 정수 인코딩 까지 진행한 데이터에 대해 원-핫 인코딩을 진행한다.
1. 원-핫 인코딩이란?
단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이다.
이렇게 표현된 벡터를 원-핫 벡터(One-Hot Vector)라고 한다.
2. 케라스를 이용한 원-핫 인코딩
케라스가 제공하는 to_categorical 함수를 이용하여 원-핫 인코딩이 가능하다.
3. 원-핫 인코딩의 한계
단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다는 단점이 있다.
(공간 측면에서 매우 비효율적인 표현 방법)
단어의 유사도를 표현할 수 없다는 단점도 존재한다.
강아지, 개, 냉장고라는 단어가 있을 때 강아지와 개가 유사하다는 것이 명확하지만, 원-핫 인코딩을 한다면 어떤 단어가 더 유사한지 알 수 없다.
유사도를 표현할 수 없을 때 발생하는 문제점은, 삿포로 숙소를 검색했을 때 료칸, 호텔, 게스트 하우스를 보여줘야하는데 숙소와 유사한 단어를 알 수 없어 이를 보여줄 수 없다.
이러한 단점을 해결하기 위해 단어의 잠재 의미를 반영하여 다차원 공간에 벡터화 하는 기법이 있다.
LSA(잠재 의미 분석), HAL : 카운트 기반의 벡터화 방법
NNLM, RNNLM, Word2Vec, FastText : 예측 기반의 벡터화 방법
GloVe : 두 가지 방법을 모두 사용하는 방법
참고자료 위키독스
알고리즘 스터디
알고리즘 스터디
알고리즘 스터디
이번 한 주도 정말 수고 많으셨습니다.
정처기, 스터디, 프로젝트, 강의 등 여러 활동을 하며 부족한 점을 많이 느꼈지만, 그 과정에서 모르던 것들을 하나씩 채워가는 기분이 들어 매일매일 즐거운 하루를 보내고 있습니다!
다음 주에는 미니 프로젝트와 정처기 시험이 기다리고 있어요 모두 좋은 결과를 얻을 수 있기를 바래요!!!
에이블러 여러분, 모두 힘내세요~!
